
Heim >Technologie-Peripheriegeräte >KI >CLRNet: Ein hierarchisch verfeinerter Netzwerkalgorithmus zur autonomen Fahrspurerkennung
CLRNet: Ein hierarchisch verfeinerter Netzwerkalgorithmus zur autonomen Fahrspurerkennung

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBnach vorne
- 2024-03-08 12:00:05711Durchsuche
In visuellen Navigationssystemen ist die Spurerkennung eine entscheidende Funktion. Es hat nicht nur erhebliche Auswirkungen auf Anwendungen wie autonomes Fahren und fortschrittliche Fahrerassistenzsysteme (ADAS), sondern spielt auch eine Schlüsselrolle bei der Selbstpositionierung und dem sicheren Fahren intelligenter Fahrzeuge. Daher ist die Entwicklung der Spurerkennungstechnologie von großer Bedeutung für die Verbesserung der Intelligenz und Sicherheit des Verkehrssystems.
Die Fahrspurerkennung weist jedoch einzigartige lokale Muster auf, erfordert eine genaue Vorhersage der Fahrspurinformationen in Netzwerkbildern und ist auf detaillierte Low-Level-Funktionen angewiesen, um eine präzise Lokalisierung zu erreichen. Daher kann die Fahrspurerkennung als eine wichtige und herausfordernde Aufgabe im Computer Vision betrachtet werden.
Die Verwendung verschiedener Funktionsebenen ist für eine genaue Fahrspurerkennung sehr wichtig, aber die Rabattierung befindet sich noch in der Erkundungsphase. In diesem Artikel wird das Cross-Layer-Refinement-Netzwerk (CLRNet) vorgestellt, das darauf abzielt, High-Level- und Low-Level-Funktionen bei der Spurerkennung vollständig auszunutzen. Erstens durch Erkennung von Spuren mit semantischen Merkmalen auf hoher Ebene und anschließende Verfeinerung basierend auf Merkmalen auf niedriger Ebene. Dieser Ansatz kann mehr Kontextinformationen zur Erkennung von Fahrspuren nutzen und gleichzeitig lokale detaillierte Fahrspurmerkmale nutzen, um die Positionierungsgenauigkeit zu verbessern. Darüber hinaus kann die Merkmalsdarstellung von Fahrspuren durch die Erfassung des globalen Kontexts über ROIGather weiter verbessert werden. Zusätzlich zum Entwurf eines völlig neuen Netzwerks wird auch ein Linien-IoU-Verlust eingeführt, der die Spurlinien als ganze Einheit zurückbildet, um die Positionierungsgenauigkeit zu verbessern.
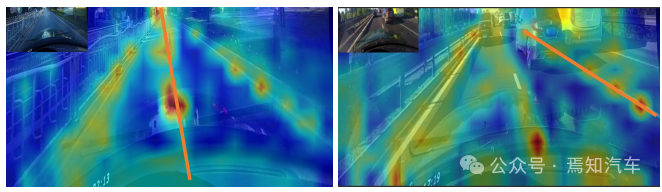
Wie bereits erwähnt, sind detaillierte Low-Level-Funktionen erforderlich, um Lane genau zu lokalisieren, da Lane über eine Semantik auf hoher Ebene, aber über spezifische lokale Muster verfügt. Es bleibt ein Problem, wie unterschiedliche Funktionsebenen in CNNs effektiv genutzt werden können. Wie in Abbildung 1(a) unten dargestellt, haben Orientierungspunkte und Fahrspurlinien eine unterschiedliche Semantik, weisen jedoch ähnliche Merkmale auf (z. B. lange weiße Linien). Ohne hochrangige Semantik und globalen Kontext ist es schwierig, zwischen ihnen zu unterscheiden. Andererseits wird aber auch die Regionalität groß geschrieben, die Gassen sind lang und schmal und das Ortsbild einfach.
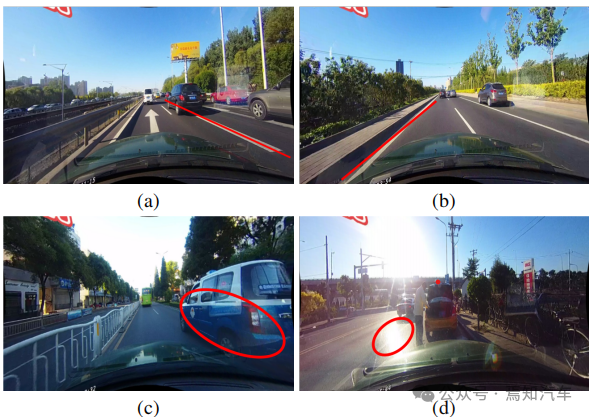
zeigt die Erkennungsergebnisse von High-Level-Features in Abbildung 1(b). Obwohl die Spur erfolgreich erkannt wurde, muss ihre Genauigkeit verbessert werden. Daher kann die Kombination von Low-Level- und High-Level-Informationen einander ergänzen, was zu einer genaueren Fahrspurerkennung führt.
Ein weiteres häufiges Problem bei der Spurerkennung ist der Mangel an visuellen Informationen über die Spurpräsenz. In einigen Fällen können Fahrspuren durch andere Fahrzeuge belegt sein, was die Spurerkennung erschwert. Darüber hinaus kann die Spurerkennung bei extremen Lichtverhältnissen schwierig werden.
Verwandte Arbeit
Vorherige Arbeiten modellieren entweder die lokale Geometrie der Fahrspur und integrieren sie in die globalen Ergebnisse oder erstellen eine vollständig verbundene Ebene mit globalen Features, um die Fahrspur vorherzusagen. Diese Detektoren haben die Bedeutung lokaler oder globaler Merkmale für die Fahrspurerkennung gezeigt, nutzen jedoch nicht beide Merkmale gleichzeitig, was möglicherweise zu einer ungenauen Erkennungsleistung führt. SCNN und RESA schlagen beispielsweise einen Mechanismus zur Nachrichtenweitergabe vor, um globalen Kontext zu erfassen. Diese Methoden führen jedoch eine Vorhersage auf Pixelebene durch und behandeln Spuren nicht als ganze Einheit. Dadurch bleibt ihre Leistung hinter der vieler moderner Detektoren zurück.
Für die Spurerkennung ergänzen sich Low-Level- und High-Level-Funktionen. Auf dieser Grundlage schlägt dieser Artikel eine neuartige Netzwerkarchitektur (CLRNet) vor, um Low-Level- und High-Level-Funktionen für die Spurerkennung vollständig zu nutzen. Zunächst wird über ROIGather globaler Kontext erfasst, um die Darstellung von Fahrspurmerkmalen weiter zu verbessern, die auch in andere Netzwerke eingefügt werden können. Zweitens wird ein auf die Fahrspurerkennung zugeschnittener Line-over-Union-Verlust (LIoU) vorgeschlagen, um die Fahrspur als Ganzes zurückzubilden und die Leistung deutlich zu verbessern. Um die Positionierungsgenauigkeit verschiedener Detektoren besser vergleichen zu können, wird außerdem ein neuer mF1-Indikator verwendet.
Die CNN-basierte Spurerkennung wird derzeit hauptsächlich in drei Methoden unterteilt: segmentierungsbasierte Methode, ankerbasierte Methode und parameterbasierte Methode. Diese Methoden identifizieren basierend auf der Darstellung von Spuren.
1. Segmentierungsbasierte Methode
Diese Art von Algorithmus verwendet normalerweise eine pixelweise Vorhersageformel, dh die Spurerkennung wird als semantische Segmentierungsaufgabe betrachtet. SCNN schlägt einen Nachrichtenübermittlungsmechanismus vor, um das Problem nicht visuell erkennbarer Objekte zu lösen, der die starken räumlichen Beziehungen in Fahrspuren erfasst. SCNN verbessert die Leistung der Fahrspurerkennung erheblich, für Echtzeitanwendungen ist die Methode jedoch langsam. RESA schlägt ein Echtzeit-Feature-Aggregationsmodul vor, das es dem Netzwerk ermöglicht, globale Features zu sammeln und die Leistung zu verbessern. In CurveLane-NAS wird Neural Architecture Search (NAS) verwendet, um bessere Netzwerke zu finden, die genaue Informationen erfassen, um die Erkennung von Kurvenspuren zu erleichtern. Allerdings ist NAS extrem rechenintensiv und benötigt viel GPU-Zeit. Diese segmentierungsbasierten Methoden sind ineffizient und zeitaufwändig, da sie Vorhersagen auf Pixelebene für das gesamte Bild durchführen und die Spur nicht als ganze Einheit betrachten.
2. Ankerbasierte Methoden
Ankerbasierte Methoden bei der Spurerkennung können in zwei Kategorien unterteilt werden, z. B. linienankerbasierte Methoden und linienankerbasierte Methoden. Auf Linienankern basierende Methoden verwenden vordefinierte Linienanker als Referenzen für regressionsgenaue Fahrspuren. Line-CNN ist eine bahnbrechende Arbeit, die Linien und Akkorde zur Fahrspurerkennung nutzt. LaneATT schlägt einen neuartigen ankerbasierten Aufmerksamkeitsmechanismus vor, der globale Informationen aggregieren kann. Es erzielt Ergebnisse auf dem neuesten Stand der Technik und zeigt eine hohe Wirksamkeit und Effizienz. SGNet führt einen neuartigen Fluchtpunkt-geführten Ankergenerator ein und fügt mehrere Strukturführer hinzu, um die Leistung zu verbessern. Bei der auf Zeilenankern basierenden Methode werden mögliche Zellen für jede vordefinierte Zeile im Bild vorhergesagt. UFLD schlug zunächst eine auf Spurankern basierende Spurerkennungsmethode vor und übernahm ein leichtes Backbone-Netzwerk, um eine hohe Inferenzgeschwindigkeit zu erreichen. Obwohl es einfach und schnell ist, ist die Gesamtleistung nicht gut. CondLaneNet führt eine bedingte Spurerkennungsstrategie ein, die auf bedingter Faltung und einer auf Zeilenankern basierenden Formel basiert. Das heißt, es lokalisiert zuerst den Startpunkt der Spurlinie und führt dann eine auf Zeilenankern basierende Spurerkennung durch. In einigen komplexen Szenarien ist der Ausgangspunkt jedoch schwer zu identifizieren, was zu einer relativ schlechten Leistung führt.
3. Parameterbasierte Methode
Im Gegensatz zur Punktregression verwendet die parameterbasierte Methode Parameter zur Modellierung der Fahrspurkurve und regressiert diese Parameter zur Erkennung der Fahrspur. PolyLaneNet übernimmt das polynomiale Regressionsproblem und erreicht eine hohe Effizienz. LSTR berücksichtigt die Straßenstruktur und die Kameraposition, um die Spurform zu modellieren, und führt dann Transformer in die Spurerkennungsaufgabe ein, um globale Merkmale zu erhalten.
Parameterbasierte Methoden erfordern weniger Parameter für die Regression, reagieren jedoch empfindlich auf Vorhersageparameter. Beispielsweise können falsche Vorhersagen von Koeffizienten höherer Ordnung zu Änderungen der Spurform führen. Obwohl parameterbasierte Methoden eine hohe Inferenzgeschwindigkeit aufweisen, haben sie immer noch Schwierigkeiten, eine höhere Leistung zu erzielen.
Methodischer Überblick über das Cross-Layer Refinement Network (CLRNet)
In diesem Artikel wird ein neues Framework vorgestellt – Cross-Layer Refinement Network (CLRNet), das Low-Level- und High-Level-Funktionen vollständig nutzt Spurerkennungserkennung. Insbesondere werden zunächst hochsemantische Merkmale erkannt, um Fahrspuren grob zu lokalisieren. Verfeinern Sie dann schrittweise die Spurposition und die Merkmalsextraktion basierend auf detaillierten Merkmalen, um hochpräzise Erkennungsergebnisse (d. h. genauere Positionen) zu erhalten. Um das Problem blinder Bereiche in Fahrspuren zu lösen, die visuell nicht erkannt werden können, wird ein ROI-Sammler eingeführt, um mehr globale Kontextinformationen zu erfassen, indem die Beziehung zwischen ROI-Fahrspurmerkmalen und der gesamten Merkmalskarte hergestellt wird. Darüber hinaus wird auch das Kreuzungs-über-Union-Verhältnis IoU von Fahrspurlinien definiert, und es wird vorgeschlagen, dass der Linien-IoU-Verlust (LIoU) die Fahrspur als Ganzes zurückbildet, was die Leistung im Vergleich zum Standardverlust (d. h. glatt) erheblich verbessert -l1 Verlust).
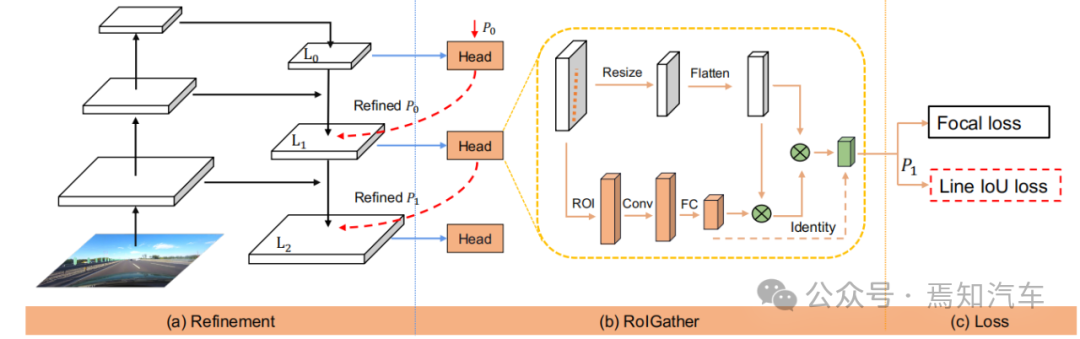
Abbildung 2. Übersicht über CLRNet
Die obige Abbildung zeigt das gesamte Front-End-Netzwerk für die Lane-Line-IoU-Verarbeitung unter Verwendung des in diesem Artikel vorgestellten CLRNet-Algorithmus. Unter anderem generiert das Netzwerk in Abbildung (a) Feature-Maps aus der FPN-Struktur. Anschließend wird jede vorherige Spur von High-Level-Features zu Low-Level-Features verfeinert. Abbildung (b) zeigt, dass jeder Kopf mehr Kontextinformationen nutzt, um frühere Merkmale für die Spur zu erhalten. Abbildung (c) zeigt die Spur vor der Klassifizierung und Regression. Der in diesem Artikel vorgeschlagene Leitungs-IoU-Verlust trägt dazu bei, die Regressionsleistung weiter zu verbessern.
Im Folgenden wird der Arbeitsablauf des in diesem Artikel vorgestellten Algorithmus ausführlicher erläutert.
1. Lane-Netzwerkdarstellung
Wie wir alle wissen, sind die Fahrspuren auf tatsächlichen Straßen dünn und lang. Diese Feature-Darstellung verfügt über starke Form-Priori-Informationen, sodass die vordefinierte Fahrspur-Priorität dem Netzwerk helfen kann, die Fahrspur besser zu lokalisieren. Bei der herkömmlichen Objekterkennung werden Objekte durch rechteckige Kästchen dargestellt. Allerdings eignen sich rechteckige Kästchen jeglicher Art nicht zur Darstellung langer Linien. Dabei werden äquidistante 2D-Punkte als Fahrspurdarstellung verwendet. Konkret wird eine Fahrspur als Folge von Punkten dargestellt, d. h. P = {(x1, y1), ···,(xN , yN )}. Die Y-Koordinaten der Punkte werden gleichmäßig in der vertikalen Richtung des Bildes abgetastet, d. h. 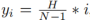 , wobei H die Bildhöhe ist. Daher ist die x-Koordinate mit dem entsprechenden
, wobei H die Bildhöhe ist. Daher ist die x-Koordinate mit dem entsprechenden 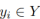 verknüpft, und diese Darstellung wird hier als „Lane-first“ bezeichnet. Jede vorherige Spur wird vom Netzwerk vorhergesagt und besteht aus vier Teilen:
verknüpft, und diese Darstellung wird hier als „Lane-first“ bezeichnet. Jede vorherige Spur wird vom Netzwerk vorhergesagt und besteht aus vier Teilen:
(1) Vordergrund- und Hintergrundwahrscheinlichkeiten.
(2) Die Spurlänge hat Vorrang.
(3) Der Winkel zwischen dem Startpunkt der Spurlinie und der x-Achse der vorherigen Spur (genannt x, y und θ).
(4) N Offsets, also der horizontale Abstand zwischen der Vorhersage und ihrem wahren Wert.
2. Motivation zur schichtübergreifenden Verfeinerung
In neuronalen Netzen zeigen tiefe Merkmale auf hoher Ebene ein stärkeres Feedback zu Straßenzielen mit mehr semantischen Merkmalen, während flache Merkmale auf niedriger Ebene mehr lokale Kontextinformationen aufweisen. Algorithmen, die Fahrspurobjekten den Zugriff auf übergeordnete Funktionen ermöglichen, können dazu beitragen, nützlichere Kontextinformationen zu nutzen, beispielsweise die Unterscheidung von Fahrspurlinien oder Orientierungspunkten. Gleichzeitig helfen feine Detailfunktionen dabei, Fahrspuren mit hoher Positionierungsgenauigkeit zu erkennen. Bei der Objekterkennung wird eine Feature-Pyramide erstellt, um die Pyramidenform der ConvNet-Feature-Hierarchie auszunutzen, und Objekte unterschiedlichen Maßstabs verschiedenen Pyramidenebenen zugewiesen. Es ist jedoch schwierig, eine Spur direkt nur einer Ebene zuzuordnen, da sowohl Funktionen auf hoher als auch auf niedriger Ebene für die Spur von entscheidender Bedeutung sind. Inspiriert durch Cascade RCNN können Fahrspurobjekte allen Ebenen zugeordnet und einzelne Fahrspuren nacheinander erkannt werden.
Insbesondere Fahrspuren mit erweiterten Funktionen können erkannt werden, um Fahrspuren grob zu lokalisieren. Basierend auf den erkannten bekannten Fahrspuren können detailliertere Merkmale verwendet werden, um diese zu verfeinern.
3. Verfeinerte Struktur
Das Ziel des gesamten Algorithmus besteht darin, die Pyramiden-Feature-Hierarchie von ConvNet (mit Semantik von Low-Level bis High-Level) auszunutzen und eine Feature-Pyramide aufzubauen, die immer hoch ist Semantik auf -Ebene. Das Restnetzwerk ResNet wird als Rückgrat verwendet und {L0, L1, L2} wird zur Darstellung der von FPN generierten Funktionsebenen verwendet.
Wie in Abbildung 2 dargestellt, beginnt die schichtübergreifende Verfeinerung auf der höchsten Ebene L0 und nähert sich allmählich L2. Die entsprechende Verfeinerung wird durch die Verwendung von {R0,R1,R2} dargestellt. Anschließend können Sie mit dem Aufbau einer Reihe verfeinerter Strukturen fortfahren:
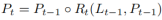
wobei t = 1, · · · , T, T die Gesamtzahl der Verfeinerungen ist.
Die gesamte Methode führt die Erkennung von der höchsten Ebene aus mit hoher Semantik durch. Pt ist der Parameter der Spur vor (Startpunktkoordinaten x, y und Winkel θ), der inspiriert und selbstlernend ist. Für die erste Schicht L0 ist P0 gleichmäßig auf der Bildebene verteilt. Die Ausdünnung von Rt verwendet Pt als Eingabe, um die ROI-Spurmerkmale zu erhalten, und führt dann zwei FC-Schichten aus, um die Ausdünnungsparameter Pt zu erhalten. Die schrittweise Verfeinerung der Spurvorinformationen und die Extraktion von Merkmalsinformationen sind für die schichtübergreifende Verfeinerung sehr wichtig. Beachten Sie, dass diese Methode nicht auf FPN-Strukturen beschränkt ist, sondern auch nur die Verwendung von ResNet oder die Übernahme von PAFPN geeignet ist.
4. ROI-Erfassung
Nachdem jeder Feature-Map Fahrspur-Prioritätsinformationen zugewiesen wurden, kann das ROI-Align-Modul verwendet werden, um Fahrspur-Prioritätsmerkmale zu erhalten. Allerdings sind die Kontextinformationen zu diesen Funktionen noch unzureichend. In einigen Fällen können Fahrspurinstanzen bei extremen Lichtverhältnissen belegt oder verdeckt sein. In diesem Fall liegen möglicherweise keine lokalen visuellen Echtzeit-Verfolgungsdaten vor, die das Vorhandensein der Fahrspur anzeigen. Um festzustellen, ob ein Pixel zu einer Fahrspur gehört, muss man sich nahegelegene Merkmale ansehen. Einige neuere Untersuchungen haben auch gezeigt, dass die Leistung verbessert werden kann, wenn Remote-Abhängigkeiten vollständig ausgenutzt werden. Daher können nützlichere Kontextinformationen gesammelt werden, um Fahrspurmerkmale besser zu lernen.
Zu diesem Zweck werden zunächst Faltungsberechnungen entlang der Spur durchgeführt, sodass jedes Pixel in der Spur zuvor Informationen von benachbarten Pixeln sammeln kann und der belegte Teil basierend auf diesen Informationen verbessert werden kann. Darüber hinaus wird die Beziehung zwischen den Fahrspur-Prioritätsmerkmalen und der gesamten Merkmalskarte hergestellt. Daher können mehr Kontextinformationen genutzt werden, um bessere Merkmalsdarstellungen zu lernen.
Die gesamte Struktur des ROI-Erfassungsmoduls ist leichtgewichtig und einfach zu implementieren. Da Feature-Maps und Lane-Prioritäten als Eingabe verwendet werden, verfügt jede Lane-Priorität über N Punkte. Anders als bei der ROI-Ausrichtung des Begrenzungsrahmens ist es für jede Spur-Vorinformationserfassung erforderlich, zunächst die Spur-Vor-ROI-Merkmale (Xp ∈ RC×Np) gemäß der ROI-Ausrichtung zu erhalten. Abtasten Sie Np-Punkte gleichmäßig von der vorherigen Fahrspur und berechnen Sie mithilfe der bilinearen Interpolation die genauen Werte der Eingabemerkmale an diesen Standorten. Für die ROI-Features von L1 und L2 kann die Feature-Darstellung durch Verbinden der ROI-Features der vorherigen Ebenen verbessert werden. Die nahegelegenen Merkmale jedes Fahrspurpixels können durch Faltung der extrahierten ROI-Merkmale erfasst werden. Um Speicher zu sparen, wird hier die vollständige Verbindung verwendet, um Lane-Prior-Features (Xp ∈ RC×1) weiter zu extrahieren, wobei die Größe der Feature-Map angepasst wird. Sie kann weiterhin auf Xf∈ abgeflacht werden RC×HW. Um die globalen Kontextinformationen der Fahrspur mit früheren Merkmalen zu sammeln, muss zunächst die Aufmerksamkeitsmatrix W zwischen den früheren ROI-Fahrspurmerkmalen (Xp) und der geschriebenen globalen Merkmalskarte (Xf) berechnet werden als:
wobei f die Normalisierungsfunktion soft max ist. Die aggregierten Merkmale können wie folgt geschrieben werden:
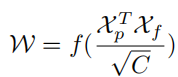
Die Ausgabe G spiegelt den Überlagerungswert von Xf auf Xp wider, der aus allen Positionen von Xf ausgewählt wird. Abschließend wird die Ausgabe zur ursprünglichen Eingabe Xp addiert.
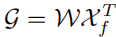
Abbildung 3. Darstellung der Aufmerksamkeitsgewichte in ROIGather
5. Fahrspurlinienschnittpunkt und Vereinigungsverhältnis-IoU-Verlust
Wie oben erwähnt besteht der Fahrspurprior aus diskreten Punkten, die auf ihre Grundwahrheit zurückgeführt werden müssen. Zur Regression dieser Punkte können gängige Distanzverluste wie Smooth-L1 verwendet werden. Dieser Verlust behandelt Punkte jedoch als separate Variablen, was eine zu stark vereinfachte Annahme darstellt und zu einer weniger genauen Regression führt.
Im Gegensatz zum Distanzverlust kann Intersection over Union (IoU) Fahrspurprioren als ganze Einheit zurückbilden und ist auf die Bewertungsmetrik zugeschnitten. Hier wird ein einfacher und effizienter Algorithmus abgeleitet, um den Line over Union (LIoU)-Verlust zu berechnen.Wie in der Abbildung unten gezeigt, können der Linienschnittpunkt und das Vereinigungsverhältnis IoU berechnet werden, indem der IoU des erweiterten Segments entsprechend der abgetasteten XI-Position integriert wird. Abbildung 4: Linien-IoU-Diagramm Wechselwirkung zwischen zwei Liniensegmenten und das Verhältnis der Vereinigung. Erweitern Sie jeden Punkt in der vorhergesagten Spur, wie in Abbildung 4 dargestellt, zunächst (x
pi
) in ein Liniensegment mit dem Radius e. Dann kann die IoU zwischen dem erweiterten Liniensegment und seiner Grundwahrheit berechnet werden, geschrieben als:
wobei xpi - e, xpi + e der Erweiterungspunkt von xpi i + e der entsprechende Groundtruth-Punkt ist. Beachten Sie, dass d0i negativ sein kann, was eine effiziente Informationsoptimierung im Fall nicht überlappender Liniensegmente ermöglicht. Dann kann LIoU als eine Kombination unendlicher Linienpunkte betrachtet werden. Um den Ausdruck zu vereinfachen und die Berechnung zu erleichtern, wandeln Sie ihn in die diskrete Form um überlappen sich perfekt, dann ist LIoU = 1. Wenn die beiden Linien weit voneinander entfernt sind, konvergiert LIoU gegen -1. Die Berechnung der Spurlinienkorrelation durch Linien-IoU-Verlust hat zwei Vorteile: (1) Sie ist einfach und differenzierbar und lässt sich leicht parallel berechnen. (2) Es prognostiziert die Spur als Ganzes, was zur Verbesserung der Gesamtleistung beiträgt.
6. Trainings- und Inferenzdetails
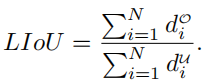
Zuerst wird eine Vorwärtsprobenauswahl durchgeführt.
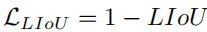
Während des Trainingsprozesses werden jeder Ground-Truth-Lane dynamisch eine oder mehrere vorhergesagte Lanes als positive Stichprobe zugewiesen. Insbesondere werden die Vorhersagespuren nach den Zuordnungskosten sortiert, die wie folgt definiert sind:
wobei Ccls die Fokuskosten zwischen der Vorhersage und dem Etikett sind. Csim sind die Ähnlichkeitskosten zwischen der vorhergesagten Spur und der realen Spur. Es besteht aus drei Teilen. Cdis stellt den durchschnittlichen Pixelabstand aller gültigen Spurpunkte dar, Cxy stellt den Abstand der Startpunktkoordinaten dar und Ctheta stellt die Differenz im Theta-Winkel dar. Sie sind alle auf [0, 1] normiert. wcls und wsim sind die Gewichtskoeffizienten jeder definierten Komponente. Jeder Ground-Truth-Lane wird gemäß Cassign eine dynamische Anzahl (top-k) vorhergesagter Lanes zugewiesen.
Zweitens gibt es den Trainingsausfall.
Der Trainingsverlust umfasst Klassifizierungsverlust und Regressionsverlust, wobei der Regressionsverlust nur für bestimmte Stichproben berechnet wird. Die Gesamtverlustfunktion ist definiert als:
Lcls ist der Fokusverlust zwischen Vorhersagen und Beschriftungen, Lxytl ist der Smooth-l1-Verlust für die Regression von Startpunktkoordinaten, Theta-Winkel und Spurlänge, LLIoU ist zwischen Vorhersagespuren und Grundwahrheit des Leitungs-IoU-Verlusts. Durch das Hinzufügen eines zusätzlichen Segmentierungsverlusts wird dieser nur während des Trainings verwendet und verursacht keine Inferenzkosten.
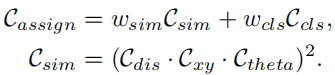
Zusammenfassung
In diesem Artikel haben wir ein Cross-Layer Refinement Network (CLRNet) für die Spurerkennung vorgeschlagen. CLRNet kann High-Level-Funktionen nutzen, um Fahrspuren vorherzusagen, und gleichzeitig lokale Detailfunktionen nutzen, um die Lokalisierungsgenauigkeit zu verbessern. Um das Problem unzureichender visueller Beweise für das Vorhandensein einer Fahrspur zu lösen, wird vorgeschlagen, die Darstellung von Fahrspurmerkmalen zu verbessern, indem mithilfe von ROIGather Beziehungen zu allen Pixeln hergestellt werden. Um Fahrspuren als Ganzes zu regressieren, wird ein auf die Fahrspurerkennung zugeschnittener Linien-IoU-Verlust vorgeschlagen, der die Leistung im Vergleich zum Standardverlust (d. h. Smooth-l1-Verlust) erheblich verbessert. Die vorliegende Methode wird anhand von drei Benchmark-Datensätzen zur Spurerkennung bewertet, nämlich CULane, LLamas und Tusimple. Die vorgeschlagene Methode übertrifft andere hochmoderne Methoden (CULane, Tusimple und LLAMAS) bei drei Fahrspurerkennungs-Benchmarks deutlich.
Das obige ist der detaillierte Inhalt vonCLRNet: Ein hierarchisch verfeinerter Netzwerkalgorithmus zur autonomen Fahrspurerkennung. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!