
Heim >Technologie-Peripheriegeräte >KI >Verstehen Sie in einem Artikel: die Zusammenhänge und Unterschiede zwischen KI, maschinellem Lernen und Deep Learning
Verstehen Sie in einem Artikel: die Zusammenhänge und Unterschiede zwischen KI, maschinellem Lernen und Deep Learning

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBnach vorne
- 2024-03-02 11:19:301500Durchsuche
In der heutigen Welle rasanter technologischer Veränderungen sind Künstliche Intelligenz (KI), Maschinelles Lernen (ML) und Deep Learning (DL) wie helle Sterne und führen die neue Welle der Informationstechnologie an. Diese drei Wörter tauchen häufig in verschiedenen hochaktuellen Diskussionen und praktischen Anwendungen auf, doch für viele Entdecker, die neu auf diesem Gebiet sind, sind ihre spezifische Bedeutung und ihre internen Zusammenhänge möglicherweise noch immer rätselhaft.
Dann schauen wir uns zunächst dieses Bild an.

Es ist ersichtlich, dass zwischen Deep Learning, maschinellem Lernen und künstlicher Intelligenz ein enger Zusammenhang und eine fortschreitende Beziehung besteht. Deep Learning ist ein spezifischer Bereich des maschinellen Lernens, der ein wichtiger Bestandteil der künstlichen Intelligenz ist. Die Verbindungen und die gegenseitige Förderung dieser Bereiche ermöglichen die kontinuierliche Weiterentwicklung und Verbesserung der Technologie der künstlichen Intelligenz.
Was ist künstliche Intelligenz?
Künstliche Intelligenz (KI) ist ein umfassendes Konzept, dessen Hauptziel darin besteht, Computersysteme zu entwickeln, die die menschliche Intelligenz simulieren, erweitern oder sogar übertreffen können. Es gibt spezifische Anwendungen in vielen Bereichen, wie zum Beispiel:
- Bilderkennung (Bilderkennung) ist ein wichtiger Zweig der KI, der sich der Untersuchung widmet, wie Computer in die Lage versetzt werden können, Daten über visuelle Sensoren zu erhalten und diese Daten anhand dieser Daten zu analysieren, um Bilder zu identifizieren in Bildern simulieren Objekte, Szenen, Verhaltensweisen und andere Informationen den Erkennungs- und Verständnisprozess visueller Signale durch das menschliche Auge und Gehirn.
- Natural Language Processing (NLP) ist die Fähigkeit von Computern, menschliche natürliche Sprache zu verstehen und zu erzeugen. Sie deckt eine Vielzahl von Aufgaben wie Textklassifizierung, semantische Analyse, maschinelle Übersetzung usw. ab und zielt darauf ab, menschliche Fähigkeiten im Zuhören zu simulieren. Sprechen, Lesen und Schreiben usw. intelligentes Verhalten.
- Computer Vision (CV) umfasst Bilderkennung im weiteren Sinne. Es umfasst auch viele Aspekte wie Bildanalyse, Videoanalyse und dreidimensionale Rekonstruktion. Ziel ist es, Computern das „Sehen“ und Erkennen von Bildern aus zweidimensionalen Bereichen zu ermöglichen oder dreidimensionale Bilder. Die Welt zu verstehen ist eine tiefe Nachahmung des menschlichen visuellen Systems.
- Knowledge Graph (KG) ist ein strukturiertes Datenmodell, das zum Speichern und Darstellen von Entitäten und ihren komplexen Beziehungen untereinander verwendet wird. Es simuliert die Fähigkeit des Menschen, Wissen im kognitiven Prozess anzusammeln und zu nutzen auf vorhandenem Wissen.
Diese High-End-Technologien werden rund um das Kernkonzept der „Simulation menschlicher Intelligenz“ erforscht und angewendet. Sie konzentrieren sich auf die Entwicklung verschiedener Wahrnehmungsdimensionen (wie Sehen, Hören, Denklogik usw.) und fördern gemeinsam die kontinuierliche Entwicklung und den Fortschritt der Technologie der künstlichen Intelligenz.
Was ist maschinelles Lernen?
Maschinelles Lernen (ML) ist ein entscheidender Zweig im Bereich der künstlichen Intelligenz (KI). Mithilfe verschiedener Algorithmen können Computersysteme automatisch Regeln und Muster aus Daten lernen, um Vorhersagen und Entscheidungen zu treffen und so die Fähigkeiten der menschlichen Intelligenz zu verbessern und zu erweitern.
Beim Training eines Katzenerkennungsmodells läuft der maschinelle Lernprozess beispielsweise wie folgt ab:
- Datenvorverarbeitung: Zunächst wird eine große Anzahl gesammelter Katzen- und Nichtkatzenbilder vorverarbeitet, einschließlich Skalierung, Graustufen, Normalisierung und anderen Vorgängen werden durchgeführt und das Bild wird in eine Merkmalsvektordarstellung umgewandelt. Diese Merkmale können aus manuell entwickelten Merkmalsextraktionstechniken stammen, wie z. B. Haar-ähnlichen Merkmalen, lokalen binären Mustern (LBP) oder anderen häufig verwendeten Merkmalsdeskriptoren im Bereich Computer Vision .
- Merkmalsauswahl und Dimensionsreduzierung: Wählen Sie Schlüsselmerkmale entsprechend den Merkmalen des Problems aus, entfernen Sie redundante und irrelevante Informationen und verwenden Sie manchmal PCA, LDA und andere Methoden zur Dimensionsreduzierung, um die Merkmalsdimensionen weiter zu reduzieren und die Algorithmuseffizienz zu verbessern.
- Modelltraining: Verwenden Sie dann den vorverarbeiteten beschrifteten Datensatz, um das ausgewählte Modell für maschinelles Lernen zu trainieren, und optimieren Sie die Modellleistung, indem Sie die Modellparameter so anpassen, dass das Modell anhand der Merkmale Katzen von Nicht-Katzen unterscheiden kann.
- Modellbewertung und -validierung: Nach Abschluss des Trainings wird das Modell mithilfe eines unabhängigen Testsatzes bewertet, um sicherzustellen, dass das Modell über eine gute Generalisierungsfähigkeit verfügt und genau auf neue, unbekannte Proben angewendet werden kann.
Die 10 am häufigsten verwendeten Algorithmen für maschinelles Lernen sind: Entscheidungsbaum, Random Forest, logistische Regression, SVM, Naive Bayes, K-Nearest-Neighbor-Algorithmus, K-Means-Algorithmus, Adaboost-Algorithmus, neuronales Netzwerk, Markov usw.
Was ist Deep Learning?
Deep Learning (DL) ist eine spezielle Form des maschinellen Lernens. Es simuliert die Art und Weise, wie das menschliche Gehirn Informationen durch eine tiefe neuronale Netzwerkstruktur verarbeitet und dadurch automatisch komplexe Merkmalsdarstellungen aus den Daten extrahiert.
Beim Training eines Katzenerkennungsmodells läuft der Deep-Learning-Prozess beispielsweise wie folgt ab:
(1) Datenvorverarbeitung und -vorbereitung:
- Eine große Anzahl von Datensätzen mit Katzen- und Nichtkatzenbildern sammeln und ausführen Reinigen und beschriften Sie. Achten Sie dabei darauf, dass jedes Bild mit einer entsprechenden Beschriftung versehen ist (z. B. „Katze“ oder „keine Katze“).
- Bildvorverarbeitung: Passen Sie alle Bilder auf eine einheitliche Größe an, führen Sie eine Normalisierungsverarbeitung, Datenverbesserung und andere Vorgänge durch.
(2) Modelldesign und -bau:
- Wählen Sie eine Deep-Learning-Architektur. Für Bilderkennungsaufgaben wird normalerweise Convolutional Neural Network (CNN) verwendet. CNN kann lokale Merkmale von Bildern effektiv extrahieren und sie durch mehrschichtige Strukturen abstrahieren.
- Erstellen Sie Modellschichten, einschließlich Faltungsschichten (zur Merkmalsextraktion), Pooling-Schichten (um Berechnungen zu reduzieren und Überanpassung zu verhindern), vollständig verbundene Schichten (zur Integration und Klassifizierung von Merkmalen) und mögliche Stapelnormalisierungsschichten, Aktivierungsfunktionen (wie ReLU, Sigma usw.).
(3) Initialisierungsparameter und Festlegen von Hyperparametern:
- Initialisieren Sie die Gewichte und Verzerrungen jeder Schicht im Modell. Sie können eine zufällige Initialisierung oder eine bestimmte Initialisierungsstrategie verwenden.
- Legen Sie Hyperparameter wie Lernrate, Optimierer (wie SGD, Adam usw.), Stapelgröße, Trainingszeitraum (Epoche) usw. fest.
(4) Vorwärtsausbreitung:
- Geben Sie das vorverarbeitete Bild in das Modell ein, und durch Faltung, Pooling, lineare Transformation und andere Operationen jeder Schicht wird schließlich die vorhergesagte Wahrscheinlichkeitsverteilung der Ausgabeschicht erhalten Das heißt, das Modell bestimmt die Wahrscheinlichkeit, dass das Eingabebild eine Katze ist.
(5) Verlustfunktion und Backpropagation:
- Verwenden Sie die Kreuzentropie-Verlustfunktion oder eine andere geeignete Verlustfunktion, um den Unterschied zwischen den Modellvorhersageergebnissen und der wahren Bezeichnung zu messen.
- Führen Sie nach der Berechnung des Verlusts den Backpropagation-Algorithmus aus, um den Gradienten des Verlusts in Bezug auf die Modellparameter zu berechnen und die Parameter zu aktualisieren.
(6) Optimierung und Parameteraktualisierung:
- Verwenden Sie Gradientenabstiegs- oder andere Optimierungsalgorithmen, um Modellparameter basierend auf Gradienteninformationen anzupassen, mit dem Ziel, die Verlustfunktion zu minimieren.
- Während jeder Trainingsiteration lernt das Modell weiter und passt Parameter an, wodurch seine Fähigkeit, Katzenbilder zu erkennen, schrittweise verbessert wird.
(7) Verifizierung und Bewertung:
- Bewerten Sie regelmäßig die Modellleistung im Verifizierungssatz, überwachen Sie Änderungen in Genauigkeit, Präzision, Rückruf und anderen Indikatoren, um die Hyperparameteranpassung und das frühe Lernen während des Modelltrainings zu steuern.
(8) Abschluss und Test des Trainings:
- Wenn sich die Leistung des Modells im Validierungssatz stabilisiert oder die voreingestellten Stoppbedingungen erreicht, beenden Sie das Training.
- Bewerten Sie abschließend die Generalisierungsfähigkeit des Modells anhand eines unabhängigen Testsatzes, um sicherzustellen, dass das Modell Katzen anhand neuer, unsichtbarer Proben effektiv identifizieren kann.
Der Unterschied zwischen Deep Learning und maschinellem Lernen
Der Unterschied zwischen Deep Learning und maschinellem Lernen ist:
1. Methode zur Lösung des Problems
Maschinelle Lernalgorithmen basieren normalerweise auf von Menschen entworfenem Feature Engineering, d. h. vorab -Extraktion basierend auf dem Hintergrundwissen des Problems Schlüsselmerkmale, und erstellen Sie dann ein Modell basierend auf diesen Merkmalen und führen Sie Optimierungslösungen durch.
Deep Learning verwendet eine End-to-End-Lernmethode, die durch mehrschichtige nichtlineare Transformation automatisch abstrakte Merkmale auf hoher Ebene generiert. Diese Merkmale werden während des gesamten Trainingsprozesses kontinuierlich optimiert. Es ist nicht erforderlich, Merkmale manuell auszuwählen und zu erstellen , der dem kognitiven Verarbeitungsstil des Gehirns näher kommt.
Wenn Sie beispielsweise eine Software zur Erkennung eines Autos schreiben möchten und maschinelles Lernen verwenden, müssen Sie die Eigenschaften des Autos, wie Größe und Form, manuell extrahieren, und wenn Sie Deep Learning verwenden, dann künstliche Intelligenz Das neuronale Netzwerk extrahiert diese Merkmale selbst, zum Lernen ist jedoch eine große Anzahl von Bildern erforderlich, die als Autos gekennzeichnet sind.
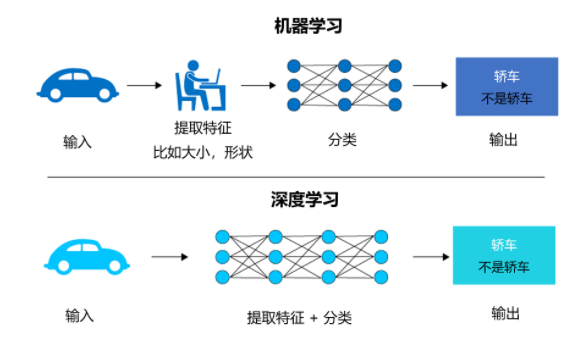
2. Anwendungsszenarien
Die Anwendung von maschinellem Lernen in den Bereichen Fingerabdruckerkennung, Erkennung charakteristischer Objekte und anderen Bereichen hat grundsätzlich die Anforderungen der Kommerzialisierung erfüllt.
Deep Learning wird hauptsächlich in den Bereichen Texterkennung, Gesichtstechnologie, semantische Analyse, intelligente Überwachung und anderen Bereichen eingesetzt. Derzeit wird es auch in intelligenten Hardware-, Bildungs-, Medizin- und anderen Branchen rasch eingesetzt.
3. Erforderliche Datenmenge
Maschinelle Lernalgorithmen können auch bei einigen einfachen Aufgaben oder Problemen, bei denen Funktionen leicht zu extrahieren sind, zufriedenstellende Ergebnisse erzielen.
Deep Learning erfordert normalerweise eine große Menge an annotierten Daten, um tiefe neuronale Netze zu trainieren. Sein Vorteil besteht darin, dass es komplexe Muster und Darstellungen direkt aus den Originaldaten lernen kann, insbesondere wenn die Datengröße zunimmt ist bedeutsamer.
4. Ausführungszeit
Während der Trainingsphase ist der Trainingsprozess aufgrund der mehreren Schichten von Deep-Learning-Modellen und der großen Anzahl von Parametern oft zeitaufwändig und erfordert die Unterstützung von Hochleistungsrechnerressourcen, wie z GPU-Cluster.
Im Vergleich dazu haben Algorithmen für maschinelles Lernen (insbesondere die leichtgewichtigen Modelle) normalerweise einen geringeren Trainingszeit- und Rechenressourcenbedarf und eignen sich besser für schnelle Iteration und experimentelle Verifizierung.
Das obige ist der detaillierte Inhalt vonVerstehen Sie in einem Artikel: die Zusammenhänge und Unterschiede zwischen KI, maschinellem Lernen und Deep Learning. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Was müssen Sie über die künstliche Intelligenz von Python lernen?
- Was ist die fortschrittlichste Form der künstlichen Intelligenz der Zukunft?
- Der Zukunftstrend der künstlichen Intelligenz
- Turing-Preisträger Geoffrey Hinton: Meine fünfzigjährige Deep-Learning-Karriere und meine Forschungsmethoden
- Deep Learning hat eine neue Gefahr! Die University of Sydney schlägt eine neue modalübergreifende Aufgabe vor, bei der Text als Leitfaden für den Bildausschnitt verwendet wird