
Heim >Technologie-Peripheriegeräte >KI >Bekämpfen Sie das Problem der „konzeptionellen Eleganz'! Google veröffentlicht neues Zeitwahrnehmungs-Framework: Bilderkennungsgenauigkeit um 15 % erhöht
Bekämpfen Sie das Problem der „konzeptionellen Eleganz'! Google veröffentlicht neues Zeitwahrnehmungs-Framework: Bilderkennungsgenauigkeit um 15 % erhöht

- 王林nach vorne
- 2024-03-02 12:04:02700Durchsuche
In der maschinellen Lernforschung war Konzeptdrift schon immer ein heikles Problem. Es bezieht sich auf Änderungen in der Datenverteilung im Laufe der Zeit, die zu einer Beeinträchtigung der Wirksamkeit des Modells führen. Diese Situation zwingt Forscher dazu, Modelle ständig anzupassen, um sie an neue Datenverteilungen anzupassen. Der Schlüssel zur Lösung des Problems der Konzeptdrift liegt in der Entwicklung von Algorithmen, die Änderungen in den Daten rechtzeitig erkennen und anpassen können. Ein offensichtliches Beispiel ist die Bildanzeige des nichtstationären Lernbenchmarks CLEAR, die die signifikanten Änderungen in den Daten aufzeigt visuelle Eigenschaften von Objekten im letzten Jahrzehnt verändert.
Dieses Phänomen wird als „langsame Konzeptdrift“ bezeichnet und stellt eine große Herausforderung für Objektklassifizierungsmodelle dar. Da sich das Aussehen oder die Eigenschaften von Objekten im Laufe der Zeit ändern, steht die Frage im Mittelpunkt der Forschung, wie sichergestellt werden kann, dass sich das Modell an diese Änderung anpassen und weiterhin korrekt klassifizieren kann.
Angesichts dieser Herausforderung schlug das Google AI-Forschungsteam kürzlich eine optimierungsgesteuerte Methode namens MUSCATEL (Multi-Scale Temporal Learning) vor, die die Leistung des Modells bei großen und sich ändernden Daten erfolgreich verbesserte. Dieses Forschungsergebnis wurde auf der AAAI2024 veröffentlicht. 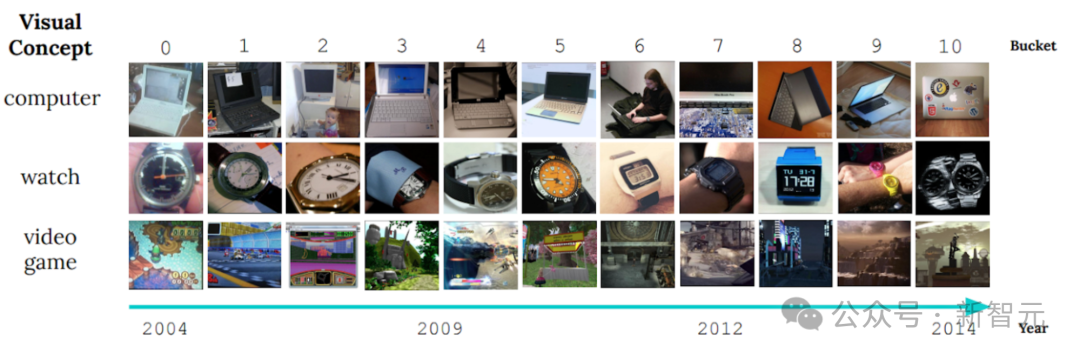
Papieradresse: https://arxiv.org/abs/2212.05908
Die gängigen Methoden zur Wahrscheinlichkeitsdrift sind derzeit Online-Lernen und kontinuierliches Lernen (online und kontinuierliches Lernen).
Das Hauptkonzept dieser Methoden besteht darin, das Modell kontinuierlich zu aktualisieren, um es an die neuesten Daten anzupassen und so die Wirksamkeit des Modells sicherzustellen. Dieser Ansatz steht jedoch vor zwei großen Herausforderungen.
Diese Methoden konzentrieren sich oft nur auf die neuesten Daten und ignorieren die wertvollen Informationen, die in früheren Daten enthalten sind. Darüber hinaus gehen sie davon aus, dass der Beitrag aller Dateninstanzen im Laufe der Zeit gleichmäßig abnimmt, was nicht mit der tatsächlichen Situation übereinstimmt. Die
MUSCATEL-Methode kann diese Probleme effektiv lösen. Sie weist Trainingsinstanzen Wichtigkeitswerte zu und optimiert die Leistung des Modells in zukünftigen Instanzen.
Zu diesem Zweck führten die Forscher ein Hilfsmodell ein, das Instanzen und deren Alter kombiniert, um Scores zu generieren. Das Hilfsmodell und das Hauptmodell lernen gemeinsam, zwei Kernprobleme zu lösen.
Diese Methode weist in praktischen Anwendungen eine hervorragende Leistung auf. In einem groß angelegten Experiment mit realen Datensätzen, das 39 Millionen Fotos umfasste und über 9 Jahre dauerte, erhöhte sich die Genauigkeit im Vergleich zu anderen Basismethoden des stationären Lernens um 15 %. .
Gleichzeitig zeigt es auch in zwei instationären Lerndatensätzen und kontinuierlichen Lernumgebungen bessere Ergebnisse als die SOTA-Methode.
Herausforderungen des Konzeptdrifts zum überwachten Lernen
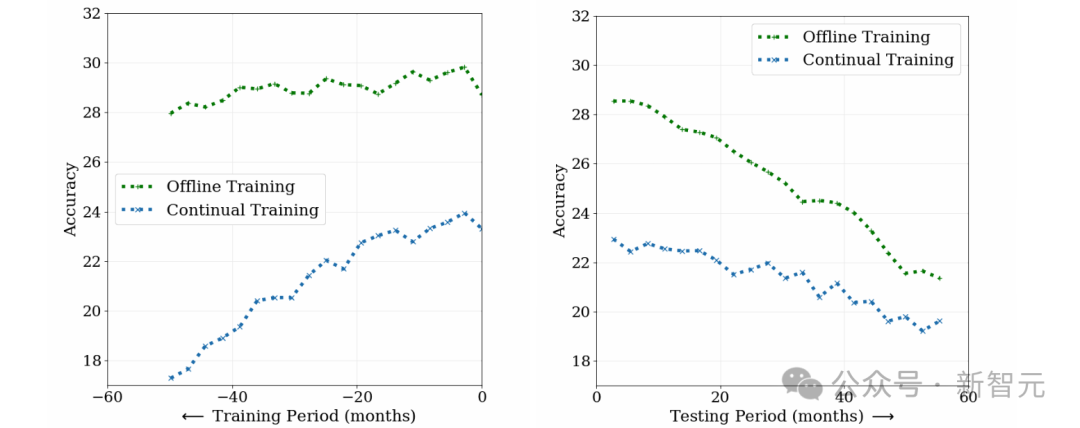
Um die Herausforderungen des Konzeptdrifts zum überwachten Lernen zu untersuchen, verglichen Forscher Offline-Training (Offline-Training) und kontinuierliches Training (Weiterbildung) in der Fotoklassifizierungsmethode unter Verwendung von etwa 39 Millionen Social-Media-Fotos aus einem Zeitraum von 10 Jahren.
Wie in der folgenden Abbildung dargestellt, ist die anfängliche Leistung des Offline-Trainingsmodells zwar hoch, die Genauigkeit nimmt jedoch mit der Zeit ab und das Verständnis früher Daten wird aufgrund des katastrophalen Vergessens verringert.
Im Gegenteil: Obwohl die anfängliche Leistung des kontinuierlichen Trainingsmodells geringer ist, ist es weniger abhängig von alten Daten und lässt während des Tests schneller nach.
Dies zeigt, dass sich die Daten mit der Zeit weiterentwickeln und die Anwendbarkeit der beiden Modelle abnimmt. Konzeptdrift stellt eine Herausforderung für überwachtes Lernen dar, das eine kontinuierliche Aktualisierung des Modells erfordert, um sich an Datenänderungen anzupassen.
MUSCATEL
MUSCATEL ist ein innovativer Ansatz, der das Problem der langsamen Konzeptdrift lösen soll. Ziel ist es, den Leistungsabfall des Modells in Zukunft zu reduzieren, indem die Vorteile von Offline-Lernen und kontinuierlichem Lernen geschickt kombiniert werden.
Angesichts riesiger Trainingsdaten zeigt MUSCATEL seinen einzigartigen Charme. Es basiert nicht nur auf traditionellem Offline-Lernen, sondern regelt und optimiert auf dieser Grundlage auch sorgfältig die Auswirkungen vergangener Daten und legt so eine solide Grundlage für die zukünftige Leistung des Modells.
Um die Leistung des Hauptmodells bei neuen Daten weiter zu verbessern, führt MUSCATEL ein Hilfsmodell ein.
Basierend auf den Optimierungszielen in der Abbildung unten weist das Trainingshilfsmodell jedem Datenpunkt basierend auf seinem Inhalt und Alter Gewichte zu. Dieses Design ermöglicht es dem Modell, sich besser an Änderungen in zukünftigen Daten anzupassen und kontinuierliche Lernfähigkeiten aufrechtzuerhalten.

Um das Hilfsmodell und das Hauptmodell gemeinsam weiterzuentwickeln, wendet MUSCATEL auch eine Meta-Lernstrategie an.
Der Schlüssel zu dieser Strategie besteht darin, den Beitrag von Probeninstanzen und Alter effektiv zu trennen und die Gewichte durch die Kombination mehrerer fester Abklingzeitskalen festzulegen, wie in der folgenden Abbildung dargestellt.
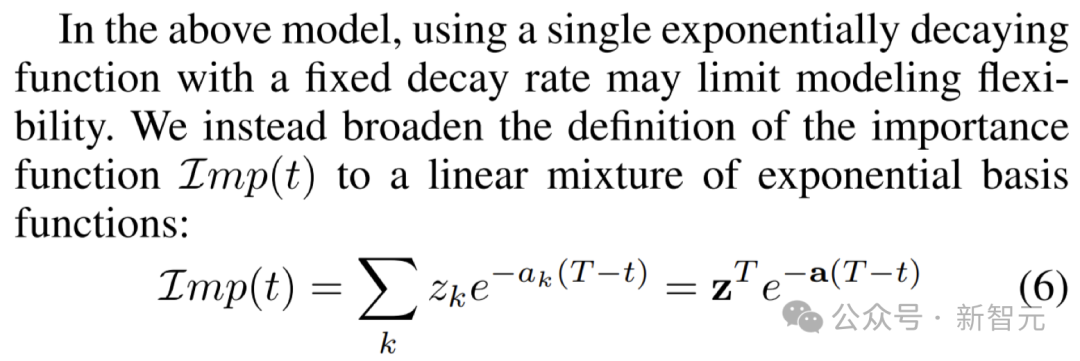
Darüber hinaus lernt MUSCATEL, jede Instanz auf die am besten geeignete Zeitskala zu „verteilen“, um ein präziseres Lernen zu ermöglichen.
Instanzgewichtsbewertung
Wie in der folgenden Abbildung gezeigt, hat das erlernte Hilfsmodell bei der CLEAR-Objekterkennungsherausforderung das Gewicht von Objekten erfolgreich angepasst: Das Gewicht von Objekten mit neuem Erscheinungsbild nahm zu und das Gewicht von Objekten mit altem Aussehen vermindert.

Durch die Gradienten-basierte Bewertung der Merkmalswichtigkeit kann festgestellt werden, dass sich das Hilfsmodell unabhängig vom Alter der Instanz auf das Motiv im Bild und nicht auf den Hintergrund oder die Merkmale konzentriert, was seine Wirksamkeit demonstriert.

Ein bedeutender Durchbruch bei der groß angelegten Fotoklassifizierungsaufgabe
Die groß angelegte Fotoklassifizierungsaufgabe (PCAT) wurde anhand des YFCC100M-Datensatzes untersucht, wobei die Daten der ersten fünf Jahre als verwendet wurden Trainingssatz und die Daten der letzten fünf Jahre als Testsatz.
Im Vergleich zu ungewichteten Basislinien und anderen robusten Lerntechniken zeigt die MUSCATEL-Methode offensichtliche Vorteile.
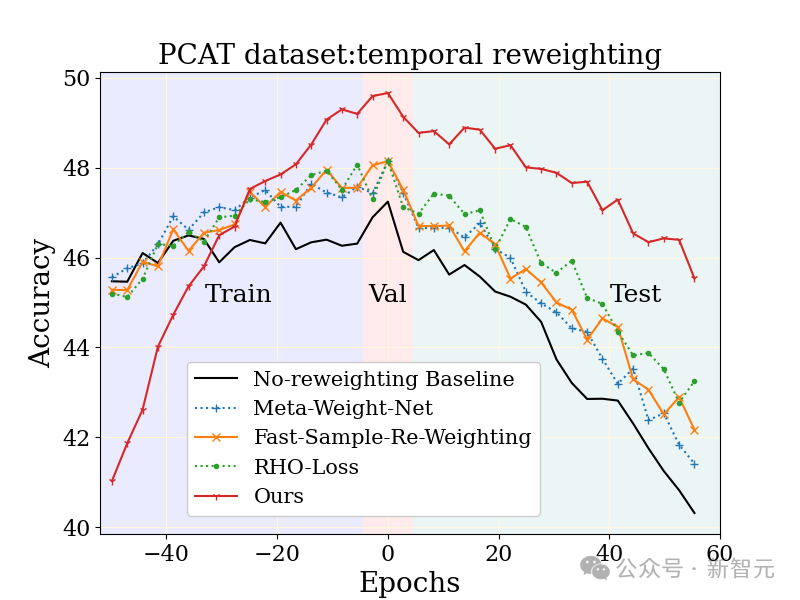
Es ist erwähnenswert, dass die MUSCATEL-Methode bewusst die Genauigkeit von Daten aus der fernen Vergangenheit anpasst, um im Gegenzug eine deutliche Leistungsverbesserung während des Tests zu erzielen. Diese Strategie optimiert nicht nur die Anpassungsfähigkeit des Modells an zukünftige Daten, sondern zeigt auch eine geringere Verschlechterung während des Tests.
Validieren Sie die breite Verwendbarkeit über Datensätze hinweg.
Der Datensatz für die instationäre Lernherausforderung umfasst eine Vielzahl von Datenquellen und Modalitäten, darunter Fotos, Satellitenbilder, Social-Media-Texte, Krankenakten, Sensormesswerte und Tabellendaten Die Datengröße liegt ebenfalls zwischen 10.000 und 39 Millionen Instanzen. Es ist zu beachten, dass die bisher beste Methode für jeden Datensatz unterschiedlich sein kann. Wie in der Abbildung unten gezeigt, hat die MUSCATEL-Methode jedoch vor dem Hintergrund der Daten- und Methodenvielfalt erhebliche Gewinneffekte gezeigt. Dieses Ergebnis zeigt voll und ganz die breite Anwendbarkeit von MUSCATEL.
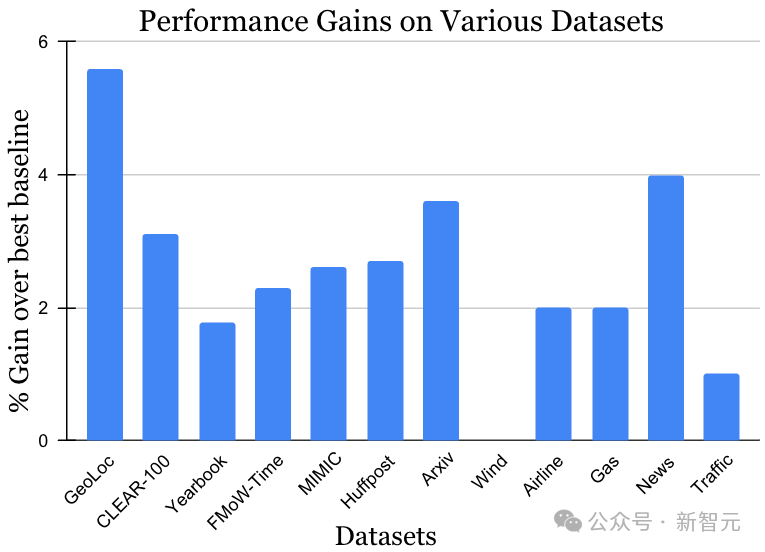
Erweitern Sie kontinuierliche Lernalgorithmen, um die Herausforderungen bei der Datenverarbeitung im großen Maßstab zu bewältigen.
Wenn Sie mit Bergen großer Datenmengen konfrontiert werden, können herkömmliche Offline-Lernmethoden das Gefühl haben, unzureichend zu sein.
Mit Blick auf dieses Problem hat das Forschungsteam eine durch kontinuierliches Lernen inspirierte Methode geschickt angepasst, um sich problemlos an die Verarbeitung großer Datenmengen anzupassen.
Diese Methode ist sehr einfach. Sie fügt jedem Datenstapel eine Zeitgewichtung hinzu und aktualisiert das Modell dann nacheinander.
Obwohl es dabei noch einige kleine Einschränkungen gibt, wie z. B. Modellaktualisierungen nur auf den neuesten Daten basieren können, ist der Effekt überraschend gut!
Im folgenden Benchmark-Test zur Fotoklassifizierung schnitt diese Methode besser ab als der herkömmliche kontinuierliche Lernalgorithmus und verschiedene andere Algorithmen.
Darüber hinaus ist zu erwarten, dass die Wirkung in Kombination mit anderen Methoden noch erstaunlicher sein wird, da die Idee gut mit vielen bestehenden Methoden harmoniert!
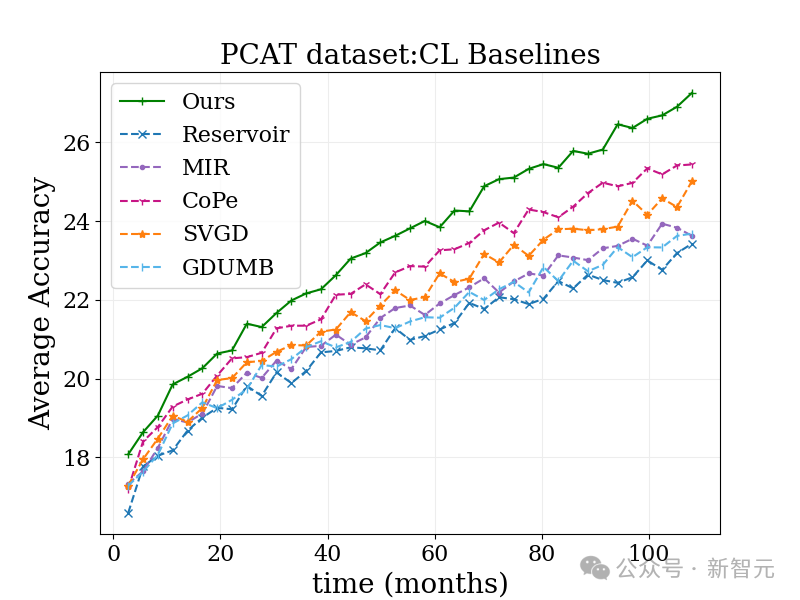
Im Allgemeinen hat das Forschungsteam Offline- und kontinuierliches Lernen erfolgreich kombiniert, um das Datendriftproblem zu lösen, das die Branche seit langem plagt.
Diese innovative Strategie lindert nicht nur das Phänomen des „Katastrophenvergessens“ des Modells erheblich, sondern eröffnet auch einen neuen Weg für die zukünftige Entwicklung des kontinuierlichen Lernens großer Datenmengen und verleiht dem gesamten Bereich des maschinellen Lernens neue Vitalität .
Das obige ist der detaillierte Inhalt vonBekämpfen Sie das Problem der „konzeptionellen Eleganz'! Google veröffentlicht neues Zeitwahrnehmungs-Framework: Bilderkennungsgenauigkeit um 15 % erhöht. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!