
Heim >Technologie-Peripheriegeräte >KI >VPR 2024 perfektes Ergebnispapier! Meta schlägt EfficientSAM vor: schnell alles aufteilen!
VPR 2024 perfektes Ergebnispapier! Meta schlägt EfficientSAM vor: schnell alles aufteilen!

- 王林nach vorne
- 2024-03-02 10:10:021416Durchsuche
EfficientSAM Diese Arbeit wurde in CVPR 2024 mit einer perfekten Punktzahl von 5/5/5 aufgenommen! Der Autor teilte das Ergebnis in den sozialen Medien mit, wie im Bild unten gezeigt:
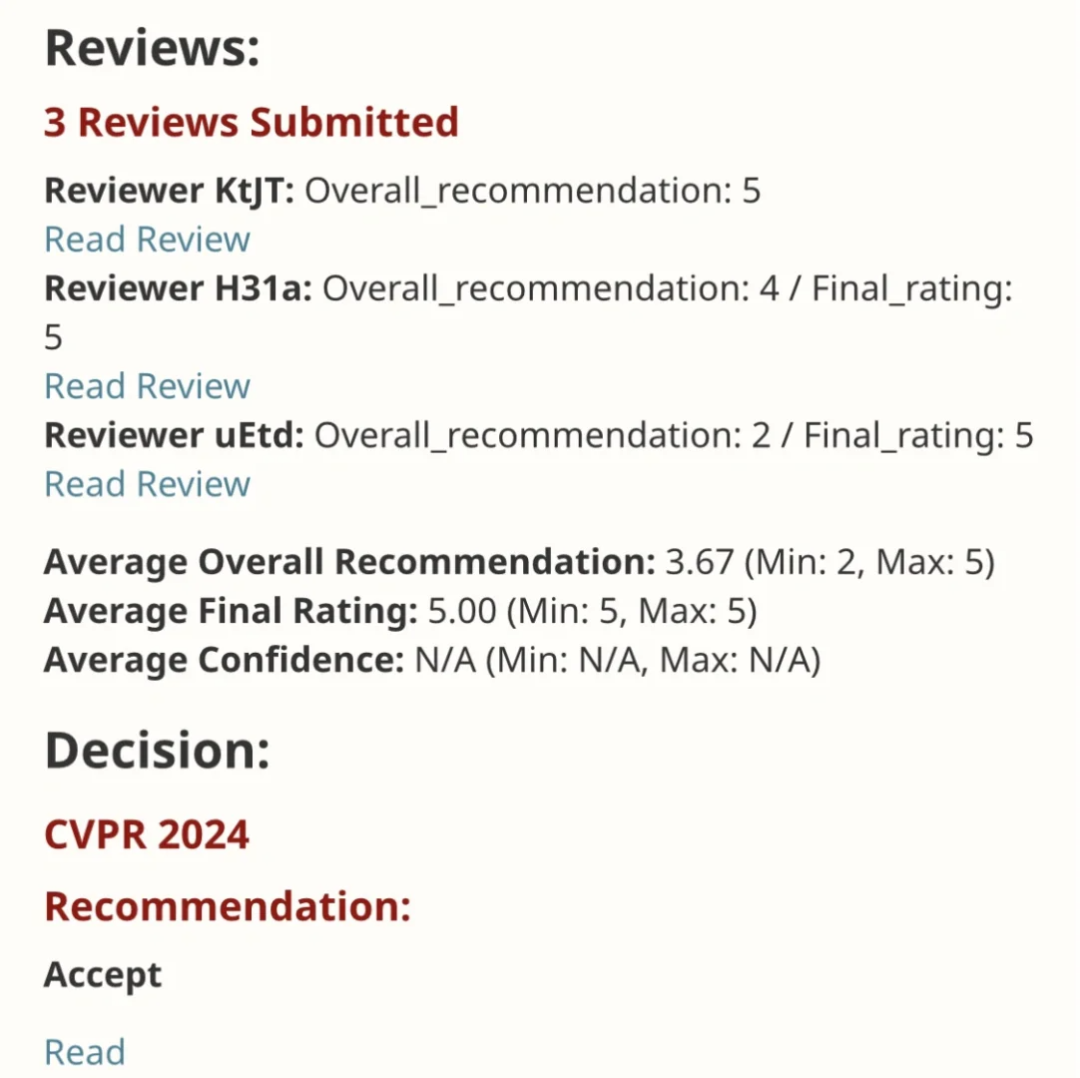
Der LeCun-Turing-Preisträger hat diese Arbeit ebenfalls wärmstens empfohlen!

In jüngsten Untersuchungen haben Metaforscher eine neue verbesserte Methode vorgeschlagen, das Masked Image Pre-Training mit SAM (SAMI). Dieser Ansatz kombiniert MAE-Vortrainingstechniken und SAM-Modelle, um hochwertige vorab trainierte ViT-Encoder zu erhalten. Durch SAMI versuchen Forscher, die Leistung und Effizienz des Modells zu verbessern und bessere Lösungen für Sehaufgaben bereitzustellen. Der Vorschlag dieser Methode bringt neue Ideen und Möglichkeiten mit sich, die Bereiche Computer Vision und Deep Learning weiter zu erforschen und weiterzuentwickeln. Durch die Kombination verschiedener Pre-Training-Techniken und Modellstrukturen können Forscher weiterhin

- Link zum Papier: https://arxiv.org/pdf/2312.00863
- Code : github.com/yformer/EfficientSAM
- Homepage: https://yformer.github.io/efficient-sam/
Dieser Ansatz reduziert die Komplexität von SAM und sorgt gleichzeitig für eine gute Leistung. Konkret nutzt SAMI den SAM-Encoder ViT-H, um Feature-Einbettungen zu generieren und trainiert ein Maskenbildmodell mit einem leichtgewichtigen Encoder, wodurch Features aus SAMs ViT-H anstelle von Bildpatches rekonstruiert werden und das resultierende universelle ViT-Backbone für nachgelagerte Aufgaben wie z B. Bildklassifizierung, Objekterkennung und -segmentierung usw. Anschließend verwenden wir den SAM-Decoder zur Feinabstimmung des vorab trainierten, leichten Encoders, um jede Segmentierungsaufgabe abzuschließen.
Um die Wirksamkeit dieser Methode zu überprüfen, verwendeten die Forscher eine Transfer-Lerneinstellung, die vorab auf maskierten Bildern trainiert wurde. Konkret trainierten sie zunächst das Modell mit Rekonstruktionsverlust im ImageNet-Datensatz mit einer Bildauflösung von 224×224. Anschließend optimieren sie das Modell mithilfe überwachter Daten aus der Zielaufgabe. Diese Transferlernmethode kann dem Modell helfen, schnell zu lernen und die Leistung bei neuen Aufgaben zu verbessern, da das Modell in der Vortrainingsphase gelernt hat, Merkmale aus den Originaldaten zu extrahieren. Diese Transfer-Lernstrategie nutzt effektiv das in großen Datensätzen erlernte Wissen und erleichtert so die Anpassung des Modells an verschiedene Aufgaben. Gleichzeitig kann ViT-Tiny/- durch SAMI-Vortraining auf ImageNet-1K Small trainiert werden /-Base und andere Modelle und verbessern die Generalisierungsleistung. Für das ViT-Small-Modell erreichten die Forscher nach 100-maliger Feinabstimmung auf ImageNet-1K eine Top-1-Genauigkeit von 82,7 %, was besser ist als bei anderen hochmodernen Bild-Pre-Training-Baselines.
Die Forscher haben das vorab trainierte Modell hinsichtlich Zielerkennung, Instanzsegmentierung und semantischer Segmentierung verfeinert. Bei all diesen Aufgaben erzielt unsere Methode bessere Ergebnisse als andere vorab trainierte Basislinien und, was noch wichtiger ist, sie erzielt erhebliche Fortschritte bei kleinen Modellen.
Yunyang Xiong, der Autor des Artikels, sagte: Die in diesem Artikel vorgeschlagenen EfficientSAM-Parameter werden um das 20-fache reduziert, aber die Laufzeit ist 20-mal schneller. Der Unterschied zum ursprünglichen SAM-Modell beträgt nur 2 Prozentpunkte , was viel besser ist als MobileSAM/FastSAM.
Klicken Sie in der Demo auf das Tier im Bild, und EfficientSAM kann das Objekt schnell segmentieren: 
EfficientSAM kann auch die Personen auf dem Bild genau identifizieren: 
Testadresse: https://ab348ea7942fe2af48.gradio.live/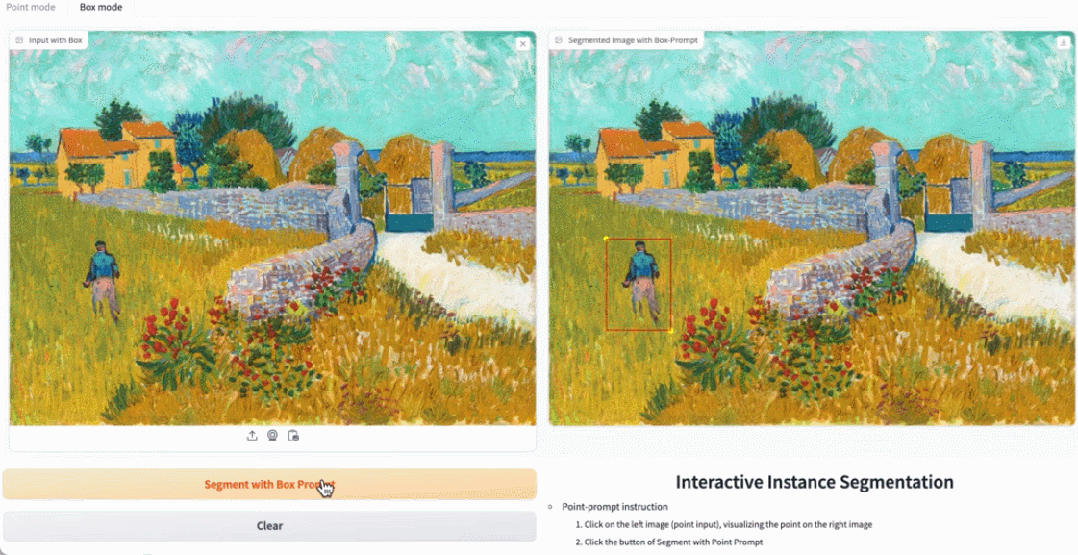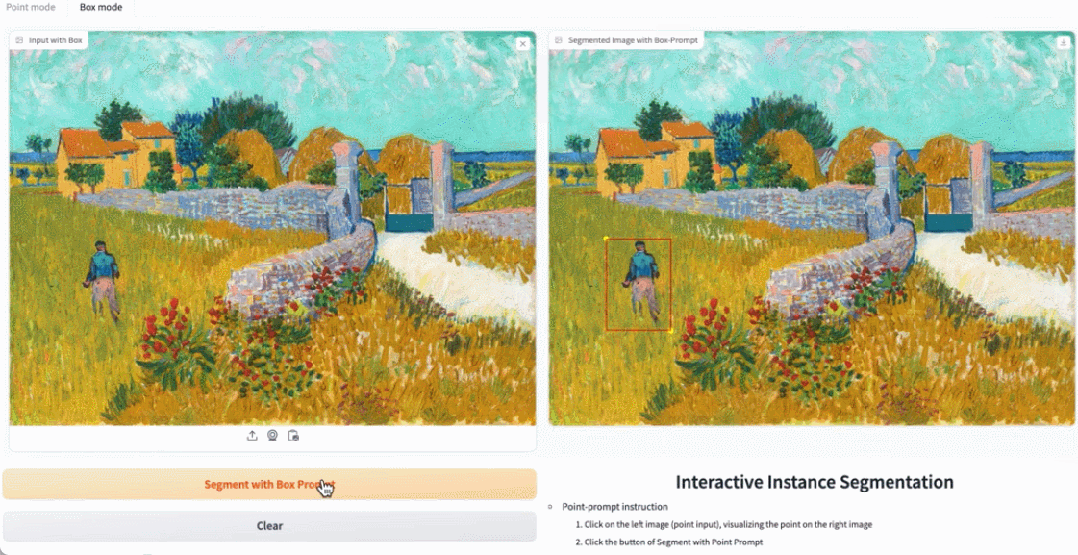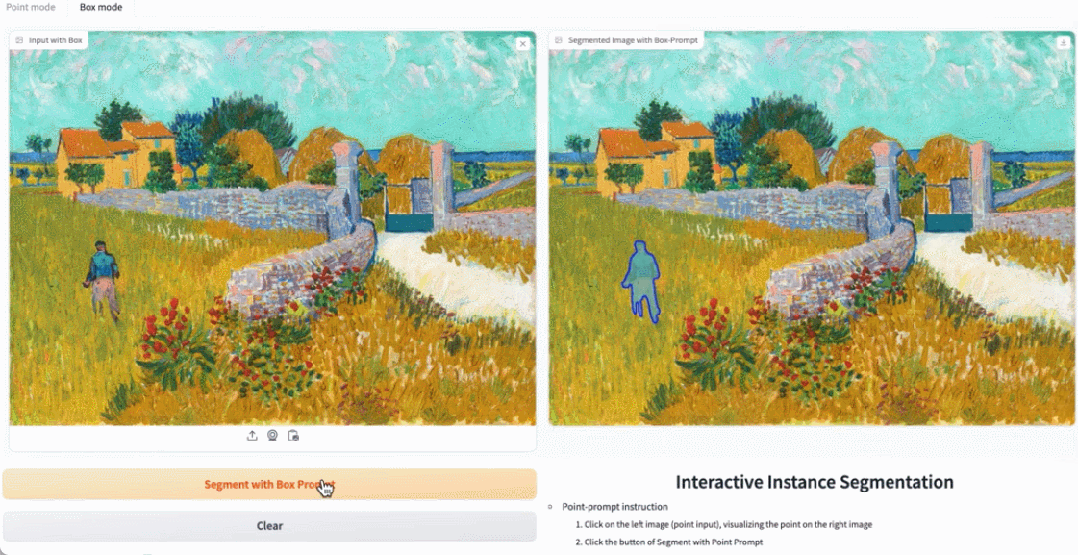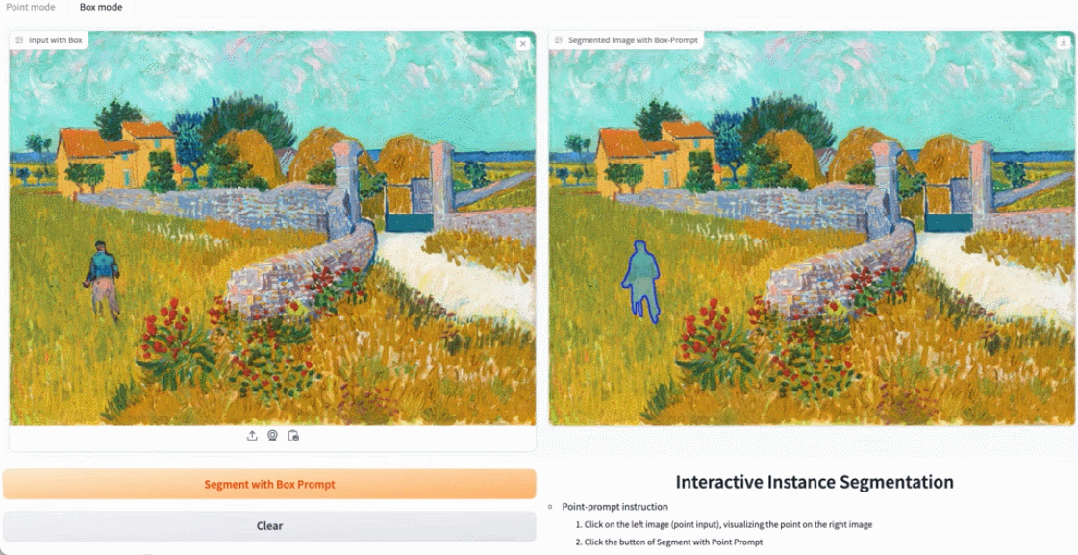
Methode
EfficientSAM enthält zwei Phasen: 1) SAMI vor dem Training auf ImageNet (Teil 1); 2) SA-1B-Feinabstimmung das SAM (unten).
Effizientes SAM enthält hauptsächlich die folgenden Komponenten: während des Rekonstruktionsprozesses rekonstruiert werden können, fungieren als Anker. Im Cross-Attention-Decoder kommt die Abfrage von den maskierten Token, und die Schlüssel und Werte werden von den unmaskierten Features und maskierten Features vom Encoder abgeleitet. In diesem Artikel werden die Ausgabemerkmale der maskierten Token des Cross-Attention-Decoders und die Ausgabemerkmale der unmaskierten Token des Encoders für die MAE-Ausgabeeinbettung zusammengeführt. Diese kombinierten Features werden dann in der endgültigen MAE-Ausgabe an den ursprünglichen Positionen der Eingabebild-Tokens neu angeordnet.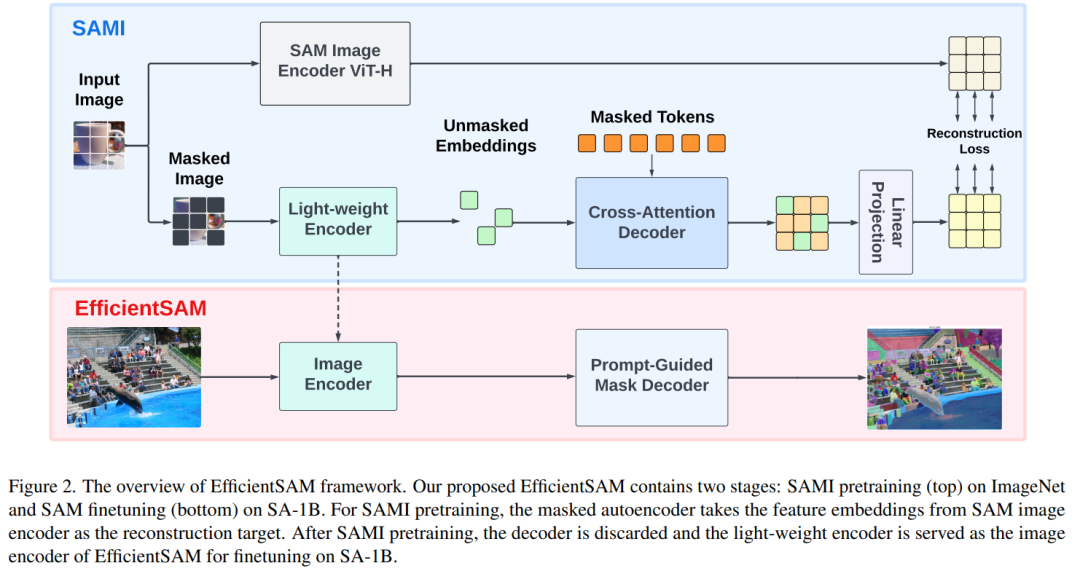
Linearer Projektionskopf. Anschließend haben wir die über den Encoder und den Queraufmerksamkeitsdecoder erhaltenen Bildausgaben in einen kleinen Projektkopf eingespeist, um die Merkmale im SAM-Bildencoder auszurichten. Der Einfachheit halber wird in diesem Artikel nur ein linearer Projektionskopf verwendet, um die Nichtübereinstimmung der Merkmalsabmessungen zwischen dem SAM-Bildcodierer und der MAE-Ausgabe zu beheben.
Wiederaufbau von Verlusten. In jeder Trainingsiteration umfasst SAMI die Extraktion von Vorwärtsmerkmalen aus dem SAM-Bildkodierer sowie Vorwärts- und Rückwärtsausbreitungsprozesse des MAE. Die Ausgaben des SAM-Bildkodierers und des MAE-Linearprojektionskopfes werden verglichen, um den Rekonstruktionsverlust zu berechnen.
Nach dem Vortraining kann der Encoder Feature-Darstellungen für verschiedene visuelle Aufgaben extrahieren, und der Decoder wird ebenfalls verworfen. Um insbesondere ein effizientes SAM-Modell für jede Segmentierungsaufgabe zu erstellen, werden in diesem Artikel vorab trainierte SAMI-Leichtgewicht-Encoder (wie ViT-Tiny und ViT-Small) als Bild-Encoder von EfficientSAM und Standard-Maskendecoder von SAM verwendet. , wie in Abbildung 2 (unten) dargestellt. In diesem Artikel wird das EfficientSAM-Modell für den SA-1B-Datensatz verfeinert, um eine Segmentierung jeder Aufgabe zu erreichen.
Experiment
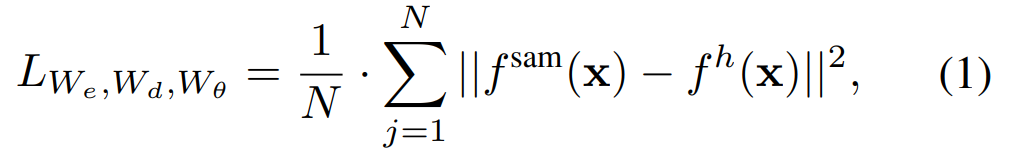
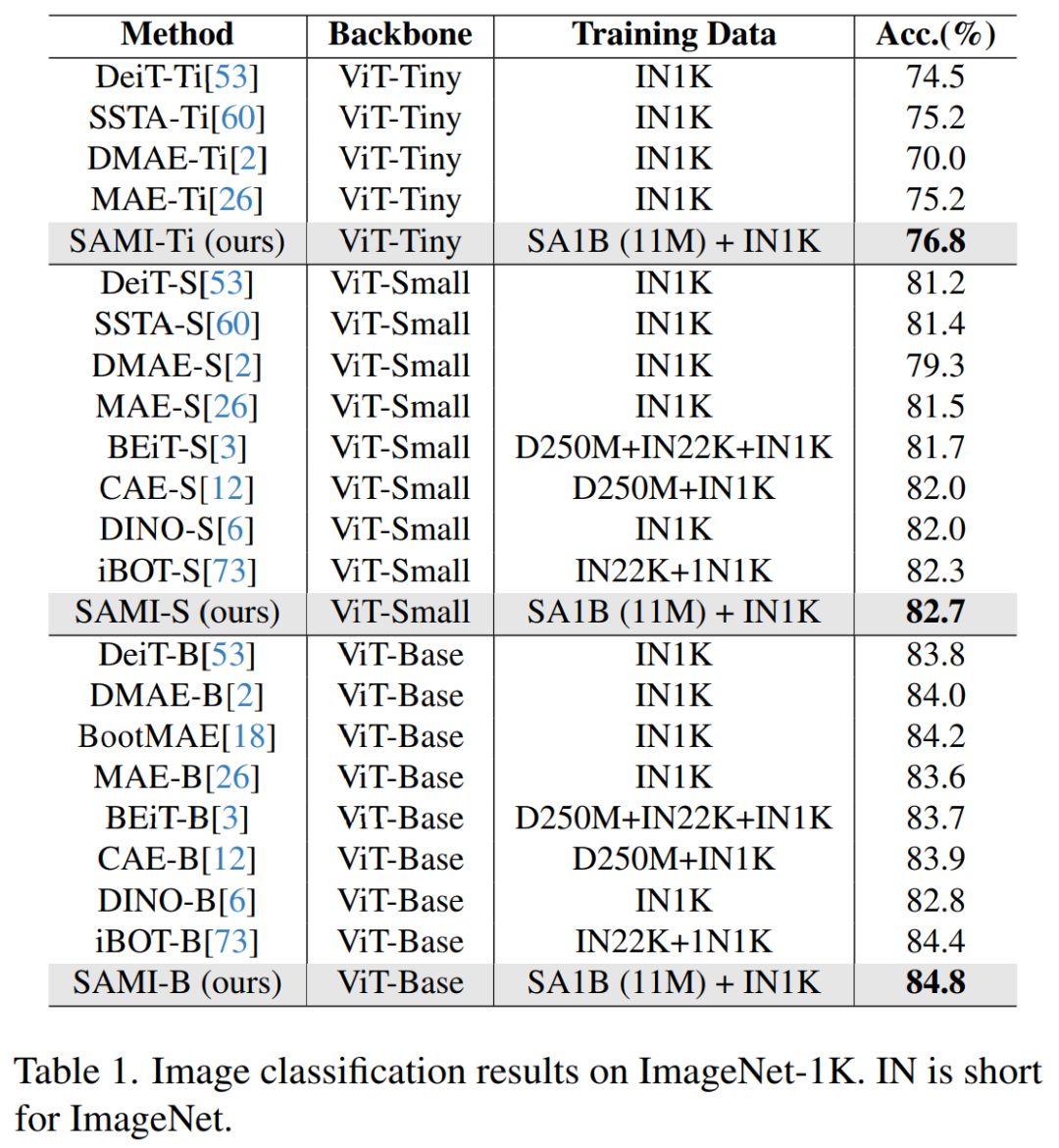
Bildklassifizierung. Um die Wirksamkeit dieser Methode bei Bildklassifizierungsaufgaben zu bewerten, wandten die Forscher SAMI-Ideen auf das ViT-Modell an und verglichen ihre Leistung auf ImageNet-1K.
Wie in Tabelle 1 gezeigt, wird SAMI mit Pre-Training-Methoden wie MAE, iBOT, CAE und BEiT sowie Destillationsmethoden wie DeiT und SSTA verglichen.
Die Top1-Genauigkeit von SAMI-B erreicht 84,8 %, was höher ist als die vorab trainierte Basislinie MAE, DMAE, iBOT, CAE und BEiT. SAMI zeigt auch große Verbesserungen im Vergleich zu Destillationsmethoden wie DeiT und SSTA. Bei leichten Modellen wie ViT-Tiny und ViT-Small zeigen die SAMI-Ergebnisse deutliche Vorteile im Vergleich zu DeiT, SSTA, DMAE und MAE.
Objekterkennung und Instanzsegmentierung. Dieses Papier erweitert auch das SAMI-vortrainierte ViT-Backbone auf nachgelagerte Objekterkennungs- und Instanzsegmentierungsaufgaben und vergleicht es mit einer Basislinie, die auf dem COCO-Datensatz vorab trainiert wurde. Wie in Tabelle 2 gezeigt, übertrifft SAMI durchweg die Leistung anderer Baselines.
Diese experimentellen Ergebnisse zeigen, dass das von SAMI bereitgestellte vorab trainierte Detektor-Backbone bei Objekterkennungs- und Instanzsegmentierungsaufgaben sehr effektiv ist.
Semantische Segmentierung. In diesem Artikel wird das vorab trainierte Backbone weiter auf semantische Segmentierungsaufgaben erweitert, um seine Wirksamkeit zu bewerten. Die Ergebnisse sind in Tabelle 3 aufgeführt. Mask2former erreicht mit dem vorab trainierten SAMI-Backbone bessere mIoU auf ImageNet-1K als mit dem vorab trainierten MAE-Backbone. Diese experimentellen Ergebnisse bestätigen, dass die in diesem Artikel vorgeschlagene Technologie gut auf verschiedene nachgelagerte Aufgaben übertragen werden kann. 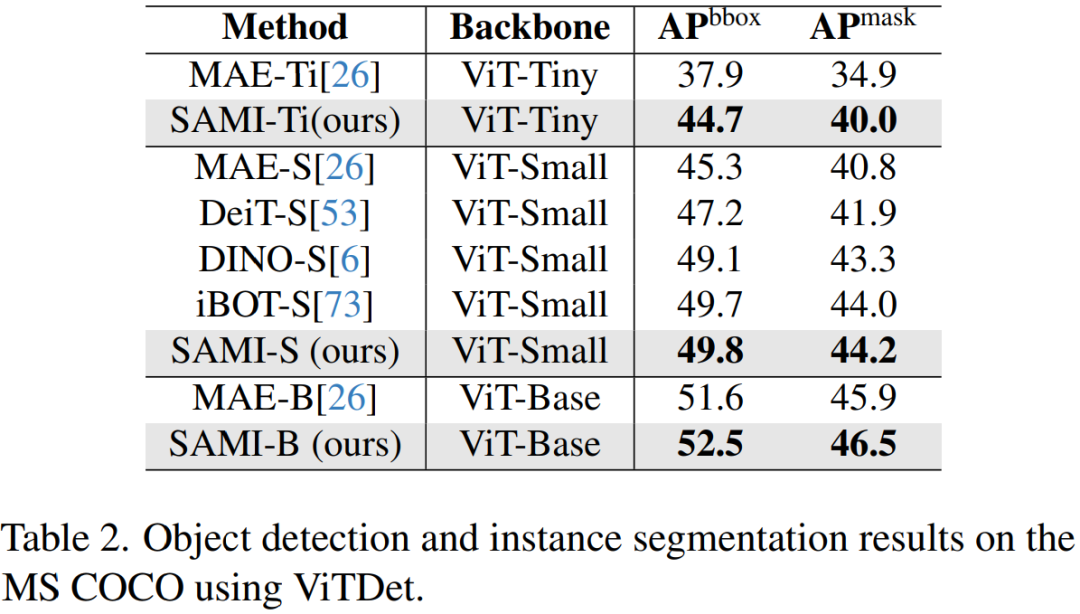
Tabelle 4 vergleicht EfficientSAMs mit SAM, MobileSAM und SAM-MAE-Ti. Auf COCO übertrifft EfficientSAM-Ti MobileSAM. EfficientSAM-Ti verfügt über vorab trainierte SAMI-Gewichte und bietet auch eine bessere Leistung als vorab trainierte MAE-Gewichte.
Darüber hinaus ist EfficientSAM-S nur 1,5 mIoU niedriger als SAM auf der COCO-Box und 3,5 mIoU niedriger als SAM auf der LVIS-Box, mit 20-mal weniger Parametern. In diesem Artikel wurde außerdem festgestellt, dass EfficientSAM im Vergleich zu MobileSAM und SAM-MAE-Ti auch bei mehreren Klicks eine gute Leistung zeigte.
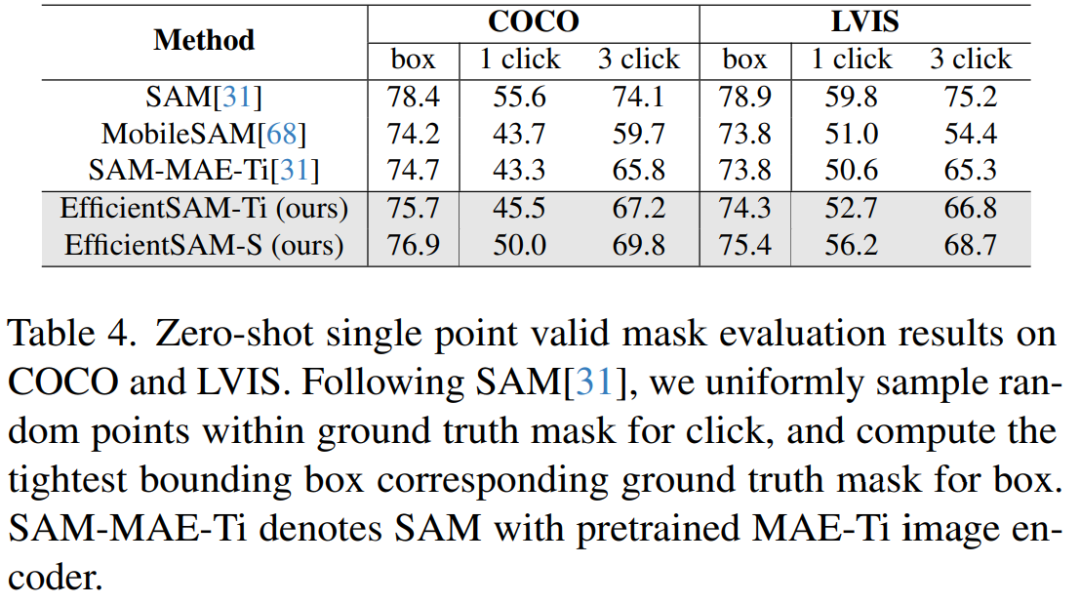
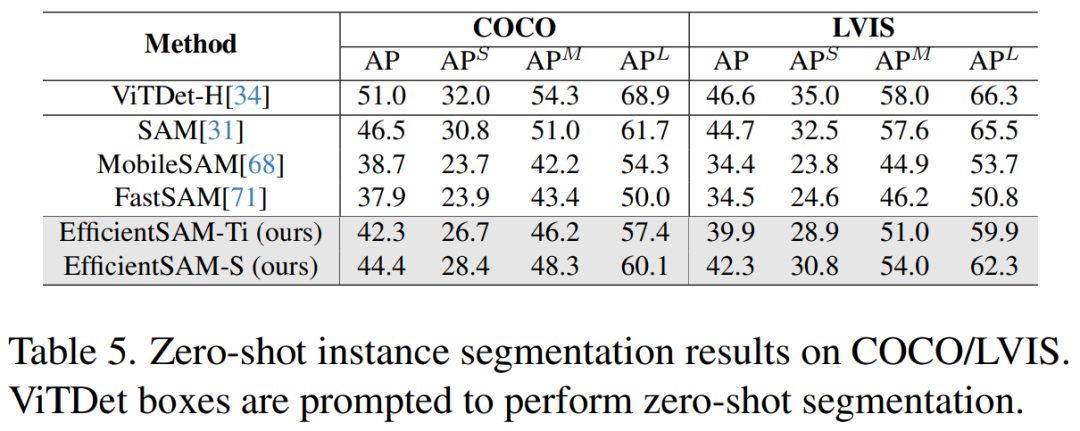
Tabelle 5 zeigt die AP, APS, APM und APL der Zero-Shot-Instanzsegmentierung. Die Forscher verglichen EfficientSAM mit MobileSAM und FastSAM und es zeigt sich, dass EfficientSAM-S im Vergleich zu FastSAM mehr als 6,5 APs auf COCO und 7,8 APs auf LVIS gewann. Im Fall von EffidientSAM-Ti ist es mit 4,1 APs auf COCO und 5,3 APs auf LVIS immer noch deutlich besser als FastSAM, während MobileSAM 3,6 APs auf COCO und 5,5 APs auf LVIS hat.
Darüber hinaus ist EfficientSAM viel leichter als FastSAM, die Parameter vonefficientSAM-Ti betragen 9,8M, während die Parameter von FastSAM 68M betragen.
Die Abbildungen 3, 4 und 5 liefern einige qualitative Ergebnisse, damit die Leser ein ergänzendes Verständnis der Instanzsegmentierungsfunktionen von EfficientSAMs erhalten.



Weitere Forschungsdetails finden Sie im Originalpapier.
Das obige ist der detaillierte Inhalt vonVPR 2024 perfektes Ergebnispapier! Meta schlägt EfficientSAM vor: schnell alles aufteilen!. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Warum nach Schlüsselwörtern suchen?
- Recherche- und Reparaturmethoden für Sicherheitslücken innerhalb des Vue-Frameworks
- Forschung zur Psychologie von Netzwerk-Hacker-Angriffen
- Nutzen Sie die Vision, um zu motivieren! Shen Xiangyang stellte das neue Modell des IDEA Research Institute vor, das weder Schulung noch Feinabstimmung erfordert und sofort einsatzbereit ist.