
Heim >Technologie-Peripheriegeräte >KI >LeCun verwendet ein Diffusionsmodell zur Generierung von Netzwerkparametern und lobt die neue Forschung des You Yang-Teams
LeCun verwendet ein Diffusionsmodell zur Generierung von Netzwerkparametern und lobt die neue Forschung des You Yang-Teams

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBnach vorne
- 2024-02-26 08:10:03604Durchsuche
Wenn Sie von den von Sora generierten Videos schockiert waren, dann haben Sie das enorme Potenzial von Diffusionsmodellen bei der visuellen Generierung erkannt. Das Potenzial des Diffusionsmodells endet hier natürlich nicht. Weitere Fälle finden Sie in unserem aktuellen Bericht „Die Technologie hinter der Explosion von Sora“, einem Artikel, der die Diffusion zusammenfasst neueste Entwicklungsrichtung der Modelle》.
Kürzlich hat eine von You Yangs Team an der National University of Singapore, der University of California, Berkeley und Meta AI Research durchgeführte Forschung eine neue Anwendung des Diffusionsmodells entdeckt: Es wird zur Generierung von Modellparametern für neuronale Netze verwendet.
- Papieradresse: https://arxiv.org/pdf/2402.13144.pdf
- Projektadresse: https://github.com/NUS-HPC-AI-Lab/Neural-Network- Diffusion
- Titel des Papiers: Diffusion neuronaler Netze
Diffusion neuronaler Netze
Einführung in Diffusionsmodelle
Diffusionsmodelle bestehen normalerweise aus Vorwärts- und Rückwärtsprozessen, die einen mehrstufigen Kettenprozess bilden und durch Zeitschritte indiziert werden können.Weiterleitungsprozess. Bei einer Stichprobe x_0 ∼ q(x) besteht der Vorwärtsprozess darin, schrittweise in T-Schritten Gaußsches Rauschen hinzuzufügen, um x_1, x_2 ... x_T zu erhalten.
Umgekehrter Vorgang. Im Gegensatz zum Vorwärtsprozess besteht das Ziel des Rückwärtsprozesses darin, ein Netzwerk zur Rauschunterdrückung zu trainieren, das Rauschen in x_t rekursiv entfernen kann. Der Prozess ist die Umkehrung mehrerer Schritte, wobei t von T bis hinunter auf 0 abnimmt.
Überblick über neuronale Netzwerkdiffusionsmethoden
Neuronale Netzwerkdiffusion (p-diff) Das Ziel dieser neuen Methode ist die Generierung leistungsstarker Parameter auf der Grundlage von Zufallsrauschen. Wie in Abbildung 2 dargestellt, besteht diese Methode aus zwei Prozessen: Parameter-Autoencoder und Parametergenerierung.
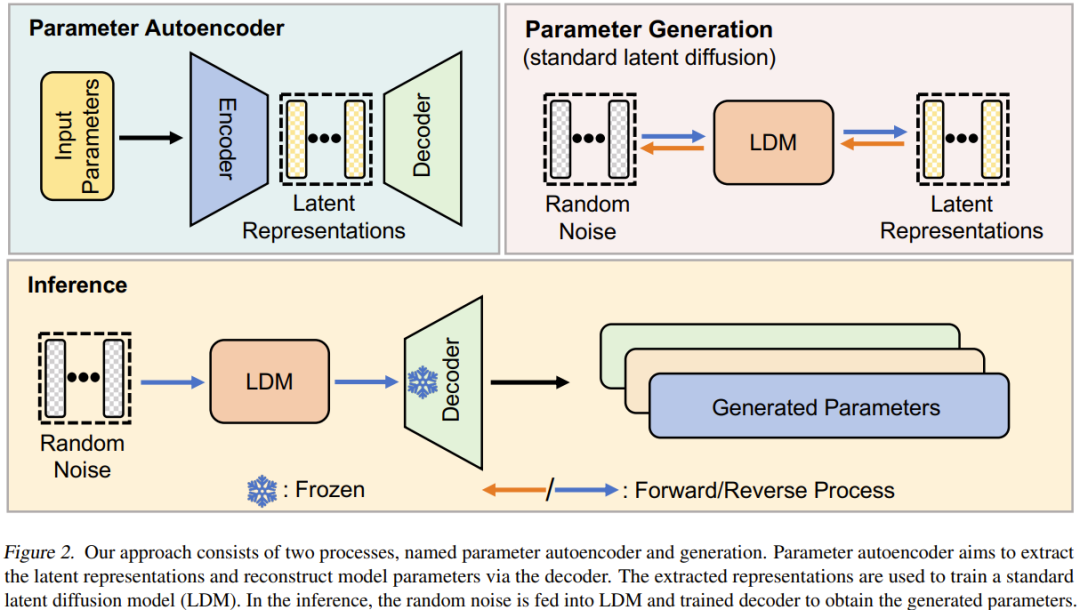
Wählen Sie bei einem Satz trainierter Hochleistungsmodelle zunächst eine Teilmenge seiner Parameter aus und reduzieren Sie sie auf einen eindimensionalen Vektor.
Danach wird ein Encoder verwendet, um die impliziten Darstellungen dieser Vektoren zu extrahieren, und ein Decoder ist für die Rekonstruktion der Parameter basierend auf diesen impliziten Darstellungen verantwortlich.
Dann wird ein standardmäßiges latentes Diffusionsmodell trainiert, um diese latente Darstellung basierend auf zufälligem Rauschen zu synthetisieren.
Nach dem Training können Sie p-diff verwenden, um durch einen solchen Kettenprozess neue Parameter zu generieren: zufälliges Rauschen → umgekehrter Prozess → trainierter Decoder → generierte Parameter.
Experiment
Das Team hat in der Arbeit detaillierte experimentelle Einstellungen angegeben, die anderen Forschern helfen können, ihre Ergebnisse zu reproduzieren. Hier konzentrieren wir uns mehr auf die Ergebnisse und die Ablationsforschung.
Ergebnisse
Tabelle 1 ist ein Vergleich der Ergebnisse mit zwei Basismethoden für 8 Datensätze und 6 Architekturen.

Basierend auf diesen Ergebnissen können folgende Beobachtungen gemacht werden: 1) In den meisten experimentellen Fällen kann die neue Methode Ergebnisse erzielen, die mit den beiden Basismethoden vergleichbar oder besser sind. Dies zeigt, dass die neu vorgeschlagene Methode die Verteilung von Hochleistungsparametern effizient lernen und auf der Grundlage von Zufallsrauschen bessere Modelle generieren kann. 2) Die neue Methode funktioniert bei mehreren verschiedenen Datensätzen gut, was zeigt, dass diese Methode eine gute Generalisierungsleistung aufweist.
Ablationsstudie und -analyse
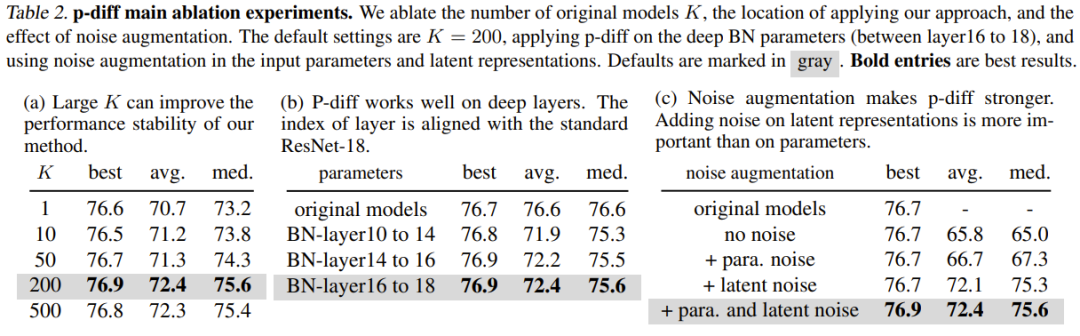
Tabelle 2(a) zeigt die Auswirkungen unterschiedlicher Trainingsdatengrößen (d. h. die Anzahl der Originalmodelle). Wie man sieht, ist der Leistungsunterschied zwischen den besten Ergebnissen für unterschiedliche Anzahlen von Originalmodellen eigentlich nicht so groß.
Um die Wirksamkeit von p-diff bei anderen Tiefen der Normalisierungsschicht zu untersuchen, untersuchte das Team auch die Leistung neuer Methoden zur Synthese anderer flacher Parameter. Um eine gleiche Anzahl von BN-Parametern zu gewährleisten, implementierte das Team die neu vorgeschlagene Methode für drei Sätze von BN-Schichten (die sich zwischen Schichten unterschiedlicher Tiefe befinden). Die experimentellen Ergebnisse sind in Tabelle 2(b) dargestellt. Es ist ersichtlich, dass die Leistung (beste Genauigkeit) der neuen Methode in allen Tiefen der BN-Schichteinstellungen besser ist als die des ursprünglichen Modells.
Der Zweck der Rauschverstärkung besteht darin, die Robustheit und Generalisierungsfähigkeit trainierter Autoencoder zu verbessern. Das Team führte Ablationsstudien zur Anwendung der Rauschverstärkung auf Eingabeparameter und implizite Darstellungen durch. Die Ergebnisse sind in Tabelle 2(c) dargestellt.
Zuvor wurde in Experimenten die Wirksamkeit neuer Methoden bei der Synthese einer Teilmenge von Modellparametern (d. h. Batch-Normalisierungsparametern) bewertet. Wir kommen also nicht umhin zu fragen: Können die Gesamtparameter des Modells mit dieser Methode synthetisiert werden?
Um diese Frage zu beantworten, führte das Team Experimente mit zwei kleinen Architekturen durch: MLP-3 und ConvNet-3. Darunter enthält MLP-3 drei lineare Schichten und eine ReLU-Aktivierungsfunktion, und ConvNet-3 enthält drei Faltungsschichten und eine lineare Schicht. Im Gegensatz zur zuvor erwähnten Strategie zur Trainingsdatenerfassung trainierte das Team diese Architekturen von Grund auf auf der Grundlage von 200 verschiedenen Zufallsstartwerten.
Tabelle 3 enthält die experimentellen Ergebnisse, wobei die neue Methode mit zwei Basismethoden (Originalmethode und Ensemble-Methode) verglichen wird. Es berichtet über den Vergleich der Ergebnisse und der Anzahl der Parameter von ConvNet-3 auf CIFAR-10/100 und MLP-3 auf CIFAR-10 und MNIST.

Diese Experimente demonstrieren die Wirksamkeit und Generalisierungsfähigkeit der neuen Methode bei der Synthese allgemeiner Modellparameter, was bedeutet, dass die neue Methode eine Leistung erzielt, die mit der Basismethode vergleichbar oder besser ist. Diese Ergebnisse können auch das praktische Anwendungspotenzial der neuen Methode belegen.
Aber das Team zeigte in der Arbeit auch, dass es derzeit nicht in der Lage ist, die Gesamtparameter großer Architekturen wie ResNet, ViT und ConvNeXt zu synthetisieren. Dies wird hauptsächlich durch die Grenzen des GPU-Speichers begrenzt.
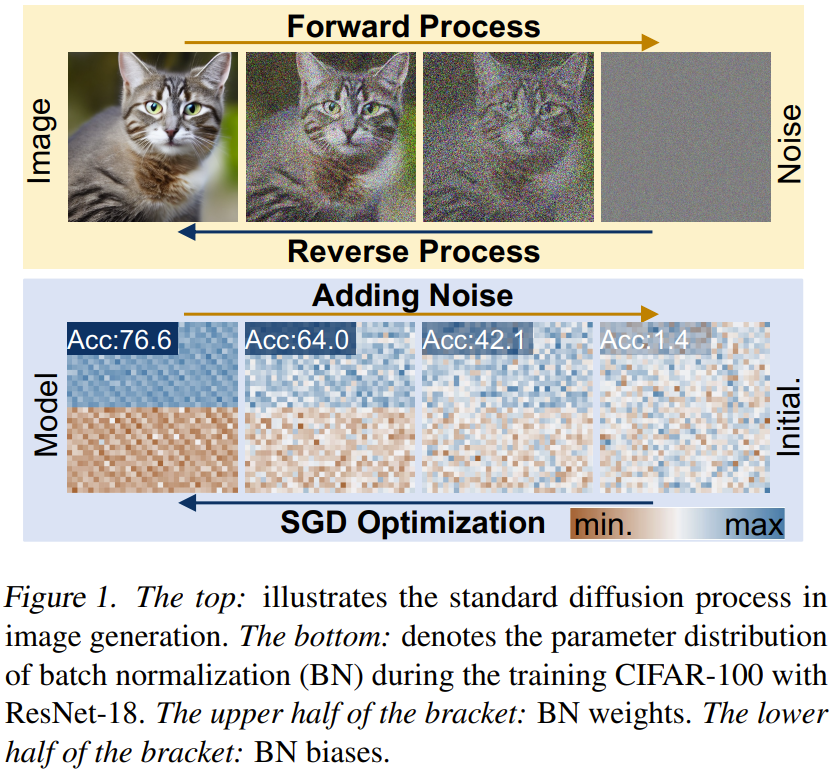
Das Team versuchte auch, die Gründe dafür zu erforschen und zu analysieren, warum diese neue Methode effektiv neuronale Netzwerkparameter generieren kann. Sie trainierten ResNet-18 von Grund auf mit drei zufälligen Seeds und visualisierten seine Parameter, wie in Abbildung 3 dargestellt.
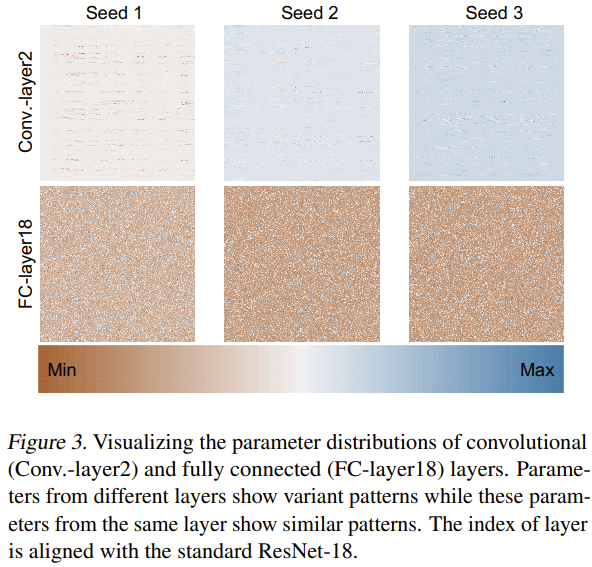
Sie verwendeten die Min-Max-Normalisierungsmethode, um Wärmekarten der Parameterverteilungen verschiedener Schichten zu erhalten. Basierend auf den Visualisierungsergebnissen der Faltungsschicht (Conv.-Schicht2) und der vollständig verbundenen Schicht (FC-Schicht18) ist ersichtlich, dass in diesen Schichten bestimmte Parametermuster vorhanden sind. Durch das Erlernen dieser Muster kann die neue Methode leistungsstarke neuronale Netzwerkparameter generieren.
Verlässt sich p-diff nur auf den Speicher?
p-diff scheint in der Lage zu sein, neuronale Netzwerkparameter zu generieren, aber generiert es Parameter oder speichert es sie nur? Das Team hat hierzu einige Untersuchungen durchgeführt und die Unterschiede zwischen dem Originalmodell und dem generierten Modell verglichen.
Für den quantitativen Vergleich schlugen sie einen Ähnlichkeitsindex vor. Einfach ausgedrückt bestimmt dieser Indikator die Ähnlichkeit zwischen zwei Modellen, indem er das Verhältnis „Intersection over Union“ (IoU) ihrer falschen Vorhersageergebnisse berechnet. Anschließend führten sie auf dieser Grundlage einige Vergleichsstudien und Visualisierungen durch. Die Vergleichsergebnisse sind in Abbildung 4 dargestellt.
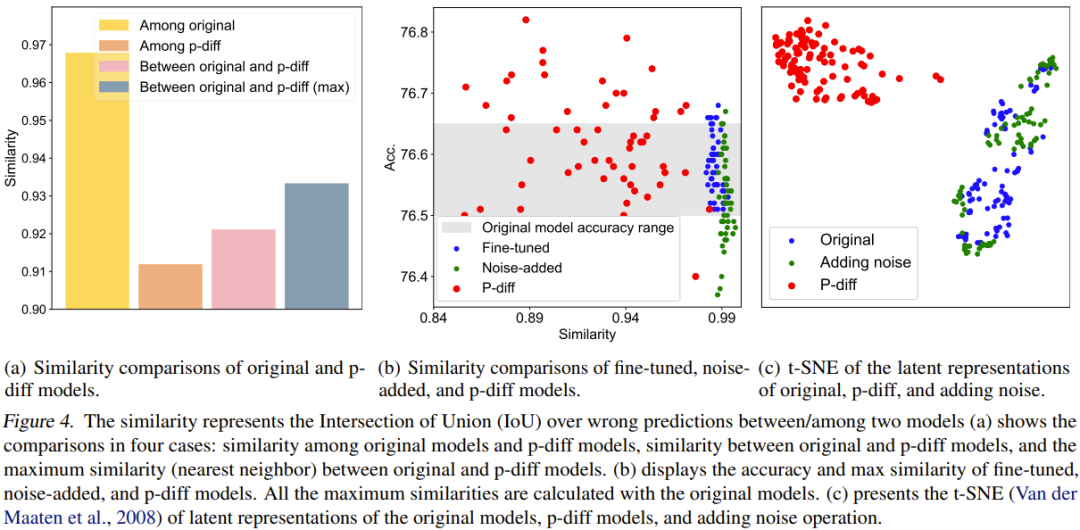
Abbildung 4(a) zeigt den Ähnlichkeitsvergleich zwischen dem Originalmodell und dem p-diff-Modell, das vier Vergleichsschemata umfasst.
Wie Sie sehen, ist der Unterschied zwischen den generierten Modellen viel größer als der Unterschied zwischen den Originalmodellen. Darüber hinaus ist auch die maximale Ähnlichkeit zwischen dem Originalmodell und dem generierten Modell geringer als die Ähnlichkeit zwischen den Originalmodellen. Dies reicht aus, um zu zeigen, dass p-diff neue Parameter generieren kann, die sich von seinen Trainingsdaten (d. h. dem Originalmodell) unterscheiden.
Das Team verglich die neue Methode auch mit fein abgestimmten Modellen und Modellen mit zusätzlichem Rauschen. Die Ergebnisse sind in Abbildung 4(b) dargestellt.
Es ist ersichtlich, dass es für das fein abgestimmte Modell und das Modell mit zusätzlichem Rauschen schwierig ist, das Originalmodell zu übertreffen. Darüber hinaus ist die Ähnlichkeit zwischen dem fein abgestimmten Modell oder dem Modell mit zusätzlichem Rauschen und dem Originalmodell sehr hoch, was darauf hindeutet, dass mit diesen beiden Betriebsmethoden kein völlig neues und leistungsstarkes Modell erhalten werden kann. Allerdings weisen die mit der neuen Methode generierten Modelle verschiedene Ähnlichkeiten und eine bessere Leistung als das Originalmodell auf.
Das Team verglich auch implizite Darstellungen. Die Ergebnisse sind in Abbildung 4(c) dargestellt. Wie man sieht, kann p-diff eine völlig neue latente Darstellung erzeugen, während das Hinzufügen von Rauschmethoden nur um die latente Darstellung des ursprünglichen Modells herum interpoliert.
Das Team visualisierte auch den Verlauf des p-diff-Prozesses. Insbesondere zeichneten sie die Parametertrajektorien auf, die zu verschiedenen Zeitschritten der Inferenzphase erzeugt wurden. Abbildung 5(a) zeigt 5 Trajektorien (unter Verwendung von 5 verschiedenen zufälligen Rauschinitialisierungen). Die rote Mitte in der Abbildung ist der Durchschnittsparameter des Originalmodells und der graue Bereich ist seine Standardabweichung (Standard).
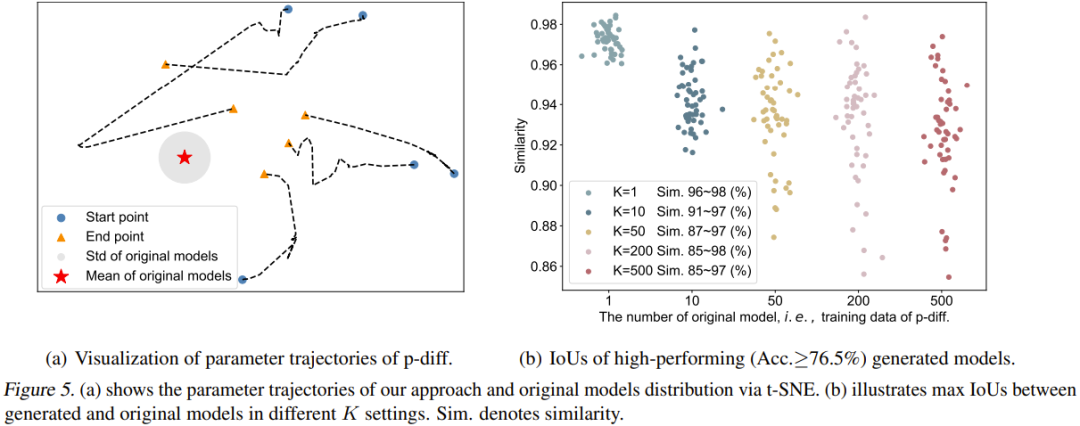
Mit zunehmenden Zeitschritten werden die generierten Parameter näher am Originalmodell als Ganzes liegen. Allerdings ist auch zu erkennen, dass die Endpunkte dieser Trajektorien (orangefarbene Dreiecke) noch einiges von den Durchschnittsparametern entfernt sind. Darüber hinaus sind auch die Formen dieser fünf Flugbahnen sehr unterschiedlich.
Abschließend untersuchte das Team den Einfluss der Anzahl der Originalmodelle (K) auf die Vielfalt der generierten Modelle. Abbildung 5(b) zeigt visuell die maximale Ähnlichkeit zwischen dem ursprünglichen Modell und dem generierten Modell für verschiedene K. Konkret generierten sie 50 Modelle, indem sie so lange Parameter generierten, bis die generierten 50 Modelle in allen Fällen eine Leistung von mehr als 76,5 % erbrachten.
Es ist ersichtlich, dass bei K = 1 die Ähnlichkeit sehr hoch und der Bereich eng ist, was darauf hinweist, dass das zu diesem Zeitpunkt generierte Modell im Wesentlichen die Parameter des Originalmodells speichert. Mit zunehmendem K wird auch der Ähnlichkeitsbereich größer, was darauf hinweist, dass die neue Methode andere Parameter als das ursprüngliche Modell generieren kann.
Das obige ist der detaillierte Inhalt vonLeCun verwendet ein Diffusionsmodell zur Generierung von Netzwerkparametern und lobt die neue Forschung des You Yang-Teams. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Was macht ein Python-Entwicklungsingenieur?
- So erstellen Sie ein vscode-Projekt
- Nicht so gut wie GAN! Google, DeepMind und andere haben Artikel veröffentlicht: Diffusionsmodelle werden direkt aus dem Trainingssatz „kopiert'.
- In Kombination mit der Physik-Engine generiert das GPT-4+-Diffusionsmodell realistische, kohärente und vernünftige Videos
- Umfassende Analyse des stabilen Diffusionsmodells (einschließlich Prinzipien, Techniken, Anwendungen und häufige Fehler)