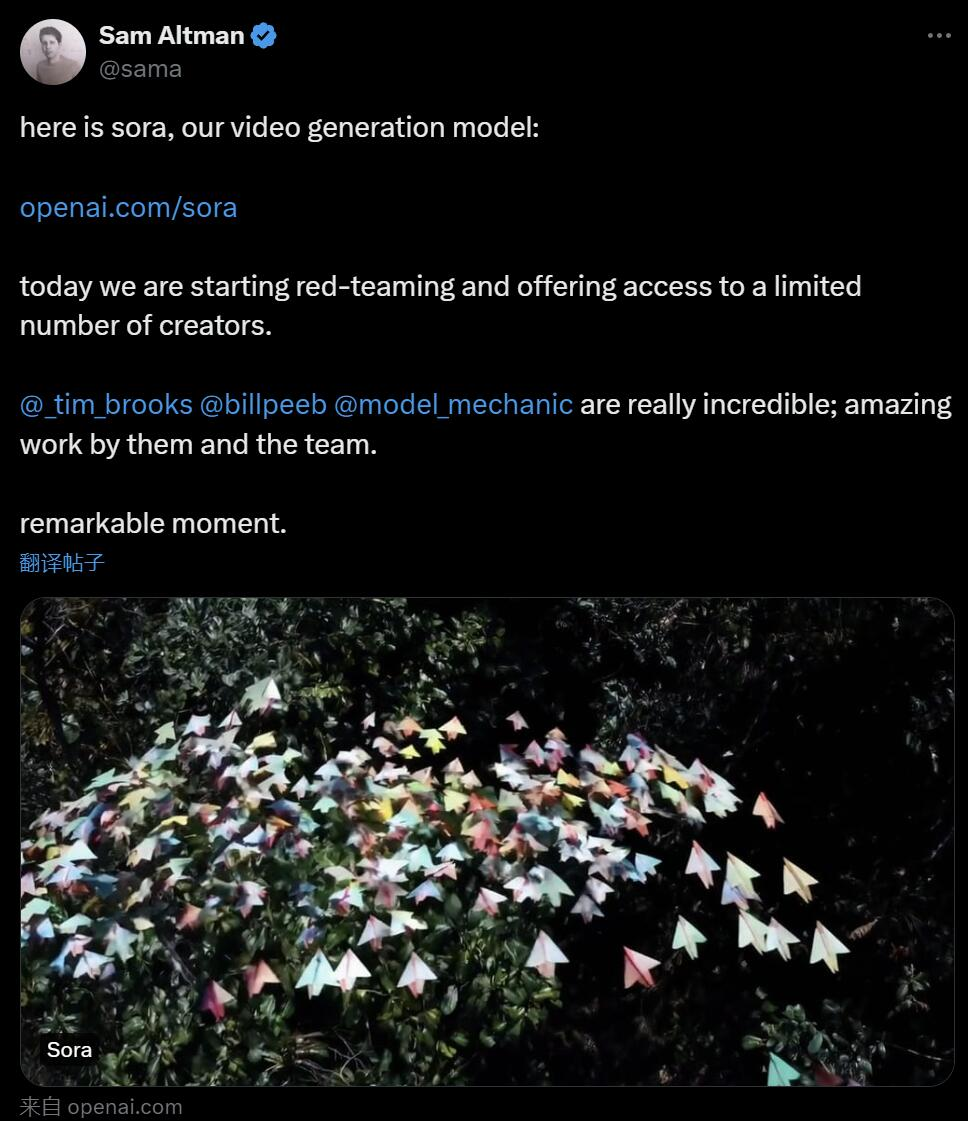
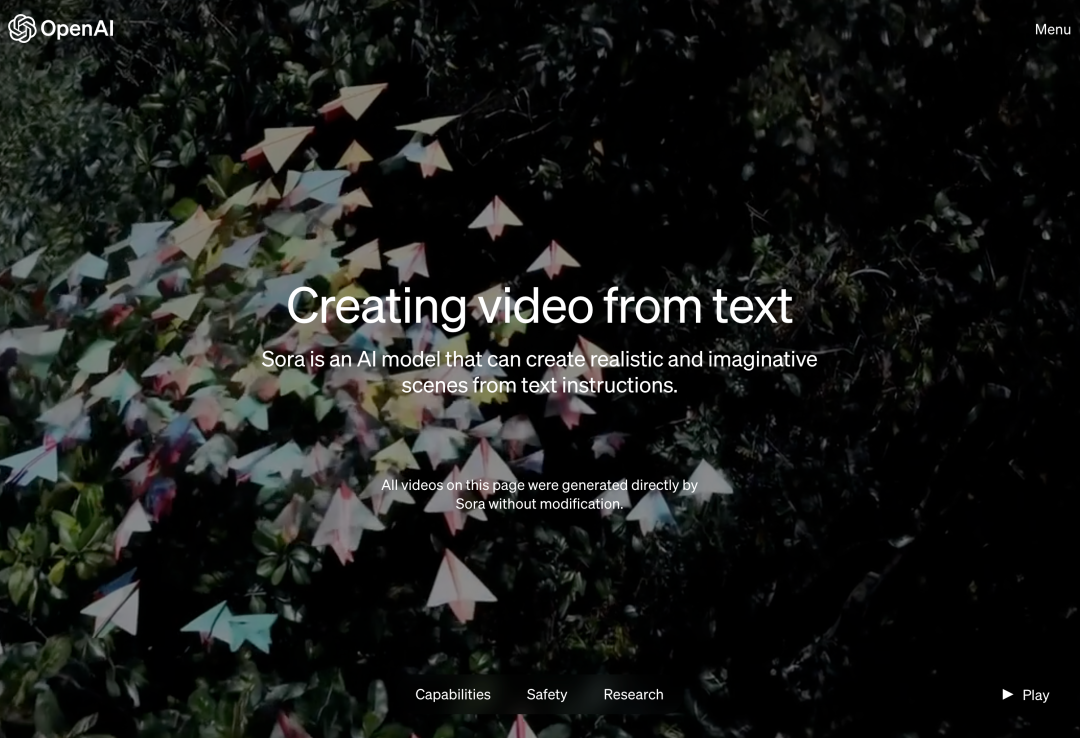
Heute früh Pekinger Zeit hat OpenAI offiziell das Text-zu-Video-Generierungsmodell Sora veröffentlicht. Nach Runway, Pika, Google und Meta schloss sich OpenAI endlich dem Krieg im Bereich der Videogenerierung an. Nachdem die Nachricht von Ultraman Sam veröffentlicht wurde, sahen die Leute zum ersten Mal die von OpenAI-Ingenieuren demonstrierten KI-generierten Videoeffekte. Die Leute beklagten: Ist die Ära von Hollywood vorbei? OpenAI behauptet, dass Sora mit einer kurzen oder detaillierten Beschreibung oder einem statischen Bild eine filmähnliche 1080p-Szene mit mehreren Charakteren, verschiedenen Arten von Aktionen und Hintergrunddetails generieren kann. Was ist das Besondere an Sora? Es verfügt über ein tiefes Sprachverständnis, ist in der Lage, Aufforderungen genau zu interpretieren und ansprechende Charaktere zu generieren, die lebendige Emotionen ausdrücken. Gleichzeitig kann Sora nicht nur die Benutzeranforderung in der Eingabeaufforderung verstehen, sondern auch deren Existenz in der physischen Welt erfassen. Im offiziellen Blog stellt OpenAI viele Beispiele für von Sora generierte Videos zur Verfügung, die beeindruckende Ergebnisse zeigen, zumindest im Vergleich zu früheren textgenerierten Videotechnologien. Für den Anfang kann Sora Videos in verschiedenen Stilen (z. B. fotorealistisch, animiert, Schwarzweiß) mit einer Länge von bis zu einer Minute generieren – viel länger als die meisten Text-zu-Video-Modelle. Die Videos behalten eine angemessene Konsistenz bei und unterliegen nicht immer sogenannten „KI-Verrücktheiten“, wie etwa der Bewegung von Objekten in physikalisch unmögliche Richtungen. Lass Sora zunächst ein Video über den Drachentanz im chinesischen Jahr des Drachen erstellen. 
Geben Sie beispielsweise „prompt“ ein: historische Aufnahmen des kalifornischen Goldrauschs. 
Eingabeaufforderung: Nahaufnahme einer Glaskugel mit einem Zen-Garten darin. Im Inneren der Kugel ist ein Zwerg, der Muster in den Sand malt. 
Eingabeaufforderung: Extreme Nahaufnahme einer blinzelnden 24-jährigen Frau, die während der Magic Hour in Marrakesch steht, Filmaufnahme in 70 mm, Schärfentiefe, lebendige Farben, filmreif. 
Eingabeaufforderung: Das Spiegelbild im Fenster eines Zuges, der durch die Vororte von Tokio fährt. 
Bewerben Sie sich: die Lebensgeschichte eines Roboters in einer Cyberpunk-Umgebung. 
Das Bild ist zu real und zu seltsam zugleichAber OpenAI gibt zu, dass das aktuelle Modell auch Schwächen hat. Möglicherweise hat es Schwierigkeiten, physikalische Phänomene in komplexen Szenarien genau zu simulieren, und es kann sein, dass es bestimmte Ursache-Wirkungs-Beziehungen nicht versteht. Das Modell verwechselt möglicherweise auch räumliche Details von Hinweisen, z. B. links und rechts, und hat möglicherweise Schwierigkeiten, Ereignisse im Zeitverlauf genau zu beschreiben, z. B. das Verfolgen einer bestimmten Kamerabahn. Zum Beispiel fanden sie heraus, dass Tiere und Menschen während des Generierungsprozesses spontan auftauchten, insbesondere in Szenen mit vielen Entitäten. Im Beispiel unten lautete Prompt ursprünglich „Fünf graue Wolfswelpen, die auf einer abgelegenen Schotterstraße, umgeben von Gras, spielten und sich gegenseitig jagten. Die Welpen rannten, sprangen, jagten, bissen und spielten miteinander.“ Aber das erzeugte „Kopieren und Einfügen“-Bild erinnert sehr an einige mysteriöse Geisterlegenden: 
Es gibt auch das folgende Beispiel: Vor und nach dem Ausblasen der Kerze hat sich die Flamme überhaupt nicht verändert. Es ist seltsam : 
Wir wissen sehr wenig über die Details des Modells hinter Sora. Laut dem OpenAI-Blog werden weitere Informationen in späteren technischen Artikeln veröffentlicht. Einige grundlegende Informationen im Blog: Sora ist ein Diffusionsmodell, das Videos generiert, die zunächst wie statisches Rauschen aussehen, und das Video dann schrittweise transformiert, indem das Rauschen in mehreren Schritten entfernt wird. Die Bild- und Videogeneratoren von Midjourney und Stable Diffusion basieren ebenfalls auf Diffusionsmodellen. Aber wir können sehen, dass die Qualität der von OpenAI Sora generierten Videos viel besser ist. Sora hat das Gefühl, ein echtes Video zu erstellen, während frühere Modelle dieser Konkurrenten wie Stop-Motion-Animationen von KI-generierten Bildern wirkten. Sora kann das gesamte Video auf einmal generieren oder das generierte Video verlängern, um es länger zu machen. Indem das Modell mehrere Bilder gleichzeitig vorsieht, löst OpenAI das anspruchsvolle Problem, sicherzustellen, dass das Motiv auch dann intakt bleibt, wenn es vorübergehend die Sichtlinie verlässt. Ähnlich wie das GPT-Modell nutzt auch Sora die Transformer-Architektur, um eine hervorragende Skalierbarkeitsleistung zu erzielen. OpenAI stellt Videos und Bilder als eine Sammlung kleinerer Dateneinheiten dar, die als Patches bezeichnet werden. Jeder Patch ähnelt einem Token in GPT. Durch die Vereinheitlichung der Datendarstellung kann OpenAI Diffusionstransformatoren auf ein breiteres Spektrum visueller Daten als je zuvor trainieren, einschließlich verschiedener Dauer, Auflösungen und Seitenverhältnisse. Sora basiert auf früheren Forschungen zu DALL・E- und GPT-Modellen. Es nutzt die Rekapitulationstechnologie von DALL・E 3, um aussagekräftige Untertitel für visuelle Trainingsdaten zu generieren. Dadurch ist das Modell in der Lage, den Texthinweisen des Benutzers in den generierten Videos genauer zu folgen. Das Modell ist nicht nur in der Lage, Videos ausschließlich auf Basis von Textbeschreibungen zu generieren, sondern kann auch Videos auf Basis vorhandener statischer Bilder generieren und den Bildinhalt präzise und sorgfältig animieren. Das Modell kann auch vorhandene Videos extrahieren und erweitern oder fehlende Frames ergänzen. Referenzlink: https://openai.com/soraDas obige ist der detaillierte Inhalt vonGeschenkpaket zum Frühlingsfest! OpenAI veröffentlicht sein erstes Videogenerierungsmodell, ein 60-sekündiges High-Definition-Meisterwerk, das Internetnutzer beeindruckt. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!