
Heim >Technologie-Peripheriegeräte >KI >OpenAI veröffentlicht ein neues Konsistenzmodell, die GAN-Geschwindigkeit erreicht 18 FPS und kann in Echtzeit qualitativ hochwertige Bilder erzeugen.
OpenAI veröffentlicht ein neues Konsistenzmodell, die GAN-Geschwindigkeit erreicht 18 FPS und kann in Echtzeit qualitativ hochwertige Bilder erzeugen.

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBnach vorne
- 2023-04-22 09:58:091987Durchsuche
Die Popularität von ChatGPT und Midjourney hat das Technologiediffusionsmodell dahinter zur Grundlage der Revolution der „generativen KI“ gemacht.
Sogar es ist bei Forschern in der Branche sehr gefragt und seine Popularität übertrifft die von GAN, das einst die Welt angriff, bei weitem.
Gerade als Diffusionsmodelle am leistungsstärksten sind, verkündeten einige Internetnutzer plötzlich in großer Öffentlichkeit:
Die Ära der Diffusionsmodelle ist vorbei! Konsistenzmodelle werden zum König gekrönt!

Was zum Teufel ist da los? ? ?
Es stellt sich heraus, dass OpenAI im März ein Blockbuster- und wertvolles Papier „Consistency Models“ veröffentlicht hat und heute die Modellgewichte auf GitHub veröffentlicht hat.

Papieradresse: https://arxiv.org/abs/2303.01469
Projektadresse: https://github.com/openai/consistency_models
Die Das „Konsistenzmodell“ untergräbt das Diffusionsmodell in Bezug auf die Trainingsgeschwindigkeit. Es kann einfache Aufgaben „in einem Schritt generieren“ und eine Größenordnung schneller erledigen als das Diffusionsmodell und erfordert 10–2000 Mal weniger Berechnungen.

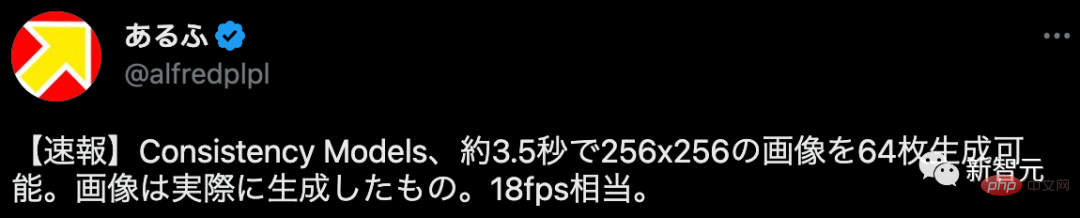
Einige Internetnutzer sagten, dass dies der Erzeugung von 64 Bildern mit einer Auflösung von 256 x 256 in etwa 3,5 Sekunden entspricht, was
18 Bildern pro Sekunde entspricht!

, sowie den chinesischen Gelehrten Mark Chen und Prafulla Dhariwal, die DALL-E entwickelt haben, verfasst 2. Sie können sich vorstellen, wie hartnäckig der Forschungsinhalt ist. Einige Internetnutzer sagten sogar, dass das „Konsistenzmodell“ die zukünftige Forschungsrichtung ist. Ich glaube, wir werden in Zukunft definitiv über das Diffusionsmodell lachen.

Schneller, stärker, kein Grund zur Konfrontation
Derzeit ist dieses Papier noch eine unvollendete Version und die Forschung ist noch im Gange.
Im Jahr 2021 schrieb OpenAI-CEO Sam Altman einen Blog, in dem er erörterte, wie Moores Gesetz auf alle Bereiche angewendet werden sollte.

Altman hat vor einiger Zeit öffentlich auf Twitter über die Entwicklung künstlicher Intelligenz gesprochen Erkenne den „Sprungsprung“. Er sagte: „Eine neue Version des Mooreschen Gesetzes könnte bald erscheinen, wobei sich die Zahl der Intelligenzen im Universum alle 18 Monate verdoppelt.“ 🎜#
Für andere mag Altmans Optimismus unbegründet erscheinen .

Man sagt, dass 2022 das erste Jahr von AIGC ist, weil Viele Modelle hinter Quanguang basieren auf dem Diffusionsmodell.

Allerdings ist das neu vorgeschlagene „Konsistenzmodell“ nachweislich in der Lage, in kürzerer Zeit die gleichen Qualitätsinhalte wie das Diffusionsmodell auszugeben.
Dies liegt daran, dass dieses „Konsistenzmodell“ einen einstufigen Generierungsprozess ähnlich wie GAN verwendet.
Im Gegensatz dazu verwendet das Diffusionsmodell einen wiederholten Abtastprozess, um das Rauschen im Bild schrittweise zu beseitigen.
Diese Methode ist zwar beeindruckend, erfordert aber die Durchführung von Hunderten bis Tausenden Schritten, um gute Ergebnisse zu erzielen, was nicht nur teuer in der Durchführung, sondern auch langsam ist.
Der kontinuierliche iterative Generierungsprozess des Diffusionsmodells ist besser als der „ Konsistenzmodell“ Es verbraucht 10-2000 Mal mehr Rechenleistung und verlangsamt sogar die Inferenzgeschwindigkeit während des Trainings.
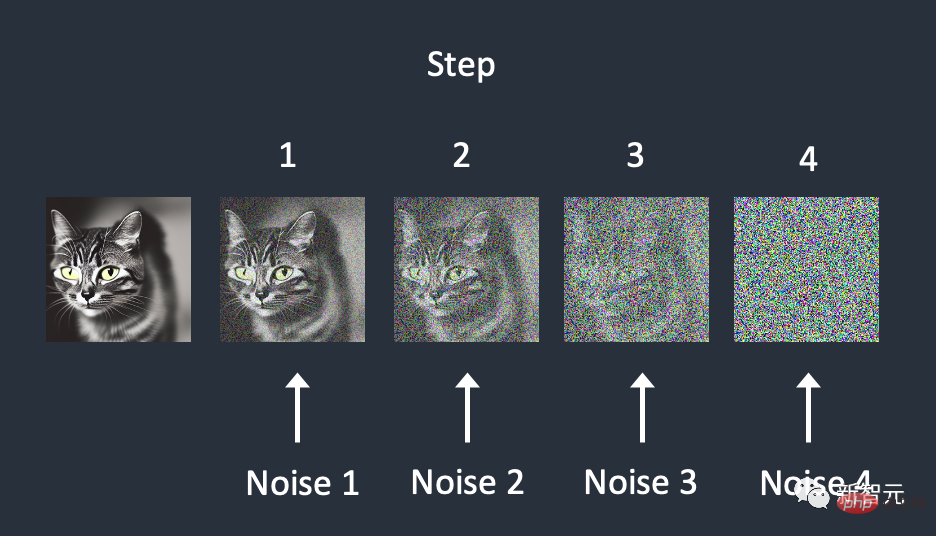
Darüber hinaus ist dieses Modell in der Lage, Zero-Shot-Datenbearbeitungsaufgaben wie Bildpatching, Kolorierung oder strichgeführte Bildbearbeitung durchzuführen.
Verwendet durch Destillation auf LSUN Bedroom 256^256 The Das trainierte Konsistenzmodell führt eine Zero-Shot-Bildbearbeitung durch. Die resultierende Ausgabe ist für ähnliche Datenpunkte konsistent und ermöglicht reibungslose Übergänge zwischen ihnen. 
Diese Art von Gleichung wird „Gewöhnliche Wahrscheinlichkeitsfluss-Differentialgleichung“ (Probability Flow ODE) genannt.
Diese Studie nannte diesen Modelltyp „Konsistenz“, weil sie diese Selbstkonsistenz zwischen Eingabedaten und Ausgabedaten aufrechterhalten. Diese Modelle können entweder im Destillationsmodus oder im Isolationsmodus trainiert werden. Im Destillationsmodus ist das Modell in der Lage, Daten aus einem vorab trainierten Diffusionsmodell zu extrahieren, sodass es in einem einzigen Schritt ausgeführt werden kann. Im getrennten Modus ist das Modell überhaupt nicht vom Diffusionsmodell abhängig, was es zu einem völlig unabhängigen Modell macht. 
Es ist erwähnenswert, dass beide Trainingsmethoden ein „Konfrontationstraining“ sind daraus gelöscht.
Ich muss zugeben, dass gegnerisches Training tatsächlich ein leistungsfähigeres neuronales Netzwerk hervorbringen wird, aber der Prozess ist komplizierter. Das heißt, es führt einen Satz falsch klassifizierter gegnerischer Stichproben ein und trainiert dann das neuronale Zielnetzwerk mit den richtigen Bezeichnungen neu.
Daher führt das gegnerische Training auch zu einem leichten Rückgang der Genauigkeit von Deep-Learning-Modellvorhersagen und kann bei Roboteranwendungen sogar zu unerwarteten Nebenwirkungen führen.
Experimentelle Ergebnisse zeigen, dass die zum Training des „Konsistenzmodells“ verwendete Destillationstechnik besser ist als die für das Diffusionsmodell verwendete.
Das „Konsistenzmodell“ erreichte die neuesten hochmodernen FID-Werte von 3,55 und 6,20 für den CIFAR10-Bildsatz bzw. den ImageNet 64x64-Datensatz.
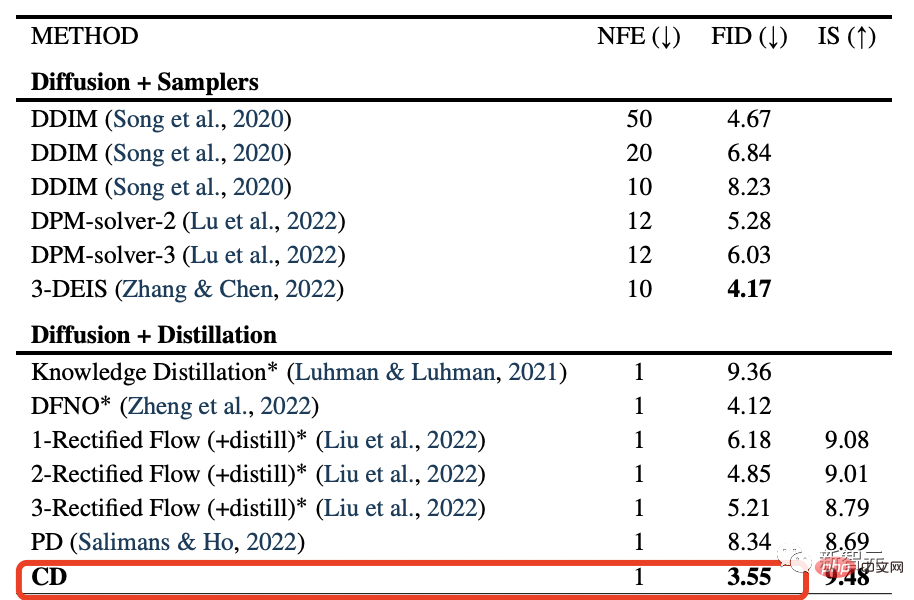
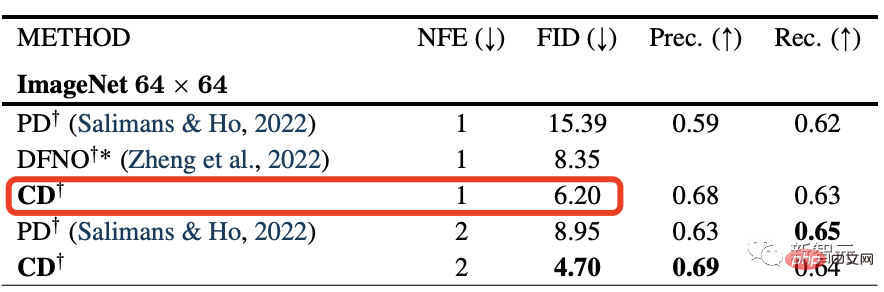
Dies ist einfach zu erkennen, die Qualität des Diffusionsmodells + die Geschwindigkeit von GAN, doppelte Perfektion.
Im Februar veröffentlichte Sutskever einen Tweet, in dem er Folgendes vorschlug:
Viele Menschen glauben, dass großer KI-Fortschritt ein neues „ Ideen". Aber das ist nicht der Fall: Viele der größten Fortschritte der KI sind in Form dieser vertrauten, bescheidenen Idee entstanden, die, wenn sie gut umgesetzt wird, unglaublich wird.
Neueste Untersuchungen beweisen genau das, und die Optimierung eines alten Konzepts kann alles verändern. Ilya Sutskever
Keine Notwendigkeit, ins Detail zu gehen, schauen Sie sich einfach dieses Gruppenfoto der „Top-Handler“ an.(Bild ganz rechts) # 🎜🎜#
Yang Song(松飏)
#🎜 🎜#Papier Yang Song ist Forschungswissenschaftler bei OpenAI.
Zuvor erhielt er einen Bachelor-Abschluss in Mathematik und Physik von der Tsinghua-Universität sowie einen Master- und Doktortitel in Informatik von der Stanford University. Darüber hinaus absolvierte er Praktika bei Google Brain, Uber ATG und Microsoft Research.
Als Forscher für maschinelles Lernen konzentriert er sich auf die Entwicklung skalierbarer Methoden zur Modellierung, Analyse und Generierung komplexer hochdimensionaler Daten. Seine Interessen umfassen mehrere Bereiche, darunter generative Modellierung, Repräsentationslernen, probabilistisches Denken, Sicherheit künstlicher Intelligenz und KI für die Wissenschaft.
Mark Chen

Mark Chen ist OpenAI Leiter der multimodalen und Grenzforschung und Trainer des U.S. Computer Olympiad Teams.
Zuvor erwarb er einen Bachelor-Abschluss in Mathematik und Informatik am MIT und arbeitete als Quant bei mehreren Eigenhandelsfirmen, darunter bei Jane Street Capital Trader.
Nach seinem Beitritt zu OpenAI leitete er das Team zur Entwicklung von DALL-E 2 und führte Vision in GPT-4 ein. Darüber hinaus leitete er die Entwicklung von Codex, beteiligte sich am GPT-3-Projekt und erstellte Image GPT.
Prafulla Dhari Wal ist OpenAI ist ein Forscher, der sich mit generativen Modellen und unbeaufsichtigtem Lernen beschäftigt. Davor war er Student am MIT und studierte Informatik, Mathematik und Physik.
 Interessanterweise kann das Diffusionsmodell GAN im Bereich der Bilderzeugung schlagen, was er im NeurIPS-Artikel 2021 vorgeschlagen hat.
Interessanterweise kann das Diffusionsmodell GAN im Bereich der Bilderzeugung schlagen, was er im NeurIPS-Artikel 2021 vorgeschlagen hat.
Netizen: Endlich zurück zu Open AI
# 🎜 🎜 #OpenAI hat heute den Quellcode des Konsistenzmodells geöffnet.

Endlich zurück zu Open AI.
Jeden Tag mit so vielen verrückten Durchbrüchen und Ankündigungen konfrontiert. Internetnutzer fragten: Sollen wir eine Pause machen oder schneller gehen? Dies wird den Forschern beim Training von Modellen im Vergleich zu Diffusionsmodellen erhebliche Kosteneinsparungen ermöglichen.

Einige Internetnutzer gaben auch zukünftige Anwendungsfälle des „Konsistenzmodells“ an: Echtzeitbearbeitung, NeRF-Rendering, Echtzeit-Spiel-Rendering.
 Derzeit gibt es keine Demo, aber es lohnt sich zu bestätigen, dass es die Geschwindigkeit der Bilderzeugung erheblich steigern kann und immer der Gewinner ist.
Derzeit gibt es keine Demo, aber es lohnt sich zu bestätigen, dass es die Geschwindigkeit der Bilderzeugung erheblich steigern kann und immer der Gewinner ist.
Wir haben direkt von DFÜ auf Breitband umgestellt.

Gehirn-Computer-Schnittstelle sowie ultrarealistische Bilder, die nahezu in Echtzeit generiert werden.

Das obige ist der detaillierte Inhalt vonOpenAI veröffentlicht ein neues Konsistenzmodell, die GAN-Geschwindigkeit erreicht 18 FPS und kann in Echtzeit qualitativ hochwertige Bilder erzeugen.. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Technologietrends, die Sie im Jahr 2023 im Auge behalten sollten
- Wie künstliche Intelligenz Rechenzentrumsteams neue Alltagsaufgaben beschert
- Können künstliche Intelligenz oder Automatisierung das Problem der geringen Energieeffizienz in Gebäuden lösen?
- OpenAI-Mitbegründer im Interview mit Huang Renxun: Die Argumentationsfähigkeiten von GPT-4 haben noch nicht die Erwartungen erfüllt
- Dank der OpenAI-Technologie übertrifft Bing von Microsoft Google im Suchverkehr