
Heim >Technologie-Peripheriegeräte >KI >„Smart Emergence' der Spracherzeugung: 100.000 Stunden Datentraining, Amazon bietet 1 Milliarde Parameter BASE TTS
„Smart Emergence' der Spracherzeugung: 100.000 Stunden Datentraining, Amazon bietet 1 Milliarde Parameter BASE TTS

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBnach vorne
- 2024-02-16 18:40:251379Durchsuche
Mit der rasanten Entwicklung generativer Deep-Learning-Modelle haben die Verarbeitung natürlicher Sprache (NLP) und Computer Vision (CV) erhebliche Veränderungen erfahren. Von den früheren überwachten Modellen, die eine spezielle Schulung erforderten, bis hin zu einem allgemeinen Modell, das nur einfache und klare Anweisungen zur Erledigung verschiedener Aufgaben erfordert. Diese Transformation bietet uns eine effizientere und flexiblere Lösung.
Im Bereich der Sprachverarbeitung und Text-to-Speech (TTS) findet ein Wandel statt. Durch die Nutzung Tausender Stunden an Daten bringt das Modell die Synthese immer näher an die reale menschliche Sprache heran.
In einer aktuellen Studie hat Amazon BASE TTS offiziell eingeführt und damit die Parameterskala des TTS-Modells auf ein beispielloses Niveau von 1 Milliarde erhöht.

Titel des Papiers: BASE TTS: Lehren aus der Erstellung eines Text-to-Speech-Modells mit Milliarden Parametern auf 100.000 Stunden Daten
Link zum Papier: https://arxiv.org/pdf/2402.08093. pdf
BASE TTS ist ein groß angelegtes mehrsprachiges TTS-System (LTTS) mit mehreren Sprechern. Für das Training wurden etwa 100.000 Stunden öffentlich zugänglicher Sprachdaten verwendet, was doppelt so viel ist wie bei VALL-E, das zuvor über die höchste Menge an Trainingsdaten verfügte. Inspiriert durch die erfolgreiche Erfahrung von LLM behandelt BASE TTS TTS als das Problem der Vorhersage des nächsten Tokens und kombiniert es mit einer großen Menge an Trainingsdaten, um leistungsstarke Funktionen für mehrere Sprachen und mehrere Sprecher zu erzielen.
Die Hauptbeiträge dieses Artikels sind wie folgt zusammengefasst:
Das vorgeschlagene BASE TTS ist derzeit das größte TTS-Modell mit 1 Milliarde Parametern und wird auf der Grundlage eines Datensatzes trainiert, der aus 100.000 Stunden öffentlich zugänglicher Sprachdaten besteht. Durch die subjektive Bewertung übertrifft BASE TTS das öffentliche LTTS-Basismodell in der Leistung.
In diesem Artikel wird gezeigt, wie Sie die Fähigkeit von BASE TTS, geeignete Prosodie für komplexe Texte wiederzugeben, verbessern können, indem Sie sie auf größere Datensätze und Modellgrößen erweitern. Um das Textverständnis und die Wiedergabefähigkeiten groß angelegter TTS-Modelle zu bewerten, entwickelten die Forscher einen Testsatz für „Emergent Capability“ und berichteten über die Leistung verschiedener Varianten von BASE TTS bei diesem Benchmark. Die Ergebnisse zeigen, dass mit zunehmender Größe des Datensatzes und zunehmender Anzahl von Parametern die Qualität von BASE TTS schrittweise verbessert wird.
3. Es wird eine neue diskrete Sprachdarstellung basierend auf dem WavLM-SSL-Modell vorgeschlagen, die darauf abzielt, nur die phonologischen und prosodischen Informationen des Sprachsignals zu erfassen. Diese Darstellungen übertreffen grundlegende Quantisierungsmethoden und ermöglichen die Dekodierung in hochwertige Wellenformen durch einfache, schnelle und Streaming-Decoder trotz hoher Komprimierungsgrade (nur 400 Bit/s).
Als nächstes schauen wir uns die Papierdetails an.
BASIS-TTS-Modell
Ähnlich wie bei jüngsten Arbeiten zur Sprachmodellierung haben Forscher einen LLM-basierten Ansatz zur Bewältigung von TTS-Aufgaben übernommen. Text wird in ein transformatorbasiertes autoregressives Modell eingespeist, das diskrete Audiodarstellungen (sogenannte Sprachcodes) vorhersagt, die dann von einem separat trainierten Decoder, der aus linearen und Faltungsschichten besteht, in Wellenformen dekodiert werden.
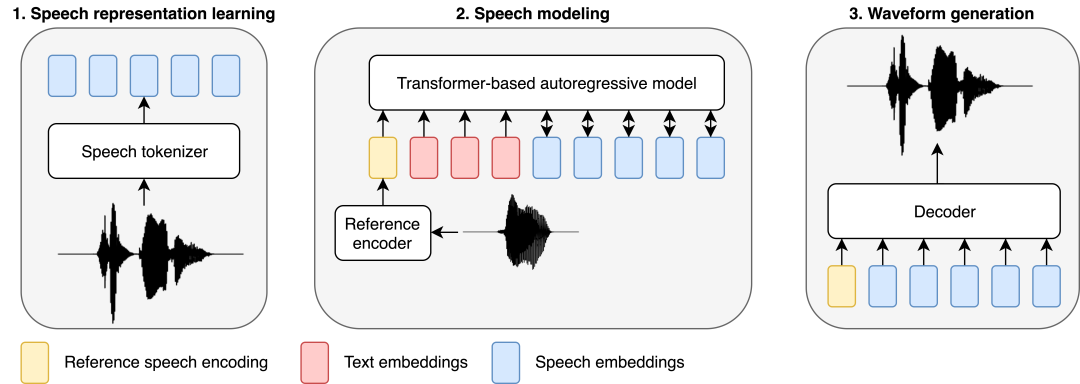
BASE TTS wurde entwickelt, um die gemeinsame Verteilung von Text-Tokens gefolgt von diskreten Sprachdarstellungen zu simulieren, was Forscher als Sprachcodierung bezeichnen. Die Diskretisierung von Sprache durch Audio-Codecs ist von zentraler Bedeutung für den Entwurf, da sie die direkte Anwendung von für LLM entwickelten Methoden ermöglicht, die die Grundlage für aktuelle Forschungsergebnisse in LTTS bilden. Konkret modellieren wir die Sprachkodierung mithilfe eines dekodierenden autoregressiven Transformers mit einem entropieübergreifenden Trainingsziel. Obwohl dieses Ziel einfach ist, kann es die komplexe Wahrscheinlichkeitsverteilung expressiver Sprache erfassen und so das Problem der übermäßigen Glättung, das in frühen neuronalen TTS-Systemen auftritt, abmildern. Als implizites Sprachmodell wird BASE TTS auch einen qualitativen Sprung bei der Prosodie-Wiedergabe machen, sobald ausreichend große Varianten auf ausreichend Daten trainiert werden.
Diskrete Sprachdarstellung
Diskrete Darstellungen sind die Grundlage für den Erfolg von LLM, aber die Identifizierung kompakter und informativer Darstellungen in der Sprache ist nicht so offensichtlich wie im Text und wurde bisher weniger erforscht. Für BASE TTS versuchten die Forscher zunächst, die VQ-VAE-Basislinie (Abschnitt 2.2.1) zu verwenden, die auf einer Autoencoder-Architektur basiert, um das Mel-Spektrogramm durch diskrete Engpässe zu rekonstruieren. VQ-VAE hat sich zu einem erfolgreichen Paradigma für die Sprach- und Bilddarstellung entwickelt, insbesondere als Modellierungseinheit für TTS.
Die Forscher stellten außerdem eine neue Methode zum Erlernen der Sprachdarstellung durch WavLM-basierte Sprachcodierung vor (Abschnitt 2.2.2). Bei diesem Ansatz diskretisieren Forscher aus dem WavLM-SSL-Modell extrahierte Merkmale, um Mel-Spektrogramme zu rekonstruieren. Die Forscher verwendeten eine zusätzliche Verlustfunktion, um die Sprechertrennung zu erleichtern, und komprimierten die generierten Sprachcodes mithilfe von Byte-Pair-Encoding (BPE), um die Sequenzlänge zu reduzieren, was die Verwendung des Transformers für längere Audiomodellierung ermöglichte.
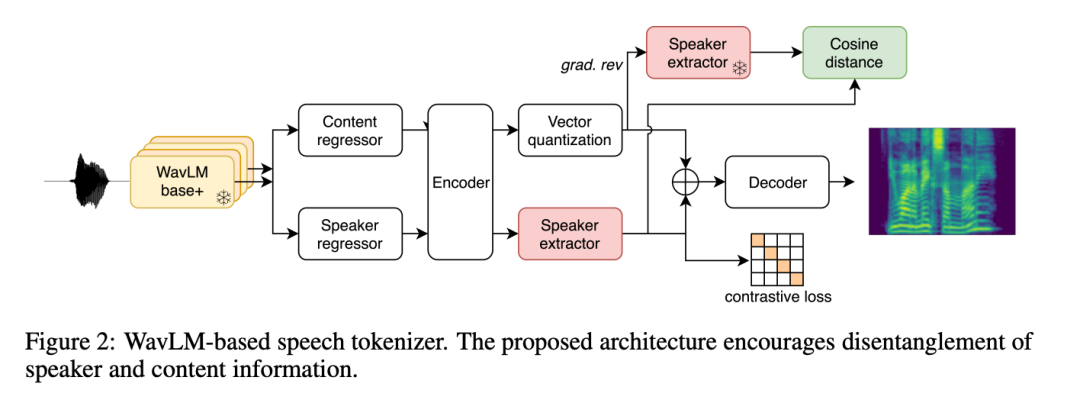
Beide Darstellungen sind komprimiert (325 Bit/s bzw. 400 Bit/s), um eine effizientere autoregressive Modellierung im Vergleich zu gängigen Audio-Codecs zu ermöglichen. Basierend auf dieser Komprimierungsstufe besteht das nächste Ziel darin, Informationen aus dem Sprachcode zu entfernen, die während der Dekodierung rekonstruiert werden können (Sprecher, Audiorauschen usw.), um sicherzustellen, dass die Kapazität des Sprachcodes hauptsächlich zur Kodierung von Phonetik und Prosodik genutzt wird Information.
Autoregressive Sprachmodellierung (SpeechGPT)
Die Forscher trainierten ein autoregressives Modell „SpeechGPT“ mit einer GPT-2-Architektur, das zur Vorhersage der Sprachcodierung abhängig von Text und Referenzsprache verwendet wird. Die Referenzsprachbedingung bestand aus zufällig ausgewählten Äußerungen desselben Sprechers, die als Einbettungen fester Größe codiert wurden. Referenz-Spracheinbettungen, Text- und Sprachkodierungen werden zu einer Sequenz verkettet, die durch ein Transformer-basiertes autoregressives Modell modelliert wird. Wir verwenden separate Positionseinbettungen und separate Vorhersageköpfe für Text und Sprache. Sie trainierten ein autoregressives Modell von Grund auf, ohne vorher Text zu trainieren. Um Textinformationen zur Steuerung der Lautmalerei zu bewahren, wird SpeechGPT auch mit dem Ziel trainiert, das nächste Token des Textteils der Eingabesequenz vorherzusagen, sodass der SpeechGPT-Teil ein Nur-Text-LM ist. Hier wird für Textverlust eine geringere Gewichtung angenommen als für Sprachverlust.
Wellenformerzeugung
Darüber hinaus spezifizierten die Forscher einen separaten Sprachcoder-zu-Wellenform-Decoder (genannt „Sprachcodec“), der für die Rekonstruktion der Sprecheridentität und der Aufnahmebedingungen verantwortlich ist. Um das Modell skalierbarer zu machen, ersetzten sie die LSTM-Schicht durch eine Faltungsschicht, um die Zwischendarstellung zu dekodieren. Untersuchungen zeigen, dass dieser auf Faltung basierende Sprachcodec recheneffizient ist und die Gesamtsynthesezeit des Systems im Vergleich zu diffusionsbasierten Basisdecodern um mehr als 70 % reduziert.
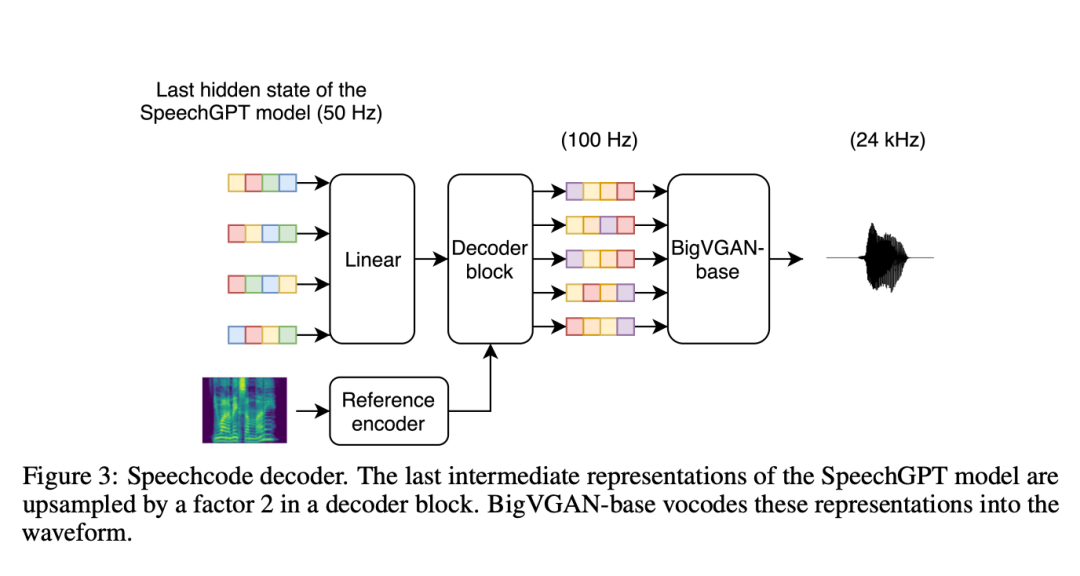
Die Forscher wiesen auch darauf hin, dass die Eingabe des Sprachcodecs tatsächlich nicht die Sprachkodierung ist, sondern der letzte verborgene Zustand des autoregressiven Transformators. Dies geschah, weil die dichten latenten Darstellungen in früheren TortoiseTTS-Methoden umfangreichere Informationen liefern als ein einzelner phonetischer Code. Während des Trainingsprozesses geben die Forscher Text und Zielcode in das trainierte SpeechGPT ein (Parameter-Einfrieren) und passen dann den Decoder basierend auf dem endgültigen verborgenen Zustand an. Die Eingabe des letzten verborgenen Zustands von SpeechGPT trägt zur Verbesserung der Segmentierung und akustischen Qualität der Sprache bei, bindet den Decoder aber auch an eine bestimmte Version von SpeechGPT. Dies erschwert Experimente, da die beiden Komponenten immer nacheinander erstellt werden müssen. Diese Einschränkung muss in zukünftigen Arbeiten behoben werden.
Experimentelle Bewertung
Die Forscher untersuchten, wie sich die Skalierung auf die Fähigkeit des Modells auswirkt, geeignete Prosodie und Ausdruck für anspruchsvolle Texteingaben zu erzeugen, ähnlich wie LLM durch Daten- und Parameterskalierung neue Fähigkeiten „entsteht“. Um zu testen, ob diese Hypothese auch auf LTTS zutrifft, schlugen die Forscher ein Bewertungsschema zur Bewertung potenziell entstehender Fähigkeiten in TTS vor und identifizierten sieben herausfordernde Kategorien: zusammengesetzte Substantive, Emotionen, Fremdwörter, Parasprache und Zeichensetzung, Probleme und syntaktische Komplexität.
Mehrere Experimente bestätigten die Struktur von BASE TTS sowie seine Qualität, Funktionalität und Rechenleistung:
Zuerst verglichen die Forscher die Modellqualität, die durch Autoencoder-basierte und WavLM-basierte Sprachcodierung erreicht wurde.
Die Forscher bewerteten dann zwei Ansätze zur akustischen Dekodierung von Sprachcodes: diffusionsbasierte Decoder und Sprachcodecs.
Nach Abschluss dieser strukturellen Ablationen haben wir die neuen Fähigkeiten von BASE TTS anhand von drei Variationen von Datensatzgröße und Modellparametern sowie durch Sprachexperten bewertet.
Darüber hinaus führten die Forscher subjektive MUSHRA-Tests zur Messung der Natürlichkeit sowie automatische Verständlichkeits- und Sprecherähnlichkeitsmessungen durch und berichteten über Sprachqualitätsvergleiche mit anderen Open-Source-Text-zu-Sprache-Modellen.
VQ-VAE-Sprachkodierung vs. WavLM-Sprachkodierung
Um die Qualität und Vielseitigkeit der beiden Sprach-Tokenisierungsmethoden umfassend zu testen, führten die Forscher MUSHRA an 6 amerikanischen Englisch- und 4 spanischen Sprechern durch. In Bezug auf die mittleren MUSHRA-Werte in Englisch waren die auf VQ-VAE und WavLM basierenden Systeme vergleichbar (VQ-VAE: 74,8 vs. WavLM: 74,7). Für Spanisch ist das WavLM-basierte Modell jedoch statistisch signifikant besser als das VQ-VAE-Modell (VQ-VAE: 73,3 vs. WavLM: 74,7). Beachten Sie, dass die englischen Daten etwa 90 % des Datensatzes ausmachen, während die spanischen Daten nur 2 % ausmachen.
Tabelle 3 zeigt die Ergebnisse nach Sprecher:
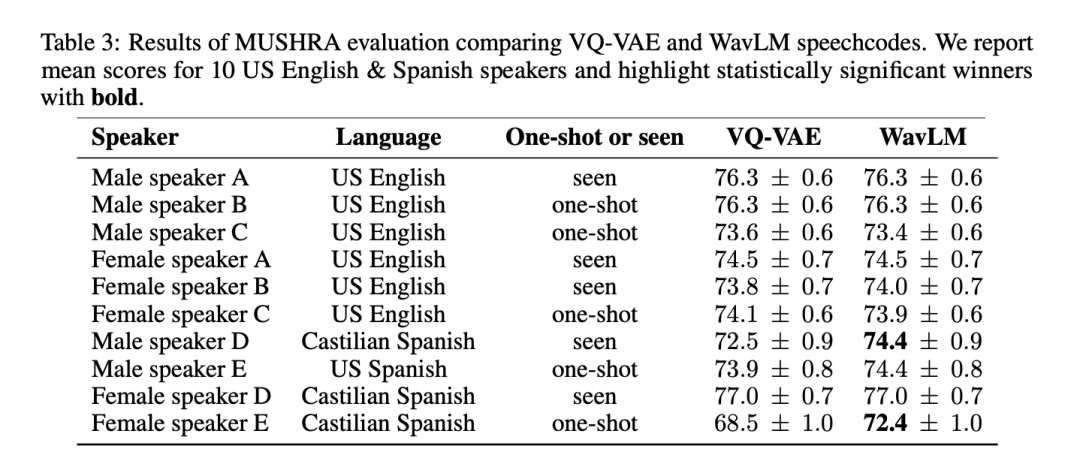
Da das WavLM-basierte System mindestens genauso gut oder besser als die VQ-VAE-Basislinie abschnitt, haben wir es zur Darstellung von BASE TTS in weiteren Experimenten verwendet.
Diffusionsbasierter Decoder vs. Sprachcode-Decoder
Wie oben erwähnt, vereinfacht BASE TTS den diffusionsbasierten Basisdecoder, indem es einen End-to-End-Sprachcodec vorschlägt. Die Methode ist fließend und verbessert die Inferenzgeschwindigkeit um das Dreifache. Um sicherzustellen, dass dieser Ansatz die Qualität nicht beeinträchtigt, wurde der vorgeschlagene Sprachcodec anhand von Basislinien bewertet. Tabelle 4 listet die Ergebnisse der MUSHRA-Bewertung für vier englischsprachige Amerikaner und zwei spanischsprachige Personen auf:
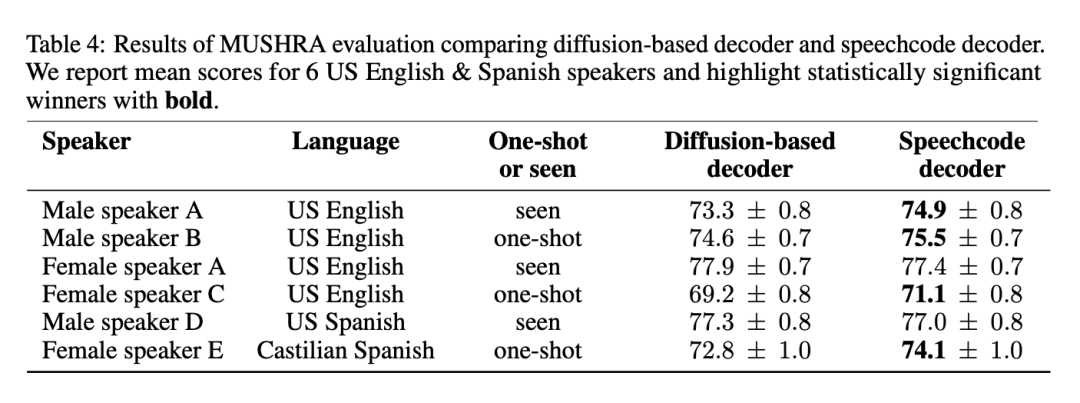
Die Ergebnisse zeigen, dass der Sprachcodec die bevorzugte Methode ist, da er die Qualität nicht beeinträchtigt. Und für die meisten Sprachen gilt: Es verbessert die Qualität und ermöglicht gleichzeitig eine schnellere Schlussfolgerung. Die Forscher stellten außerdem fest, dass die Kombination zweier leistungsstarker generativer Modelle zur Sprachmodellierung überflüssig ist und durch den Verzicht auf den Diffusionsdecoder vereinfacht werden kann.
Emergent Power: Ablation von Daten und Modellgröße
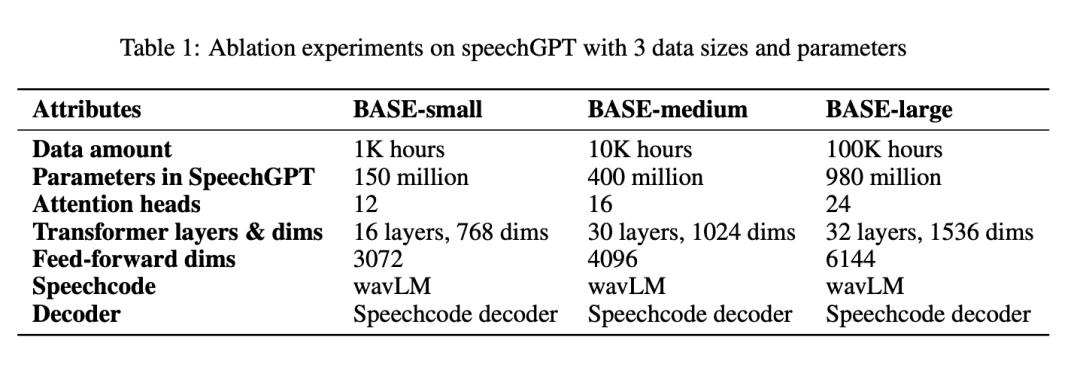
Tabelle 1 zeigt alle Parameter nach BASE-small-, BASE-medium- und BASE-large-Systemen:
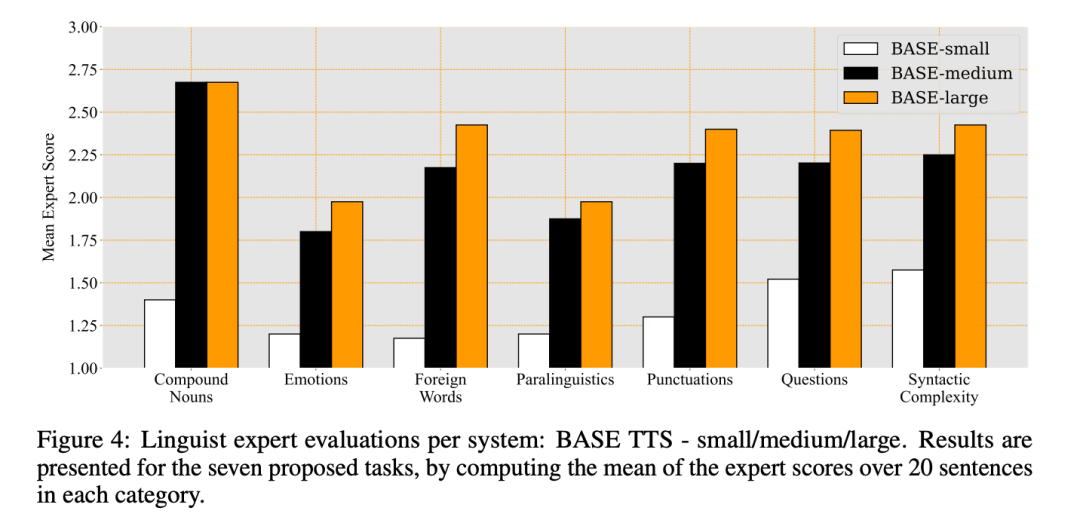
Ergebnisse der Sprachexpertenbeurteilung für die drei Systeme und jedes Die Durchschnittswerte jeder Kategorie sind in Abbildung 4 dargestellt:
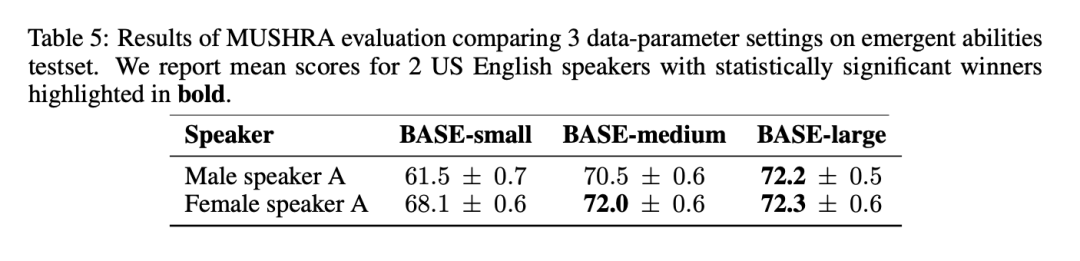
In den MUSHRA-Ergebnissen in Tabelle 5 ist zu erkennen, dass sich die Natürlichkeit der Sprache von BASE-klein auf BASE-mittel deutlich verbessert, von BASE-mittel auf BASE – Die Verbesserung von groß ist geringer:
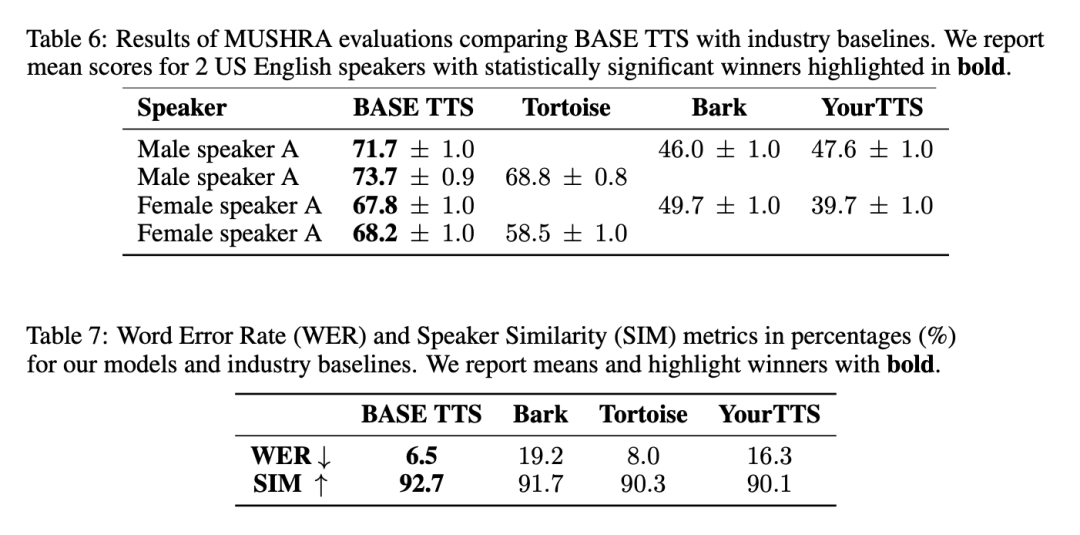
BASE TTS im Vergleich zum Branchenstandard
Im Allgemeinen erzeugt BASE TTS die natürlichste Sprache, weist die geringste Abweichung vom Eingabetext auf und ist dem am ähnlichsten Die relevanten Ergebnisse sind in Tabelle 6 und Tabelle 7 aufgeführt:
Verbesserung der Syntheseeffizienz durch den Sprachcodec
Der Sprachcodec ist in der Lage, die Sprache zu streamen, d. h. Sprache inkrementell zu erzeugen Benehmen. Durch die Kombination dieser Fähigkeit mit autoregressivem SpeechGPT kann das System eine erste Byte-Latenz von nur 100 Millisekunden erreichen – genug, um mit nur wenigen dekodierten Sprachcodes verständliche Sprache zu erzeugen.
Diese minimale Latenz steht in scharfem Gegensatz zu diffusionsbasierten Decodern, bei denen die gesamte Sprachsequenz (ein oder mehrere Sätze) auf einmal generiert werden muss, wobei die Latenz des ersten Bytes der gesamten Generierungszeit entspricht.
Darüber hinaus stellten die Forscher fest, dass der Sprachcodec das gesamte System im Vergleich zur Diffusionsbasislinie um den Faktor 3 recheneffizienter machte. Sie führten einen Benchmark durch, der 1000 Anweisungen mit einer Dauer von etwa 20 Sekunden und einer Stapelgröße von 1 auf einer NVIDIA® V100-GPU generierte. Im Durchschnitt benötigt ein SpeechGPT mit Milliarden Parametern unter Verwendung eines Diffusionsdecoders 69,1 Sekunden, um die Synthese abzuschließen, während das gleiche SpeechGPT unter Verwendung eines Sprachcodecs nur 17,8 Sekunden benötigt.
Weitere Forschungsdetails finden Sie im Originalpapier.
Das obige ist der detaillierte Inhalt von„Smart Emergence' der Spracherzeugung: 100.000 Stunden Datentraining, Amazon bietet 1 Milliarde Parameter BASE TTS. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Technologische Innovationen beschleunigen die Umsetzung der Gehirn-Computer-Schnittstellenindustrie meines Landes
- Südkorea kündigte an, in den nächsten fünf Jahren 500 Milliarden Won zu investieren, um die Kernindustrie der KI-Technologie zu unterstützen.
- Inländische humanoide Allzweckroboter werden auf den Markt kommen und die Branche wird Durchbrüche beschleunigen
- Lohnt sich der Kauf von Amazon Fire HD 10 Plus (2021)?