
Heim >System-Tutorial >LINUX >Machen Sie eine Bestandsaufnahme von 12 Befehlen zur Leistungsoptimierung in Linux-Systemen.
Machen Sie eine Bestandsaufnahme von 12 Befehlen zur Leistungsoptimierung in Linux-Systemen.

- 王林nach vorne
- 2024-02-13 10:54:311391Durchsuche
Leistungsoptimierung war schon immer eine der wichtigsten Aufgaben für Betriebs- und Wartungsingenieure, wenn Sie eine langsame Systemreaktion, einen abnormalen Festplatten-IO-Durchsatz, eine niedrigere Datenverarbeitungsgeschwindigkeit als erwartet in Ihrer Produktionsumgebung oder wenn die CPU oder der Speicher überlastet sind Festplatten-, Netzwerk- und andere Systemressourcen sind schon lange erschöpft, dann wird Ihnen dieser Artikel wirklich helfen. Wenn nicht, speichern Sie ihn bitte zuerst.

1, Lesegeschwindigkeit der HDParm-Prüfhärte:
命令:hdparm -t /dev/sda5 打印:Timing buffered disk reads: 254 MB in 3.01 seconds = 84.34 MB/sec 说明:能够指定具体的哪块硬盘进行查询的哦!
2, iostat erkennt den Festplatten-IO-Status:
格式:iostat [ -c | -d ] [ -k ] [ -t ] [ -V ] [ -x [ device ] ] [ interval ] 描述:iostat是I/O statistics(输入/输出统计)的缩写,iostat工具将对系统的磁盘操作活动进行监视。它的特点是汇报磁盘活动统计情况,同时也会汇报出CPU使用情况,同vmstat一样,iostat也有一个弱点,就是它不能对某个进程进行深入分析,仅对系统的整体情况进行分析,每1秒检测统计一次(共5次)。

“
blk_read/s Anzahl der pro Sekunde gelesenen Datenblöcke
blk_wrtn/s Anzahl der pro Sekunde geschriebenen Datenblöcke
blk_read stellt die Anzahl aller gelesenen Datenblöcke dar
blk_wrtn stellt die Anzahl aller geschriebenen Datenblöcke dar
“
3, vmstat meldet Speicher- und CPU-Status:
名称:报告虚拟内存的统计信息 格式:vmstat [-n] [延时[次数]]

| R: | 运行和等待CPU时间片的进程数。Wenn die Zahl über einen längeren Zeitraum größer als die CPU ist, bedeutet dies, dass die CPU nicht ausreicht |
|---|---|
| B: | Die Anzahl der Prozesse, die auf Ressourcen warten, ist möglicherweise E/A oder Speicher |
| Wechseln Sie zur Speichergröße des Speicher-Swap-Bereichs [in KB] | |
| Die aktuelle Menge an freiem physischem Speicher [in KB] | |
| Von der Festplatte in den Speicher übertragen | |
| Vom Speicher auf die Festplatte übertragen | |
| Die Gesamtmenge der vom Blockgerät gelesenen Daten | |
| Die Gesamtmenge der auf das Blockgerät geschriebenen Daten | |
| 1000 Wenn der Wert 1000 überschreitet, liegt ein Problem mit der Lese- und Schreibgeschwindigkeit der Festplatte vor | |
| Die Anzahl der Geräteunterbrechungen pro Sekunde, die innerhalb eines bestimmten Zeitintervalls beobachtet werden [zu viele Unterbrechungen beeinträchtigen die Leistung] | |
| Die Spalte | stellt die Anzahl der pro Sekunde generierten Kontextwechsel dar|
| Stellt eine unzureichende CPU-Ressource dar | |
| Prozentsatz der von Benutzerprozessen verbrauchten CPU-Zeit | |
| Prozentsatz der von Kernelprozessen verbrauchten CPU-Zeit | |
| id: | Prozentsatz der Zeit, in der die CPU im Leerlauf ist |
| wa: | Prozentsatz der Zeit, die mit dem Warten auf IO verbracht wurde |
| runq-sz: | Anzahl der Prozesse, die im Speicher ausgeführt werden können |
| plist-sz: | Anzahl der aktiven Aufgaben im System |
显示详细信息
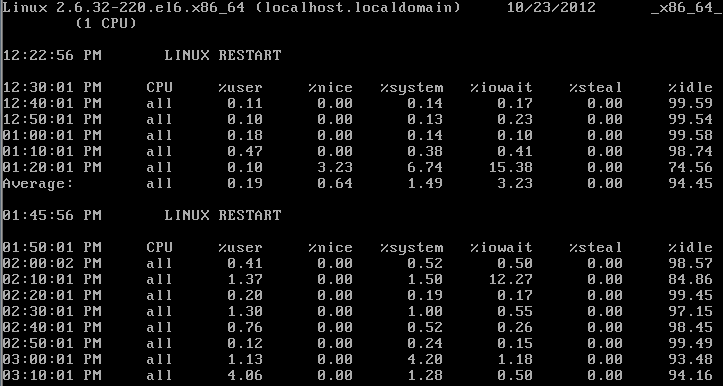
4,sar检测CPU资源:
任务计划 /etc/cron.d/sysstat 日志目录 /var/log/sa 查看方法 Sar –q –f /var/log/sa/sa10
5,lscpu显示CPU信息:
dmesg 显示出开机启动的信息 lscpu 显示CPU信息 lscpu -p 显示CPU对应的节点数 getconf LONG_BIT 获知主机的位数 getconf -a 查看全部的参数 /sys/class/dmi/id 可以查看Bios的信息 bios_*
6,strace显示程序的调用:
strace –fc elinks –dump http://localhost
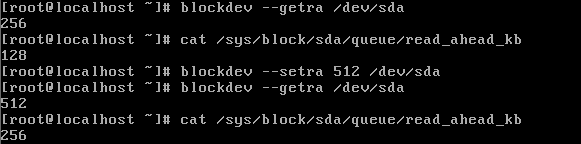
7,调优硬盘优先写入/读取数据用:
“
预先读取需要写入的量,然后再处理写请求,↑读到的值将会是设置值的一半↑。
设置读取到缓存中的数值越大.写入时就会因为数据量大而速度变慢。/sys/block/sda/queue/nr_requests 队列长度越大,硬盘IO速度会提升,但占用内存
/sys/block/sda/queue/scheduler 调度算法Noop、anticipatory、deadline、[cfq]”
8,将Ext3文件系统的日志功能独立:
“
1、创建200M的/dev/sdb1 格式化为ext3 2、dumpe2fs /dev/sdb1查看文件系统功能中包含的has_journal 3、Tune2fs –O ^has_journal /dev/sdb1 去掉默认原有的日志功能 4、再分一个200M的分区./dev/sdb2. 日志卷的block必须等于 /dev/sdb1 Mke2fs –O journal_dev –b 1024 /dev/sdb2 5、将/dev/sdb2作为/dev/sdb1的日志卷. Tune2fs –j –J device=/dev/sdb2 /dev/sdb1”
9,关闭记录文件系统atime:
对于网站文件,频繁的修改atime是没有意义的,会影响性能 mount –o remount,noatime DEVICE 即可
10、修改文件日志的提交时间:
默认是5秒提交一次日志,修改更长时间可以提高性能,但容易丢失数据。 mount –o remount,commit=15 DEVICE
11,RAID轮循写入调优,适用于0/5/6:
“
chunk size.轮循一次写入的字节.默认是64K,只要没有写满,就不会移动到下一个设备
设置在每个硬盘都只写一个文件就切换到下一块硬盘,那么如果都是1K的小文件,就会将系统资源浪费在切换硬盘上
如果将chunk size的值设置很大,比如100M,那么也就没有了意义,还不如用一块硬盘。
Stripe size.条带大小,并不是有数据就写入,而是设置每次写入的数据量,一般是16K写一次。
所以.Chunk size(64K)/stripe size(16K),也就是说每块硬盘写四次。
————————————算当前应该把chunk size调成多少————————————
使用iostat –x查看自开机以来每秒的平均请求数avgrq-sz
chunk size = 每秒请求数*512/1024/磁盘数,取一个最紧接2倍数的整数
stride = chunk size /block(默认是4k)创建raid并设置chunk sinze
mdadm –C /dev/md0 –l 0 –n3 –chunk=8 /dev/sdb[123] 修改raid
mke2fs –j –b 4096 –E stride=2 /dev/md0”
12,硬盘的block保留数:
dumpe2fs /dev/sda1 tune2fs –m 10 /dev/sda1 保留block百分比 tune2fs –r 保留block数 保留的block过少,影响性能,保留的过多又浪费硬盘,默认是5%
学习了上面的性能调优命令和方法后,再总结几条调优的金句:
独立设备性能速度比集成的强,因为不占用主机整体资源
工程师一般不会远程管理计算机,需要提供日志等信息
硬盘空间越大,读取的速度越慢,可以考虑用多块硬盘组成一块较大空间
分区只是在硬盘上做标识,而不像格式化在做文件系统特性,所以速度快
硬盘越靠外侧速度越快[分区号越小越靠外区,所以将数据量大的首先分区].
程序开发者注重雇主的功能要求,系统管理员注重程序的资源开销
Das obige ist der detaillierte Inhalt vonMachen Sie eine Bestandsaufnahme von 12 Befehlen zur Leistungsoptimierung in Linux-Systemen.. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!