
Heim >System-Tutorial >LINUX >Trockenes Zeug! 9 technische Architekturen mit hoher Leistung und hoher Parallelität
Trockenes Zeug! 9 technische Architekturen mit hoher Leistung und hoher Parallelität

- PHPznach vorne
- 2024-02-13 11:00:29651Durchsuche
Layering ist das häufigste Architekturmuster in Unternehmensanwendungssystemen. Es unterteilt das System in mehrere Teile in der horizontalen Dimension. Jeder Teil ist für eine relativ einfache und einzelne Verantwortung verantwortlich und stützt sich dann auf die unteren Schichten und plant diese .bilden ein Gesamtsystem.
In der Schichtarchitektur einer Website gibt es drei gemeinsame Schichten, nämlich Anwendungsschicht, Serviceschicht und Datenschicht. Die Anwendungsschicht ist speziell für die Anzeige von Geschäftsdaten und -ansichten verantwortlich. Die Serviceschicht bietet Serviceunterstützung für die Datenbank, die Zugriffsdienste für die Datenspeicherung bereitstellt, z. B. Datenbanken, Caches, Dateien, Suchmaschinen usw.
Die geschichtete Architektur ist logisch, da die dreistufige Architektur auf derselben physischen Maschine bereitgestellt werden kann. Bei der Entwicklung des Website-Geschäfts ist es jedoch erforderlich, die bereits geschichteten Module separat bereitzustellen Da die dreistufige Struktur separat auf verschiedenen Servern bereitgestellt wird, verfügt die Website über mehr Rechenressourcen, um immer mehr Benutzerbesuche bewältigen zu können.
Obwohl der ursprüngliche Zweck des Schichtarchitekturmodells darin besteht, eine klare logische Struktur der Software zu planen, um Entwicklung und Wartung zu erleichtern, ist die Schichtstruktur im Entwicklungsprozess der Website von entscheidender Bedeutung, damit die Website die Entwicklung einer hohen Parallelität unterstützt und verteilte Richtung.
Die Website muss 7×24 Stunden lang ununterbrochen laufen, daher muss sie über einen entsprechenden Redundanzmechanismus verfügen, um zu verhindern, dass sie beim Ausfall einer bestimmten Maschine verfügbar ist. Durch Redundanz kann eine hohe Dienstverfügbarkeit erreicht werden, indem mindestens zwei Server zur Bildung eines Clusters eingesetzt werden. Neben regelmäßigen Backups muss die Datenbank auch Hot- und Cold-Backups implementieren. Disaster-Recovery-Rechenzentren können sogar weltweit eingesetzt werden.
Wenn beim Layering die horizontale Aufteilung der Software erfolgt, dann beim Partitionieren die vertikale Aufteilung der Software.
Je größer die Website, desto komplexer die Funktionen und desto mehr Arten von Diensten und Datenverarbeitung. Die Trennung dieser verschiedenen Funktionen und Dienste und deren Paketierung in modulare Einheiten mit hoher Kohäsion und geringer Kopplung wird nicht nur die Entwicklung und Wartung der Website erleichtern Software Es erleichtert auch die verteilte Bereitstellung verschiedener Module und verbessert die gleichzeitigen Verarbeitungsfähigkeiten und Funktionserweiterungsmöglichkeiten der Website.
Die Granularität der Trennung kann bei großen Websites gering sein. Auf der Anwendungsebene sind beispielsweise verschiedene Geschäftsbereiche wie Einkaufen, Foren, Suche und Werbung in verschiedene Anwendungen unterteilt. Gegensätzliche Teams sind für sie verantwortlich und werden auf verschiedenen Servern bereitgestellt.
Bei der Verwendung von Asynchronität handelt es sich bei der Nachrichtenübermittlung zwischen Unternehmen nicht um einen synchronen Aufruf, sondern um einen Geschäftsvorgang, der in mehrere Phasen unterteilt ist und jede Phase zur Zusammenarbeit durch Datenaustausch asynchron ausgeführt wird.
Die spezifische Implementierung kann innerhalb eines einzelnen Servers durch Multithread-Shared-Memory verarbeitet werden, in einem verteilten System kann eine asynchrone Implementierung durch verteilte Nachrichtenwarteschlangen erreicht werden.
Die typische asynchrone Architektur ist die Producer-Consumer-Methode, und es gibt keinen direkten Aufruf zwischen den beiden.
Bei großen Websites besteht einer der Hauptzwecke der Schichtung und Trennung darin, die verteilte Bereitstellung geteilter Module zu erleichtern, d. h. die Bereitstellung verschiedener Module auf verschiedenen Servern und die Zusammenarbeit über Remote-Aufrufe. Verteilung bedeutet, dass mehr Computer verwendet werden können, um die gleiche Arbeit zu erledigen. Je mehr Computer, desto mehr CPU-, Speicher- und Speicherressourcen und desto mehr gleichzeitige Zugriffe und Daten können verarbeitet werden, wodurch mehr Benutzer bereitgestellt werden können.
In Website-Anwendungen gibt es mehrere häufig verwendete verteilte Lösungen.
Verteilte Anwendungen und Dienste: Die verteilte Bereitstellung mehrschichtiger und getrennter Anwendungs- und Dienstmodule kann die Leistung und Parallelität der Website verbessern, die Entwicklung und Veröffentlichung beschleunigen und den Ressourcenverbrauch der Datenbankverbindung reduzieren.
Verteilte statische Ressourcen: Die statischen Ressourcen der Website, wie JS, CSS, Logobilder und andere Ressourcen, werden verteilt bereitgestellt und verwenden unabhängige Domänennamen, was oft als Trennung von statischen und dynamischen Ressourcen bezeichnet wird. Die verteilte Bereitstellung statischer Ressourcen kann den Lastdruck auf dem Anwendungsserver verringern; das gleichzeitige Laden des Browsers wird durch die Verwendung unabhängiger Domänennamen beschleunigt.
Verteilte Daten und Speicherung: Große Websites müssen riesige Datenmengen verarbeiten, gemessen in P. Ein einzelner Computer kann keinen so großen Speicherplatz bereitstellen. Diese Datenbanken erfordern verteilten Speicher.
Verteiltes Computing: Derzeit verwenden Websites für solche Batch-Berechnungen im Allgemeinen die Distributed-Computing-Frameworks Hadoop und MapReduce, die eher durch mobiles Computing als durch mobile Daten gekennzeichnet sind.
Websites verfügen über viele Modi in Bezug auf die Sicherheitsarchitektur: Die Identitätsauthentifizierung durch Passwörter und Mobiltelefon-Verifizierungscodes muss für die Anmeldung und Transaktionen verschlüsselt werden. Um zu verhindern, dass Roboter Ressourcen missbrauchen, müssen Bestätigungscodes zur Identifizierung verwendet werden. Häufige XSS-Angriffe, SQL-Injection erfordert eine Codierungskonvertierung; Spam-Informationen müssen gefiltert werden usw.
Im Einzelnen umfasst es einen automatisierten Freigabeprozess, eine automatisierte Codeverwaltung, automatisierte Tests, eine automatisierte Sicherheitserkennung, eine automatisierte Bereitstellung, eine automatisierte Überwachung, automatisierte Alarme, ein automatisiertes Failover, eine automatisierte Wiederherstellung nach Fehlern usw.
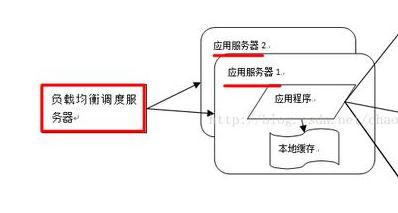
Für Module mit zentralisiertem Benutzerzugriff müssen unabhängig bereitgestellte Server geclustert werden, d. h. mehrere Server stellen dieselbe Anwendung bereit, um einen Cluster zu bilden, und stellen gemeinsam externe Dienste über Lastausgleichsgeräte bereit.
Der Servercluster kann mehr gleichzeitige Unterstützung für denselben Dienst bieten. Wenn also mehr Benutzer darauf zugreifen, müssen Sie nur neue Maschinen zum Cluster hinzufügen. Außerdem kann der Lastausgleichs-Failover-Mechanismus verwendet werden um Anfragen an andere Server im Cluster weiterzuleiten und so die Systemverfügbarkeit zu verbessern.
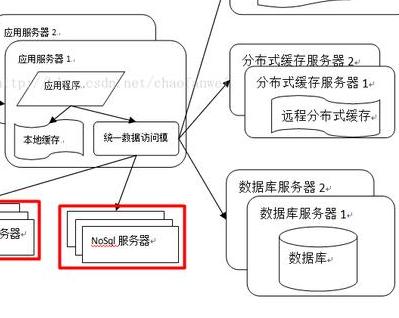
Der Zweck des Caching besteht darin, die Berechnung des Servers zu reduzieren, sodass die Daten direkt an den Benutzer zurückgegeben werden können. Im heutigen Softwaredesign ist Caching allgegenwärtig. Zu den spezifischen Implementierungen gehören CDN, Reverse-Proxy, lokaler Cache, verteilter Cache usw.
Es gibt zwei Bedingungen für die Verwendung des Caches: Unausgeglichener Zugriff auf Daten-Hotspots, d aufgrund des Datenablaufs, was sich auf die Richtigkeit der Daten auswirkt.
Das obige ist der detaillierte Inhalt vonTrockenes Zeug! 9 technische Architekturen mit hoher Leistung und hoher Parallelität. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!