
Heim >Technologie-Peripheriegeräte >KI >Terence Tao nannte ihn einen Experten, nachdem er es gesehen hatte! Google und andere nutzten LLM zum automatischen Beweisen von Theoremen und gewannen herausragende Konferenzbeiträge. Je vollständiger der Kontext, desto besser der Beweis.
Terence Tao nannte ihn einen Experten, nachdem er es gesehen hatte! Google und andere nutzten LLM zum automatischen Beweisen von Theoremen und gewannen herausragende Konferenzbeiträge. Je vollständiger der Kontext, desto besser der Beweis.

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBnach vorne
- 2024-02-04 09:30:471061Durchsuche
Der Fähigkeitsbaum von Transformer wird immer leistungsfähiger.
Forscher der University of Massachusetts, Google und der University of Illinois at Urbana-Champaign (UIUC) haben kürzlich einen Artikel veröffentlicht, in dem sie das Ziel erfolgreich erreicht haben, mithilfe großer Sprachmodelle automatisch vollständige Theorembeweise zu generieren.

Papieradresse: https://arxiv.org/pdf/2303.04910.pdf
Dieses Werk ist nach Baldur (dem Bruder von Thor in der nordischen Mythologie) benannt und es ist das erste Mal, dass dies der Fall ist Transformer kann einen vollständigen Beweis generieren. Der Beweis zeigt auch, dass frühere Beweise des Modells verbessert werden können, wenn das Modell mit zusätzlichem Kontext versehen wird.
Dieses Papier wurde im Dezember 2023 auf der ESEC/FSE (ACM European Joint Conference on Software Engineering and Symposium on Fundamentals of Software Engineering) veröffentlicht und mit dem Outstanding Paper Award ausgezeichnet.
Wie wir alle wissen, sind Fehler in Software unvermeidlich, was für allgemeine Anwendungen oder Websites möglicherweise kein allzu großes Problem darstellt. Bei der Software hinter kritischen Systemen wie Verschlüsselungsprotokollen, medizinischen Geräten und Raumfähren müssen wir jedoch sicherstellen, dass keine Fehler vorliegen.
– Allgemeine Codeüberprüfungen und -tests können diese Garantie nicht geben, was eine formelle Überprüfung erfordert.
Für die formale Verifizierung lautet die Erklärung von ScienceDirect:
der Prozess der mathematischen Überprüfung, ob das Verhalten eines Systems, das mithilfe eines formalen Modells beschrieben wird, eine bestimmte Eigenschaft erfüllt, die ebenfalls mithilfe eines formalen Modells beschrieben wird
bezieht sich auf den Prozess der mathematischen Überprüfung, ob das Verhalten eines Systems, das mithilfe eines formalen Modells beschrieben wird, gegebene Eigenschaften erfüllt.
Um es einfach auszudrücken: Mithilfe mathematischer Analysemethoden wird mithilfe einer Algorithmus-Engine ein Modell erstellt, um eine umfassende Analyse und Überprüfung des Zustandsraums des zu testenden Designs durchzuführen.
Die formale Softwareverifizierung ist eine der anspruchsvollsten Aufgaben für Softwareentwickler. Beispielsweise ist CompCert, ein C-Compiler, der mit dem interaktiven Theorembeweis Coq verifiziert wurde, der einzige Compiler, der unter anderem von den allgegenwärtigen GCC und LLVM verwendet wird.
Allerdings sind die Kosten für die manuelle formale Verifizierung (Schreiben von Beweisen) ziemlich hoch – der Beweis eines C-Compilers ist mehr als dreimal so groß wie der Compiler-Code selbst.
Die formale Verifizierung selbst ist also eine „arbeitsintensive“ Aufgabe, und Forscher erforschen auch automatisierte Methoden.
Beweisassistenten wie Coq und Isabelle trainieren ein Modell, um jeweils einen Beweisschritt vorherzusagen, und verwenden das Modell, um den möglichen Beweisraum zu durchsuchen.
Der Baldur hat in diesem Artikel zum ersten Mal die Fähigkeit großer Sprachmodelle in diesem Bereich vorgestellt, den Text und Code in natürlicher Sprache trainiert und den Beweis verfeinert.
Baldur kann einen vollständigen Beweis generieren des Theorems auf einmal, anstatt es Schritt für Schritt durchzugehen.
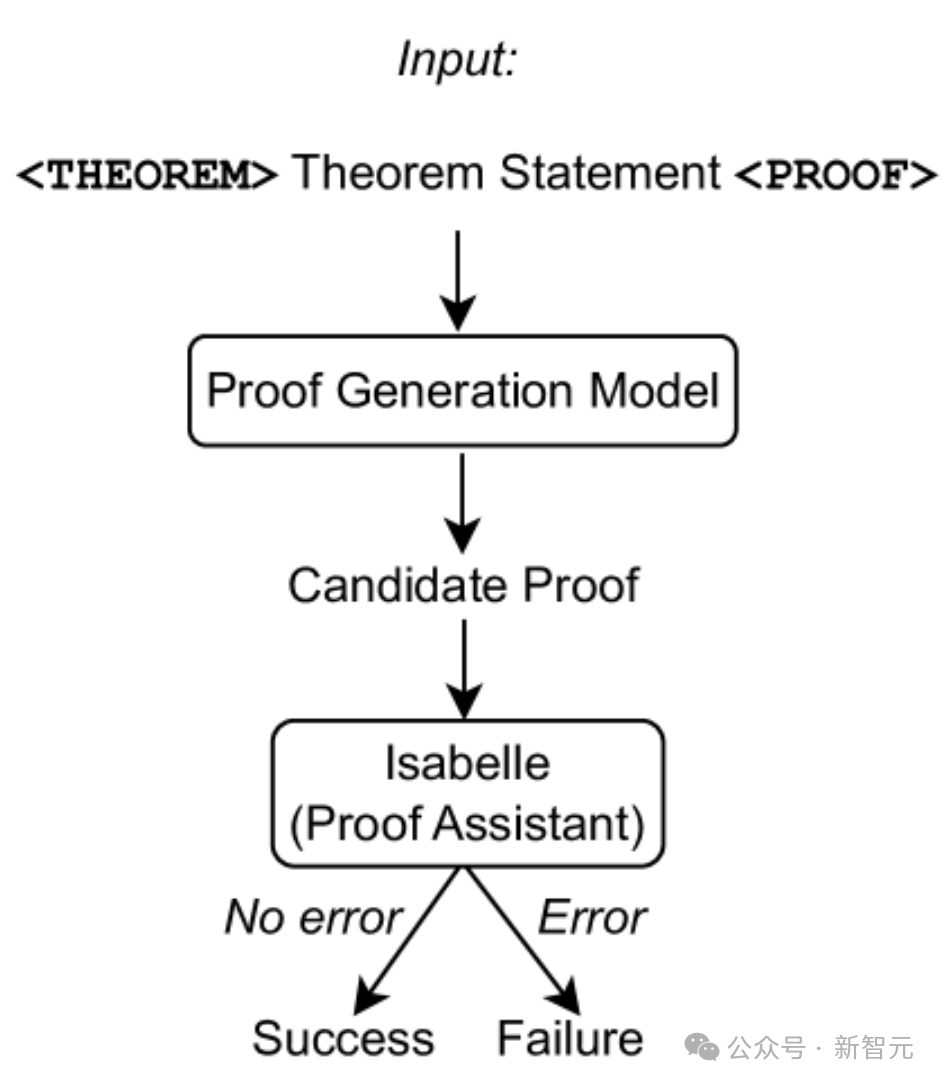
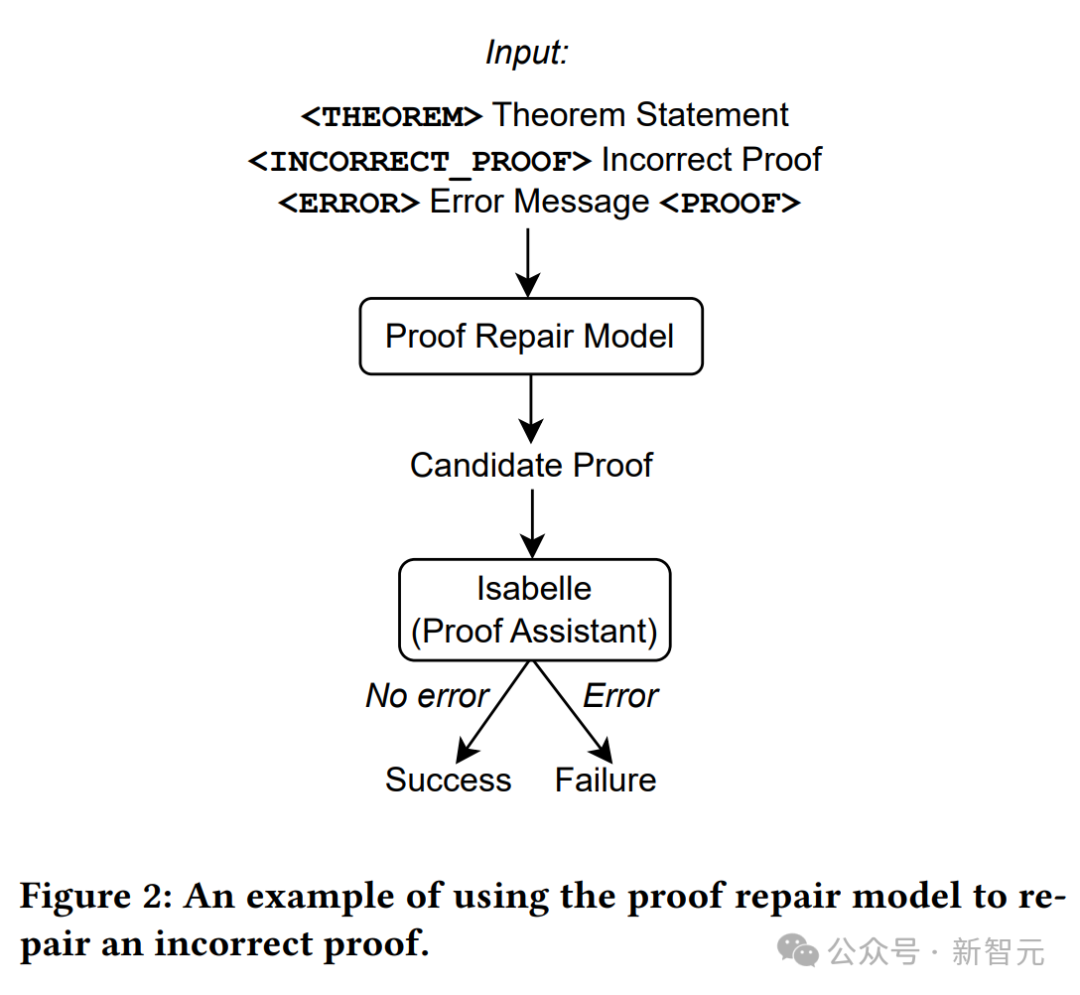
Wie in der Abbildung oben gezeigt, werden nur Theoremanweisungen als Eingabe für das Beweisgenerierungsmodell verwendet, dann werden Beweisversuche aus dem Modell extrahiert und Isabelle wird zur Beweisprüfung verwendet.
Wenn Isabelle den Beweisversuch fehlerfrei akzeptiert, ist der Beweis erfolgreich; andernfalls wird ein weiterer Beweisversuch aus dem Beweisgenerierungsmodell extrahiert.
Baldur wird anhand eines Benchmarks von 6336 Isabelle/HOL-Theoremen und ihren Beweisen bewertet und demonstriert empirisch die Wirksamkeit der vollständigen Beweiserstellung, Reparatur und Hinzufügung von Kontext.
Darüber hinaus könnte der Grund, warum dieses Tool Baldur heißt, darin liegen, dass das derzeit beste Tool zur automatischen Proof-Erstellung Thor heißt.
Thor hat eine höhere Beweisrate (57 %). Es verwendet ein kleineres Sprachmodell in Kombination mit einer Methode zum Durchsuchen des möglichen Beweisraums, um den nächsten Schritt des Beweises vorherzusagen, während Baldurs Vorteil in seiner Fähigkeit liegt, vollständige Beweise zu generieren.

Aber auch die beiden Brüder Thor und Baldur können zusammenarbeiten, was die Nachweisquote auf knapp 66 % erhöhen kann.
Automatisch vollständige Beweise generieren
Baldur basiert auf Minerva, dem großen Sprachmodell von Google, das auf wissenschaftliche Arbeiten und Webseiten mit mathematischen Ausdrücken trainiert und auf Daten zu Beweisen und Theoremen verfeinert wird.
Baldur kann mit der Theorembeweisassistentin Isabelle zusammenarbeiten, die die Beweisergebnisse überprüft. Als Baldur eine Theoremerklärung erhielt, konnte er in fast 41 % der Fälle einen vollständigen Beweis erbringen.
Um Baldurs Leistung weiter zu verbessern, stellten die Forscher dem Modell zusätzliche Kontextinformationen zur Verfügung (z. B. andere Definitionen oder Theoremaussagen in theoretischen Dokumenten), wodurch die Beweisquote auf 47,5 % stieg.
Das bedeutet, dass Baldur in der Lage ist, den Kontext zu erfassen und daraus neue korrekte Beweise vorherzusagen – ähnlich wie Programmierer, die Fehler in ihren Programmen eher beheben, wenn sie die relevanten Methoden und den Code verstehen.
Hier ist ein Beispiel (fun_sum_commute-Theorem):

Dieser Satz stammt aus einem Projekt namens Polynomials in den Formal Proof Archives.
Beim manuellen Schreiben eines Beweises werden zwei Fälle unterschieden: Die Menge ist endlich oder nicht endlich:

Für das Modell ist die Eingabe also die Satzaussage und die Zielausgabe ist dieser Mensch -schriftliche Beweise.
Baldur erkannte hier die Notwendigkeit einer Induktion und wandte eine spezielle Induktionsregel namens „infinite_finite_induct“ an, die dem gleichen allgemeinen Ansatz folgt wie menschliche schriftliche Beweise, aber prägnanter ist.
Und weil Induktion erforderlich ist, kann der von Isabelle verwendete Vorschlaghammer diesen Satz standardmäßig nicht beweisen.
Training
Um das Beweisgenerierungsmodell zu trainieren, erstellten die Forscher einen neuen Beweisgenerierungsdatensatz.
Der vorhandene Datensatz enthält Beispiele für einen einzelnen Beweisschritt, und jedes Trainingsbeispiel enthält den Beweisstatus (Eingabe) und den nächsten anzuwendenden Beweisschritt (Ziel).
Angenommen ein Datensatz, der einen einzelnen Beweisschritt enthält, müssen Sie hier einen neuen Datensatz erstellen, um das Modell zu trainieren, den gesamten Beweis auf einmal vorherzusagen.
Die Forscher extrahierten die Beweisschritte jedes Theorems aus dem Datensatz und verketteten sie, um den ursprünglichen Beweis zu rekonstruieren.
Proof-Fix
Nehmen wir immer noch das obige fun_sum_commute als Beispiel:

Baldurs erster generierter Proof-Versuch ist im Proof-Checker fehlgeschlagen.
Baldur versuchte, Induktion anzuwenden, schaffte es jedoch nicht, den Beweis zunächst in zwei Fälle aufzuteilen (endliche Menge vs. unendliche Menge). Isabelle gibt die folgende Fehlermeldung zurück:

Um aus diesen Zeichenfolgen ein Beispiel für ein Beweisreparaturtraining abzuleiten, werden hier Theoremaussagen, fehlgeschlagene Beweisversuche und Fehlermeldungen als Eingabe verkettet und ein korrekter, von Menschen geschriebener Beweis als Ziel verwendet.
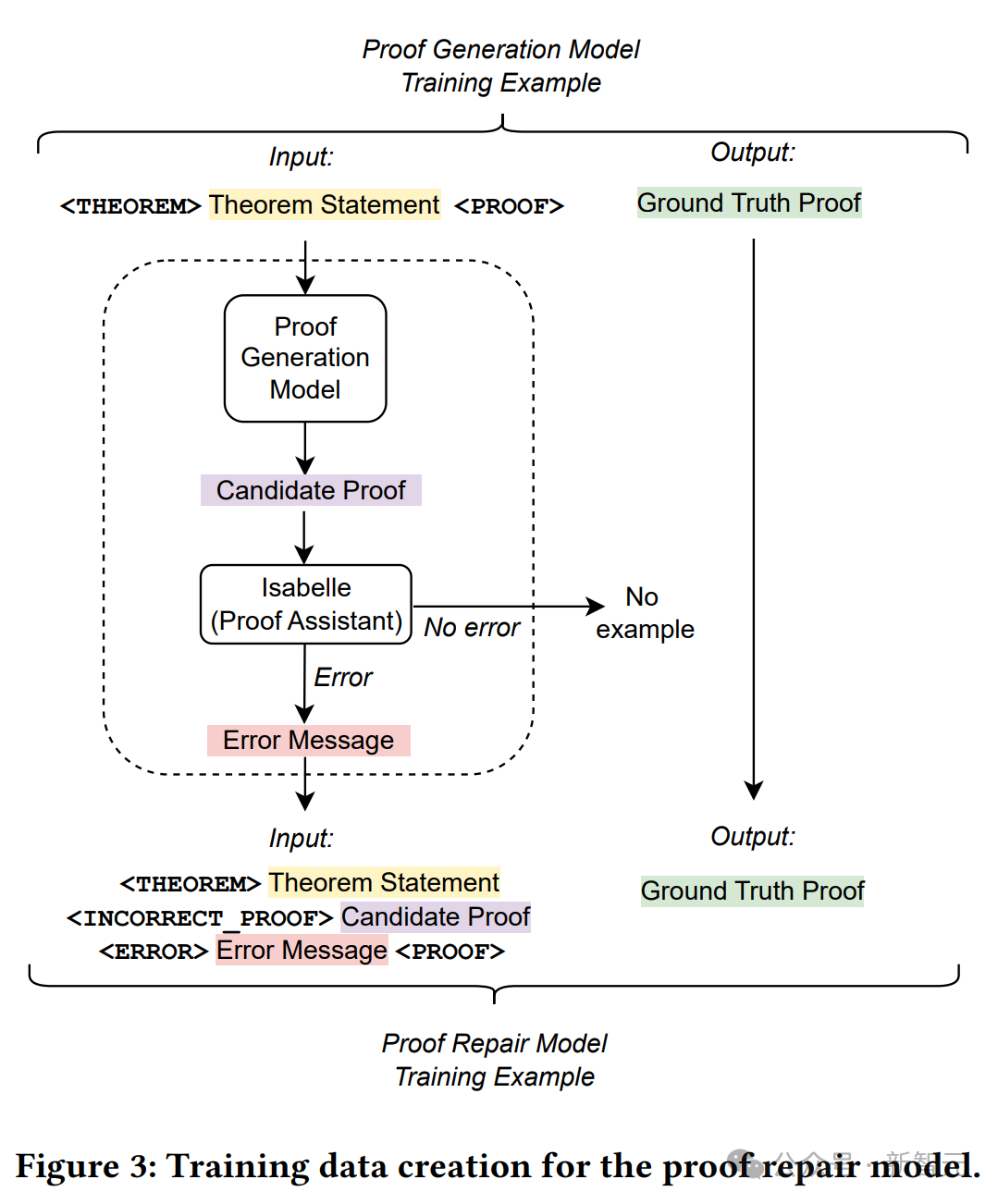
Die obige Abbildung zeigt detailliert den Erstellungsprozess von Trainingsdaten.
Verwenden Sie ein Beweisgenerierungsmodell, um Beweise mit einer Temperatur von 0 für jede Frage im ursprünglichen Trainingssatz abzutasten.
Verwenden Sie den Proofing-Assistenten, um alle fehlgeschlagenen Proofs und ihre Fehlermeldungen zu protokollieren, und fahren Sie dann mit der Erstellung eines neuen Proof-Fix-Trainingssatzes fort.
Verketten Sie für jedes ursprüngliche Trainingsbeispiel die Theoremaussage, den vom Beweisgenerierungsmodell generierten (falschen) Kandidatenbeweis und die entsprechende Fehlermeldung, um die Eingabesequenz des neuen Trainingsbeispiels zu erhalten.
Kontext hinzufügen
Fügen Sie Zeilen aus der Theoriedatei vor den Theoremaussagen als zusätzlichen Kontext hinzu. Das folgende Bild sieht beispielsweise so aus: Das Beweisgenerierungsmodell mit Kontext in Baldur kann diese zusätzlichen Informationen nutzen. Zeichenfolgen, die in den fun_sum_commute-Theorem-Anweisungen vorkommen, erscheinen in diesem Kontext erneut, sodass die sie umgebenden zusätzlichen Informationen dem Modell helfen können, bessere Vorhersagen zu treffen.
 Kontext kann eine Aussage (Satz, Definition, Beweis) oder eine Anmerkung in natürlicher Sprache sein.
Kontext kann eine Aussage (Satz, Definition, Beweis) oder eine Anmerkung in natürlicher Sprache sein.
Um die verfügbare Eingabelänge von LLM auszunutzen, addierten die Forscher zunächst bis zu 50 Aussagen aus derselben Theoriedatei.
Während des Trainings werden alle diese Anweisungen zunächst in Token umgewandelt und dann wird die linke Seite der Sequenz gekürzt, um sie an die Eingabelänge anzupassen.
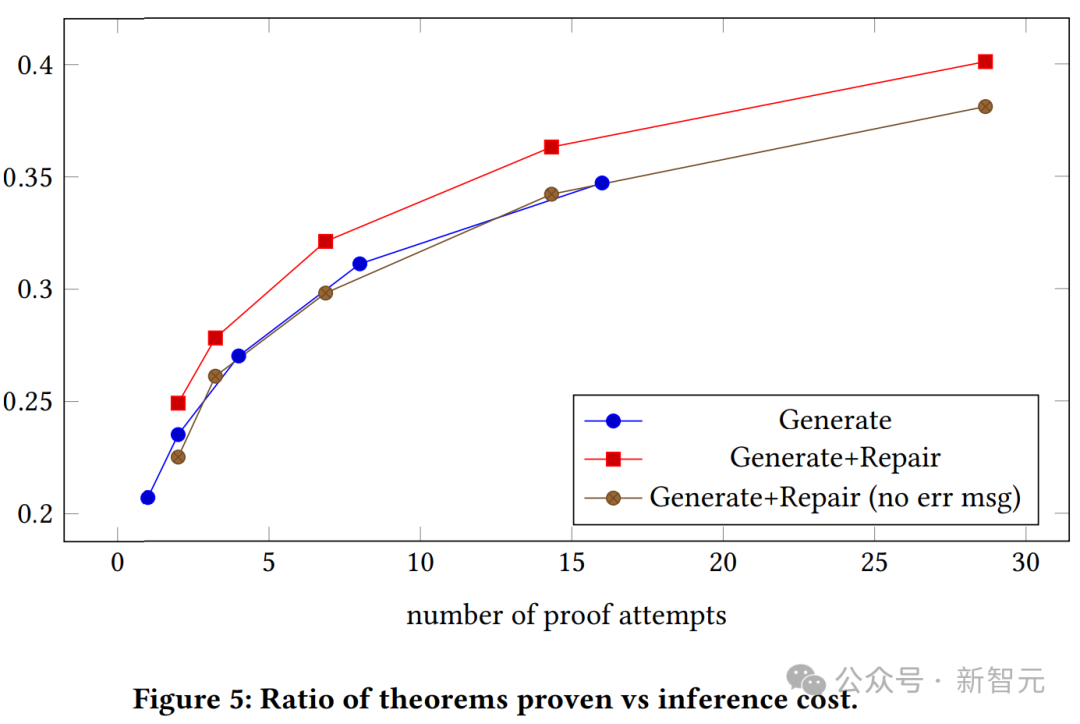
Die obige Abbildung zeigt die Beziehung zwischen der Beweiserfolgsrate und der Anzahl der Beweisversuche für kontextbezogene und kontextfreie generative Modelle. Wir können sehen, dass beweisfähige generative Modelle mit Kontext durchweg einfache generative Modelle übertreffen.
Die obige Grafik zeigt das Verhältnis von verifizierten Theoremen zu Inferenzkosten für Modelle unterschiedlicher Größe und Temperatur.
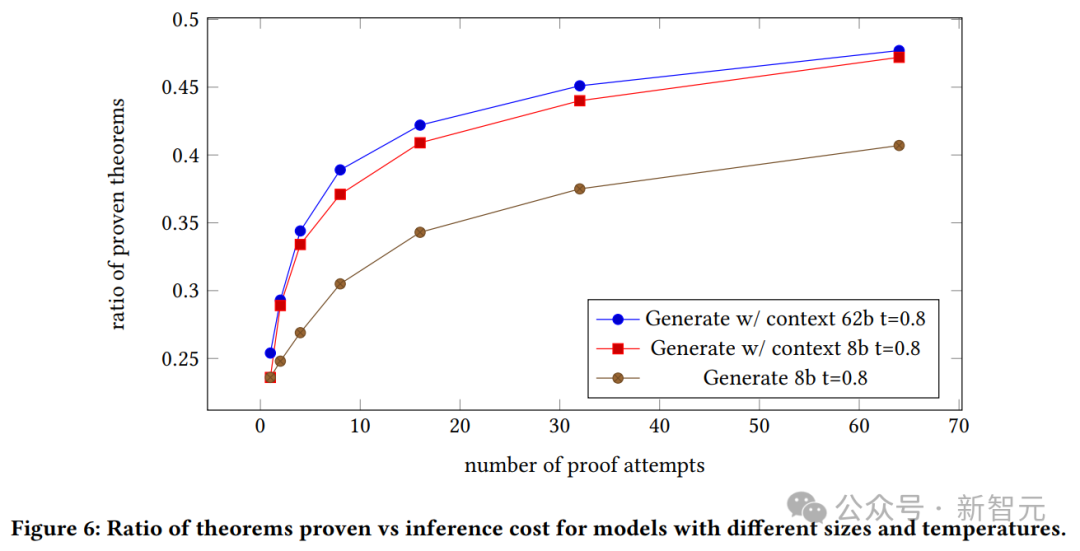 Wir können die Beweiserfolgsrate des generierten Modells sowie die Beziehung zwischen dem Kontext des 8B-Modells und des 62B-Modells und der Anzahl der Beweisversuche sehen.
Wir können die Beweiserfolgsrate des generierten Modells sowie die Beziehung zwischen dem Kontext des 8B-Modells und des 62B-Modells und der Anzahl der Beweisversuche sehen.
Das 62B-Modell mit Kontext beweist, dass das generative Modell das 8B-Modell mit Kontext übertrifft.
Die Autoren betonen hier jedoch, dass das 62B-Modell aufgrund der hohen Kosten dieser Experimente und ihrer Unfähigkeit, die Hyperparameter anzupassen, möglicherweise eine bessere Leistung erbringt, wenn es optimiert wird.
Das obige ist der detaillierte Inhalt vonTerence Tao nannte ihn einen Experten, nachdem er es gesehen hatte! Google und andere nutzten LLM zum automatischen Beweisen von Theoremen und gewannen herausragende Konferenzbeiträge. Je vollständiger der Kontext, desto besser der Beweis.. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!