
Heim >Technologie-Peripheriegeräte >KI >Ohne OpenAI sind die Gewichte, Daten und Codes alle Open Source, und das Einbettungsmodell Nomic Embed ist hier, das perfekt reproduziert werden kann.
Ohne OpenAI sind die Gewichte, Daten und Codes alle Open Source, und das Einbettungsmodell Nomic Embed ist hier, das perfekt reproduziert werden kann.

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBnach vorne
- 2024-02-04 09:54:151222Durchsuche
Vor einer Woche hat OpenAI den Benutzern Vorteile gewährt. Sie haben das Problem der Faulheit von GPT-4 gelöst und fünf neue Modelle eingeführt, darunter das Einbettungsmodell text-embedding-3-small, das kleiner und effizienter ist.
Einbettungen sind Zahlenfolgen, die zur Darstellung von Konzepten in natürlicher Sprache, Code und mehr verwendet werden. Sie helfen Modellen des maschinellen Lernens und anderen Algorithmen, besser zu verstehen, wie Inhalte zusammenhängen, und erleichtern die Durchführung von Aufgaben wie Clustering oder Abruf. Im Bereich NLP spielt die Einbettung eine sehr wichtige Rolle.
Das Einbettungsmodell von OpenAI ist jedoch nicht für jedermann kostenlos. Beispielsweise kostet text-embedding-3-small 0,00002 US-Dollar pro 1.000 Token.
Jetzt gibt es hier ein besseres Einbettungsmodell als text-embedding-3-small, und es ist kostenlos.
Nomic AI, ein KI-Startup, hat kürzlich das erste Einbettungsmodell veröffentlicht, das Open Source, offene Daten, offene Gewichtungen und offenen Trainingscode ist – Nomic Embed. Das Modell ist mit einer Kontextlänge von 8192 vollständig reproduzierbar und überprüfbar. Nomic Embed schlug die OpenAI-Modelle text-embeding-3-small und text-embedding-ada-002 sowohl in Kurz- als auch in Langkontext-Benchmarks. Dieser Erfolg markiert den wichtigen Fortschritt von Nomic AI auf dem Gebiet der eingebetteten Modelle.

Texteinbettung ist eine Schlüsselkomponente in modernen NLP-Anwendungen und bietet Retrieval Augmentation Generation (RAG)-Funktionen zur Unterstützung von LLM und semantischer Suche. Diese Technologie ermöglicht eine effizientere Verarbeitung, indem sie die semantischen Informationen eines Satzes oder Dokuments in einen niedrigdimensionalen Vektor kodiert und auf nachgelagerte Anwendungen wie Clustering zur Datenvisualisierung, Klassifizierung und Informationsabfrage anwendet. Derzeit ist text-embedding-ada-002 von OpenAI eines der beliebtesten Modelle zur Texteinbettung mit langem Kontext und unterstützt bis zu 8192 Kontextlängen. Leider ist Ada jedoch eine geschlossene Quelle und seine Trainingsdaten können nicht geprüft werden, was seine Glaubwürdigkeit einschränkt. Trotzdem ist das Modell immer noch weit verbreitet und funktioniert bei vielen NLP-Aufgaben gut. Wir hoffen, in Zukunft transparentere und überprüfbare Texteinbettungsmodelle zu entwickeln, um deren Glaubwürdigkeit und Zuverlässigkeit zu verbessern. Dies wird dazu beitragen, die Entwicklung des NLP-Bereichs voranzutreiben und effizientere und genauere Textverarbeitungsfunktionen für verschiedene Anwendungen bereitzustellen.
Die leistungsstärksten Open-Source-Modelle zum Einbetten von Langkontexttexten wie E5-Mistral und jina-embeddings-v2-base-en weisen möglicherweise einige Einschränkungen auf. Einerseits ist das Modell aufgrund der Größe möglicherweise nicht für den allgemeinen Gebrauch geeignet. Andererseits können diese Modelle möglicherweise nicht das Leistungsniveau ihrer OpenAI-Gegenstücke übertreffen. Daher müssen diese Faktoren bei der Auswahl eines für eine bestimmte Aufgabe geeigneten Modells berücksichtigt werden. Die Veröffentlichung von
Nomic-embed ändert das. Das Modell hat nur 137 Millionen Parameter, ist sehr einfach bereitzustellen und kann in 5 Tagen trainiert werden.

Papieradresse: https://static.nomic.ai/reports/2024_Nomic_Embed_Text_Technical_Report.pdf
Papiertitel: Nomic Embed: Training a Reproducible Long Context Text Embedder
Projekt Adresse: https://github.com/nomic-ai/contrastors
So erstellen Sie nomic-embed
Einer der Hauptnachteile bestehender Textencoder besteht darin, dass sie auf die Sequenzlänge beschränkt sind. die auf 512 Token begrenzt ist. Um ein Modell für längere Sequenzen zu trainieren, muss zunächst BERT so angepasst werden, dass es lange Sequenzlängen verarbeiten kann. Die Zielsequenzlänge für diese Studie war 8192.
Training von BERT mit einer Kontextlänge von 2048
Diese Studie folgt einer mehrstufigen kontrastiven Lernpipeline, um nomic-embed zu trainieren. Zunächst führte die Studie eine BERT-Initialisierung durch. Da bert-base nur eine Kontextlänge von bis zu 512 Token verarbeiten kann, entschied sich die Studie, ein eigenes BERT mit einer Kontextlänge von 2048 Token zu trainieren – nomic-bert-2048.
Inspiriert von MosaikBERT nahm das Forschungsteam einige Änderungen am Trainingsprozess von BERT vor, darunter:
- Verwenden Sie die Einbettung gedrehter Positionen, um die Extrapolation der Kontextlänge zu ermöglichen.
- Verwenden Sie die SwiGLU-Aktivierung, da sich gezeigt hat, dass sie die Modellleistung verbessert.
- Dropout auf 0 setzen.
und die folgenden Trainingsoptimierungen vorgenommen:
- Trainieren Sie mit Deepspeed und FlashAttention;
- Trainieren Sie mit BF16-Genauigkeit;
- Erhöhen Sie den Wortschatz (Wortschatz) auf ein Vielfaches von 64 ;
- Die Stapelgröße für das Training beträgt 4096.
- Während des maskierten Sprachmodellierungsprozesses beträgt die Maskierungsrate 30 % statt 15 %.
- Das nächste Satzvorhersageziel wird nicht verwendet.
Beim Training trainiert diese Studie alle Stufen mit einer maximalen Sequenzlänge von 2048 und verwendet dynamische NTK-Interpolation, um während der Inferenz eine Sequenzlänge von 8192 zu erreichen.
Experimente
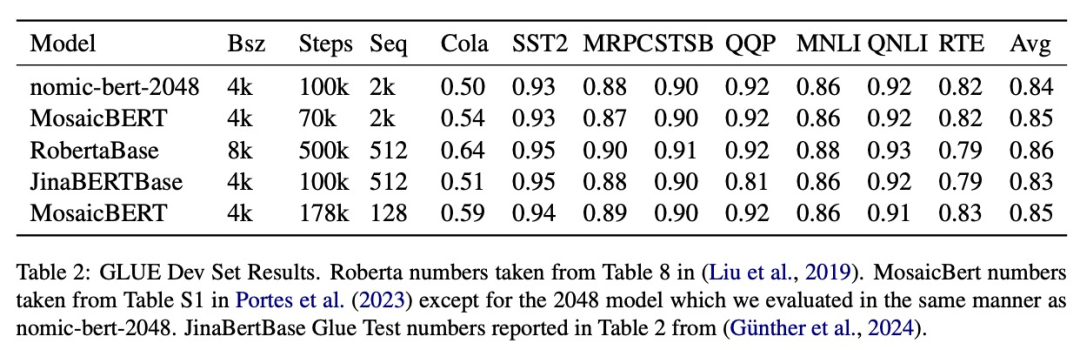
Diese Studie bewertet die Qualität von nomic-bert-2048 anhand des Standard-GLUE-Benchmarks und kommt zu dem Ergebnis, dass es auf Augenhöhe mit anderen BERT-Modellen abschneidet, jedoch mit dem Vorteil deutlich längerer Kontextlängen.
Vergleichendes Training von nomic-embed
Diese Studie verwendet nomic-bert-2048, um das Training von nomic-embed zu initialisieren. Der Vergleichsdatensatz besteht aus etwa 235 Millionen Textpaaren und seine Qualität wurde während der Erfassung umfassend mit Nomic Atlas überprüft.
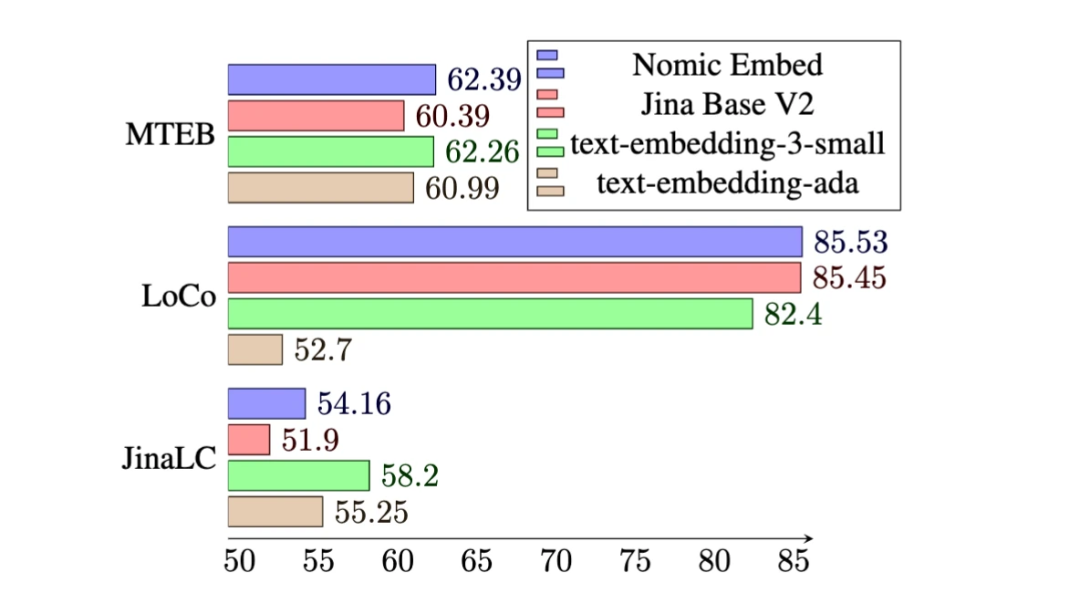
Beim MTEB-Benchmark übertrifft nomic-embed text-embedding-ada-002 und jina-embeddings-v2-base-en.
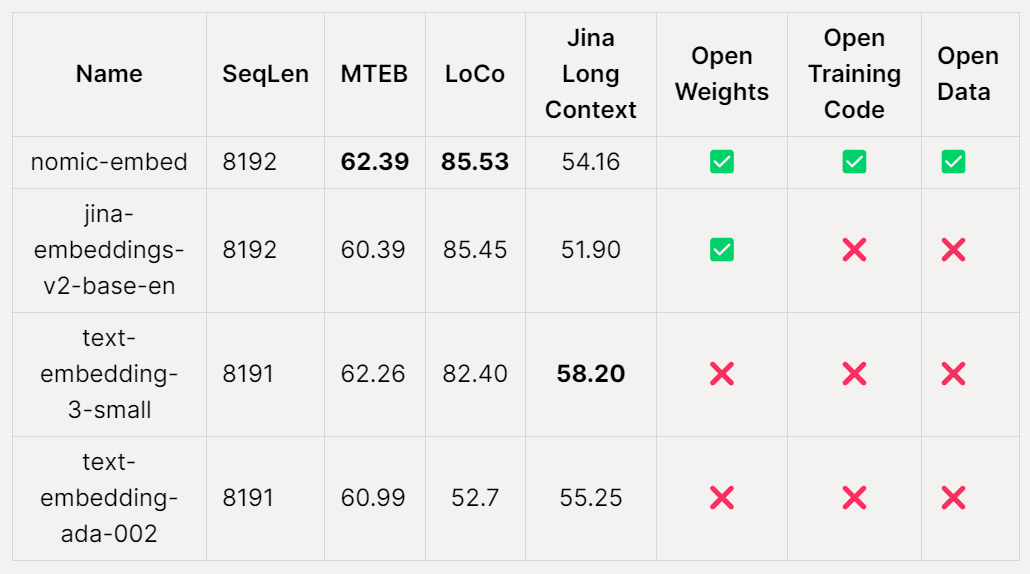
Allerdings kann MTEB keine langen Kontextaufgaben auswerten. Daher bewertet diese Studie nomic-embed anhand des kürzlich veröffentlichten LoCo-Benchmarks sowie des Jina Long Context-Benchmarks.
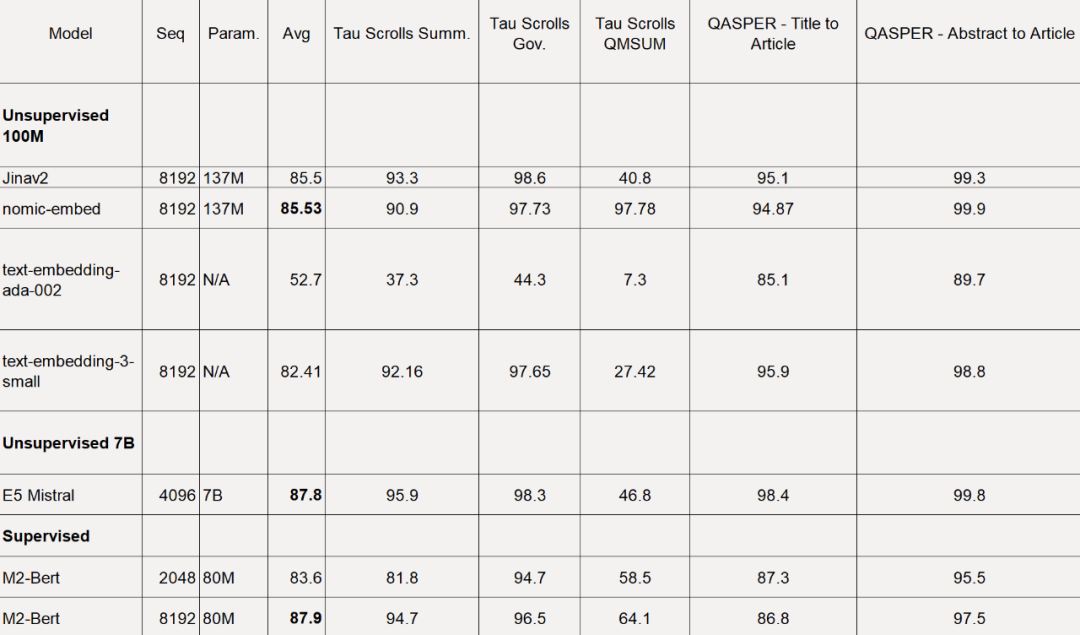
Für den LoCo-Benchmark wird die Studie getrennt nach Parameterkategorie ausgewertet und danach, ob die Auswertung in einem überwachten oder unüberwachten Setting durchgeführt wird.
Wie in der Tabelle unten gezeigt, ist Nomic Embed das unbeaufsichtigte 100-M-Parameter-Modell mit der besten Leistung. Insbesondere ist Nomic Embed mit den leistungsstärksten Modellen in der 7B-Parameterkategorie sowie mit Modellen, die in einer überwachten Umgebung speziell für den LoCo-Benchmark trainiert wurden, vergleichbar:
Die Gesamtleistung von Nomic Embed beim Jina Long Context-Benchmark schneidet ebenfalls ab besser als jina-embeddings-v2-base-en, aber Nomic Embed schneidet bei diesem Benchmark nicht besser ab als OpenAI ada-002 oder text-embedding-3-small:
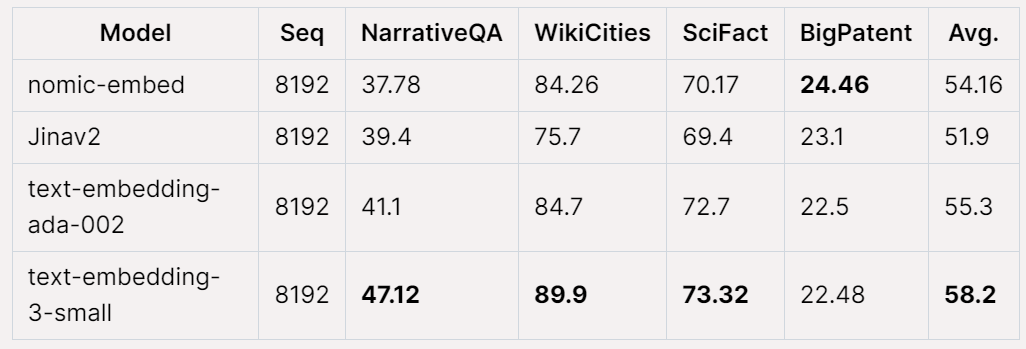
Insgesamt Mit anderen Worten: Nomic Embed übertrifft OpenAI Ada-002 und text-embedding-3-small im 2/3-Benchmark.
Die Studie besagt, dass die beste Option für die Verwendung von Nomic Embed die Nomic Embedding API ist, und der Weg, die API zu erhalten, ist wie folgt:

Schließlich der Datenzugriff: Um auf die vollständigen Daten zugreifen zu können, stellte die Studie den Benutzern Zugriffsschlüssel für Cloudflare R2 (einen Objektspeicherdienst ähnlich AWS S3) zur Verfügung. Um Zugriff zu erhalten, müssen Benutzer zunächst ein Nomic Atlas-Konto erstellen und den Anweisungen im Contrastors-Repository folgen.
Contrastors-Adresse: https://github.com/nomic-ai/contrastors?tab=readme-ov-file#data-access
Das obige ist der detaillierte Inhalt vonOhne OpenAI sind die Gewichte, Daten und Codes alle Open Source, und das Einbettungsmodell Nomic Embed ist hier, das perfekt reproduziert werden kann.. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!