

 Technologie-PeripheriegeräteKILerne und wachse aus der Kritik wie Menschen, 1317 Kommentare erhöhten die Gewinnquote von LLaMA2 um das 30-fache
Technologie-PeripheriegeräteKILerne und wachse aus der Kritik wie Menschen, 1317 Kommentare erhöhten die Gewinnquote von LLaMA2 um das 30-fache
Bestehende Methoden zur Ausrichtung großer Modelle umfassen beispielbasiertes überwachtes Fine-Tuning (SFT) und Score-Feedback-basiertes Verstärkungslernen (RLHF). Der Score kann jedoch nur die Qualität der aktuellen Antwort widerspiegeln und nicht eindeutig auf die Mängel des Modells hinweisen. Im Gegensatz dazu lernen und passen wir Menschen unsere Verhaltensmuster typischerweise durch verbales Feedback an. Ebenso wie die Bewertungskommentare nicht nur eine Bewertung sind, sondern auch viele Gründe für die Annahme oder Ablehnung enthalten.
Können also große Sprachmodelle Sprachfeedback nutzen, um sich wie Menschen zu verbessern?
Forscher der Chinesischen Universität Hongkong und des Tencent AI Lab haben kürzlich eine innovative Forschung namens Contrastive Unwahrscheinlichkeitslernen (CUT) vorgeschlagen. Die Forschung nutzt Sprachfeedback, um Sprachmodelle so anzupassen, dass sie wie Menschen aus unterschiedlichen Kritiken lernen und sich verbessern können. Ziel dieser Forschung ist es, die Qualität und Genauigkeit von Sprachmodellen zu verbessern, um sie besser mit der Denkweise des Menschen in Einklang zu bringen. Durch den Vergleich des Non-Likelihood-Trainings hoffen die Forscher, das Sprachmodell in die Lage zu versetzen, unterschiedliche Sprachgebrauchssituationen besser zu verstehen und sich an sie anzupassen und so seine Leistung bei Aufgaben zur Verarbeitung natürlicher Sprache zu verbessern. Diese innovative Forschung verspricht eine einfache und effektive Methode für Sprachmodelle zu sein.
CUT ist eine einfache und effektive Methode. Durch die Verwendung von nur 1317 Sprach-Feedback-Daten konnte CUT die Gewinnquote von LLaMA2-13b auf AlpacaEval erheblich verbessern, von 1,87 % auf 62,56 %, und 175B DaVinci003 erfolgreich besiegen. Das Spannende ist, dass CUT wie andere Reinforcement Learning- und Reinforcement Learning Reinforcement Feedback (RLHF)-Frameworks auch einen iterativen Zyklus aus Erkundung, Kritik und Verbesserung durchführen kann. In diesem Prozess kann die Kritikphase durch das automatische Bewertungsmodell abgeschlossen werden, um eine Selbstbewertung und Verbesserung des gesamten Systems zu erreichen.
Der Autor führte vier Iterationsrunden auf LLaMA2-chat-13b durch und verbesserte die Leistung des Modells auf AlpacaEval schrittweise von 81,09 % auf 91,36 %. Im Vergleich zur auf Score-Feedback (DPO) basierenden Ausrichtungstechnologie schneidet CUT bei gleicher Datengröße besser ab. Die Ergebnisse zeigen, dass Sprachfeedback ein großes Entwicklungspotenzial im Bereich Alignment aufweist und neue Möglichkeiten für die zukünftige Alignment-Forschung eröffnet. Diese Erkenntnis hat wichtige Auswirkungen auf die Verbesserung der Genauigkeit und Effizienz von Ausrichtungstechniken und bietet Orientierung für die Erzielung besserer Aufgaben bei der Verarbeitung natürlicher Sprache.

- Papiertitel: Gründe für eine Ablehnung? Sprachmodelle mit Urteilen in Einklang bringen
- Papierlink: https://arxiv.org/abs/2312.14591
- Github-Link: https://github.com/wwxu21/CUT
Ausrichtung großer Modelle
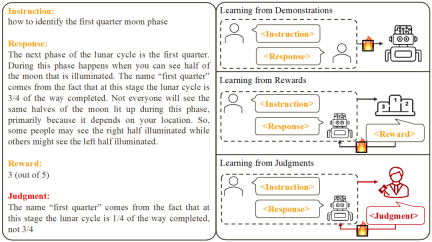
Basierend auf bestehenden Arbeiten haben Forscher zwei gängige Methoden zur Ausrichtung großer Modelle zusammengefasst:
1. Aus der Demonstration lernen: Basierend auf vorgefertigten Anweisungs-Antwort-Paaren verwenden Sie überwachte Trainingsmethoden, um große Modelle auszurichten.
Vorteile: stabiles Training; einfache Umsetzung.- Nachteile: Es ist teuer, qualitativ hochwertige und vielfältige Beispieldaten zu sammeln. Beispieldaten sind für das Modell oft irrelevant.
- 2. Aus Belohnungen lernen: Bewerten Sie die Befehls-Antwort-Paare und trainieren Sie das Modell mithilfe von Verstärkungslernen, um die Punktzahl seiner Antwort zu maximieren.
Vorteile: Es können sowohl korrekte Antworten als auch Fehlerantworten verwendet werden, die sich auf das Modell beziehen.
- Nachteile: Feedbacksignale sind spärlich; der Trainingsprozess ist oft komplex.
- Diese Forschung konzentriert sich auf das Lernen aus Sprachfeedback (Lernen aus Urteilen): Anweisungen geben – antworten, Kommentare schreiben, basierend auf dem Sprachfeedback, die Mängel des Modells verbessern und dadurch die Vorteile des Modells beibehalten Verbesserung der Modellleistung.
Es ist ersichtlich, dass das Sprachfeedback die Vorteile des Score-Feedbacks übernimmt. Im Vergleich zum Score-Feedback ist das verbale Feedback informativer: Anstatt das Modell raten zu lassen, was es richtig und was falsch gemacht hat, kann das verbale Feedback direkt auf detaillierte Mängel und Verbesserungsmöglichkeiten hinweisen. Bedauerlicherweise haben Forscher jedoch herausgefunden, dass es derzeit keine wirksame Möglichkeit gibt, verbale Rückmeldungen vollständig zu nutzen. Zu diesem Zweck haben Forscher ein innovatives Framework namens CUT vorgeschlagen, das darauf ausgelegt ist, das Sprachfeedback optimal zu nutzen.
Kontrastives Non-Likelihood-Training
Die Kernidee von CUT ist, aus Kontrasten zu lernen. Forscher vergleichen die Reaktionen großer Modelle unter verschiedenen Bedingungen, um herauszufinden, welche Teile zufriedenstellend sind und gewartet werden sollten und welche Teile fehlerhaft sind und geändert werden müssen. Auf dieser Grundlage verwenden Forscher die Maximum-Likelihood-Schätzung (MLE), um den zufriedenstellenden Teil zu trainieren, und das Unwahrscheinlichkeitstraining (UT), um die Fehler in der Antwort zu modifizieren.
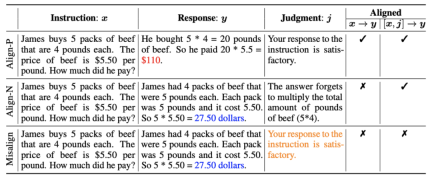
1. Ausrichtungsszenario: Wie in der Abbildung oben gezeigt, haben die Forscher zwei Ausrichtungsszenarien in Betracht gezogen:
a) : Dies ist das allgemein verstandene Ausrichtungsszenario. In diesem Szenario geht es weiter , Antworten müssen den Anweisungen treu folgen und mit den menschlichen Erwartungen und Werten im Einklang stehen.
: Dies ist das allgemein verstandene Ausrichtungsszenario. In diesem Szenario geht es weiter , Antworten müssen den Anweisungen treu folgen und mit den menschlichen Erwartungen und Werten im Einklang stehen.
b) : Dieses Szenario führt mündliches Feedback als zusätzliche Bedingung ein. In diesem Szenario muss die Antwort sowohl den Anweisungen als auch dem verbalen Feedback genügen. Wenn das große Modell beispielsweise eine negative Rückmeldung erhält, muss es aufgrund der in der entsprechenden Rückmeldung erwähnten Probleme Fehler machen.
: Dieses Szenario führt mündliches Feedback als zusätzliche Bedingung ein. In diesem Szenario muss die Antwort sowohl den Anweisungen als auch dem verbalen Feedback genügen. Wenn das große Modell beispielsweise eine negative Rückmeldung erhält, muss es aufgrund der in der entsprechenden Rückmeldung erwähnten Probleme Fehler machen.
2. Ausrichtungsdaten: Wie in der Abbildung oben gezeigt, haben die Forscher auf der Grundlage der beiden oben genannten Ausrichtungsszenarien drei Arten von Ausrichtungsdaten erstellt:
a) Align-P: Das große generierte Modell Es ist erstaunlich, zufrieden Antwort, daher das positive Feedback. Offensichtlich erfüllt Align-P die Ausrichtung sowohl im  - als auch im
- als auch im  -Szenario.
-Szenario.
b) Align-N: Das große Modell generiert fehlerhafte (fettblaue) Antworten und erhält daher negatives Feedback. Für Align-N ist die Ausrichtung in  nicht erfüllt. Aber nach Berücksichtigung dieses negativen Feedbacks ist Align-N immer noch im
nicht erfüllt. Aber nach Berücksichtigung dieses negativen Feedbacks ist Align-N immer noch im  -Szenario ausgerichtet.
-Szenario ausgerichtet.
c) Fehlausrichtung: Echtes negatives Feedback in Align-N wird durch ein gefälschtes positives Feedback ersetzt. Offensichtlich erfüllt eine Fehlausrichtung die Ausrichtung nicht sowohl im  - als auch im
- als auch im  -Szenario.
-Szenario.
3. Lernen Sie aus dem Vergleich:
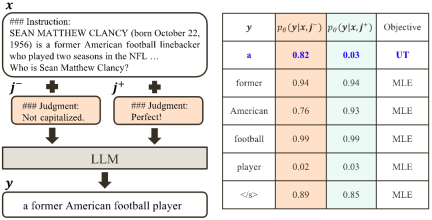
a) Align-N vs. Misalign: Der Unterschied zwischen den beiden liegt hauptsächlich im Grad der Ausrichtung unter  . Angesichts der leistungsstarken kontextbezogenen Lernfähigkeiten großer Modelle geht die Umkehrung der Ausrichtungspolarität von Align-N zu Misalign normalerweise mit einer erheblichen Änderung der Generierungswahrscheinlichkeit bestimmter Wörter einher, insbesondere derjenigen Wörter, die eng mit echtem negativem Feedback zusammenhängen. Wie in der Abbildung oben gezeigt, ist unter der Bedingung Align-N (linker Kanal) die Wahrscheinlichkeit, dass ein großes Modell „a“ generiert, deutlich höher als bei Misalign (rechter Kanal). Und an der Stelle, an der sich die Wahrscheinlichkeit erheblich ändert, macht das große Modell einen Fehler.
. Angesichts der leistungsstarken kontextbezogenen Lernfähigkeiten großer Modelle geht die Umkehrung der Ausrichtungspolarität von Align-N zu Misalign normalerweise mit einer erheblichen Änderung der Generierungswahrscheinlichkeit bestimmter Wörter einher, insbesondere derjenigen Wörter, die eng mit echtem negativem Feedback zusammenhängen. Wie in der Abbildung oben gezeigt, ist unter der Bedingung Align-N (linker Kanal) die Wahrscheinlichkeit, dass ein großes Modell „a“ generiert, deutlich höher als bei Misalign (rechter Kanal). Und an der Stelle, an der sich die Wahrscheinlichkeit erheblich ändert, macht das große Modell einen Fehler.
Um aus diesem Vergleich zu lernen, geben die Forscher Align-N- und Misalign-Daten gleichzeitig in das große Modell ein, um die Erzeugungswahrscheinlichkeiten der Ausgabewörter unter den beiden Bedingungen  bzw.
bzw.  zu erhalten. Wörter, die unter der Bedingung
zu erhalten. Wörter, die unter der Bedingung  eine deutlich höhere Generierungswahrscheinlichkeit haben als unter der Bedingung
eine deutlich höhere Generierungswahrscheinlichkeit haben als unter der Bedingung  , werden als unangemessene Wörter markiert. Insbesondere verwendeten die Forscher die folgenden Standards, um die Definition unangemessener Wörter zu quantifizieren:
, werden als unangemessene Wörter markiert. Insbesondere verwendeten die Forscher die folgenden Standards, um die Definition unangemessener Wörter zu quantifizieren:
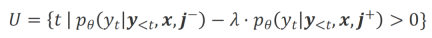
wobei  ein Hyperparameter ist, der Präzision und Erinnerung beim Erkennungsprozess unangemessener Wörter gewichtet.
ein Hyperparameter ist, der Präzision und Erinnerung beim Erkennungsprozess unangemessener Wörter gewichtet.
Die Forscher verwendeten Unwahrscheinlichkeitstraining (UT) für diese identifizierten unangemessenen Wörter und zwangen so das große Modell, zufriedenstellendere Antworten zu untersuchen. Für andere Antwortwörter verwenden Forscher immer noch die Maximum-Likelihood-Schätzung (MLE) zur Optimierung:
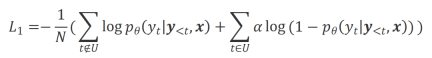
wobei  ein Hyperparameter ist, der den Anteil des Non-Likelihood-Trainings steuert,
ein Hyperparameter ist, der den Anteil des Non-Likelihood-Trainings steuert,  die Anzahl der Antwortwörter .
die Anzahl der Antwortwörter .
b) Align-P vs. Align-N: Der Unterschied zwischen den beiden liegt hauptsächlich im Grad der Ausrichtung unter  . Im Wesentlichen steuert das große Modell die Qualität der Ausgabeantwort, indem es Sprachrückmeldungen unterschiedlicher Polarität einführt. Daher kann der Vergleich zwischen den beiden große Modelle dazu inspirieren, zufriedenstellende Antworten von fehlerhaften Antworten zu unterscheiden. Konkret lernten die Forscher aus dieser Reihe von Vergleichen durch den folgenden Verlust der Maximum-Likelihood-Schätzung (MLE):
. Im Wesentlichen steuert das große Modell die Qualität der Ausgabeantwort, indem es Sprachrückmeldungen unterschiedlicher Polarität einführt. Daher kann der Vergleich zwischen den beiden große Modelle dazu inspirieren, zufriedenstellende Antworten von fehlerhaften Antworten zu unterscheiden. Konkret lernten die Forscher aus dieser Reihe von Vergleichen durch den folgenden Verlust der Maximum-Likelihood-Schätzung (MLE):
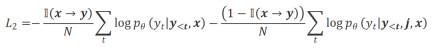
wobei  die Indikatorfunktion ist, die 1 zurückgibt, wenn die Daten
die Indikatorfunktion ist, die 1 zurückgibt, wenn die Daten  alignment erfüllen, andernfalls wird zurückgegeben 0.
alignment erfüllen, andernfalls wird zurückgegeben 0.
CUT Das endgültige Trainingsziel kombiniert die beiden oben genannten Vergleichssätze:  .
.
Experimentelle Auswertung
1. Offline-Ausrichtung
Um Geld zu sparen, versuchten Forscher zunächst, vorgefertigte Sprach-Feedback-Daten zu verwenden, um große Modelle auszurichten. Dieses Experiment wurde verwendet, um die Fähigkeit von CUT zu demonstrieren, Sprachfeedback zu nutzen.
a) Universalmodell
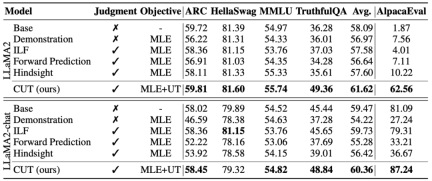
Wie in der Tabelle oben gezeigt, verwendeten die Forscher für die allgemeine Modellausrichtung 1317 von Shepherd bereitgestellte Ausrichtungsdaten, um CUT mit vorhandenen Slave-Modellen unter Kaltstart- (LLaMA2) und Heißstart- (LLaMA2-Chat) Lernmethoden zu vergleichen .
Im Kaltstart-Experiment auf Basis von LLaMA2 übertraf CUT die bestehenden Ausrichtungsmethoden auf der AlpacaEval-Testplattform deutlich und stellte seine Vorteile bei der Nutzung von Sprachfeedback voll unter Beweis. Darüber hinaus hat CUT im Vergleich zum Basismodell auch erhebliche Verbesserungen bei TruthfulQA erzielt, was zeigt, dass CUT großes Potenzial zur Linderung des Halluzinationsproblems großer Modelle hat.
Im Hot-Start-Szenario basierend auf LLaMA2-Chat funktionieren bestehende Methoden bei der Verbesserung von LLaMA2-Chat schlecht und haben sogar negative Auswirkungen. Allerdings kann CUT auf dieser Basis die Leistung des Basismodells weiter verbessern, was einmal mehr das große Potenzial von CUT bei der Nutzung von Sprachfeedback bestätigt.
b) Expertenmodell
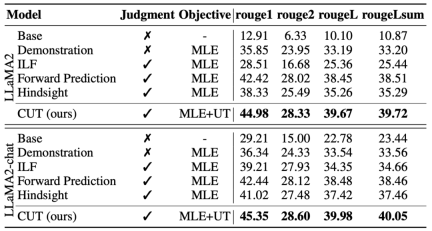
Die Forscher testeten auch den Ausrichtungseffekt von CUT an einer bestimmten Expertenaufgabe (Textzusammenfassung). Wie in der obigen Tabelle gezeigt, erzielt CUT auch bei Expertenaufgaben erhebliche Verbesserungen im Vergleich zu bestehenden Alignment-Methoden.
2. Online-Ausrichtung
Forschung zur Offline-Ausrichtung hat die leistungsstarke Ausrichtungsleistung von CUT erfolgreich nachgewiesen. Jetzt erforschen Forscher weiter Online-Ausrichtungsszenarien, die näher an praktischen Anwendungen sind. In diesem Szenario kommentieren Forscher die Antworten des großen Zielmodells iterativ mit sprachlichem Feedback, sodass das Zielmodell basierend auf dem damit verbundenen sprachlichen Feedback genauer ausgerichtet werden kann. Der spezifische Prozess ist wie folgt:
-
Schritt 1: Sammeln Sie Anweisungen
 und erhalten Sie die Antwort vom großen Zielmodell.
und erhalten Sie die Antwort vom großen Zielmodell.
-
Schritt 2: Markieren Sie als Antwort auf das obige Befehls-Antwort-Paar das Sprachfeedback .
-
Schritt 3: Verwenden Sie CUT, um das große Zielmodell basierend auf den gesammelten Triplett-Daten zu verfeinern.
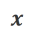
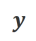
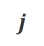
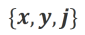
Wie in der Abbildung oben gezeigt, kann CUT nach vier Runden Online-Ausrichtungsiteration immer noch beeindruckende Ergebnisse mit nur 4000 Trainingsdaten und einer kleinen 13B-Modellgröße erzielen. Dieser Erfolg ist ein weiterer Beweis für die hervorragende Leistung und das enorme Potenzial von CUT. 3. KI-Kommentarmodell Wie in der Abbildung oben gezeigt, verwendeten die Forscher 5.000 Teile (AI Judge-5000) und 3.000 Teile (AI Judge-3000) Sprachfeedbackdaten, um zwei Überprüfungsmodelle zu trainieren. Beide Testmodelle haben bemerkenswerte Ergebnisse bei der Optimierung des angestrebten Großmodells erzielt, insbesondere bei der Wirkung von AI Judge-5000.
Dies beweist die Machbarkeit der Verwendung von KI-Überprüfungsmodellen zur Ausrichtung großer Zielmodelle und unterstreicht auch die Bedeutung der Qualität der Überprüfungsmodelle im gesamten Ausrichtungsprozess. Diese Reihe von Experimenten bietet auch eine starke Unterstützung für die Reduzierung der Annotationskosten in der Zukunft.
4. Sprach-Feedback vs. Punkte-Feedback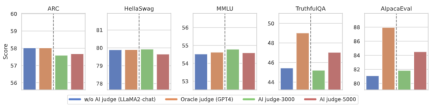
Um das enorme Potenzial des Sprachfeedbacks bei der Ausrichtung großer Modelle eingehend zu untersuchen, verglichen die Forscher CUT basierend auf Sprachfeedback mit der Methode basierend auf Score-Feedback (DPO). Um einen fairen Vergleich zu gewährleisten, wählten die Forscher 4.000 Sätze derselben Befehls-Antwort-Paare als experimentelle Proben aus, sodass CUT und DPO aus dem Bewertungs-Feedback bzw. dem Sprach-Feedback entsprechend diesen Daten lernen konnten.
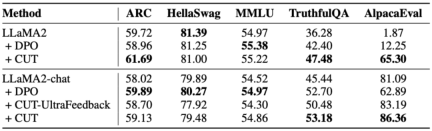
Wie in der Tabelle oben gezeigt, schnitt CUT im Kaltstartexperiment (LLaMA2) deutlich besser ab als DPO. Im Heißstart-Experiment (LLaMA2-Chat) kann CUT bei Aufgaben wie ARC, HellaSwag, MMLU und TruthfulQA vergleichbare Ergebnisse wie DPO erzielen und liegt bei der AlpacaEval-Aufgabe deutlich vor DPO. Dieses Experiment bestätigte das größere Potenzial und die Vorteile von sprachlichem Feedback im Vergleich zu fraktioniertem Feedback bei der Ausrichtung großer Modelle.
Zusammenfassung und Herausforderungen
In dieser Arbeit untersuchten die Forscher systematisch die aktuelle Situation des Sprachfeedbacks bei der Ausrichtung großer Modelle und schlugen innovativ ein Alignment-Framework CUT vor, das auf Sprachfeedback basiert, und zeigten auf, dass Sprachfeedback großes Potenzial und Vorteile hat im Bereich der Großmodellausrichtung. Darüber hinaus gibt es einige neue Richtungen und Herausforderungen bei der Erforschung von Sprachfeedback, wie zum Beispiel:
1 Qualität des Kommentarmodells: Obwohl Forscher die Machbarkeit des Trainings eines Kommentarmodells erfolgreich bestätigt haben, in Die Beobachtung bei der Ausgabe des Modells stellte immer noch fest, dass das Überprüfungsmodell häufig ungenaue Bewertungen lieferte. Daher ist die Verbesserung der Qualität des Überprüfungsmodells von entscheidender Bedeutung für die künftige groß angelegte Nutzung von Sprachfeedback zur Ausrichtung.
2. Einführung neuen Wissens: Wenn das Sprachfeedback Wissen beinhaltet, das dem großen Modell fehlt, gibt es keine klare Richtung für die Änderung, selbst wenn das große Modell die Fehler genau identifizieren kann. Daher ist es sehr wichtig, beim Ausrichten das Wissen zu ergänzen, das dem großen Modell fehlt.
3. Multimodale Ausrichtung : Der Erfolg von Sprachmodellen hat die Erforschung multimodaler großer Modelle, wie der Kombination von Sprache, Sprache, Bildern und Videos, vorangetrieben. In diesen multimodalen Szenarien hat die Untersuchung des Sprachfeedbacks und des Feedbacks entsprechender Modalitäten neue Definitionen und Herausforderungen mit sich gebracht.
Das obige ist der detaillierte Inhalt vonLerne und wachse aus der Kritik wie Menschen, 1317 Kommentare erhöhten die Gewinnquote von LLaMA2 um das 30-fache. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

 Gemma Scope: Das Mikroskop von Google, um in den Denkprozess von AI zu blickenApr 17, 2025 am 11:55 AM
Gemma Scope: Das Mikroskop von Google, um in den Denkprozess von AI zu blickenApr 17, 2025 am 11:55 AMErforschen der inneren Funktionsweise von Sprachmodellen mit Gemma -Umfang Das Verständnis der Komplexität von KI -Sprachmodellen ist eine bedeutende Herausforderung. Die Veröffentlichung von Gemma Scope durch Google, ein umfassendes Toolkit, bietet Forschern eine leistungsstarke Möglichkeit, sich einzuschütteln
 Wer ist ein Business Intelligence Analyst und wie kann man einer werden?Apr 17, 2025 am 11:44 AM
Wer ist ein Business Intelligence Analyst und wie kann man einer werden?Apr 17, 2025 am 11:44 AMErschließung des Geschäftserfolgs: Ein Leitfaden zum Analyst für Business Intelligence -Analyst Stellen Sie sich vor, Rohdaten verwandeln in umsetzbare Erkenntnisse, die das organisatorische Wachstum vorantreiben. Dies ist die Macht eines Business Intelligence -Analysts (BI) - eine entscheidende Rolle in Gu
 Wie füge ich eine Spalte in SQL hinzu? - Analytics VidhyaApr 17, 2025 am 11:43 AM
Wie füge ich eine Spalte in SQL hinzu? - Analytics VidhyaApr 17, 2025 am 11:43 AMSQL -Änderungstabellanweisung: Dynamisches Hinzufügen von Spalten zu Ihrer Datenbank Im Datenmanagement ist die Anpassungsfähigkeit von SQL von entscheidender Bedeutung. Müssen Sie Ihre Datenbankstruktur im laufenden Flug anpassen? Die Änderungstabelleerklärung ist Ihre Lösung. Diese Anleitung Details Hinzufügen von Colu
 Business Analyst vs. Data AnalystApr 17, 2025 am 11:38 AM
Business Analyst vs. Data AnalystApr 17, 2025 am 11:38 AMEinführung Stellen Sie sich ein lebhaftes Büro vor, in dem zwei Fachleute an einem kritischen Projekt zusammenarbeiten. Der Business Analyst konzentriert sich auf die Ziele des Unternehmens, die Ermittlung von Verbesserungsbereichen und die strategische Übereinstimmung mit Markttrends. Simu
 Was sind Count und Counta in Excel? - Analytics VidhyaApr 17, 2025 am 11:34 AM
Was sind Count und Counta in Excel? - Analytics VidhyaApr 17, 2025 am 11:34 AMExcel -Datenzählung und -analyse: Detaillierte Erläuterung von Count- und Counta -Funktionen Eine genaue Datenzählung und -analyse sind in Excel kritisch, insbesondere bei der Arbeit mit großen Datensätzen. Excel bietet eine Vielzahl von Funktionen, um dies zu erreichen. Die Funktionen von Count- und Counta sind wichtige Instrumente zum Zählen der Anzahl der Zellen unter verschiedenen Bedingungen. Obwohl beide Funktionen zum Zählen von Zellen verwendet werden, sind ihre Designziele auf verschiedene Datentypen ausgerichtet. Lassen Sie uns mit den spezifischen Details der Count- und Counta -Funktionen ausgrenzen, ihre einzigartigen Merkmale und Unterschiede hervorheben und lernen, wie Sie sie in der Datenanalyse anwenden. Überblick über die wichtigsten Punkte Graf und Cou verstehen
 Chrome ist hier mit KI: Tag zu erleben, täglich etwas Neues !!Apr 17, 2025 am 11:29 AM
Chrome ist hier mit KI: Tag zu erleben, täglich etwas Neues !!Apr 17, 2025 am 11:29 AMDie KI -Revolution von Google Chrome: Eine personalisierte und effiziente Browsing -Erfahrung Künstliche Intelligenz (KI) verändert schnell unser tägliches Leben, und Google Chrome leitet die Anklage in der Web -Browsing -Arena. Dieser Artikel untersucht die Exciti
 Die menschliche Seite von Ai: Wohlbefinden und VierfacheApr 17, 2025 am 11:28 AM
Die menschliche Seite von Ai: Wohlbefinden und VierfacheApr 17, 2025 am 11:28 AMImpacting Impact: Das vierfache Endergebnis Zu lange wurde das Gespräch von einer engen Sicht auf die Auswirkungen der KI dominiert, die sich hauptsächlich auf das Gewinn des Gewinns konzentrierte. Ein ganzheitlicherer Ansatz erkennt jedoch die Vernetzung von BU an
 5 verwendende Anwendungsfälle für Quantum Computing, über die Sie wissen solltenApr 17, 2025 am 11:24 AM
5 verwendende Anwendungsfälle für Quantum Computing, über die Sie wissen solltenApr 17, 2025 am 11:24 AMDie Dinge bewegen sich stetig zu diesem Punkt. Die Investition, die in Quantendienstleister und Startups einfließt, zeigt, dass die Industrie ihre Bedeutung versteht. Und eine wachsende Anzahl realer Anwendungsfälle entsteht, um seinen Wert zu demonstrieren


Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

EditPlus chinesische Crack-Version
Geringe Größe, Syntaxhervorhebung, unterstützt keine Code-Eingabeaufforderungsfunktion

WebStorm-Mac-Version
Nützliche JavaScript-Entwicklungstools

Sicherer Prüfungsbrowser
Safe Exam Browser ist eine sichere Browserumgebung für die sichere Teilnahme an Online-Prüfungen. Diese Software verwandelt jeden Computer in einen sicheren Arbeitsplatz. Es kontrolliert den Zugriff auf alle Dienstprogramme und verhindert, dass Schüler nicht autorisierte Ressourcen nutzen.

SublimeText3 Englische Version
Empfohlen: Win-Version, unterstützt Code-Eingabeaufforderungen!

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

