
Heim >Technologie-Peripheriegeräte >KI >Apple verwendet autoregressive Sprachmodelle, um Bildmodelle vorab zu trainieren
Apple verwendet autoregressive Sprachmodelle, um Bildmodelle vorab zu trainieren

- 王林nach vorne
- 2024-01-29 09:18:271058Durchsuche
1. Hintergrund
Nach dem Aufkommen großer Modelle wie GPT hat die autoregressive Modellierungsmethode Transformer + des Sprachmodells, bei der es sich um die Vortrainingsaufgabe zur Vorhersage des nächsten Tokens handelt, großen Erfolg erzielt. Kann diese autoregressive Modellierungsmethode also bessere Ergebnisse in visuellen Modellen erzielen? Der heute vorgestellte Artikel ist ein kürzlich von Apple veröffentlichter Artikel zum Training eines visuellen Modells basierend auf dem autoregressiven Vortraining von Transformer. Lassen Sie mich Ihnen diese Arbeit vorstellen.
 Bilder
Bilder
Papiertitel: Scalable Pre-training of Large Autoregressive Image Models
Download-Adresse: https://arxiv.org/pdf/2401.08541v1.pdf
Offener Quellcode: https://github .com/apple/ml-aim
2. Modellstruktur
Die Modellstruktur basiert auf Transformer und verwendet die nächste Token-Vorhersage im Sprachmodell als Optimierungsziel. Es gibt drei Hauptaspekte der Modifikation. Erstens verwendet dieser Artikel im Gegensatz zu ViT die einseitige Aufmerksamkeit von GPT, dh das Element an jeder Position berechnet die Aufmerksamkeit nur mit dem vorherigen Element. Zweitens führen wir mehr Kontextinformationen ein, um die Sprachverständnisfähigkeiten des Modells zu verbessern. Schließlich haben wir die Parametereinstellungen des Modells optimiert, um die Leistung weiter zu verbessern. Mit diesen Verbesserungen erreicht unser Modell erhebliche Leistungsverbesserungen bei Sprachaufgaben.
 Bild
Bild
Im Transformer-Modell wird ein neuer Mechanismus eingeführt, d. h. mehrere Präfix-Token werden vor der Eingabesequenz hinzugefügt. Diese Token nutzen einen Zwei-Wege-Aufmerksamkeitsmechanismus. Der Hauptzweck dieser Änderung besteht darin, die Konsistenz zwischen Pre-Training- und Downstream-Anwendungen zu verbessern. Bei nachgelagerten Aufgaben werden häufig bidirektionale Aufmerksamkeitsmethoden ähnlich wie ViT verwendet. Durch die Einführung bidirektionaler Präfix-Aufmerksamkeit im Vortrainingsprozess kann sich das Modell besser an die Anforderungen verschiedener nachgelagerter Aufgaben anpassen. Solche Verbesserungen können die Leistung und Generalisierungsfähigkeiten des Modells verbessern.
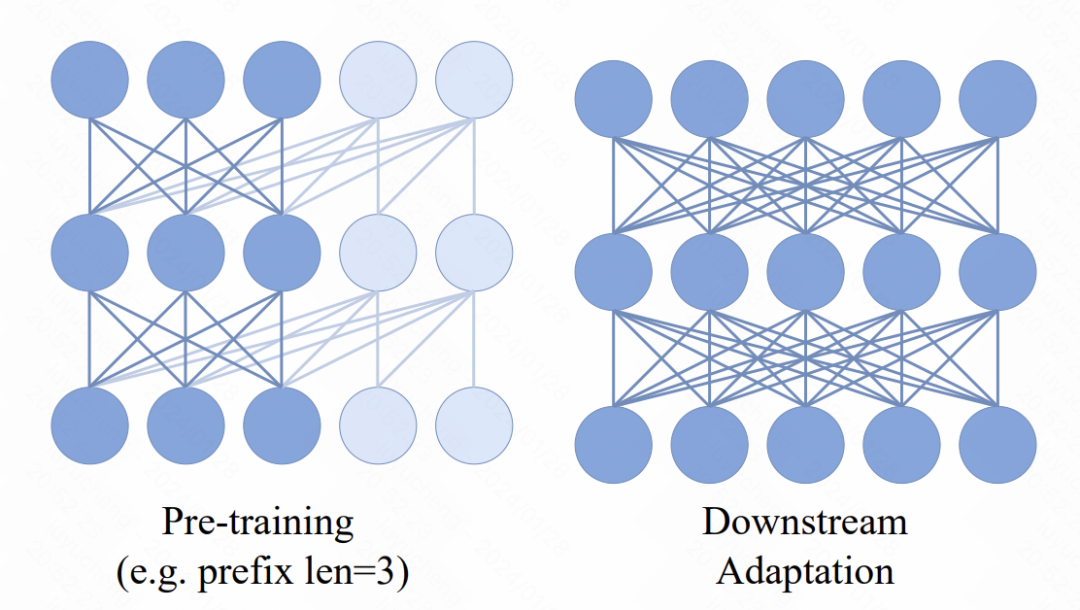 Bild
Bild
Im Hinblick auf die Optimierung der endgültigen Ausgabe-MLP-Schicht des Modells verwirft die ursprüngliche Vortrainingsmethode normalerweise die MLP-Schicht und verwendet in den nachgelagerten Aufgaben ein brandneues MLP. Dadurch soll verhindert werden, dass der vorab trainierte MLP zu sehr auf die vorab trainierte Aufgabe ausgerichtet ist, was zu einer Verringerung der Wirksamkeit nachgelagerter Aufgaben führt. In diesem Artikel schlagen die Autoren jedoch einen neuen Ansatz vor. Sie verwenden für jeden Patch einen unabhängigen MLP und nutzen außerdem die Verschmelzung von Darstellung und Aufmerksamkeit jedes Patches, um den herkömmlichen Pooling-Vorgang zu ersetzen. Auf diese Weise wird die Verwendbarkeit des vortrainierten MLP-Kopfes bei nachgelagerten Aufgaben verbessert. Durch diese Methode können die Autoren die Informationen des Gesamtbildes besser behalten und das Problem einer übermäßigen Abhängigkeit von Aufgaben vor dem Training vermeiden. Dies ist sehr hilfreich, um die Generalisierungsfähigkeit und Anpassungsfähigkeit des Modells zu verbessern.
In Bezug auf Optimierungsziele wurden in dem Artikel zwei Methoden ausprobiert. Die erste besteht darin, die Patch-Pixel direkt anzupassen und MSE für die Vorhersage zu verwenden. Die zweite besteht darin, den Bildpatch im Voraus zu tokenisieren, ihn in eine Klassifizierungsaufgabe umzuwandeln und Kreuzentropieverlust zu verwenden. Bei den nachfolgenden Ablationsexperimenten in diesem Artikel wurde jedoch festgestellt, dass die zweite Methode zwar auch ein normales Modelltraining ermöglichen kann, der Effekt jedoch nicht so gut ist wie der auf der Pixelgranularität MSE basierende.
3. Experimentelle Ergebnisse
Der experimentelle Teil des Artikels analysiert detailliert die Wirkung dieses autoregressiven Bildmodells und die Auswirkung jedes Teils auf die Wirkung.
Zunächst wird mit fortschreitendem Training die nachgelagerte Bildklassifizierungsaufgabe immer besser, was darauf hinweist, dass diese Methode vor dem Training tatsächlich gute Bilddarstellungsinformationen lernen kann.
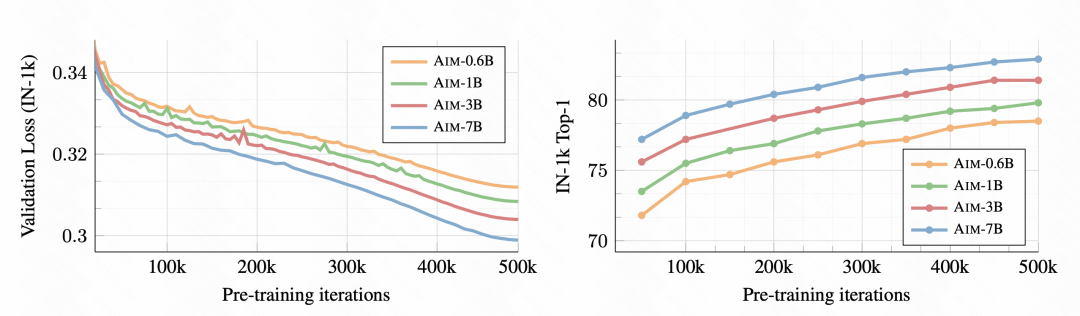 Bild
Bild
Bei den Trainingsdaten führt das Training mit einem kleinen Datensatz zu einer Überanpassung. Obwohl der anfängliche Verifizierungssatzverlust größer ist, gibt es jedoch kein offensichtliches Überanpassungsproblem.
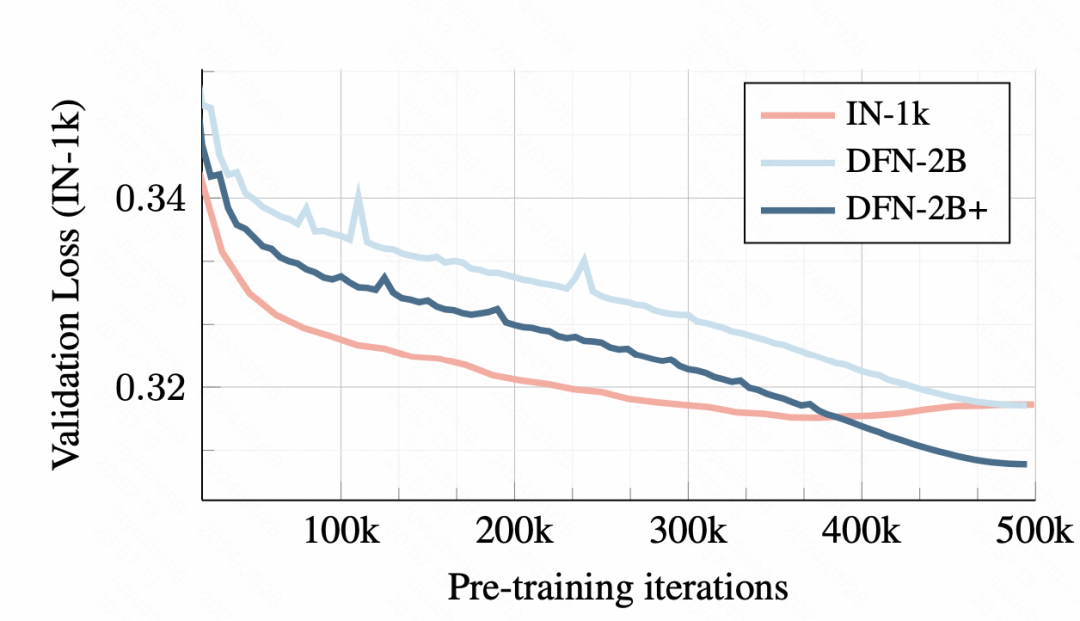 Bilder
Bilder
Bezüglich des Designs jedes Moduls des Modells führt der Artikel auch eine detaillierte Analyse des Ablationsexperiments durch.
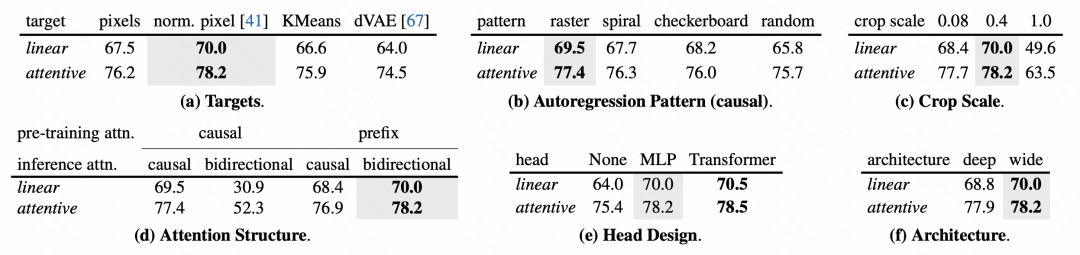 Bilder
Bilder
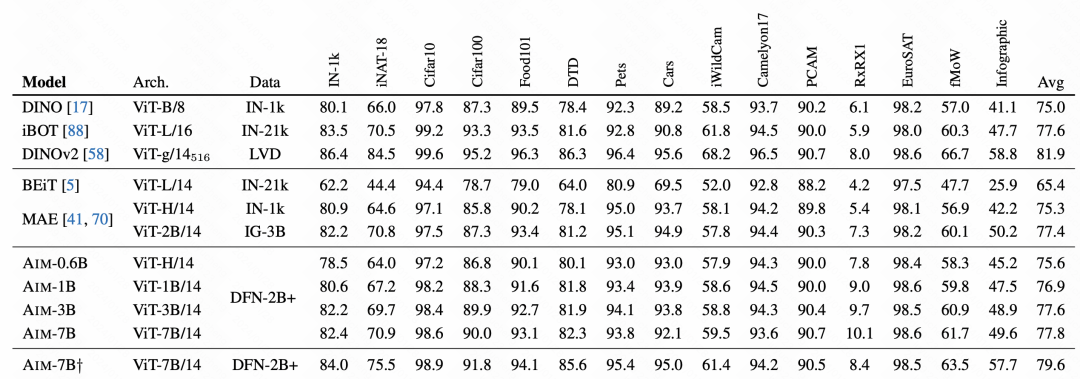
Im abschließenden Effektvergleich erzielte AIM sehr gute Ergebnisse, was auch bestätigte, dass diese autoregressive Vortrainingsmethode auch für Bilder verfügbar ist und möglicherweise zur Vortrainingsmethode für nachfolgende Großbilder wird Modelle. Eine der wichtigsten Trainingsmethoden.
 Bilder
Bilder
Das obige ist der detaillierte Inhalt vonApple verwendet autoregressive Sprachmodelle, um Bildmodelle vorab zu trainieren. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Wie füge ich mit HTML und CSS Text zum Bild hinzu? (Codebeispiel)
- Welcher Kodierungsstandard für die Bildkomprimierung ist JPEG?
- Welche Datenmodelle werden vom Access2010-Datenbankverwaltungssystem unterstützt?
- Was Sie mit dem Ausweichen-Werkzeug beim Bearbeiten eines Bildes tun können
- So löschen Sie den Verlauf der letzten Desktop-Hintergrundbilder in Windows 11