
Heim >Technologie-Peripheriegeräte >KI >Multimodale große Modelle werden von jungen Leuten online mit Open Source bevorzugt: 1080Ti lässt sich problemlos ausführen
Multimodale große Modelle werden von jungen Leuten online mit Open Source bevorzugt: 1080Ti lässt sich problemlos ausführen

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBnach vorne
- 2024-01-29 09:15:261096Durchsuche
Ein „erstes multimodales Großmodell für junge Leute“ namens Vary-toy ist da!
Die Modellgröße beträgt weniger als 2B, es kann auf Consumer-Grafikkarten trainiert werden und kann problemlos auf alten GTX1080ti 8G-Grafikkarten ausgeführt werden.
Möchten Sie ein Dokumentbild in das Markdown-Format konvertieren? In der Vergangenheit waren mehrere Schritte wie Texterkennung, Layouterkennung und -sortierung, Verarbeitung von Formeltabellen und Textbereinigung erforderlich.
Jetzt brauchen Sie nur noch einen Befehl:
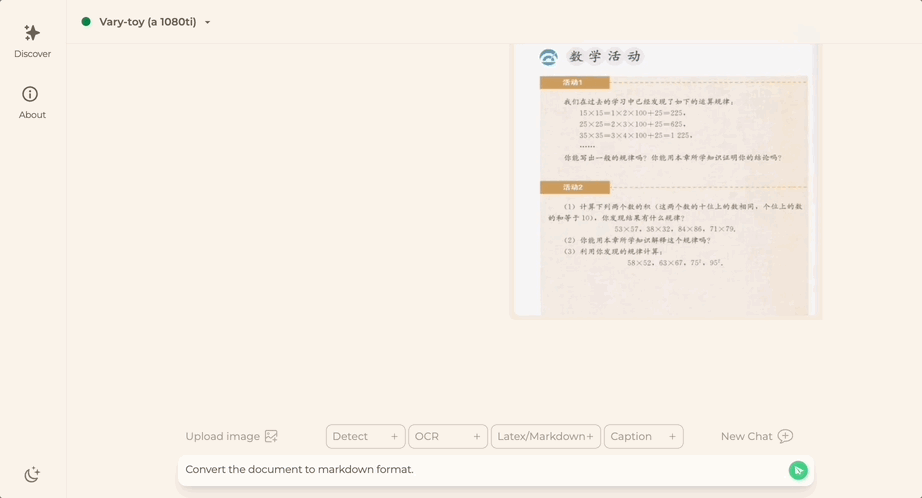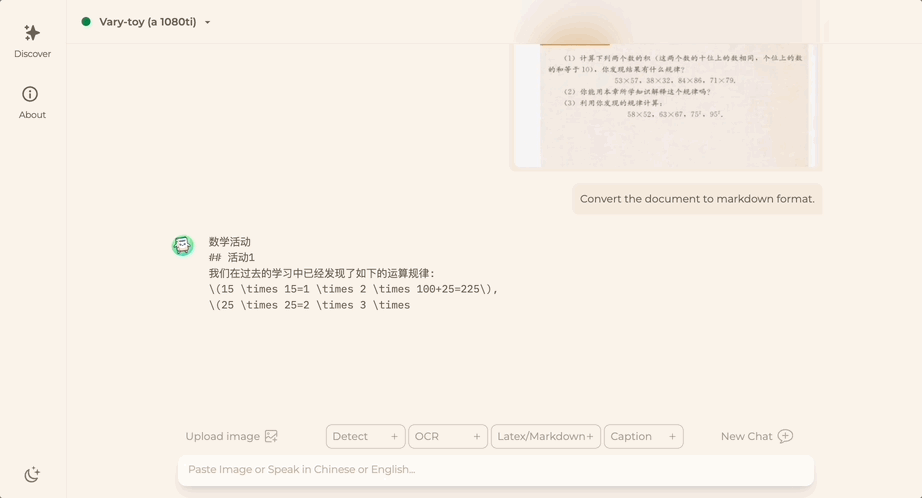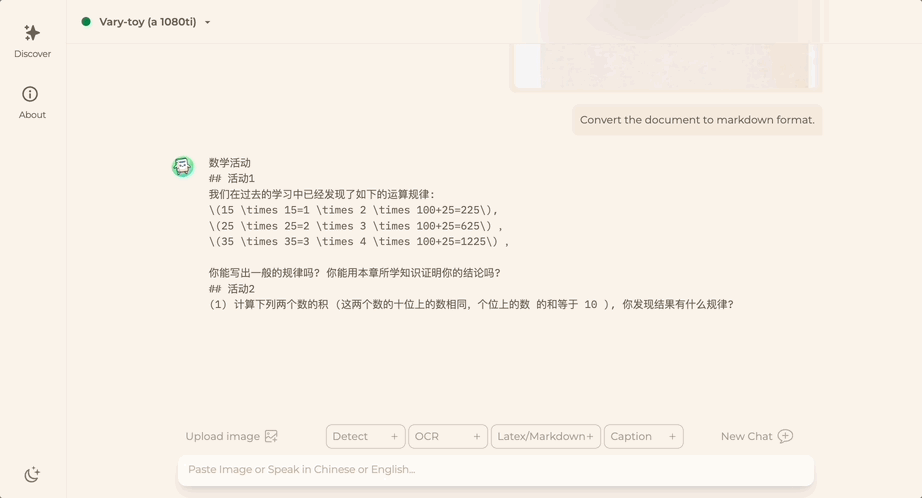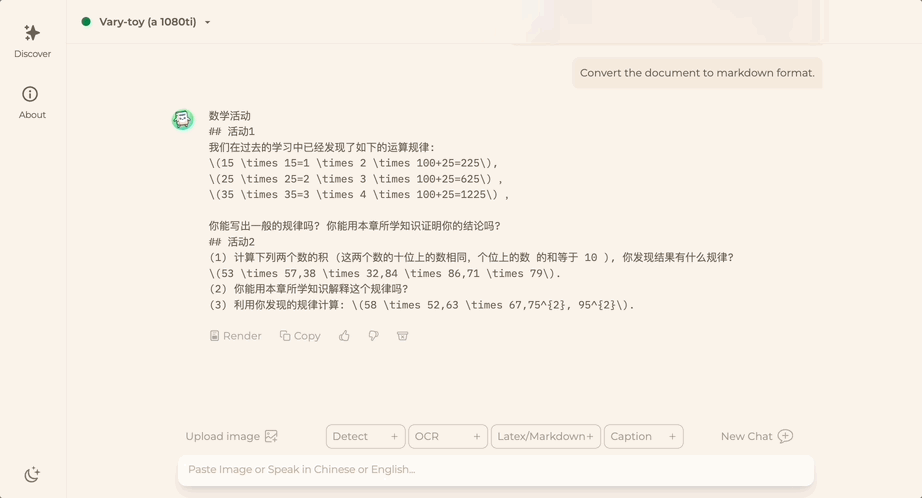
Egal Chinesisch oder Englisch, großer Text im Bild kann in wenigen Minuten extrahiert werden:

Die Objekterkennung auf einem Bild kann immer noch die Art mit spezifischem Ergebnis liefern Koordinaten:

Diese Studie wurde gemeinsam von Forschern von Megvii, der National University of Science and Technology und der Huazhong University vorgeschlagen.
Berichten zufolge deckt Vary-toy, obwohl es klein ist, fast alle Funktionen in der aktuellen Mainstream-Forschung von LVLM (Large Scale Visual Language Model) ab: Dokument-OCR-Erkennung(Document OCR), visuelle Positionierung(Visual Erdung) , Bildunterschrift, visuelle Beantwortung von Fragen (VQA) .


alte·GTX1080 und ihre Stimmung ist wie folgt:

, aber viele Leute können es aufgrund begrenzter Ressourcen nicht ausführen.
Angesichts der Tatsache, dass es relativ wenige „kleine“ VLMs gibt, die gut auf Open Source basieren und eine hervorragende Leistung aufweisen, hat das Team neu Vary-toy herausgebracht, das als „erstes Multi-Mode-Großmodell für junge Leute“ bekannt ist. Im Vergleich zu Vary ist Vary-toy nicht nur kleiner, sondern trainiert auch einstärkeres visuelles Vokabular. Das neue Vokabular beschränkt das Modell nicht mehr auf OCR auf Dokumentebene, sondern bietet eine universellere und umfassendere visuelle Wortliste , das nicht nur OCR auf Dokumentebene, sondern auch eine allgemeine visuelle Zielerkennung durchführen kann. Wie geht das?
Die Modellstruktur und der Trainingsprozess von Vary-toy sind in der folgenden Abbildung dargestellt. Im Allgemeinen ist das Training in zwei Phasen unterteilt.
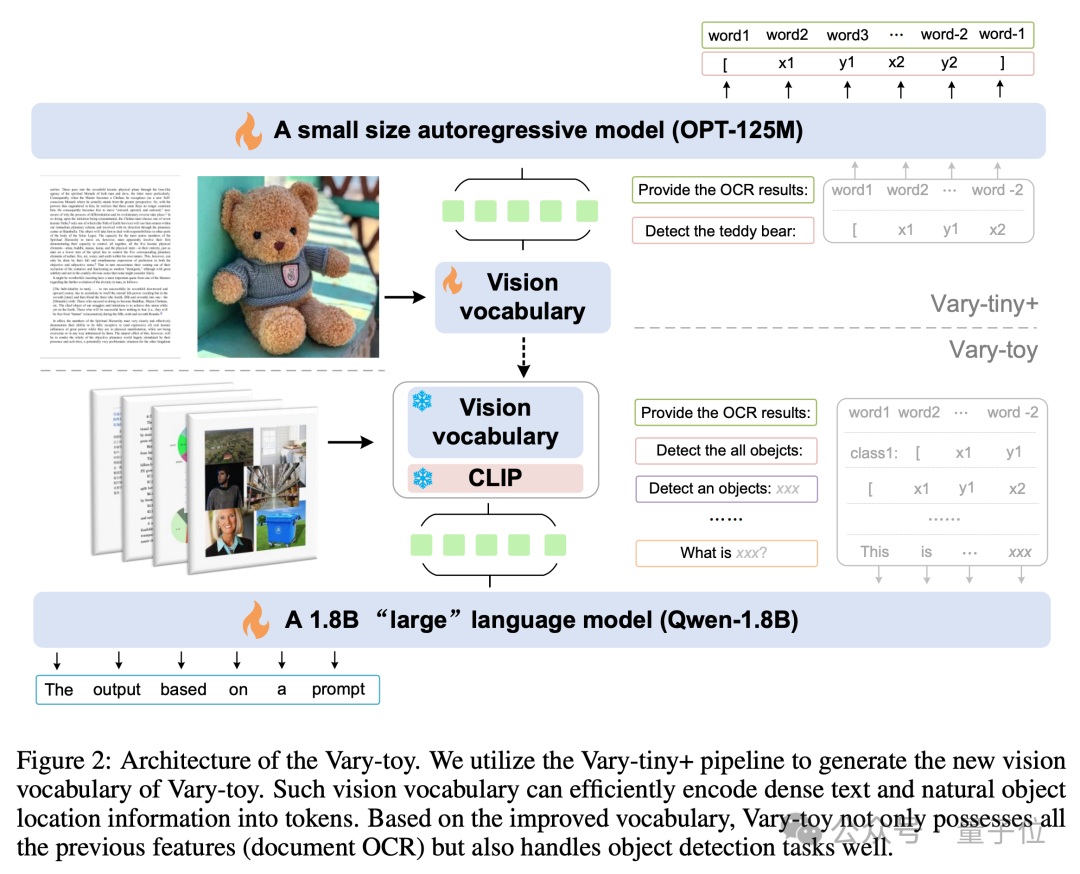 Zunächst wird in der ersten Stufe die Vary-tiny+-Struktur verwendet, um ein visuelles Vokabular vorab zu trainieren, das besser ist als das ursprüngliche Vary. Das neue visuelle Vokabular löst das Problem, dass das ursprüngliche Vary es nur verwendet für OCR auf Dokumentebene. Das Problem der Kapazitätsverschwendung und das Problem, dass die Vorteile des SAM-Vortrainings nicht vollständig genutzt werden.
Zunächst wird in der ersten Stufe die Vary-tiny+-Struktur verwendet, um ein visuelles Vokabular vorab zu trainieren, das besser ist als das ursprüngliche Vary. Das neue visuelle Vokabular löst das Problem, dass das ursprüngliche Vary es nur verwendet für OCR auf Dokumentebene. Das Problem der Kapazitätsverschwendung und das Problem, dass die Vorteile des SAM-Vortrainings nicht vollständig genutzt werden.
Dann wird in der zweiten Stufe das in der ersten Stufe trainierte visuelle Vokabular in die endgültige Struktur für das Multitask-Training/SFT zusammengeführt.
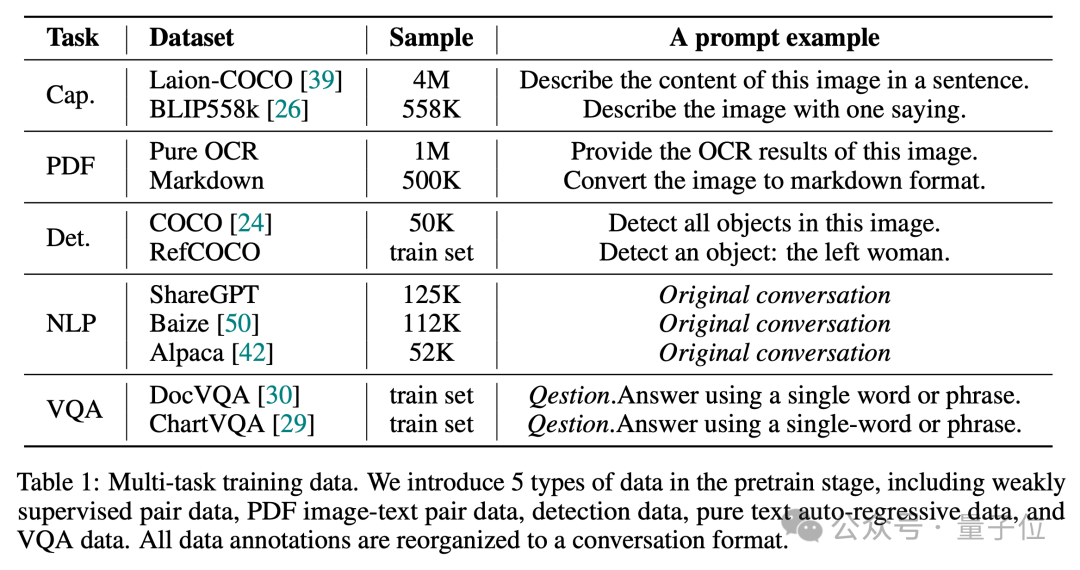
Wie wir alle wissen, ist ein gutes Datenverhältnis entscheidend, um ein voll funktionsfähiges VLM zu generieren.
In der Vortrainingsphase verwendete Vary-toy also 5 Aufgabentypen von Daten, um den Dialog aufzubauen. Das Datenverhältnis und die Beispielaufforderung sind in der folgenden Abbildung dargestellt:
 In der SFT-Phase nur LLaVA -80K Daten wurden verwendet. Weitere technische Details finden Sie im technischen Bericht von Vary-toy.
In der SFT-Phase nur LLaVA -80K Daten wurden verwendet. Weitere technische Details finden Sie im technischen Bericht von Vary-toy.
Experimentelle Testergebnisse
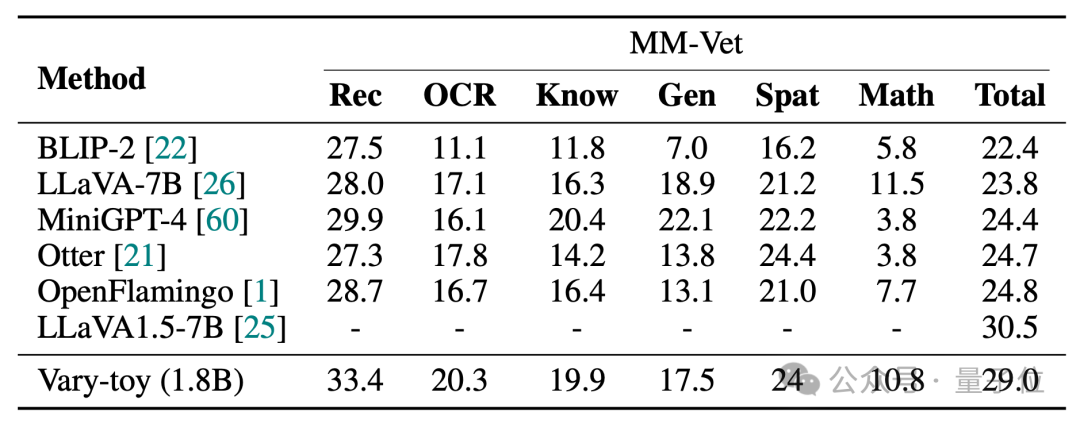
Vary-toys Ergebnisse in den vier Benchmark-Tests von DocVQA, ChartQA, RefCOCO und MMVet sind wie folgt:
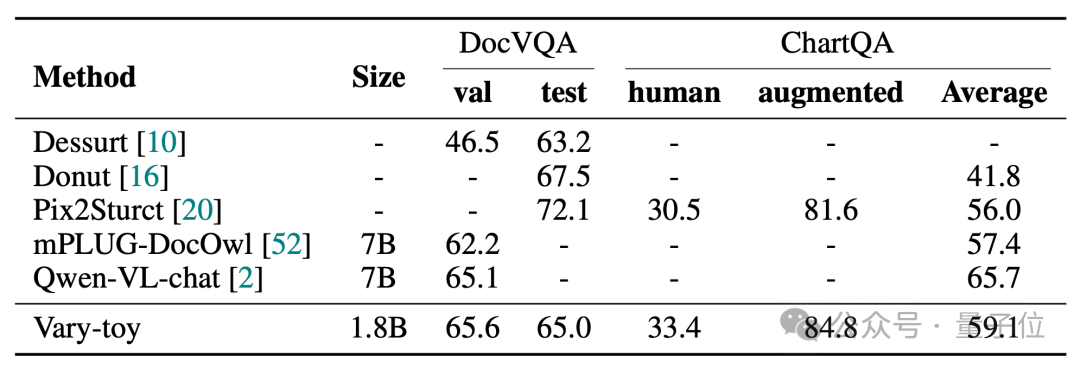
Vary-toy kann 65,6 % ANLS bei DocVQA, 59,1 % Genauigkeit bei ChartQA und 88,1 % Genauigkeit bei RefCOCO erreichen:
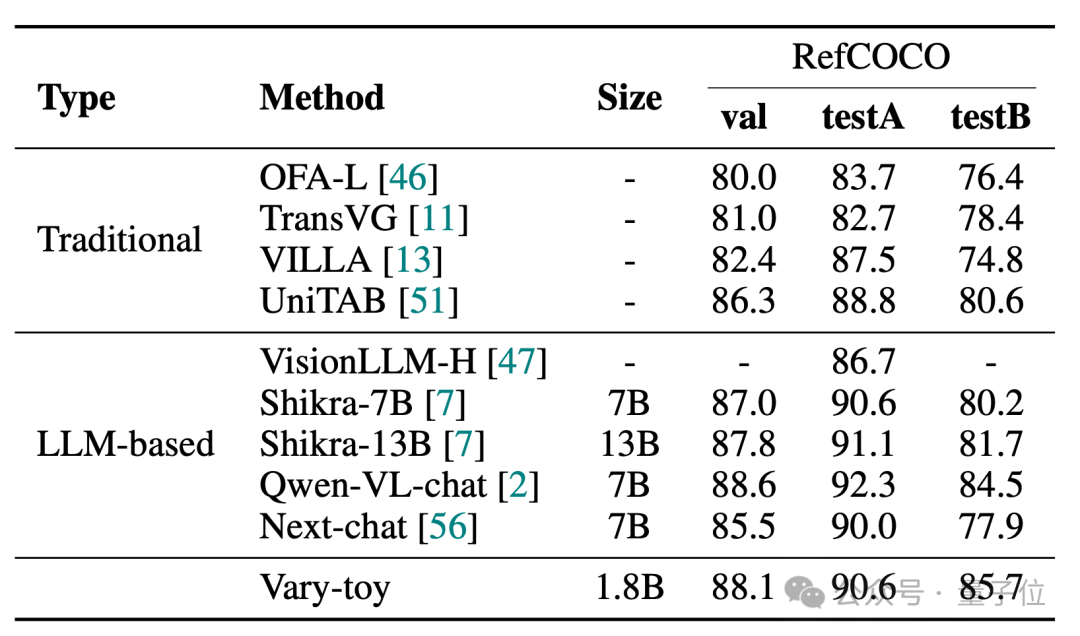
MMVet kann 29 % Genauigkeit erreichen, unabhängig davon, ob es sich um Benchmark-Scores oder Visualisierungseffekte handelt , Vary-Toy, das weniger als 2B hat, kann sogar mit der Leistung einiger beliebter 7B-Modelle mithalten.
Projektlink:
[1]https://arxiv.org/abs/2401.12503
[3]https://varytoy.github.io/
Das obige ist der detaillierte Inhalt vonMultimodale große Modelle werden von jungen Leuten online mit Open Source bevorzugt: 1080Ti lässt sich problemlos ausführen. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- So exportieren Sie ein Modell in Navicat
- Zu welcher Art von Datenmodell gehört SQL Server?
- Welcher Schicht im OSI-Referenzmodell entspricht die Transportschicht im TCP/IP-Referenzmodell?
- So importieren Sie das Layout eines CAD-Modells
- Was sind in der Datenbanktechnologie die vier wichtigsten Datenmodelle?