
Heim >Technologie-Peripheriegeräte >KI >Die Fusion mehrerer heterogener Großmodelle bringt erstaunliche Ergebnisse
Die Fusion mehrerer heterogener Großmodelle bringt erstaunliche Ergebnisse

- PHPznach vorne
- 2024-01-29 09:12:281263Durchsuche
Mit dem Erfolg großer Sprachmodelle wie LLaMA und Mistral haben viele Unternehmen begonnen, ihre eigenen großen Sprachmodelle zu erstellen. Allerdings ist das Training eines neuen Modells von Grund auf teuer und kann über redundante Funktionen verfügen.
Kürzlich haben Forscher der Sun Yat-sen-Universität und des Tencent AI Lab FuseLLM vorgeschlagen, das verwendet wird, um „mehrere heterogene große Modelle zu fusionieren“.
Im Gegensatz zu herkömmlichen Methoden zur Modellintegration und Gewichtszusammenführung bietet FuseLLM eine neue Möglichkeit, das Wissen mehrerer heterogener großer Sprachmodelle zusammenzuführen. Anstatt mehrere große Sprachmodelle gleichzeitig bereitzustellen oder die Zusammenführung von Modellergebnissen zu erfordern, verwendet FuseLLM eine leichte kontinuierliche Trainingsmethode, um das Wissen und die Fähigkeiten einzelner Modelle in ein fusioniertes großes Sprachmodell zu übertragen. Das Einzigartige an diesem Ansatz ist seine Fähigkeit, mehrere heterogene große Sprachmodelle zum Zeitpunkt der Inferenz zu verwenden und ihr Wissen in ein fusioniertes Modell zu externalisieren. Auf diese Weise verbessert FuseLLM effektiv die Leistung und Effizienz des Modells.
Dieser Artikel wurde gerade auf arXiv veröffentlicht und hat bei Internetnutzern viel Aufmerksamkeit und Weiterleitung erregt.

Jemand dachte, es wäre interessant, ein Modell in einer anderen Sprache zu trainieren, und ich habe darüber nachgedacht.
Derzeit wurde dieses Papier vom ICLR 2024 angenommen.

- Papiertitel: Knowledge Fusion of Large Language Models
- Papieradresse: https://arxiv.org/abs/2401.10491 .
- Papierlager: https://github.com/fanqiwan/FuseLLM
Einführung in die Methode
Der Schlüssel zu FuseLLM besteht darin, die Fusion großer Sprachmodelle aus der Perspektive der Wahrscheinlichkeitsverteilungsdarstellung zu untersuchen Text, der Autor Es wird angenommen, dass die von verschiedenen großen Sprachmodellen erzeugten Darstellungen deren intrinsisches Wissen zum Verständnis dieser Texte widerspiegeln. Daher verwendet FuseLLM zunächst mehrere Quellmodelle für große Sprachen, um Darstellungen zu generieren, externalisiert deren kollektives Wissen und ihre jeweiligen Vorteile, integriert dann die generierten Mehrfachdarstellungen, um sich gegenseitig zu ergänzen, und migriert schließlich durch leichtes kontinuierliches Training zum Zielmodell für große Sprachen. Die folgende Abbildung zeigt einen Überblick über den FuseLLM-Ansatz.
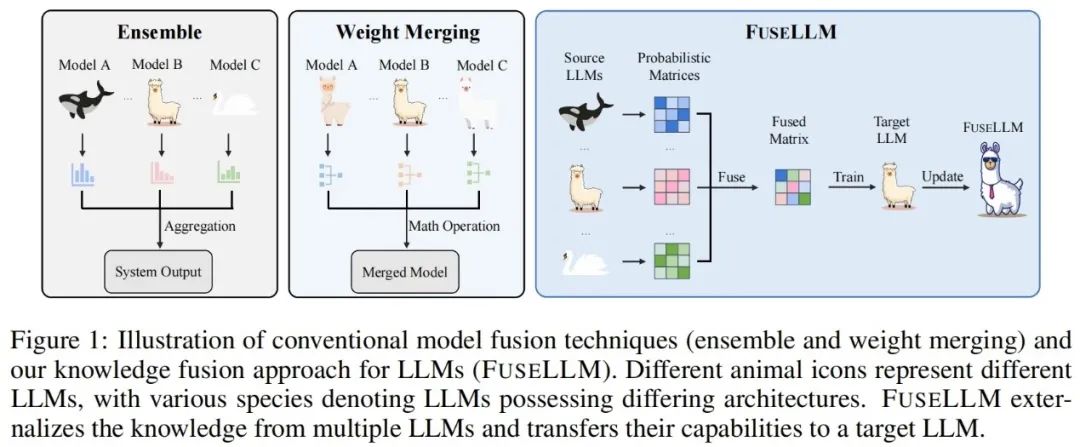
Angesichts der Unterschiede bei Tokenisierern und Vokabularlisten mehrerer heterogener großer Sprachmodelle ist die Ausrichtung der Wortsegmentierungsergebnisse ein Schlüsselfaktor beim Zusammenführen mehrerer Darstellungen: FuseLLM basiert auf einem vollständigen Abgleich auf Vokabularebene Die auf dem minimalen Bearbeitungsabstand basierende Ausrichtung ist außerdem darauf ausgelegt, die verfügbaren Informationen in der Darstellung weitestgehend beizubehalten.
Um das kollektive Wissen mehrerer großer Sprachmodelle zu kombinieren und gleichzeitig ihre jeweiligen Vorteile beizubehalten, müssen Strategien für fusionierte modellgenerierte Darstellungen sorgfältig entworfen werden. Insbesondere bewertet FuseLLM, wie gut verschiedene große Sprachmodelle diesen Text verstehen, indem es die Kreuzentropie zwischen der generierten Darstellung und dem Beschriftungstext berechnet, und führt dann zwei auf Kreuzentropie basierende Fusionsfunktionen ein:
- MinCE: Input Multiple Large Modelle generieren Darstellungen für den aktuellen Text und geben die Darstellung mit der kleinsten Kreuzentropie aus.
- AvgCE: Geben Sie die von mehreren großen Modellen generierten Darstellungen für den aktuellen Text ein und geben Sie eine gewichtete Durchschnittsdarstellung basierend auf dem durch Kreuz erhaltenen Gewicht aus Entropie;
In der kontinuierlichen Trainingsphase verwendet FuseLLM die Fusionsdarstellung als Ziel zur Berechnung des Fusionsverlusts und behält gleichzeitig den Sprachmodellverlust bei. Die endgültige Verlustfunktion ist die Summe aus Fusionsverlust und Sprachmodellverlust.
Experimentelle Ergebnisse
Im experimentellen Teil betrachtet der Autor ein allgemeines, aber anspruchsvolles Fusionsszenario für große Sprachmodelle, bei dem die Quellmodelle geringfügige Gemeinsamkeiten in Struktur oder Fähigkeiten aufweisen. Konkret wurden Experimente im 7B-Maßstab durchgeführt und drei repräsentative Open-Source-Modelle ausgewählt: Llama-2, OpenLLaMA und MPT als große Modelle zur Fusion.
Der Autor bewertete FuseLLM in Szenarien wie allgemeines Denken, gesundes Denken, Codegenerierung, Textgenerierung und Befolgen von Anweisungen und stellte fest, dass es im Vergleich zu allen Quellmodellen und kontinuierlichen Trainingsbasismodellen erhebliche Leistungsverbesserungen erzielte.
Allgemeines Denken und Denken mit gesundem Menschenverstand
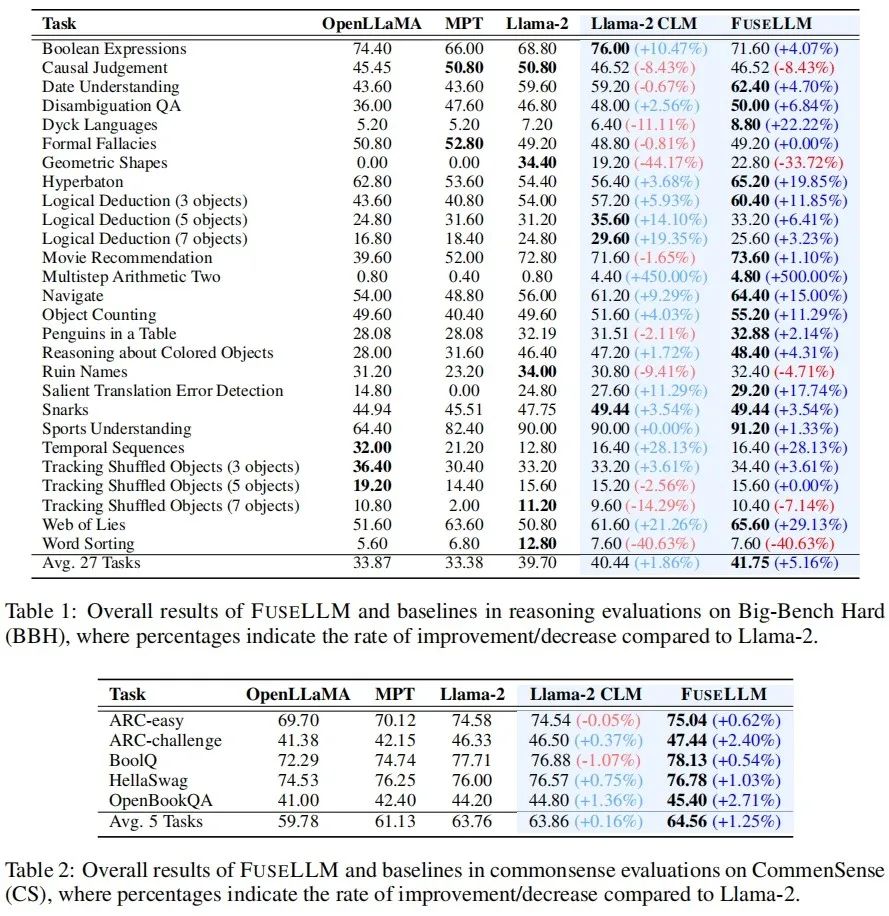
Auf dem Big-Bench Hard Benchmark, der die Fähigkeit zum allgemeinen Denken testet, wird Llama-2 CLM nach kontinuierlichem Training mit Llama-2 bei 27 An verglichen Bei jeder Aufgabe wurde eine durchschnittliche Verbesserung von 1,86 % erreicht, während FuseLLM im Vergleich zu Llama-2 eine Verbesserung von 5,16 % erzielte, was deutlich besser ist als Llama-2 CLM, was darauf hindeutet, dass FuseLLM die Vorteile mehrerer großer Sprachmodelle kombinieren kann Leistungsverbesserungen erzielen.
Beim Common Sense Benchmark, der die Fähigkeit zum gesunden Menschenverstand testet, übertraf FuseLLM alle Quellmodelle und Basismodelle und erzielte bei allen Aufgaben die beste Leistung.
Codegenerierung und Textgenerierung

Beim MultiPL-E-Benchmark, der die Codegenerierungsfähigkeiten testet, übertraf FuseLLM Llama-2 in 9 von 10 Aufgaben und erzielte eine durchschnittliche Leistungsverbesserung von 6,36 %. Der Grund, warum FuseLLM MPT und OpenLLaMA nicht übertrifft, liegt möglicherweise in der Verwendung von Llama-2 als Zielmodell für große Sprachen, das über schwache Codegenerierungsfähigkeiten und einen geringen Anteil an Codedaten im kontinuierlichen Trainingskorpus verfügt, der nur etwa 10 % ausmacht 7,59 %.
Bei mehreren Textgenerierungs-Benchmarks, die die Beantwortung von Wissensfragen (TrivialQA), das Leseverständnis (DROP), die Inhaltsanalyse (LAMBADA), die maschinelle Übersetzung (IWSLT2017) und die Theoremanwendung (SciBench) messen, übertrifft FuseLLM auch in allen Aufgaben alle Quellen Modelle und übertraf Llama-2 CLM in 80 % der Aufgaben.
Anweisungen folgen

Da FuseLLM nur die Darstellungen mehrerer Quellmodelle für die Fusion extrahieren und dann das Zielmodell kontinuierlich trainieren muss, kann es auch zur Feinabstimmung großer Modelle verwendet werden Sprachmodelle mit Anweisungen Fusion. Beim Vicuna Benchmark, der die Fähigkeit zur Befehlsfolge bewertet, erzielte FuseLLM ebenfalls eine hervorragende Leistung und übertraf alle Quellmodelle und CLM.
FuseLLM vs. Wissensdestillation & Modellintegration & Gewichtszusammenführung
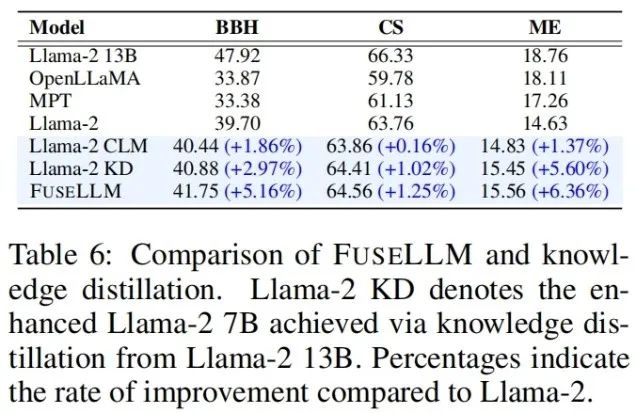
In Anbetracht der Tatsache, dass Wissensdestillation auch eine Methode zur Verwendung von Darstellung zur Verbesserung der Leistung großer Sprachmodelle ist, kombiniert der Autor FuseLLM und Llama-2 13B destilliertes Llama-2 KD wurde verglichen. Die Ergebnisse zeigen, dass FuseLLM die Destillation aus einem einzelnen 13B-Modell übertrifft, indem es drei 7B-Modelle mit unterschiedlichen Architekturen fusioniert.

Um FuseLLM mit vorhandenen Fusionsmethoden (wie Modellensemble und Gewichtszusammenführung) zu vergleichen, simulierten die Autoren ein Szenario, in dem mehrere Quellmodelle von einem Basismodell derselben Struktur stammten, aber kontinuierlich auf verschiedenen Korpora trainiert wurden , und testete die Verwirrung verschiedener Methoden an verschiedenen Testbenchmarks. Es ist ersichtlich, dass obwohl alle Fusionstechniken die Vorteile mehrerer Quellmodelle kombinieren können, FuseLLM die niedrigste durchschnittliche Verwirrung erreichen kann, was darauf hindeutet, dass FuseLLM das Potenzial hat, das kollektive Wissen von Quellmodellen effektiver zu kombinieren als Modellensemble- und Gewichtszusammenführungsmethoden.
Obwohl die Community derzeit der Fusion großer Modelle Aufmerksamkeit schenkt, basieren aktuelle Ansätze größtenteils auf der Gewichtszusammenführung und können nicht auf Modellfusionsszenarien unterschiedlicher Struktur und Größe ausgeweitet werden. Obwohl es sich bei FuseLLM nur um eine vorläufige Forschung zur heterogenen Modellfusion handelt, stellt sich die Frage, wie die Fusion dieser heterogenen Modelle aussehen wird, wenn man bedenkt, dass es in der technischen Gemeinschaft derzeit eine große Anzahl sprachlicher, visueller, akustischer und multimodaler Großmodelle unterschiedlicher Struktur und Größe gibt in der Zukunft ausbrechen? Erstaunliche Leistung? lasst uns abwarten und sehen!
Das obige ist der detaillierte Inhalt vonDie Fusion mehrerer heterogener Großmodelle bringt erstaunliche Ergebnisse. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!