
Heim >Technologie-Peripheriegeräte >KI >RoSA: Eine neue Methode zur effizienten Feinabstimmung großer Modellparameter
RoSA: Eine neue Methode zur effizienten Feinabstimmung großer Modellparameter

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBnach vorne
- 2024-01-18 17:27:17719Durchsuche
Da Sprachmodelle in beispiellosem Umfang skaliert werden, wird eine umfassende Feinabstimmung nachgelagerter Aufgaben kostspielig. Um dieses Problem zu lösen, begannen Forscher, der PEFT-Methode Aufmerksamkeit zu schenken und sie zu übernehmen. Die Hauptidee der PEFT-Methode besteht darin, den Umfang der Feinabstimmung auf einen kleinen Satz von Parametern zu beschränken, um die Rechenkosten zu senken und gleichzeitig eine hochmoderne Leistung bei Aufgaben zum Verstehen natürlicher Sprache zu erzielen. Auf diese Weise können Forscher Rechenressourcen einsparen und gleichzeitig eine hohe Leistung aufrechterhalten, wodurch neue Forschungsschwerpunkte auf dem Gebiet der Verarbeitung natürlicher Sprache entstehen.
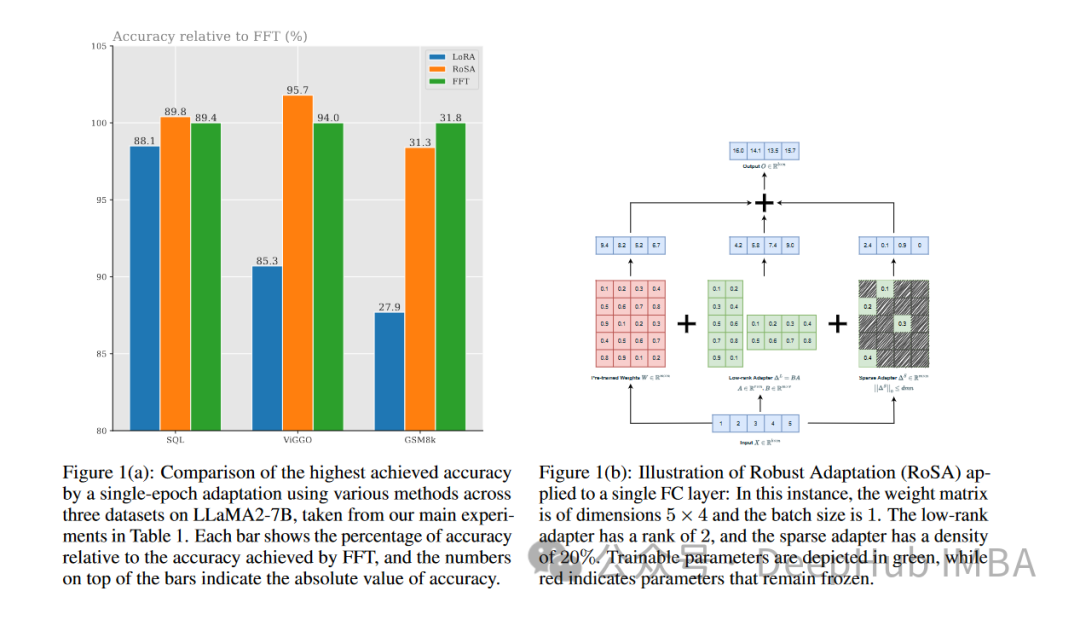
RoSA ist eine neue PEFT-Technik. Durch Experimente mit einer Reihe von Benchmarks wurde festgestellt, dass RoSA bei gleichem Parameterbudget und reiner Sparse-Feinleistung eine bessere Leistung erbringt als die vorherige Low-Rank-Adaption (LoRA). -Tuning-Methoden.
In diesem Artikel werfen wir einen detaillierten Blick auf die RoSA-Prinzipien, -Methoden und -Ergebnisse und erläutern, wie ihre Leistung einen sinnvollen Fortschritt markiert. Für diejenigen, die große Sprachmodelle effektiv verfeinern möchten, bietet RoSA eine neue Lösung, die früheren Lösungen überlegen ist.
Der Bedarf an effizienter Feinabstimmung von Parametern
NLP wurde durch transformatorbasierte Sprachmodelle wie GPT-4 revolutioniert. Diese Modelle erlernen leistungsstarke Sprachdarstellungen durch Vortraining an großen Textkorpora. Anschließend übertragen sie diese Darstellungen durch einen einfachen Prozess auf nachgelagerte Sprachaufgaben.
Da die Modellgröße von Milliarden auf Billionen Parameter anwächst, bringt die Feinabstimmung einen enormen Rechenaufwand mit sich. Bei einem Modell wie GPT-4 mit 1,76 Billionen Parametern kann die Feinabstimmung beispielsweise Millionen von Dollar kosten. Dies macht den Einsatz in realen Anwendungen sehr unpraktisch. Die
PEFT-Methode verbessert die Effizienz und Genauigkeit, indem sie den Parameterbereich der Feinabstimmung begrenzt. In jüngster Zeit sind verschiedene PEFT-Technologien entstanden, die einen Kompromiss zwischen Effizienz und Genauigkeit bieten.
LoRA
Eine bekannte PEFT-Methode ist die Low-Rank-Adaption (LoRA). LoRA wurde 2021 von Forschern von Meta und MIT ins Leben gerufen. Dieser Ansatz basiert auf der Beobachtung, dass der Transformator in seiner Kopfmatrix eine Struktur mit niedrigem Rang aufweist. Es wird vorgeschlagen, dass LoRA diese Struktur mit niedrigem Rang nutzt, um die Rechenkomplexität zu reduzieren und die Effizienz und Geschwindigkeit des Modells zu verbessern.
LoRA optimiert nur die ersten k singulären Vektoren, während andere Parameter unverändert bleiben. Dies erfordert lediglich O(k) zusätzliche Parameter zur Optimierung anstelle von O(n).
Durch die Nutzung dieser Struktur mit niedrigem Rang kann LoRA aussagekräftige Signale erfassen, die für die Generalisierung nachgelagerter Aufgaben erforderlich sind, und die Feinabstimmung auf diese obersten singulären Vektoren beschränken, wodurch Optimierung und Inferenz effizienter werden.
Experimente zeigen, dass LoRA die vollständig fein abgestimmte Leistung des GLUE-Benchmarks erreichen kann und dabei mehr als 100-mal weniger Parameter verwendet. Da die Modellgröße jedoch weiter zunimmt, erfordert das Erreichen einer starken Leistung durch LoRA eine Erhöhung des Rangs k, wodurch die Recheneinsparungen im Vergleich zur vollständigen Feinabstimmung verringert werden.
Vor RoSA stellte LoRA den neuesten Stand der PEFT-Methoden dar, mit nur bescheidenen Verbesserungen durch Techniken wie unterschiedliche Matrixfaktorisierung oder das Hinzufügen einer kleinen Anzahl zusätzlicher Feinabstimmungsparameter.
Robust Adaptation (RoSA)
Robust Adaptation (RoSA) führt eine neue Parameter-effiziente Feinabstimmungsmethode ein. RoSA basiert auf einer robusten Hauptkomponentenanalyse (robuste PCA) und verlässt sich nicht ausschließlich auf Strukturen mit niedrigem Rang.
In der traditionellen Hauptkomponentenanalyse die Datenmatrix Robust PCA geht noch einen Schritt weiter und zerlegt X in ein sauberes L mit niedrigem Rang und ein „kontaminiertes/beschädigtes“ spärliches S.
RoSA lässt sich hiervon inspirieren und unterteilt die Feinabstimmung des Sprachmodells in:
Eine LoRA-ähnliche Low-Rank-Adaptive (L)-Matrix, feinabgestimmt, um das dominante aufgabenrelevante Signal anzunähern
A height Eine spärliche Feinabstimmungsmatrix (S), die eine sehr kleine Anzahl großer, selektiv feinabgestimmter Parameter enthält, die das von L übersehene Restsignal kodieren.
Durch die explizite Modellierung der verbleibenden Sparse-Komponente kann RoSA eine höhere Genauigkeit erreichen als LoRA allein.
RoSA konstruiert L, indem es eine Low-Rank-Zerlegung der Kopfmatrix des Modells durchführt. Dadurch werden zugrunde liegende semantische Darstellungen codiert, die für nachgelagerte Aufgaben nützlich sind. RoSA passt dann selektiv die obersten m wichtigsten Parameter jeder Schicht auf S an, während alle anderen Parameter unverändert bleiben. Dieser Schritt erfasst Restsignale, die für die Anpassung mit niedrigem Rang nicht geeignet sind.
Die Anzahl der Feinabstimmungsparameter m ist eine Größenordnung kleiner als der Rang k, der allein von LoRA benötigt wird. In Kombination mit der Kopfmatrix mit niedrigem Rang in L behält RoSA daher eine extrem hohe Parametereffizienz bei.
RoSA verwendet auch einige andere einfache, aber effektive Optimierungen:
Rest-sparse-Verbindung: S-Residuen werden direkt zum Ausgang jedes Transformatorblocks hinzugefügt, bevor er die Schichtnormalisierung und Feedforward-Unterschichten durchläuft. Dadurch können von L verpasste Signale simuliert werden.
Unabhängige Sparse-Masken: Die in S zur Feinabstimmung ausgewählten Metriken werden für jede Transformatorschicht unabhängig generiert.
Gemeinsame Struktur mit niedrigem Rang: Die gleichen U- und V-Basismatrizen mit niedrigem Rang werden von allen Schichten von L gemeinsam genutzt, genau wie in LoRA. Dadurch werden semantische Konzepte in einem konsistenten Unterraum erfasst.
Diese Architekturoptionen bieten der RoSA-Modellierung eine Flexibilität, die einer vollständigen Feinabstimmung ähnelt, während gleichzeitig die Parametereffizienz für Optimierung und Inferenz erhalten bleibt. Mithilfe dieser PEFT-Methode, die robuste Low-Rank-Adaption und äußerst spärliche Residuen kombiniert, erreicht RoSA eine neue Technologie für den Kompromiss zwischen Genauigkeit und Effizienz.
Experimente und Ergebnisse
Die Forscher bewerteten RoSA anhand eines umfassenden Benchmarks von 12 NLU-Datensätzen, die Aufgaben wie Texterkennung, Stimmungsanalyse, Inferenz natürlicher Sprache und Robustheitstests abdeckten. Sie führten Experimente mit RoSA auf Basis des künstlichen Intelligenzassistenten LLM und einem 12-Milliarden-Parametermodell durch.
Bei jeder Aufgabe schneidet RoSA bei Verwendung der gleichen Parameter deutlich besser ab als LoRA. Die Gesamtparameter beider Methoden betragen ca. 0,3 % des gesamten Modells. Dies bedeutet, dass es in beiden Fällen für k = 16 für LoRA und m = 5120 für RoSA etwa 4,5 Millionen Feinabstimmungsparameter gibt.
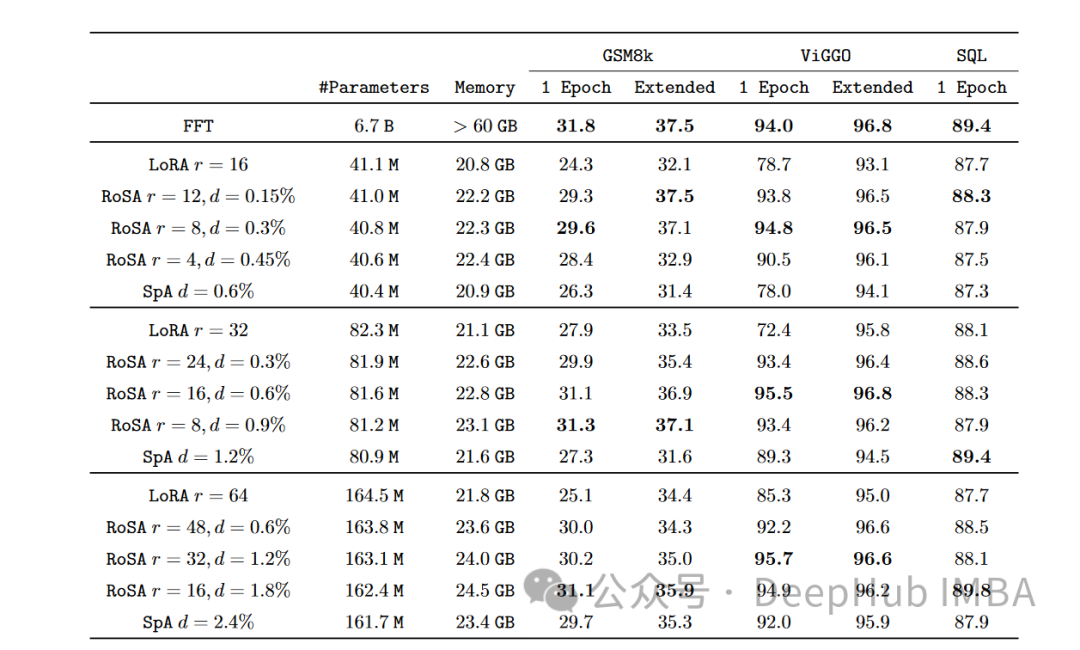
RoSA erreicht oder übertrifft auch die Leistung reiner, spärlicher, fein abgestimmter Basislinien.
Beim ANLI-Benchmark, der die Robustheit gegenüber gegnerischen Beispielen bewertet, erreicht RoSA einen Wert von 55,6, während LoRA einen Wert von 52,7 erreicht. Dies zeigt Verbesserungen bei der Generalisierung und Kalibrierung.
Für die Stimmungsanalyseaufgaben SST-2 und IMDB erreicht die Genauigkeit von RoSA 91,2 % und 96,9 %, während die Genauigkeit von LoRA 90,1 % und 95,3 % erreicht.
Beim WIC, einem anspruchsvollen Wortsinn-Begriffsklärungstest, erreichte RoSA einen F1-Wert von 93,5, während LoRA einen F1-Wert von 91,7 erreichte.
Über alle 12 Datensätze hinweg zeigt RoSA bei übereinstimmenden Parameterbudgets im Allgemeinen eine bessere Leistung als LoRA.
Bemerkenswert ist, dass RoSA diese Vorteile erzielen kann, ohne dass eine aufgabenspezifische Abstimmung oder Spezialisierung erforderlich ist. Dadurch eignet sich RoSA als universelle PEFT-Lösung.
Zusammenfassung
Da der Umfang von Sprachmodellen weiterhin schnell wächst, ist die Reduzierung des Rechenaufwands für deren Feinabstimmung ein dringendes Problem, das gelöst werden muss. Parametereffiziente adaptive Trainingstechniken wie LoRA haben erste Erfolge gezeigt, sind jedoch mit inhärenten Einschränkungen der Approximation mit niedrigem Rang konfrontiert.
RoSA kombiniert auf organische Weise robuste Low-Rank-Zerlegung und restliche, sehr spärliche Feinabstimmung, um eine überzeugende neue Lösung bereitzustellen. Es verbessert die Leistung von PEFT erheblich, indem es Signale berücksichtigt, die der Anpassung mit niedrigem Rang durch selektive, spärliche Residuen entgehen. Die empirische Auswertung zeigt signifikante Verbesserungen gegenüber LoRA und unkontrollierten Sparsity-Baselines bei verschiedenen NLU-Aufgabensätzen.
RoSA ist konzeptionell einfach, aber leistungsstark und kann die Schnittstelle zwischen Parametereffizienz, adaptiver Darstellung und kontinuierlichem Lernen weiter vorantreiben, um die Sprachintelligenz zu erweitern.
Das obige ist der detaillierte Inhalt vonRoSA: Eine neue Methode zur effizienten Feinabstimmung großer Modellparameter. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Die Parameter werden leicht verbessert und der Leistungsindex explodiert! Google: Große Sprachmodelle verbergen „mysteriöse Fähigkeiten'
- Die Genauigkeit von GPT-3 beim Lösen mathematischer Probleme ist auf 92,5 % gestiegen! Microsoft schlägt MathPrompter vor, um „wissenschaftliche' Sprachmodelle ohne Feinabstimmung zu erstellen
- Ein weiterer „starker Player' wurde dem KI-Bereich hinzugefügt: Meta veröffentlicht ein neues groß angelegtes Sprachmodell LLaMA
- Sechs Möglichkeiten zum Aufbau von KI-Chatbots und großen Sprachmodellen zur Verbesserung der Cybersicherheit
- Als erstes inländisches Unternehmen bestand 360 Intelligent Brain die bewährte AIGC-Funktionsbewertung für große Sprachmodelle der China Academy of Information and Communications Technology