
Heim >Technologie-Peripheriegeräte >KI >Das Suchteam von Xiaohongshu enthüllt: Die Bedeutung der Überprüfung negativer Proben bei der groß angelegten Modelldestillation
Das Suchteam von Xiaohongshu enthüllt: Die Bedeutung der Überprüfung negativer Proben bei der groß angelegten Modelldestillation

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBnach vorne
- 2024-01-17 11:51:051577Durchsuche

Große Sprachmodelle (LLMs) eignen sich gut für Inferenzaufgaben, aber ihre Black-Box-Eigenschaften und die große Anzahl von Parametern schränken ihre Anwendung in der Praxis ein. Insbesondere bei der Bearbeitung komplexer mathematischer Probleme entwickeln LLMs manchmal fehlerhafte Argumentationsketten. Herkömmliche Forschungsmethoden übertragen nur Wissen aus positiven Proben und ignorieren wichtige Informationen mit falschen Antworten in synthetischen Daten. Um die Leistung und Zuverlässigkeit von LLMs zu verbessern, müssen wir daher synthetische Daten umfassender berücksichtigen und nutzen und uns nicht nur auf positive Stichproben beschränken, um LLMs dabei zu helfen, komplexe Probleme besser zu verstehen und zu begründen. Dies wird dazu beitragen, die Herausforderungen von LLMs in der Praxis zu lösen und ihre breite Anwendung zu fördern.
Auf der AAAI 2024 schlug das Xiaohongshu-Suchalgorithmus-Team ein innovatives Framework vor, das negatives Stichprobenwissen bei der Destillation großer Modellschlussfähigkeiten vollständig nutzt. Negative Stichproben, also solche Daten, die während des Inferenzprozesses keine korrekten Antworten liefern, werden oft als nutzlos angesehen, tatsächlich enthalten sie jedoch wertvolle Informationen.
Der Artikel schlägt den Wert negativer Proben im Destillationsprozess großer Modelle vor und verifiziert ihn und baut einen Modellspezialisierungsrahmen auf: Neben der Verwendung positiver Proben werden auch negative Proben vollständig genutzt, um das Wissen über LLM zu verfeinern. Das Framework umfasst drei Serialisierungsschritte, darunter Negative Assisted Training (NAT), Negative Calibration Enhancement (NCE) und Dynamic Self-Consistency (ASC), die den gesamten Prozess vom Training bis zur Inferenz abdecken. Durch eine umfangreiche Reihe von Experimenten demonstrieren wir die entscheidende Rolle negativer Daten bei der LLM-Wissensdestillation.
1. HintergrundIn der aktuellen Situation haben große Sprachmodelle (LLMs) unter der Führung der Chain of Thought (CoT) leistungsstarke Argumentationsfähigkeiten bewiesen. Wir haben jedoch gezeigt, dass diese neue Fähigkeit nur durch Modelle mit Hunderten Milliarden Parametern erreicht werden kann. Da diese Modelle enorme Rechenressourcen und hohe Inferenzkosten erfordern, sind sie unter Ressourcenbeschränkungen nur schwer anzuwenden. Daher ist es unser Forschungsziel, kleine Modelle zu entwickeln, die komplexe arithmetische Schlussfolgerungen für den groß angelegten Einsatz in realen Anwendungen ermöglichen.
Wissensdestillation bietet eine effiziente Möglichkeit, die spezifischen Fähigkeiten von LLMs in kleinere Modelle zu übertragen. Dieser Prozess, auch Modellspezialisierung genannt, zwingt kleine Modelle dazu, sich auf bestimmte Fähigkeiten zu konzentrieren. Frühere Forschungen nutzen kontextuelles Lernen (ICL) von LLMs, um Argumentationspfade für mathematische Probleme zu generieren, und verwenden sie als Trainingsdaten, die kleinen Modellen dabei helfen, komplexe Argumentationsfähigkeiten zu erwerben. Allerdings verwendeten diese Studien nur die generierten Inferenzpfade mit korrekten Antworten (d. h. positive Stichproben) als Trainingsbeispiele und ignorierten das wertvolle Wissen in den Inferenzschritten mit falschen Antworten (d. h. negativen Stichproben). Daher begannen Forscher zu untersuchen, wie die Inferenzschritte in negativen Stichproben genutzt werden können, um die Leistung kleiner Modelle zu verbessern. Ein Ansatz besteht darin, kontradiktorisches Training zu verwenden, bei dem ein Generatormodell eingeführt wird, um Rückschlusspfade für falsche Antworten zu generieren, und diese Pfade dann zusammen mit positiven Beispielen verwendet werden, um ein kleines Modell zu trainieren. Auf diese Weise kann das kleine Modell im Fehlerbegründungsschritt wertvolles Wissen erlernen und seine Argumentationsfähigkeit verbessern. Ein anderer Ansatz besteht darin, selbstüberwachtes Lernen zu nutzen, indem man richtige Antworten mit falschen Antworten vergleicht und ein kleines Modell lernen lässt, zwischen ihnen zu unterscheiden und daraus nützliche Informationen zu extrahieren. Diese Methoden können ein umfassenderes Training für kleine Modelle ermöglichen und ihnen leistungsfähigere Argumentationsfähigkeiten verleihen. Kurz gesagt: Die Verwendung der Inferenzschritte in negativen Stichproben kann kleinen Modellen dabei helfen, ein umfassenderes Training zu erhalten und ihre Inferenzfähigkeiten zu verbessern. Diese Art von
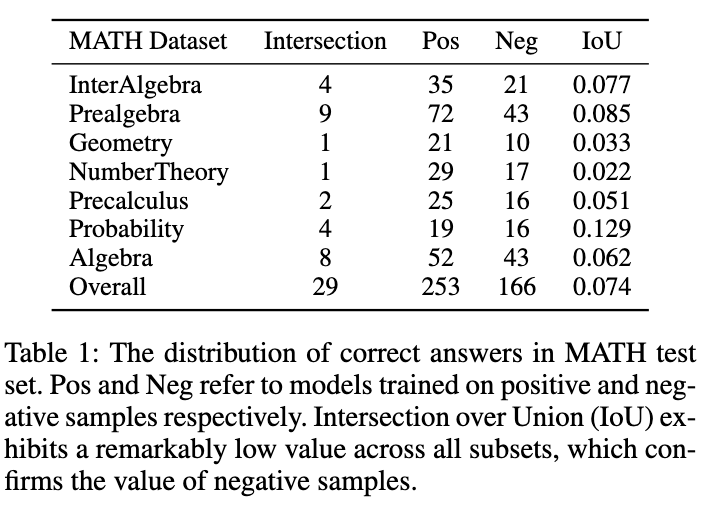 Bild
Bild
ist in der Abbildung dargestellt. Tabelle 1 zeigt ein interessantes Phänomen: Die auf positiven und negativen Beispieldaten trainierten Modelle weisen nur sehr geringe Überschneidungen bei den genauen Antworten auf den MATH-Testsatz auf. Obwohl das mit negativen Stichproben trainierte Modell weniger genau ist, kann es einige Fragen lösen, die das positive Stichprobenmodell nicht richtig beantworten kann, was bestätigt, dass die negativen Stichproben wertvolles Wissen enthalten. Darüber hinaus können fehlerhafte Verknüpfungen in negativen Stichproben dazu beitragen, dass das Modell ähnliche Fehler vermeidet. Ein weiterer Grund, warum wir negative Stichproben nutzen sollten, ist die tokenbasierte Preisstrategie von OpenAI. Selbst die Genauigkeit von GPT-4 im MATH-Datensatz beträgt weniger als 50 %, was bedeutet, dass eine große Menge an Token verschwendet wird, wenn nur positives Stichprobenwissen genutzt wird. Daher schlagen wir vor, negative Proben nicht direkt zu verwerfen, sondern wertvolles Wissen daraus zu extrahieren und zu nutzen, um die Spezialisierung kleiner Modelle zu verbessern.
Der Modellspezialisierungsprozess lässt sich im Allgemeinen in drei Schritte zusammenfassen:
1) Gedankenkettendestillation unter Verwendung der von LLMs generierten Inferenzkette, um ein kleines Modell zu trainieren.
2) Selbstverbesserung: Führen Sie eine Selbstdestillation oder Datenselbsterweiterung durch, um das Modell weiter zu optimieren.
3) Selbstkonsistenz wird häufig als wirksame Dekodierungsstrategie zur Verbesserung der Modellleistung bei Inferenzaufgaben eingesetzt.
In dieser Arbeit schlagen wir ein neues Modellspezialisierungs-Framework vor, das negative Stichproben vollständig nutzen und die Extraktion komplexer Inferenzfunktionen aus LLMs erleichtern kann.
- Wir haben zunächst die Methode Negative Assisted Training (NAT) entwickelt, bei der die Dual-LoRA-Struktur darauf ausgelegt ist, Wissen sowohl aus positiven als auch aus negativen Aspekten zu erwerben. Als Hilfsmodul kann das Wissen über negatives LoRA durch den korrigierenden Aufmerksamkeitsmechanismus dynamisch in den Trainingsprozess von positivem LoRA integriert werden.
- Zur Selbstverbesserung entwickeln wir Negative Calibration Enhancement (NCE), das den negativen Output als Grundlage nimmt, um die Destillation wichtiger Vorwärtsbegründungsverbindungen zu stärken.
- Neben der Trainingsphase nutzen wir auch negative Informationen während des Inferenzprozesses. Herkömmliche Selbstkonsistenzmethoden weisen allen Kandidatenausgaben gleiche oder wahrscheinlichkeitsbasierte Gewichtungen zu, was dazu führt, dass für einige unzuverlässige Antworten gestimmt wird. Um dieses Problem zu lindern, wird die Methode „Dynamische Selbstkonsistenz (ASC)“ zum Sortieren vor der Abstimmung vorgeschlagen, bei der das Sortiermodell anhand positiver und negativer Stichproben trainiert wird. 2. Methode
- Schritt 1: Trainieren Sie negatives LoRA durch Zusammenführen. Die Einheit hilft Erlernen Sie das Schlussfolgerungswissen über positive Proben Schritt 3: Ein Ranking-Modell wird auf positive und negative Stichproben trainiert, und Kandidaten-Inferenz-Links werden während der Inferenz adaptiv entsprechend ihren Bewertungen gewichtet. 2.1 Negative Assistance Training (NAT) Integrationseinheit besteht aus zwei Teilen:
2.1.1 Negative Wissensabsorption -
Durch Maximierung der folgenden Erwartung an negative Daten
wird das Wissen über negative Proben von LoRA θ absorbiert. Während dieses Vorgangs bleiben die Parameter von LLaMA eingefroren. 2.1.2 Dynamische integrierte Einheit In der folgenden Abbildung wird das Wissen aus θ - zur Erleichterung des Lernens positiver Beispielkenntnisse dynamisch integriert:
Bilder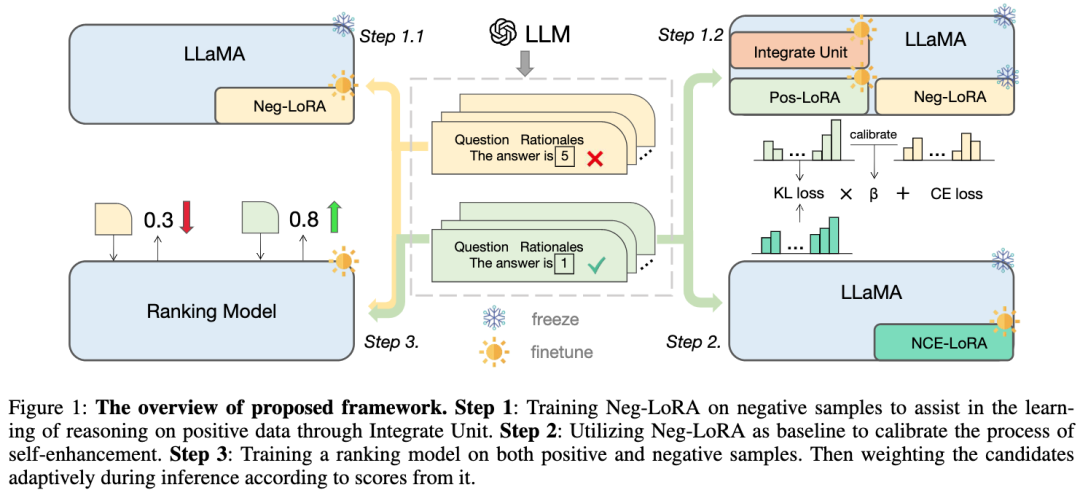
ein, um zu verhindern, dass internes Wissen entsteht vergessen und zusätzlich das positive LoRA-Modul θ einführen. Idealerweise sollten wir positive und negative LoRA-Module vorwärts integrieren (die Ausgaben in jeder LLaMA-Schicht werden als und dargestellt), um das nützliche Wissen zu ergänzen, das in den positiven Proben fehlt, aber entspricht. Wenn θ
schädliches Wissen enthält, sollten wir eine negative Integration positiver und negativer LoRA-Module durchführen, um mögliches schlechtes Verhalten in positiven Proben zu reduzieren.
Wir schlagen einen korrigierenden Aufmerksamkeitsmechanismus vor, um dieses Ziel wie folgt zu erreichen:Bilder
Bilder
Wir verwenden als Abfrage, um die Aufmerksamkeitsgewichte von und zu berechnen. Durch Hinzufügen des Korrekturterms [0,5; -0,5] wird das Aufmerksamkeitsgewicht von auf den Bereich von [-0,5, 0,5] begrenzt, wodurch der Effekt einer adaptiven Integration von Wissen sowohl aus positiver als auch aus negativer Richtung erzielt wird. Schließlich bildet die Summe von und der Ausgabe der LLaMA-Schicht die Ausgabe der dynamischen Integrationseinheit. Um die Denkfähigkeit des Modells weiter zu verbessern, schlagen wir Negative Calibration Enhancement (NCE) vor, das negatives Wissen nutzt, um den Selbstverbesserungsprozess zu unterstützen. Wir verwenden NAT zunächst, um Paare als Erweiterungsbeispiele für jede Frage zu generieren und sie in den Trainingsdatensatz einzufügen. Was den Selbstdestillationsteil betrifft, stellen wir fest, dass einige Proben möglicherweise kritischere Inferenzschritte enthalten, die für die Verbesserung der Inferenzfähigkeit des Modells von entscheidender Bedeutung sind. Unser Hauptziel ist es, diese kritischen Inferenzschritte zu identifizieren und ihr Lernen während der Selbstdestillation zu verbessern. Wenn man bedenkt, dass NAT bereits nützliches Wissen über θ enthält, sind die Faktoren, die NAT über stärkere Denkfähigkeiten als θ verfügen, implizit in den inkonsistenten Denkverbindungen zwischen den beiden enthalten. Daher verwenden wir die KL-Divergenz, um diese Inkonsistenz zu messen und die Erwartung dieser Formel zu maximieren: Bilder 2.3 Dynamische Selbstkonsistenz (ASC) Selbstkonsistenz (SC) ist wirksam bei der weiteren Verbesserung der Leistung des Modells beim komplexen Denken. Aktuelle Methoden weisen jedoch entweder jedem Kandidaten die gleiche Gewichtung zu oder weisen einfach Gewichtungen basierend auf Generationswahrscheinlichkeiten zu. Diese Strategien können die Kandidatengewichte nicht entsprechend der Qualität von (rˆ, yˆ) während der Abstimmungsphase anpassen, was die Auswahl des richtigen Kandidaten erschweren kann. Zu diesem Zweck schlagen wir die dynamische Selbstkonsistenzmethode (ASC) vor, die positive und negative Daten verwendet, um ein Ranking-Modell zu trainieren und Kandidaten-Inferenzlinks adaptiv neu zu gewichten. 2.3.1 Ranking-Modell-Training Bilder Bilder 2.3.2 Gewichtungsstrategie Bild Bild 3. Experiment Für das Lehrermodell verwenden wir die APIs gpt-3.5-turbo und gpt-4 von Open AI, um die Inferenzkette zu generieren. Für das Studentenmodell wählen wir LLaMA-7b. In unserer Forschung gibt es zwei Haupttypen von Basislinien: Die eine sind große Sprachmodelle (LLMs) und die andere basiert auf LLaMA-7b. Was LLMs betrifft, vergleichen wir sie mit zwei beliebten Modellen: GPT3 und PaLM. Für LLaMA-7b stellen wir zunächst unsere Methode zum Vergleich mit drei Einstellungen vor: Few-shot, Fine-tune (an Original-Trainingsbeispielen), CoT KD (Chain of Thought Distillation). Im Hinblick auf das Lernen aus der negativen Perspektive werden auch vier Basismethoden einbezogen: MIX (Training von LLaMA direkt mit einer Mischung aus positiven und negativen Daten), CL (kontrastives Lernen), NT (negatives Training) und UL (Nicht-Likelihood-Verlust). ) ). Alle Methoden verwenden eine gierige Suche (d. h. Temperatur = 0), und die experimentellen Ergebnisse von NAT sind in der Abbildung dargestellt, was zeigt, dass die vorgeschlagene NAT-Methode die Genauigkeit der Aufgabe auf allen Basislinien verbessert. Wie aus den niedrigen Werten von GPT3 und PaLM ersichtlich ist, ist MATH ein sehr schwieriger mathematischer Datensatz, aber NAT kann mit sehr wenigen Parametern immer noch eine gute Leistung erbringen. Im Vergleich zur Feinabstimmung von Rohdaten erreicht NAT unter zwei verschiedenen CoT-Quellen eine Verbesserung von etwa 75,75 %. NAT verbessert auch die Genauigkeit im Vergleich zu CoT KD bei positiven Proben erheblich, was den Wert negativer Proben verdeutlicht. Bei der Verwendung negativer Informationsbasislinien deutet die geringe Leistung von MIX darauf hin, dass das direkte Training negativer Proben zu einer schlechten Leistung des Modells führt. Auch andere Methoden sind NAT meist unterlegen, was zeigt, dass es bei komplexen Argumentationsaufgaben nicht ausreicht, nur negative Stichproben in die negative Richtung zu verwenden. Wie in der Abbildung gezeigt, erzielt NCE im Vergleich zur Wissensdestillation (KD) eine durchschnittliche Verbesserung von 10 % (0,66), was die Verwendung von Negativ beweist Proben Gültigkeit der für die Destillation bereitgestellten Kalibrierungsinformationen. Obwohl NCE im Vergleich zu NAT einige Parameter reduziert, weist es dennoch eine Verbesserung von 6,5 % auf, wodurch der Zweck der Komprimierung des Modells und der Verbesserung der Leistung erreicht wird. Um ASC zu bewerten, vergleichen wir es mit Basis-SC und gewichtetem (WS) SC, wobei wir die Probentemperatur T = 1 verwenden und 16 Proben generieren. Wie in der Abbildung dargestellt, zeigen die Ergebnisse, dass ASC, das Antworten aus verschiedenen Stichproben aggregiert, eine vielversprechendere Strategie ist. Zusätzlich zum MATH-Datensatz haben wir die Generalisierungsfähigkeit des Frameworks für andere mathematische Denkaufgaben bewertet. Die experimentellen Ergebnisse sind wie folgt. Diese Arbeit untersucht die Wirksamkeit der Verwendung negativer Stichproben, um komplexe Argumentationsfähigkeiten aus großen Sprachmodellen zu extrahieren und sie auf spezialisierte kleine Modelle zu übertragen. „Das Xiaohongshu Search Algorithm Team“ schlug ein brandneues Framework vor, das aus drei Serialisierungsschritten besteht und negative Informationen während des gesamten Prozesses der Modellspezialisierung vollständig nutzt. Negative Assistance Training (NAT) kann eine umfassendere Möglichkeit bieten, negative Informationen aus zwei Perspektiven zu nutzen. Negative Calibration Enhancement (NCE) ist in der Lage, den Selbstdestillationsprozess so zu kalibrieren, dass er Schlüsselwissen gezielter beherrschen kann. Ein auf beide Gesichtspunkte trainiertes Ranking-Modell kann der Antwortaggregation geeignetere Gewichtungen zuweisen, um eine dynamische Selbstkonsistenz (ASC) zu erreichen. Umfangreiche Experimente zeigen, dass unser Framework die Effektivität der Verfeinerung der Argumentationsfähigkeiten durch die generierten negativen Stichproben verbessern kann. 2.2 Negative Calibration Enhancement (NCE)
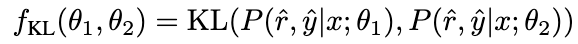 Bilder
Bilder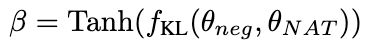 Bilder
Bilder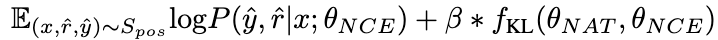 Bilder
BilderJe größer der β-Wert ist Je höher der Unterschied zwischen den beiden ist, desto mehr kritisches Wissen enthält die Stichprobe. Durch die Einführung von β zur Anpassung des Verlustgewichts verschiedener Proben kann NCE das in NAT eingebettete Wissen gezielt erlernen und verbessern.
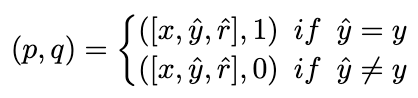 Idealerweise möchten wir, dass das Ranking-Modell den Inferenzlinks, die zur richtigen Antwort führen, höhere Gewichtungen zuweist und umgekehrt. Daher erstellen wir die Trainingsbeispiele auf folgende Weise:
Idealerweise möchten wir, dass das Ranking-Modell den Inferenzlinks, die zur richtigen Antwort führen, höhere Gewichtungen zuweist und umgekehrt. Daher erstellen wir die Trainingsbeispiele auf folgende Weise: 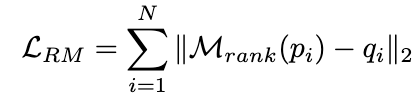 und verwenden MSE-Verlust, um das Ranking-Modell zu trainieren:
und verwenden MSE-Verlust, um das Ranking-Modell zu trainieren: 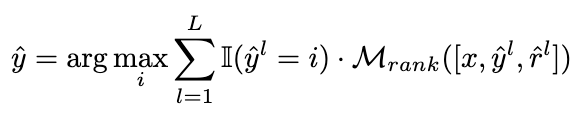 Wir ändern die Abstimmungsstrategie auf die folgende Formel, um das Ziel der adaptiven Neugewichtung von Kandidaten-Inferenzlinks zu erreichen:
Wir ändern die Abstimmungsstrategie auf die folgende Formel, um das Ziel der adaptiven Neugewichtung von Kandidaten-Inferenzlinks zu erreichen:  Die folgende Abbildung zeigt den Ablauf der ASC-Strategie:
Die folgende Abbildung zeigt den Ablauf der ASC-Strategie: 3.1 NAT-Experimentelle Ergebnisse
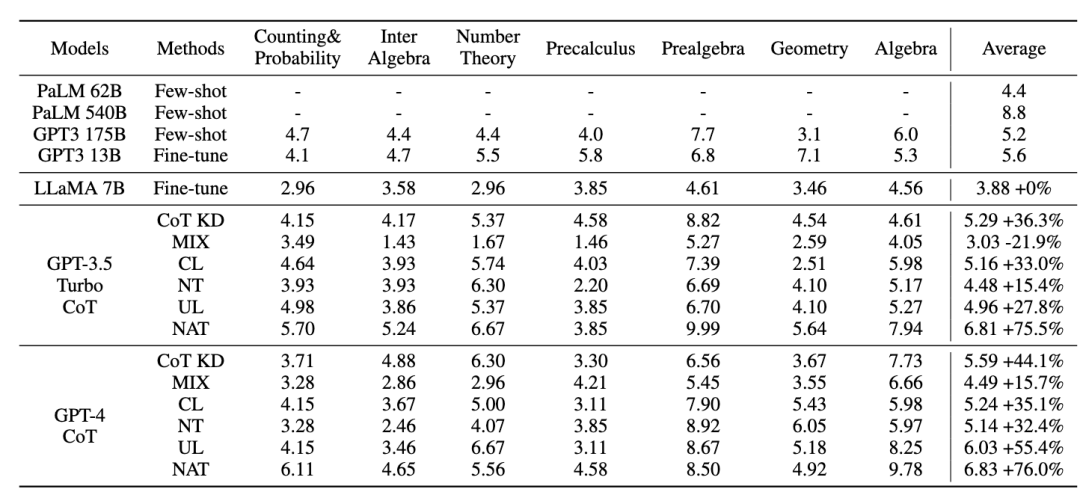 Bilder
Bilder3.2 NCE-Experimentergebnisse
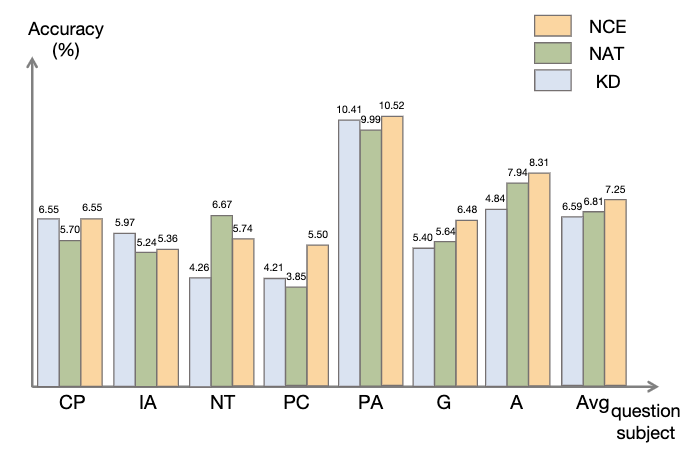 Bilder
Bilder3.3 ASC-Experimentalergebnisse
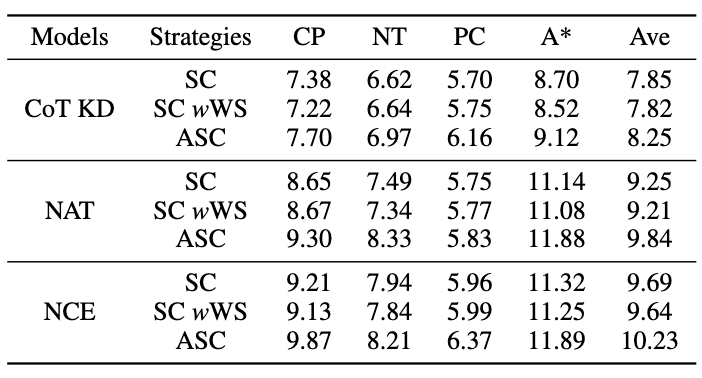 Bilder
Bilder3.4 Ergebnisse des Generalisierungsexperiments
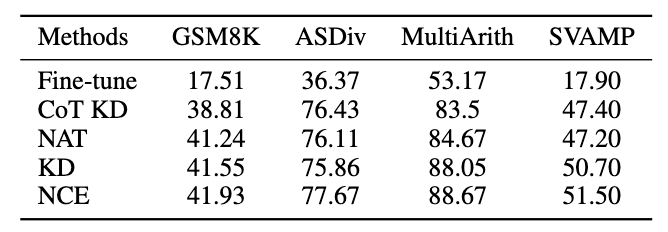 Bilder
Bilder 4. Fazit
Das obige ist der detaillierte Inhalt vonDas Suchteam von Xiaohongshu enthüllt: Die Bedeutung der Überprüfung negativer Proben bei der groß angelegten Modelldestillation. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Technologietrends, die Sie im Jahr 2023 im Auge behalten sollten
- Wie künstliche Intelligenz Rechenzentrumsteams neue Alltagsaufgaben beschert
- Können künstliche Intelligenz oder Automatisierung das Problem der geringen Energieeffizienz in Gebäuden lösen?
- OpenAI-Mitbegründer im Interview mit Huang Renxun: Die Argumentationsfähigkeiten von GPT-4 haben noch nicht die Erwartungen erfüllt
- Dank der OpenAI-Technologie übertrifft Bing von Microsoft Google im Suchverkehr