
Heim >Technologie-Peripheriegeräte >KI >TaskWeaver: ein Open-Source-Framework, das die Datenanalyse und Branchenanpassung erleichtert, um hervorragende Agent-Lösungen zu erstellen
TaskWeaver: ein Open-Source-Framework, das die Datenanalyse und Branchenanpassung erleichtert, um hervorragende Agent-Lösungen zu erstellen

- 王林nach vorne
- 2024-01-17 08:36:18733Durchsuche
Datenanalyse war schon immer ein wichtiges Werkzeug in der modernen Gesellschaft und hilft uns, das Wesentliche tiefgreifend zu verstehen, Muster zu entdecken und Entscheidungen zu treffen. Allerdings ist der Datenanalyseprozess oft komplex und zeitaufwändig, daher erwarten wir einen intelligenten Assistenten, der direkt mit den Daten interagieren kann. Mit der Entwicklung großer Sprachmodelle (LLM) sind nach und nach virtuelle Assistenten und intelligente Agenten wie Copilot entstanden, und ihre Leistung beim Verstehen und Erzeugen natürlicher Sprache ist erstaunlich. Bedauerlicherweise haben bestehende Agenten-Frameworks jedoch immer noch Schwierigkeiten, mit komplexen Datenstrukturen (wie DataFrame, ndarray usw.) umzugehen und Domänenwissen einzuführen, was genau die Kernanforderung in der Datenanalyse und in Berufsfeldern ist.
Um das Engpassproblem von Sprachassistenten bei der Ausführung von Aufgaben besser zu lösen, hat Microsoft ein Agent-Framework namens TaskWeaver eingeführt. Das Framework ist Code-First und kann Benutzeranforderungen in natürlicher Sprache intelligent in ausführbaren Code umwandeln und unterstützt gleichzeitig eine Vielzahl von Datenstrukturen und eine dynamische Plug-in-Auswahl. Darüber hinaus lässt sich TaskWeaver je nach Planungsprozess in unterschiedlichen Bereichen professionell anpassen und nutzt dabei das Potenzial großer Sprachmodelle voll aus. Als Open-Source-Framework bietet TaskWeaver anpassbare Beispiele und Plug-ins, die Wissen in bestimmten Bereichen integrieren können, sodass Benutzer auf einfache Weise personalisierte virtuelle Assistenten erstellen können. Die Einführung von TaskWeaver wird den Intelligenzgrad von Sprachassistenten effektiv verbessern und den wachsenden Bedarf der Benutzer an personalisierten virtuellen Assistenten erfüllen.

- Papier: TaskWeaver: A Code-First Agent Framework
- Papieradresse: https://export.arxiv.org/abs/2311.17541
Das TaskWeaver-Projekt ist Open Source auf GitHub und erschien am Tag der Veröffentlichung auf der GitHub-Trendliste. Derzeit hat das Projekt 2,9.000 Sterne erhalten und eine gute Resonanz erhalten. Darüber hinaus gibt es auch einige Praxisbeispiele auf sozialen Plattformen wie LinkedIn, etwa den Einsatz von TaskWeaver zur SAP-Datenanalyse. Diese Fälle zeigen den Nutzen und Wert von TaskWeaver.
- Project Homepage: https://microsoft.github.io/taskweaver/
- project Adresse: https://github.com/microsoft/taskweaver
Story-Beispiel
Versteckte Geheimnisse in Verkaufsdaten aufspüren
Xiaoya ist Business-Analystin und eine ihrer Aufgaben besteht darin, in aktuellen Verkaufsdaten nach Anomalien zu suchen und das Unternehmen auf der Grundlage dieser Anomalien bei der Anpassung seiner Daten anzuleiten Verkaufsstrategie. Alle Verkaufsdaten werden sicher in einer SQL-Datenbank gespeichert. Sie hofft, durch die Kommunikation in natürlicher Sprache mit einem KI-Assistenten Daten einfach extrahieren und analysieren zu können. Von besonderer Bedeutung ist die Tatsache, dass Anomalien in der Vertriebswelt einzigartig sind. Daher hofft sie, dass der KI-Assistent benutzerdefinierte Algorithmen zur Anomalieerkennung einsetzen kann, um dieses Problem zu lösen. Das Folgende ist die Chat-Aufzeichnung zwischen Xiaoya und dem KI-Assistenten (Abbildung 1), die die Interaktion zwischen ihnen zeigt. Xiaoya: Hallo, ich brauche Hilfe beim Extrahieren und Analysieren von Verkaufsdaten aus der Datenbank. KI-Assistent: OK, ich werde die entsprechenden Daten gleich aus der Datenbank extrahieren. Ich werde Ihnen die extrahierten Daten später zur Bestätigung vorlegen. Xiaoya: Vielen Dank. (Nach einer Weile) KI-Assistent: Ich habe die Verkaufsdaten aus der Datenbank extrahiert. Nachfolgend finden Sie eine Übersicht der Daten, bitte bestätigen Sie. (Übersicht der vom KI-Assistenten angezeigten Daten) Xiaoya: Die Daten sehen gut aus. Bitte fahren Sie mit der Erkennung und Analyse von Anomalien fort. KI-Assistent: Verstanden. Ich führe die Analyse mit unserem benutzerdefinierten Anomalieerkennungsalgorithmus durch und zeige Ihnen so schnell wie möglich intuitive Visualisierungen. (Nach einer Weile) KI-Assistent: Analyse abgeschlossen. Bitte sehen Sie sich die folgenden Visualisierungsergebnisse an. (KI-Assistent zeigt visuelle Ergebnisse an) Xiaoya: Vielen Dank für Ihre Hilfe! Diese Ergebnisse sind für mich sehr wertvoll. KI-Assistent: Ich helfe Ihnen gerne weiter. Wenn Sie weitere Fragen haben oder weitere Analysen benötigen, können Sie mich gerne kontaktieren. Xiaoya: Natürlich vielen Dank für Ihre Unterstützung.
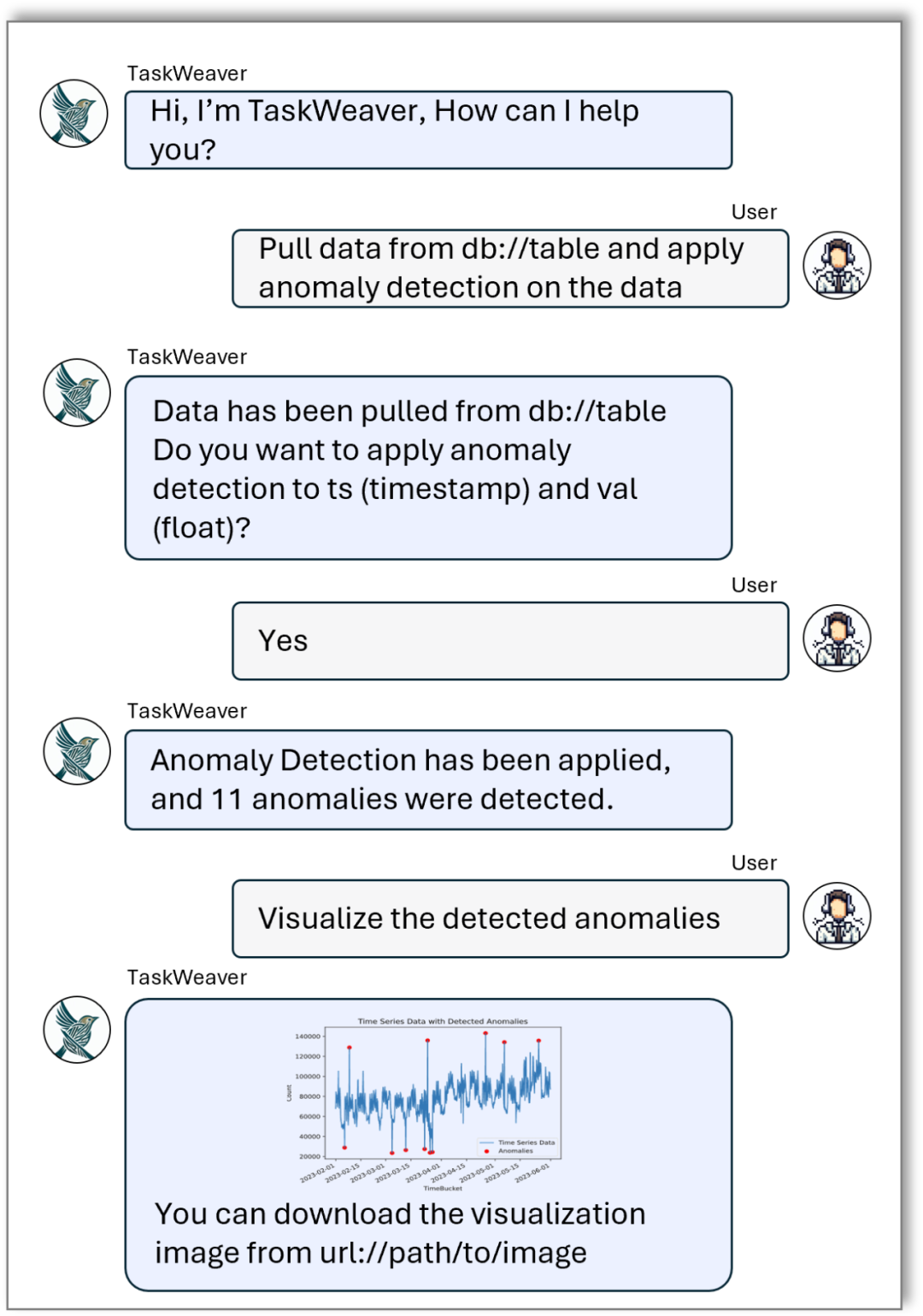
Abbildung 1. Gesprächsprotokoll im Story-Beispiel
Welche Fähigkeiten sind für das Agent-Framework erforderlich?
Durch die oben erwähnte Geschichte von Xiaoya haben wir mehrere Kernfunktionen herausgefunden, die das Agent-Framework haben sollte:
1. Plug-in-Unterstützung: In der obigen Geschichte muss der Agent Daten aus der Datenbank abrufen und dann den angegebenen Anomalieerkennungsalgorithmus verwenden. Um diese Aufgaben zu erfüllen, muss der intelligente Assistent in der Lage sein, benutzerdefinierte Plugins zu definieren und aufzurufen, beispielsweise das Plugin „query_database“ und das Plugin „anomaly_detection“.
2. Umfangreiche Datenstrukturunterstützung: Der Agent muss komplexe Datenstrukturen wie Arrays, Matrizen, Tabellendaten usw. verarbeiten, um erweiterte Datenverarbeitung wie Vorhersage, Clustering usw. reibungslos durchzuführen. Darüber hinaus sollten diese Daten nahtlos zwischen verschiedenen Plugins weitergegeben werden. Die meisten vorhandenen Agenten-Frameworks konvertieren jedoch die Zwischenergebnisse der Datenanalyse in Prompt in Text oder speichern sie zunächst als lokale Dateien und lesen sie dann bei Bedarf. Allerdings sind diese Vorgehensweisen fehleranfällig und überschreiten die Wortbeschränkung der Eingabeaufforderung.
3. Zustandsbehaftete Ausführung: Der Agent muss häufig über mehrere Iterationsrunden mit dem Benutzer interagieren und Code basierend auf Benutzereingaben generieren und ausführen. Daher sollte der Ausführungsstatus dieser Codes während der gesamten Sitzung bis zum Ende der Sitzung beibehalten werden.
4. Zuerst argumentieren und dann handeln (ReAct) : Der Agent sollte über die Fähigkeit von ReAct verfügen, das heißt, zuerst das Denken beobachten und dann Maßnahmen ergreifen, was in einigen Szenarien mit Unsicherheit sehr notwendig ist. Da beispielsweise im obigen Beispiel das Datenschema (Schema) in der Datenbank normalerweise unterschiedlich ist, muss der Agent zunächst die Datenschemainformationen abrufen und verstehen, welche Spalten geeignet sind (und dies mit dem Benutzer bestätigen), und dann die entsprechenden Spalten Der Name kann in den Anomalieerkennungsalgorithmus eingegeben werden.
5. Generieren Sie beliebigen Code: Manchmal können die vordefinierten Plug-Ins die Anforderungen des Benutzers nicht erfüllen und der Agent sollte in der Lage sein, Code zu generieren, um auf die vorübergehenden Anforderungen des Benutzers zu reagieren. Im obigen Beispiel muss der Agent Code generieren, um die erkannten Anomalien zu visualisieren, und dieser Prozess wird ohne die Hilfe von Plug-Ins erreicht.
6. Domänenwissen integrieren: Der Agent sollte eine systematische Lösung zur Integration von Wissen in bestimmten Bereichen bereitstellen. Dies wird LLM bei der besseren Planung und dem genauen Aufruf von Tools unterstützen und so zuverlässige Ergebnisse liefern, insbesondere in branchenspezifischen Szenarien.
Enthüllung der Kernarchitektur von TaskWeaver
Abbildung 2 zeigt die Gesamtarchitektur von TaskWeaver, einschließlich Planner, Code-Interpreter und Speichermodul.
Der Planer ist wie das Gehirn des Systems. Er hat zwei Hauptaufgaben: 1) Erstellen Sie einen Plan, dh teilen Sie die Anforderungen des Benutzers in Unteraufgaben auf, senden Sie diese Unteraufgaben einzeln an den Code-Interpreter und verwenden Sie sie Während des gesamten Plans wird der Plan bei Bedarf während des Ausführungsprozesses selbst angepasst. 2) Reagiert auf den Benutzer. Er wandelt die Feedback-Ergebnisse des Code-Interpreters in für den Benutzer leicht verständliche Antworten um und sendet sie an den Benutzer .
Der Code-Interpreter besteht hauptsächlich aus zwei Komponenten: Der Codegenerator (Codegenerator) empfängt die vom Planer gesendeten Unteraufgaben und kombiniert vorhandene verfügbare Plug-Ins und domänenspezifische Aufgabenbeispiele, um entsprechende Codeblöcke zu generieren Der Code Executor ist für die Ausführung des generierten Codes und die Aufrechterhaltung des Ausführungsstatus während der gesamten Sitzung verantwortlich. Dadurch können komplexe Datenstrukturen im Speicher übergeben werden, ohne dass Eingabeaufforderungen oder das Dateisystem durchlaufen werden müssen. Es ist wie beim Programmieren in Python im Jupyter Notebook, wo der Benutzer einen Codeausschnitt in eine Zelle eingibt und der interne Status des Programms während der sequentiellen Ausführung erhalten bleibt und von nachfolgenden Prozessen referenziert werden kann. In Bezug auf die Implementierung verfügt der Code-Ausführer in jeder Sitzung über einen unabhängigen Python-Prozess zum Ausführen des Codes und unterstützt so mehrere Benutzer gleichzeitig.
Das Speichermodul speichert hauptsächlich nützliche Informationen während des Betriebs des gesamten Systems, wie z. B. Ausführungsergebnisse usw., und kann von verschiedenen Modulen geschrieben und gelesen werden. Das Kurzzeitgedächtnis umfasst hauptsächlich Kommunikationsaufzeichnungen zwischen dem Benutzer und TaskWeaver in der aktuellen Sitzung sowie Kommunikationsaufzeichnungen zwischen Modulen. Das Langzeitgedächtnis umfasst Domänenwissen, das vom Benutzer im Voraus angepasst werden kann, sowie einige während des Interaktionsprozesses zusammengefasste Erfahrungen usw.
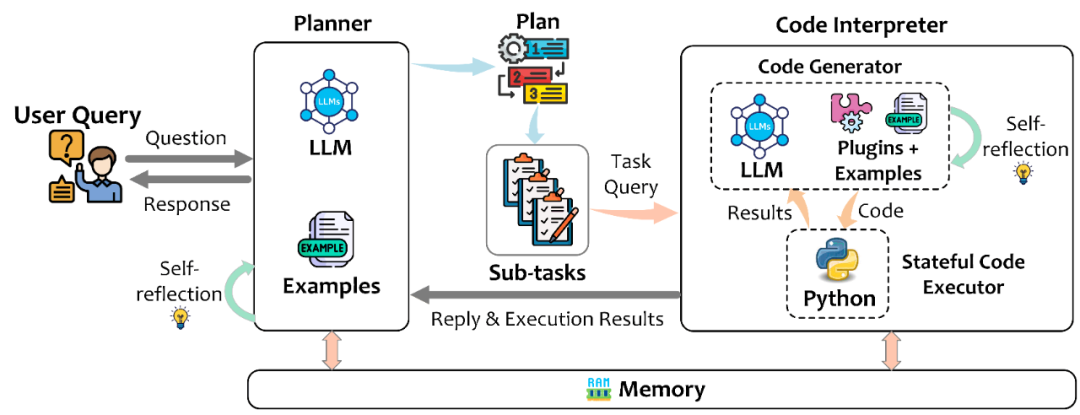
Abbildung 2. TaskWeaver-Gesamtarchitekturdiagramm
Neben der Grundarchitektur verfügt TaskWeaver auch über viele einzigartige Designs. Durch die Sitzungskomprimierung wird beispielsweise die Textgröße reduziert, was mehr Konversationsrunden ermöglicht, und die dynamische Plug-In-Auswahl wählt automatisch geeignete Plug-Ins basierend auf Benutzeranforderungen aus, was die Integration weiterer benutzerdefinierter Plug-Ins ermöglicht. Darüber hinaus unterstützt TaskWeaver auch die Funktion zum Speichern von Erfahrungen, die durch die Eingabe von Befehlen durch Benutzer während der Verwendung ausgelöst werden kann. Dadurch werden die Erfahrungen und Lektionen des Benutzers in der aktuellen Sitzung zusammengefasst, Wiederholungsfehler in der nächsten Sitzung vermieden und eine echte Personalisierung erreicht. Auch im Hinblick auf die Sicherheit ist TaskWeaver sorgfältig konzipiert. Benutzer können beispielsweise eine Whitelist von Python-Modulen angeben. Wenn der generierte Code auf Module außerhalb der Whitelist verweist, wird ein Fehler ausgelöst, wodurch Sicherheitsrisiken verringert werden.
Der spezifische Prozess von TaskWeaver
Abbildung 3 zeigt uns einen Teil des Prozesses, in dem TaskWeaver die oben genannten Beispielaufgaben erledigt.
Zunächst erhält der Planer Benutzereingaben und generiert anhand der Funktionsbeschreibungen der einzelnen Module und Planungsbeispielen konkrete Pläne. Der Plan enthält vier Teilaufgaben, von denen die erste darin besteht, Daten aus der Datenbank zu extrahieren und das Datenschema zu beschreiben.
Der Codegenerator generiert dann einen Code auf Basis seiner Funktionsbeschreibung und der Definition aller relevanten Plugins. Dieser Code ruft das Plugin sql_pull_data auf, um die Daten in einem DataFrame zu speichern und eine Beschreibung des Datenschemas bereitzustellen.
Schließlich wird der generierte Code zur Ausführung an den Code-Executor gesendet und die fertigen Ergebnisse werden an den Planer gesendet, um den Plan zu aktualisieren oder mit der nächsten Unteraufgabe fortzufahren. Die Ausführungsergebnisse in der Abbildung zeigen, dass der DataFrame zwei Spalten enthält, nämlich Datum und Wert. Der Planer kann mit dem Benutzer weiter bestätigen, ob diese Spalten korrekt sind, oder direkt mit dem nächsten Schritt des Aufrufs des Plug-Ins „anomaly_detection“ fortfahren.
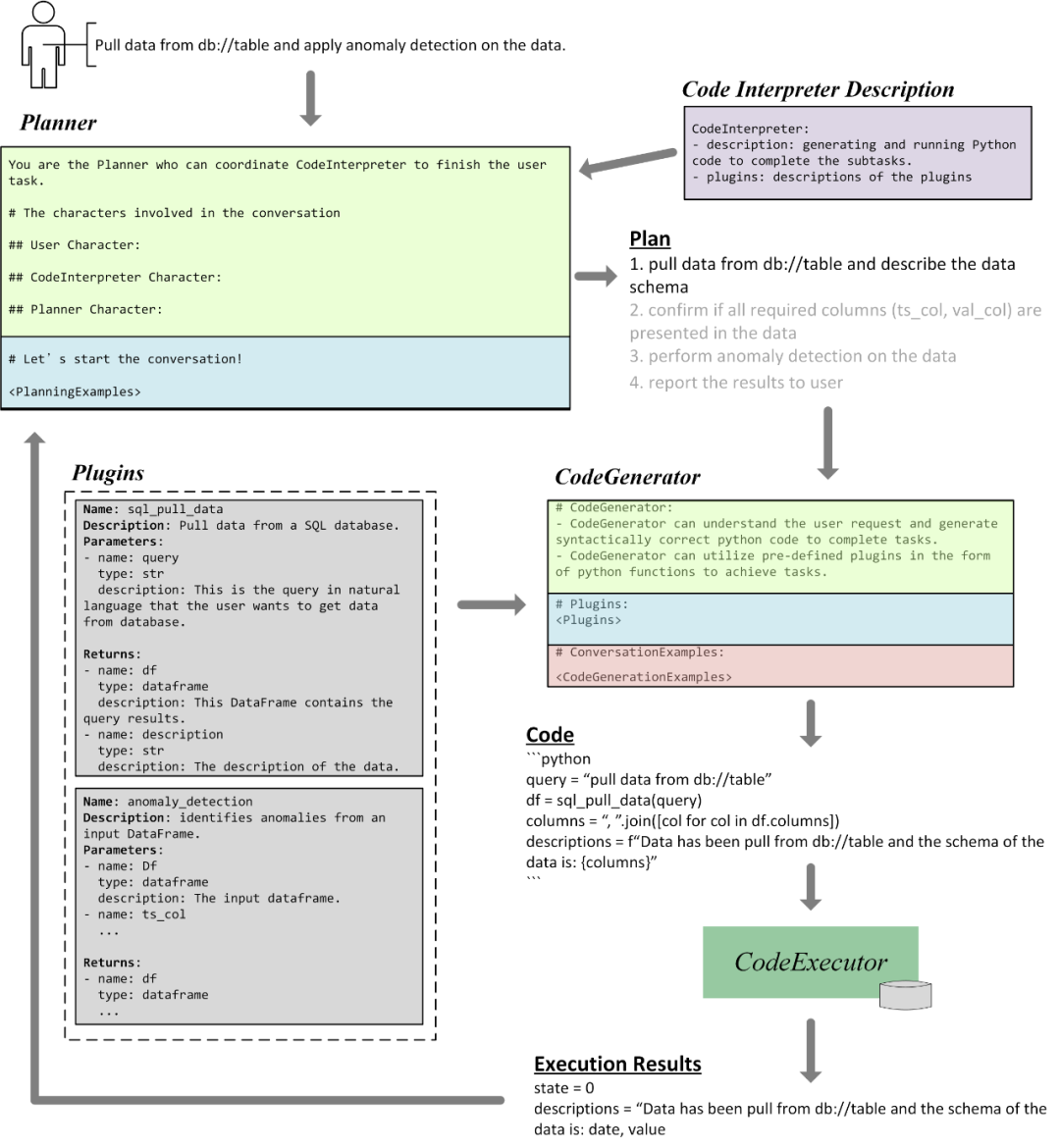
Abbildung 3. Interner TaskWeaver-Workflow
Wie fügt man Domänenwissen in TaskWeaver ein?
In großen Modellanwendungen besteht der Hauptzweck der Integration domänenspezifischen Wissens darin, die Generalisierungsleistung von LLM bei der Branchenanpassung zu verbessern. TaskWeaver bietet drei Methoden zum Einfügen von Domänenwissen in das Modell:
-
Anpassung mithilfe von Plug-Ins: Benutzer können Domänenwissen in Form von benutzerdefinierten Plug-Ins integrieren. Plug-ins können in vielen Formen vorliegen, z. B. als Aufruf einer API, zum Abrufen von Daten aus einer bestimmten Datenbank oder zum Ausführen eines bestimmten Algorithmus oder Modells für maschinelles Lernen. Die Plug-in-Anpassung ist relativ einfach. Sie müssen lediglich grundlegende Informationen über das Plug-in (einschließlich Plug-in-Name, Funktionsbeschreibung, Eingabeparameter und Rückgabewerte) und die Python-Implementierung angeben.
-
Anpassen mithilfe von Beispielen: TaskWeaver bietet Benutzern außerdem eine systematische Schnittstelle (im YAML-Format) zum Konfigurieren von Beispielen, um LLM beizubringen, wie auf Benutzeranfragen reagiert werden soll. Konkret können Beispiele in zwei Typen unterteilt werden, die für die Planung im Planer und die Codeprogrammierung im Codegenerator verwendet werden.
- Erfahrungsspeicherung: TaskWeaver unterstützt Benutzer dabei, den aktuellen Sitzungsprozess zusammenzufassen und als Langzeitgedächtnis zu speichern. Benutzer können TaskWeaver ihr Domänenwissen als Konversationen „beibringen“ und die Konversationen dann als Erfahrungen speichern. Im anschließenden Nutzungsprozess können Sie Erfahrungen dynamisch laden, um Probleme im Berufsfeld besser zu lösen.
Wie verwende ich TaskWeaver?
Der vollständige Code von TaskWeaver ist jetzt Open Source auf GitHub. Derzeit werden drei Lösungen zur Verwendung unterstützt: Befehlszeilenstart, Webdienst und Import in Form einer Python-Bibliothek. Nach einer einfachen Installation müssen Benutzer nur einige wichtige Parameter konfigurieren, wie z. B. die LLM-API-Adresse, den Schlüssel und den Modellnamen, um den TaskWeaver-Dienst einfach zu starten.
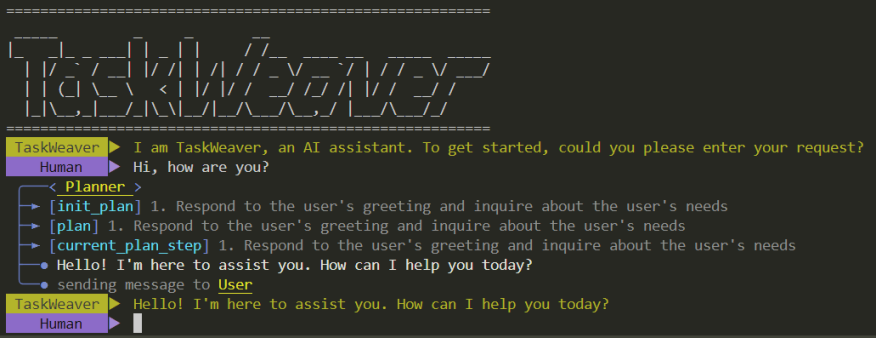
Abbildung 4. Befehlszeilen-Startoberfläche
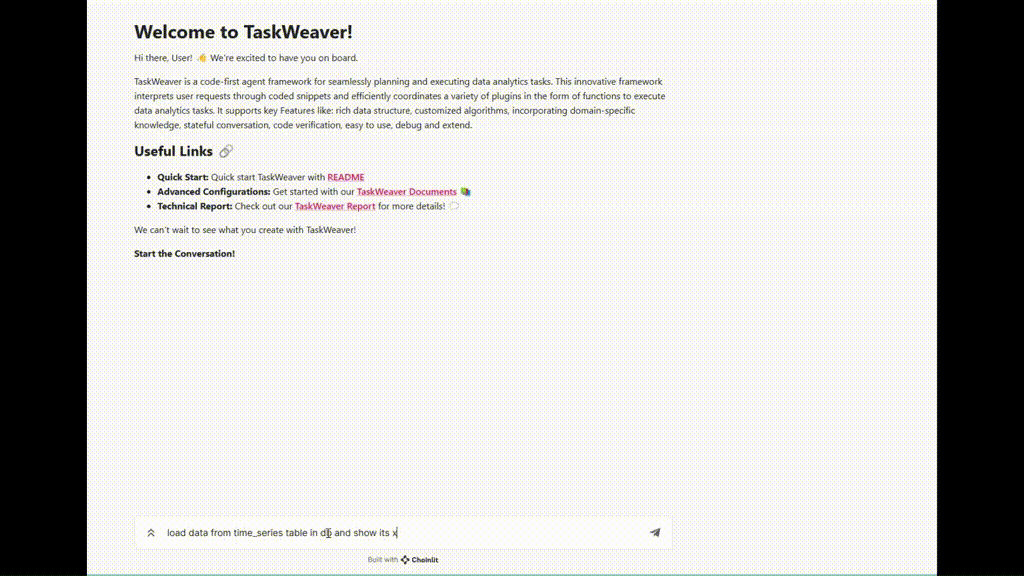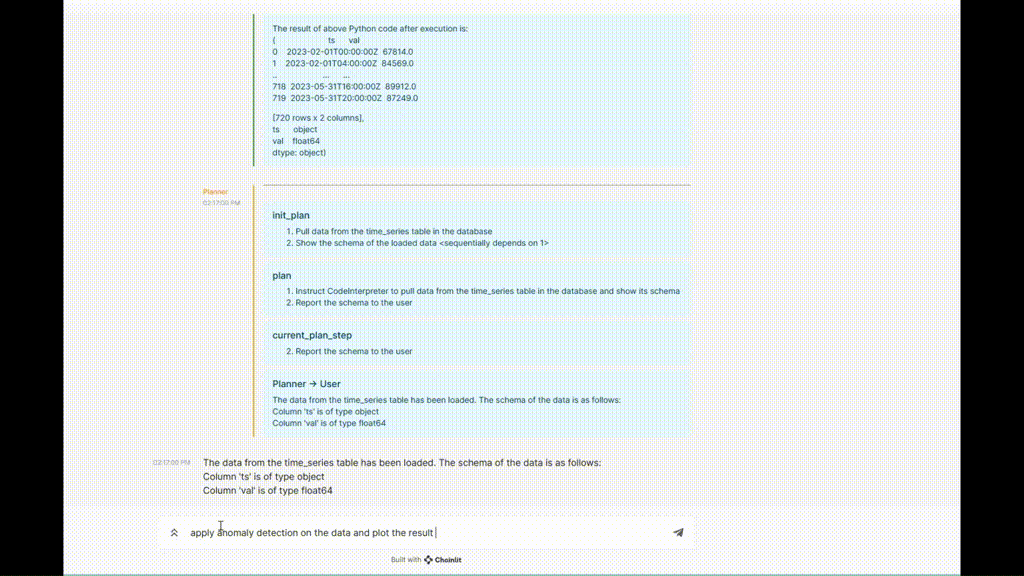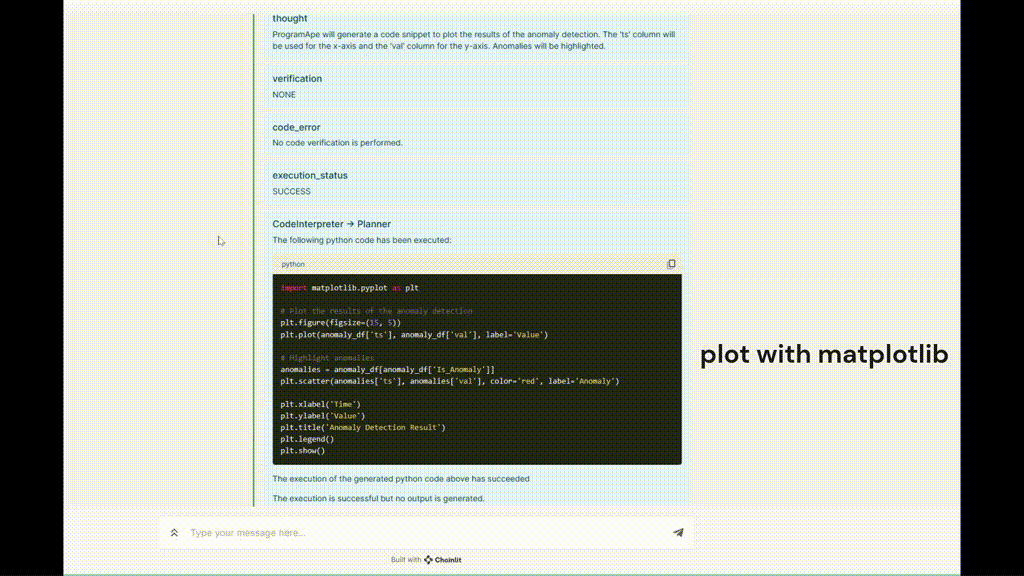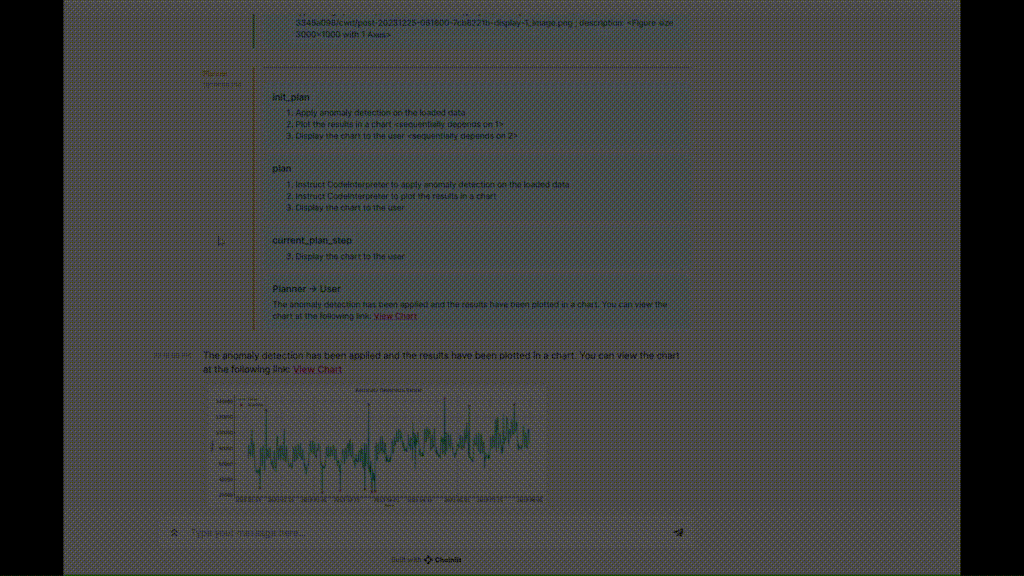
Abbildung 5. TaskWeaver-Ausführungsbeispiel
TaskWeaver ist eine neue Agent-Framework-Lösung, die speziell auf die Anforderungen von Datenanalysen und Branchenanpassungsszenarien zugeschnitten ist. Durch die Umwandlung der Benutzersprache in eine Programmiersprache wird das „Sprechen mit Daten“ kein Traum mehr, sondern Realität.
Das obige ist der detaillierte Inhalt vonTaskWeaver: ein Open-Source-Framework, das die Datenanalyse und Branchenanpassung erleichtert, um hervorragende Agent-Lösungen zu erstellen. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Was sind die Merkmale von Big Data?
- Metaforscher unternehmen einen neuen Versuch der KI: Sie bringen Robotern das physische Navigieren bei, ohne Karten oder Training
- Das Training von ViT und MAE reduziert den Rechenaufwand um die Hälfte! Sea und die Peking-Universität haben gemeinsam den effizienten Optimierer Adan vorgeschlagen, der für tiefe Modelle verwendet werden kann
- Yunshenchen und Shengteng CANN arbeiten zusammen, um ein ROS-Trainingslager für die Entwicklung vierbeiniger Roboterhunde zu eröffnen
- Zoom sorgt für Transparenz bei der Datennutzung und stellt sicher, dass das KI-Training der Zustimmung des Benutzers unterliegt