
Heim >Technologie-Peripheriegeräte >KI >Alibabas neues mPLUG-Owl-Upgrade bietet das Beste aus beiden Welten und die modale Zusammenarbeit ermöglicht MLLMs neues SOTA
Alibabas neues mPLUG-Owl-Upgrade bietet das Beste aus beiden Welten und die modale Zusammenarbeit ermöglicht MLLMs neues SOTA

- 王林nach vorne
- 2024-01-11 18:33:09747Durchsuche
Sowohl
OpenAI GPT-4V als auch Google Gemini haben sehr starke multimodale Verständnisfähigkeiten bewiesen und die schnelle Entwicklung multimodaler großer Modelle (MLLM) gefördert, die sich zur heißesten Forschungsrichtung in der Branche entwickelt haben.
MLLM hat in einer Vielzahl visuell-linguistischer offener Aufgaben eine hervorragende Fähigkeit zur Befolgung von Anweisungen erreicht. Obwohl frühere Untersuchungen zum multimodalen Lernen gezeigt haben, dass verschiedene Modalitäten zusammenarbeiten und sich gegenseitig fördern können, bleibt die bestehende MLLM-Forschung hauptsächlich auf die Verbesserung der Fähigkeit multimodaler Aufgaben und die Frage, wie die Vorteile der modalen Zusammenarbeit und die Auswirkungen modaler Interferenzen in Einklang gebracht werden können das muss angegangen werden.

Bitte klicken Sie auf den folgenden Link, um das Papier anzuzeigen: https://arxiv.org/pdf/2311.04257.pdf
Bitte sehen Sie sich die folgende Codeadresse an: https://github.com/X -PLUG/mPLUG -Owl/tree/main/mPLUG-Owl2
ModelScope-Erlebnisadresse: https://modelscope.cn/studios/damo/mPLUG-Owl2/summary
HuggingFace-Erlebnisadressenlink: https: //huggingface.co/spaces/MAGAer13/mPLUG-Owl2
Als Reaktion auf dieses Problem hat Alibabas multimodales Großmodell mPLUG-Owl ein großes Upgrade erhalten. Durch modale Zusammenarbeit verbessert es gleichzeitig die Leistung von Klartext und Multimodalität, übertrifft LLaVA1.5, MiniGPT4, Qwen-VL und andere Modelle und erzielt die beste Leistung bei einer Vielzahl von Aufgaben. Insbesondere nutzt mPLUG-Owl2 gemeinsame Funktionsmodule, um die Zusammenarbeit zwischen verschiedenen Modalitäten zu fördern, und führt ein Modalanpassungsmodul ein, um die Eigenschaften jeder Modalität beizubehalten. Mit einem einfachen und effektiven Design erreicht mPLUG-Owl2 die beste Leistung in mehreren Bereichen, einschließlich Klartext und multimodalen Aufgaben. Die Untersuchung modaler Kooperationsphänomene liefert auch Inspiration für die Entwicklung zukünftiger multimodaler Großmodelle
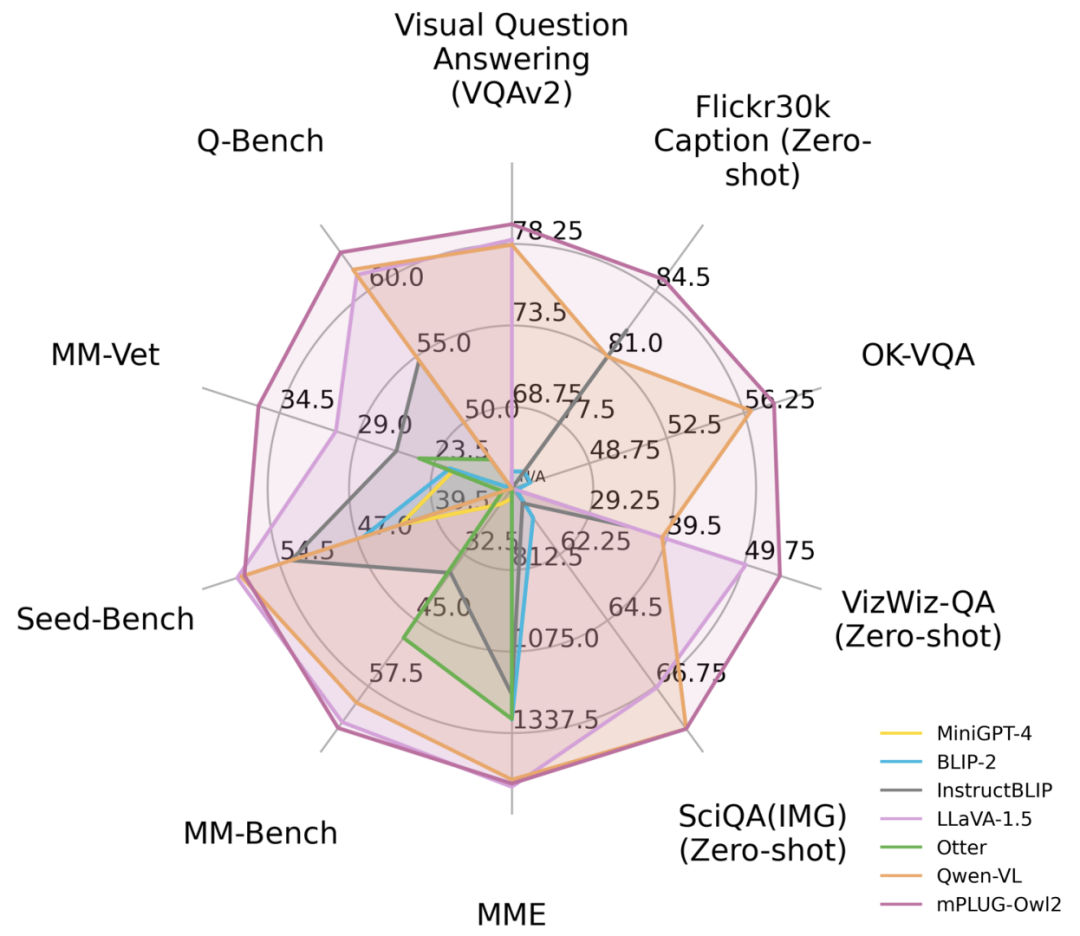
Abbildung 1 Leistungsvergleich mit bestehenden MLLM-Modellen
Methodeneinführung Um den Zweck zu erreichen, die ursprüngliche Bedeutung nicht zu ändern, muss der Inhalt ins Chinesische umgeschrieben werden.
Das mPLUG-Owl2-Modell besteht hauptsächlich aus drei Teilen:
Visual Encoder: Verwendung von ViT-L/14 als Visual Encoder, die Eingabeauflösung. Ein Bild mit einer Rate von H x B wird in eine Folge visueller Token von H/14 x B/14 umgewandelt und in Visual Abstractor eingegeben.
Visueller Extraktor: Extrahiert semantische Merkmale auf hoher Ebene durch Erlernen einer Reihe verfügbarer Abfragen und reduziert gleichzeitig die visuelle Sequenzlänge des Eingabesprachmodells.
Sprachmodell: LLaMA-2-7B wird als Textdecoder verwendet. und entwarf das modale Anpassungsmodul wie in Abbildung 3 dargestellt.
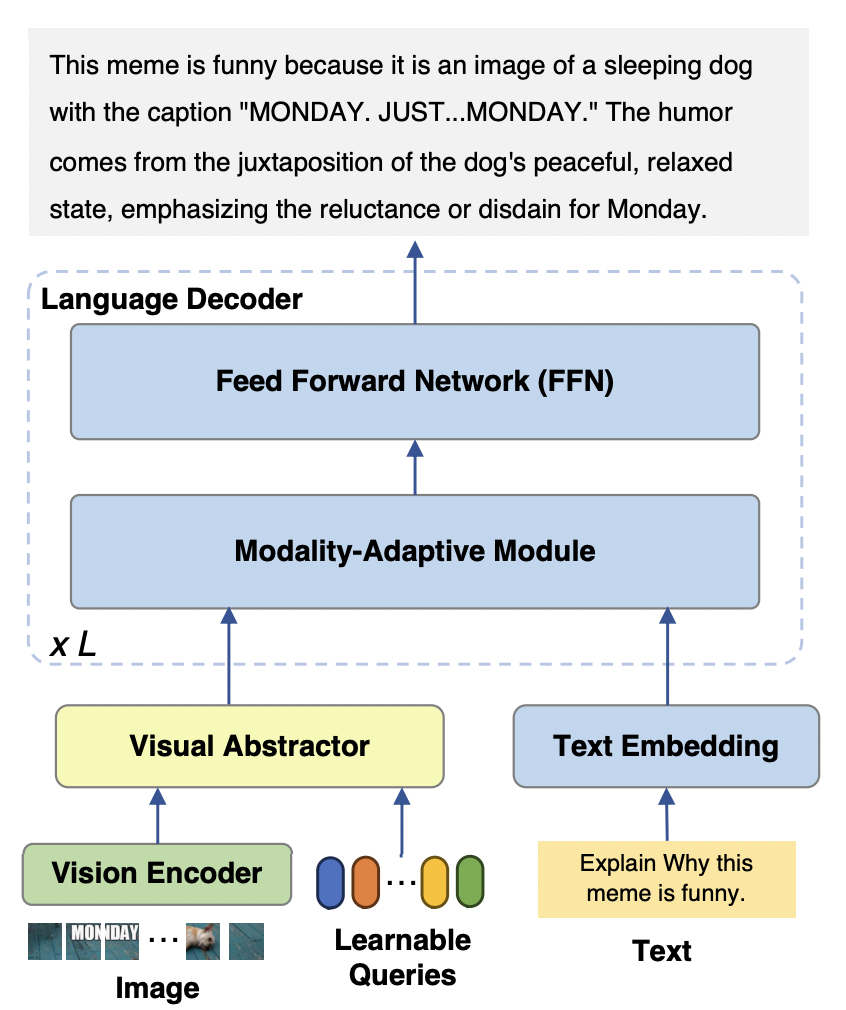
Abbildung 2 mPLUG-Owl2-Modellstruktur
Um visuelle und sprachliche Modalitäten in Einklang zu bringen, bilden bestehende Arbeiten normalerweise visuelle Merkmale in den semantischen Raum von Text ab von visuellen und Textinformationen kann aufgrund der Nichtübereinstimmung der semantischen Granularität die Leistung des Modells beeinträchtigen. Um dieses Problem zu lösen, schlägt dieser Artikel ein modalitätsadaptives Modul (MAM) vor, um visuelle und textuelle Merkmale in einem gemeinsamen semantischen Raum abzubilden und gleichzeitig visuell-sprachliche Darstellungen zu entkoppeln, um die einzigartigen Eigenschaften jeder Modalität beizubehalten.
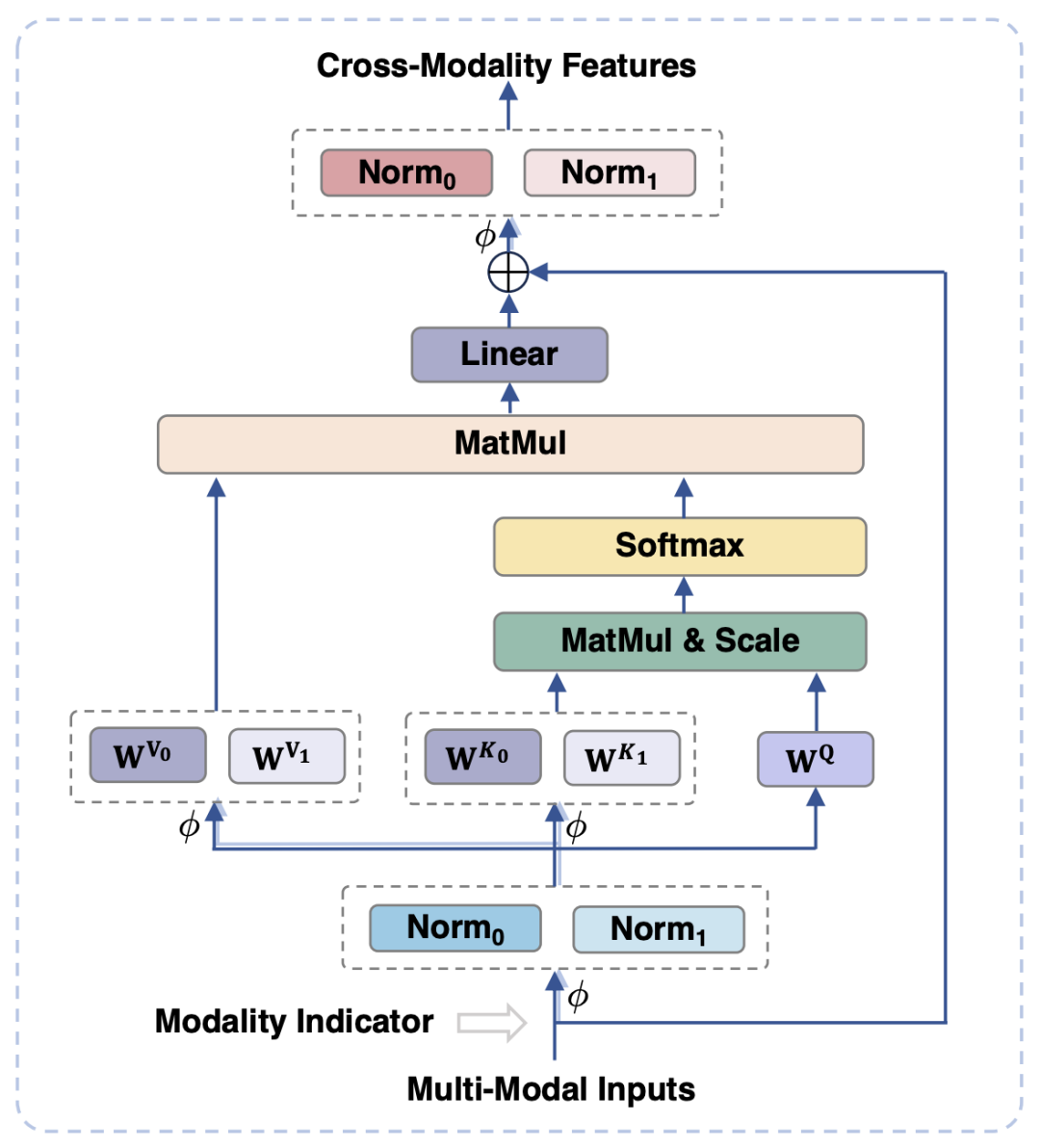
Abbildung 3 zeigt das schematische Diagramm des Modalanpassungsmoduls
Was in Abbildung 3 gezeigt wird, ist, dass im Vergleich zum herkömmlichen Transformer das Hauptdesign des Modalanpassungsmoduls wie folgt aussieht:
-
In der Eingabe- und Ausgabephase des Moduls werden LayerNorm-Operationen an den visuellen bzw. sprachlichen Modalitäten durchgeführt, um sich an die jeweiligen Merkmalsverteilungen der beiden Modalitäten anzupassen.
Bei der Selbstaufmerksamkeitsoperation werden separate Schlüssel- und Wertprojektionsmatrizen für visuelle und sprachliche Modalitäten verwendet, aber durch die Entkopplung der Schlüssel- und Wertprojektionsmatrizen auf diese Weise kommt es zu Nichtübereinstimmungen Semantische Granularität kann erreicht werden, wodurch Interferenzen zwischen den beiden Modi vermieden werden.
Durch die gemeinsame Nutzung des gleichen FFN können die beiden Modalitäten die Zusammenarbeit untereinander fördern
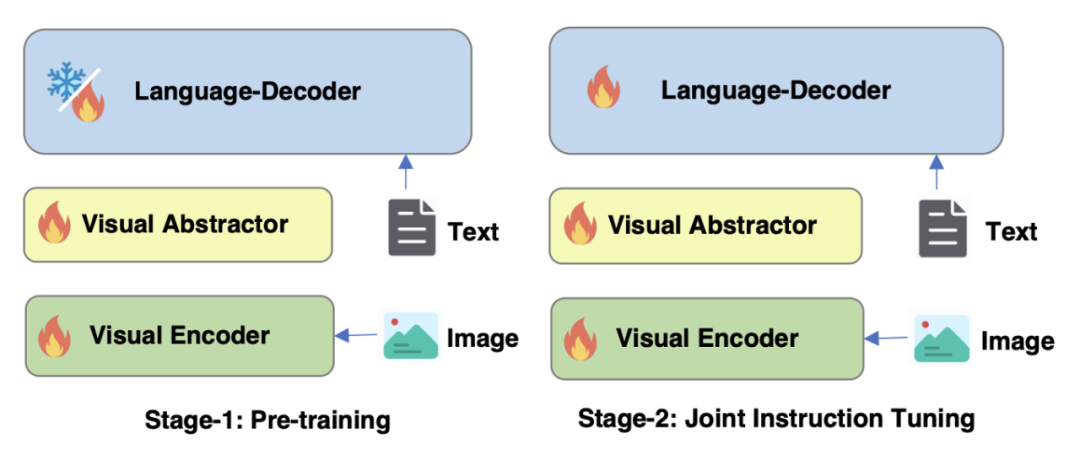
Optimierung der Trainingsstrategie von Figure 4 mPLUG-Owl2
Wie in Abbildung 4 dargestellt, umfasst das Training von mPLUG-Owl2 zwei Phasen: Vortraining und Feinabstimmung der Anweisungen. Die Vortrainingsphase dient hauptsächlich dazu, die Ausrichtung des visuellen Encoders und des Sprachmodells zu erreichen. In dieser Phase sind der visuelle Encoder und der visuelle Abstraktor trainierbar, und im Sprachmodell werden nur die durch die Modalität hinzugefügten visuellen Modellgewichte hinzugefügt Adaptive Module werden erneuert. In der Phase der Feinabstimmung der Anweisung werden alle Parameter des Modells auf der Grundlage von Text und multimodalen Anweisungsdaten (wie in Abbildung 5 dargestellt) feinabgestimmt, um die Fähigkeit des Modells zur Anweisungsbefolgung zu verbessern.
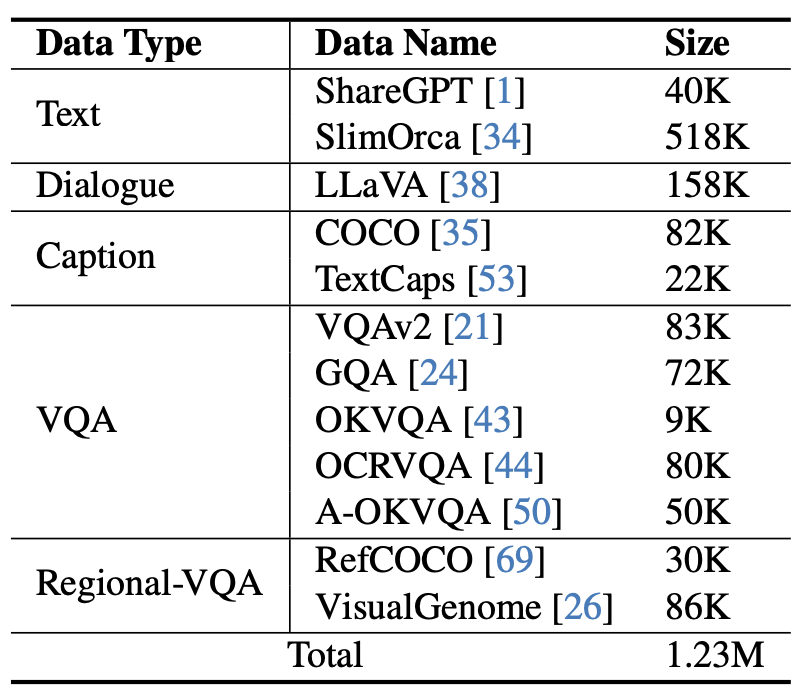
Abbildung 5: Anweisungs-Feinabstimmungsdaten, die von mPLUG-Owl2 verwendet werden.
Experimente und Ergebnisse
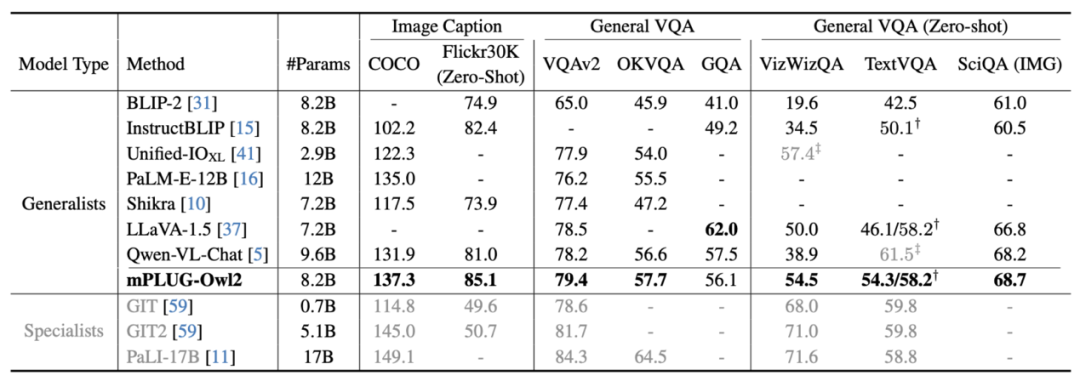
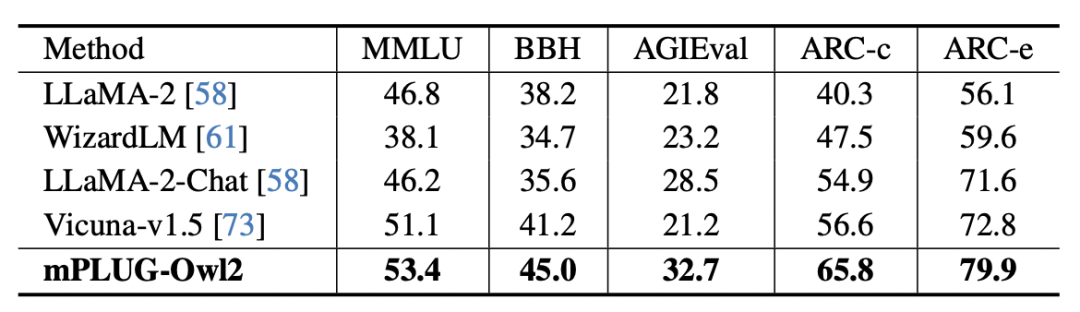
Bild 7 Die MLLM-Benchmark-Leistung ist in Abbildung 6 und Abbildung 7 dargestellt, unabhängig davon, ob es sich um traditionelle Bildbeschreibung, VQA und andere visuelle Sprachaufgaben oder MMBench, Q-Bench und andere Benchmark-Datensätze für multimodale große Daten handelt Die Modelle mPLUG-Owl2 erzielen alle eine bessere Leistung als bestehende Arbeiten. Abbildung 8: Benchmark-Leistung für reinen Text auf reine Textaufgaben Im Hinblick auf die Auswirkungen von Textaufgaben testeten die Autoren auch die Leistung von mPLUG-Owl2 beim Verständnis und der Erzeugung natürlicher Sprache. Wie in Abbildung 8 dargestellt, erzielt mPLUG-Owl2 eine bessere Leistung im Vergleich zu anderen LLMs mit fein abgestimmten Anweisungen. Abbildung 9 zeigt die Leistung bei der Klartextaufgabe. Es ist ersichtlich, dass die Untersuchungs- und Wissensfähigkeiten des Modells erheblich verbessert wurden, da das Modalanpassungsmodul die modale Zusammenarbeit fördert. Der Autor analysiert, dass dies darauf zurückzuführen ist, dass die multimodale Zusammenarbeit es dem Modell ermöglicht, visuelle Informationen zu verwenden, um Konzepte zu verstehen, die in der Sprache schwer zu beschreiben sind, und die Argumentationsfähigkeit des Modells durch die reichhaltigen Informationen im Bild verbessert und indirekt die Argumentationsfähigkeit von stärkt der Text. 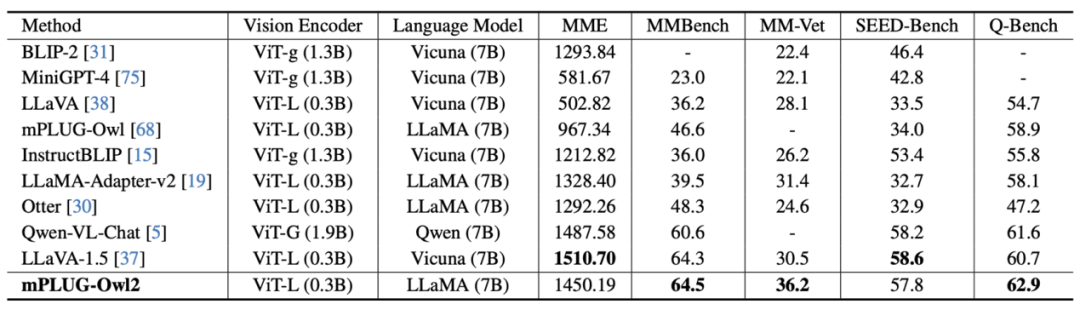
mPLUG-Owl2 zeigt hervorragende multimodale Verständnisfähigkeiten und lindert erfolgreich multimodale Halluzinationen. Diese multimodale Technologie wurde auf Kernprodukte von Tongyi wie Tongyi Stardust und Tongyi Zhiwen angewendet und in der offenen Demo von ModelScope und HuggingFace verifiziert
Das obige ist der detaillierte Inhalt vonAlibabas neues mPLUG-Owl-Upgrade bietet das Beste aus beiden Welten und die modale Zusammenarbeit ermöglicht MLLMs neues SOTA. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Stärken Sie die Modebranche mit Technologie und unterstützen Sie den Bezirk Futian beim Aufbau eines „Bay Area Fashion Headquarters Center'.
- Web3 und KI konzentrieren sich auf Veränderung und Beständigkeit und gestalten den Gipfeldialog der Filmindustrie neu
- Xiaoyu Yilian trat auf der China International Intelligent Industry Expo auf
- Zhipu AI arbeitete mit Tsinghua KEG zusammen, um ein multimodales Open-Source-Großmodell namens CogVLM-17B zu veröffentlichen
- Wie können kollaborative Roboter die intelligente Fertigung und Modernisierung der täglichen chemischen Industrie unterstützen? Hören Sie, was die Experten sagen