
Heim >Technologie-Peripheriegeräte >KI >Zhipu AI arbeitete mit Tsinghua KEG zusammen, um ein multimodales Open-Source-Großmodell namens CogVLM-17B zu veröffentlichen
Zhipu AI arbeitete mit Tsinghua KEG zusammen, um ein multimodales Open-Source-Großmodell namens CogVLM-17B zu veröffentlichen

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBnach vorne
- 2023-10-12 11:41:011499Durchsuche
Builder News Am 12. Oktober haben Zhipu AI & Tsinghua KEG kürzlich das multimodale große Modell CogVLM-17B veröffentlicht und direkt als Open Source in der Moda-Community bereitgestellt. Es wird berichtet, dass CogVLM ein leistungsstarkes visuelles Open-Source-Sprachmodell ist, das das visuelle Expertenmodul verwendet, um Sprachcodierung und visuelle Codierung tief zu integrieren, und bei 14 maßgeblichen modalübergreifenden Benchmarks SOTA-Leistung erreicht hat.
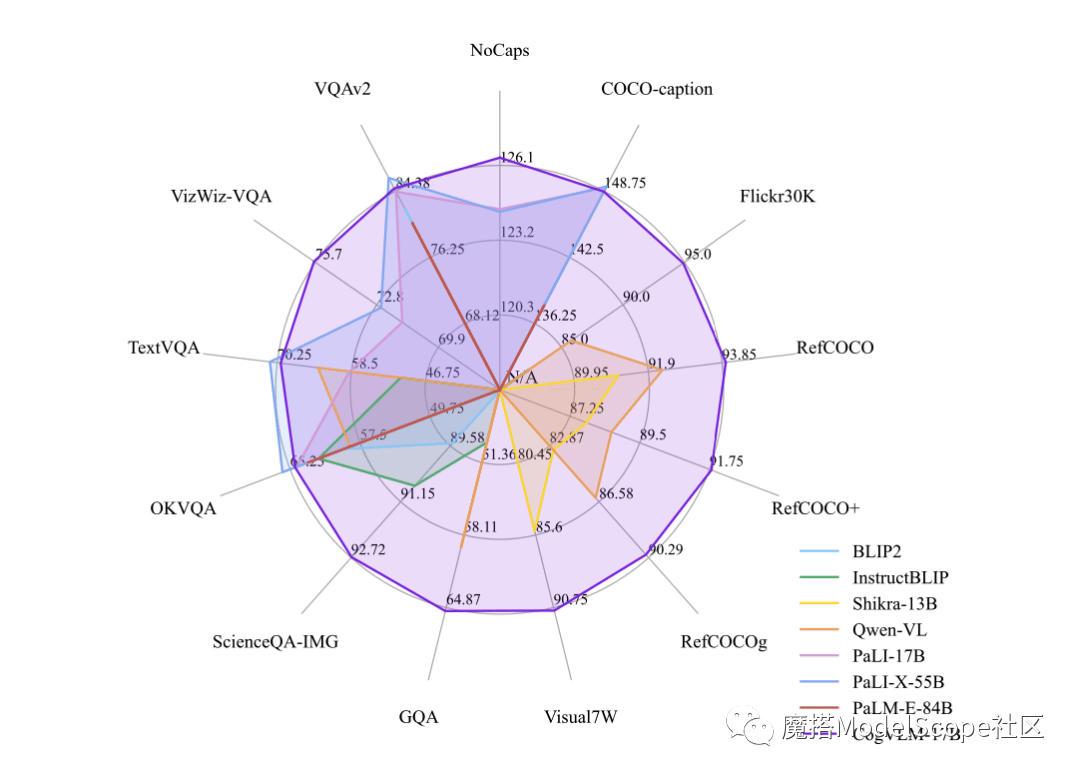
CogVLM-17B ist derzeit das Modell mit der ersten umfassenden Leistung auf der multimodalen, maßgeblichen akademischen Liste und hat bei 14 Datensätzen die fortschrittlichsten oder zweitplatzierten Ergebnisse erzielt. Die Wirkung von CogVLM beruht auf der Idee der „visuellen Priorität“, das heißt, dem visuellen Verständnis in multimodalen Modellen eine höhere Priorität einzuräumen. Es verwendet einen visuellen Encoder mit 5B Parametern und ein visuelles Expertenmodul mit 6B Parametern, mit insgesamt 11B Parametern zur Modellierung von Bildmerkmalen, sogar mehr als die 7B Parameter von Text
Das obige ist der detaillierte Inhalt vonZhipu AI arbeitete mit Tsinghua KEG zusammen, um ein multimodales Open-Source-Großmodell namens CogVLM-17B zu veröffentlichen. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- 360 hat eine strategische Zusammenarbeit mit Zhipu AI geschlossen, um gemeinsam das große Sprachmodell 360GLM zu entwickeln
- 360 und Zhipu AI gaben eine strategische Zusammenarbeit bekannt, um gemeinsam ein 100-Milliarden-Ebenen-Großsprachenmodell „360GLM' zu entwickeln.
- Die erste inländische Nachbildung des ChatGPT-F&E-Modells, 360 und Zhipu AIs strategisches Kooperationsmodell für große Sprachen
- 360 wird das 100-Milliarden-Ebenen-Großsprachenmodell 360GLM auf den Markt bringen und strategisch mit Zhipu AI zusammenarbeiten
- Gastvorstellung zum Sohu Technology Summit 2023 |. Zhang Fan: Zhipu AI COO