
Heim >Technologie-Peripheriegeräte >KI >Google Deepmind stellt sich eine Zukunft vor, die Roboter neu erfindet und verkörperte Intelligenz in große Modelle bringt
Google Deepmind stellt sich eine Zukunft vor, die Roboter neu erfindet und verkörperte Intelligenz in große Modelle bringt

- PHPznach vorne
- 2024-01-09 19:49:59891Durchsuche
Im vergangenen Jahr haben sukzessive Großmodelle Durchbrüche erzielt, die den Bereich der Robotikforschung neu gestalten.
Da die fortschrittlichsten großen Modelle zum „Gehirn“ von Robotern werden, entwickeln sich Roboter schneller als gedacht.
Im Juli kündigte Google DeepMind die Einführung von RT-2 an: das weltweit erste Vision-Language-Action (VLA)-Modell zur Steuerung von Robotern.
Sie müssen nur einen Befehl wie eine Konversation geben, und schon kann Swift anhand einer Reihe von Bildern identifiziert und ihr ein Glas „Fröhliches Wasser“ gegeben werden.

Open new ideas ins Leben gerufen. Stellen Sie sich vor, Sie geben Ihrem Roboterassistenten einfach eine einfache Aufforderung, wie zum Beispiel „Räum das Haus auf“ oder „koche eine köstliche und gesunde Mahlzeit“, und er kann diese Aufgaben erledigen. Für Menschen mögen diese Aufgaben einfach sein, aber für Roboter erfordern sie ein tiefes Verständnis der Welt, was nicht einfach ist.
Basierend auf jahrelanger Forschung im Bereich Robotertransformatoren hat Google kürzlich eine Reihe von Forschungsfortschritten bei Robotern angekündigt: AutoRT, SARA-RT und RT-Trajectory, die Robotern helfen können, Entscheidungen schneller zu treffen und sie besser zu verstehen, welche Art von Umgebung Sie haben Die angezeigten Informationen können Sie bei der Erledigung der Aufgabe besser unterstützen.
Google ist davon überzeugt, dass die Einführung von Forschungsergebnissen wie AutoRT, SARA-RT und RT-Trajectory zu Verbesserungen bei der Datenerfassung, Geschwindigkeit und Generalisierungsfähigkeiten realer Roboter führen kann.
Als nächstes schauen wir uns diese wichtigen Studien an.
AutoRT: Nutzen Sie große Modelle, um Roboter besser zu trainieren.AutoRT kombiniert große Basismodelle (z. B. große Sprachmodelle (LLM) oder visuelle Sprachmodelle (VLM)) und Robotersteuerungsmodelle (RT-1 oder RT-2). , wodurch ein System geschaffen wird, das Roboter in neuen Umgebungen einsetzen kann, um Trainingsdaten zu sammeln. AutoRT kann mehrere mit Videokameras und Endeffektoren ausgestattete Roboter gleichzeitig steuern, um verschiedene Aufgaben in verschiedenen Umgebungen auszuführen.
Konkret verwendet jeder Roboter ein visuelles Sprachmodell (VLM), um sich umzuschauen und seine Umgebung und Objekte innerhalb seiner Sichtlinie zu verstehen, basierend auf AutoRT. Als nächstes schlägt das große Sprachmodell ihm eine Reihe kreativer Aufgaben vor, wie zum Beispiel „Snacks auf den Tisch legen“, und übernimmt die Rolle des Entscheidungsträgers, indem er die Aufgaben auswählt, die der Roboter ausführen soll.
Forscher führten eine umfassende siebenmonatige Evaluierung von AutoRT in der realen Welt durch. Experimente haben gezeigt, dass das AutoRT-System bis zu 20 Roboter gleichzeitig und maximal 52 Roboter insgesamt sicher koordinieren kann. Indem die Forscher die Roboter dazu anleiteten, verschiedene Aufgaben in verschiedenen Bürogebäuden auszuführen, sammelten die Forscher einen vielfältigen Datensatz aus 77.000 Roboterversuchen mit 6.650 einzigartigen Aufgaben.
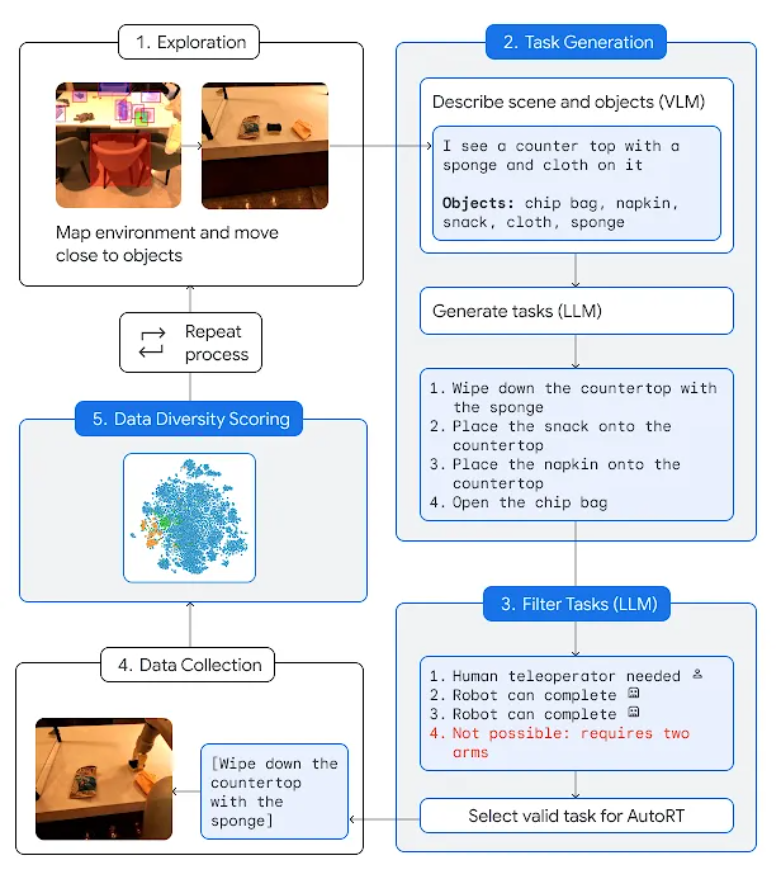 Das obige Bild zeigt den Betriebsprozess des AutoRT-Systems: (1) Der autonome Radroboter findet einen Ort mit mehreren Objekten. (2) VLM beschreibt Szenen und Objekte für LLM. (3) LLM schlägt verschiedene Betriebsaufgaben für den Roboter vor und entscheidet, welche Aufgaben der Roboter selbstständig erledigen kann, welche Aufgaben eine menschliche Fernsteuerung erfordern und welche Aufgaben nicht erledigt werden können, und trifft dann eine Auswahl. (4) Der Roboter versucht, die zu erledigenden Aufgaben auszuwählen, sammelt experimentelle Daten und bewertet die Vielfalt und Aktualität der Daten. Der Roboter wird diesen Vorgang immer wieder wiederholen.
Das obige Bild zeigt den Betriebsprozess des AutoRT-Systems: (1) Der autonome Radroboter findet einen Ort mit mehreren Objekten. (2) VLM beschreibt Szenen und Objekte für LLM. (3) LLM schlägt verschiedene Betriebsaufgaben für den Roboter vor und entscheidet, welche Aufgaben der Roboter selbstständig erledigen kann, welche Aufgaben eine menschliche Fernsteuerung erfordern und welche Aufgaben nicht erledigt werden können, und trifft dann eine Auswahl. (4) Der Roboter versucht, die zu erledigenden Aufgaben auszuwählen, sammelt experimentelle Daten und bewertet die Vielfalt und Aktualität der Daten. Der Roboter wird diesen Vorgang immer wieder wiederholen.
AutoRT hat das Potenzial, große Basismodelle zu nutzen, was für Roboter von entscheidender Bedeutung ist, um menschliche Anweisungen in realen Anwendungen zu verstehen. Durch die Erfassung umfassenderer experimenteller Trainingsdaten und vielfältigerer Daten kann AutoRT die Lernfähigkeiten von Robotern erweitern und das Robotertraining in der Praxis verbessern.
Bevor Roboter in unser tägliches Leben integriert werden können, muss ihre Sicherheit gewährleistet werden, was von den Forschern eine verantwortungsvolle Entwicklung und eingehende Forschung zur Sicherheit von Robotern erfordert.
Während AutoRT derzeit nur ein Datenerfassungssystem ist, können Sie es sich als die frühen Stadien autonomer Roboter in der realen Welt vorstellen. Es verfügt über Sicherheitsleitplanken, darunter eine Reihe sicherheitsorientierter Aufforderungswörter, die Grundregeln festlegen, die befolgt werden müssen, wenn der Roboter LLM-basierte Entscheidungen trifft.
Diese Regeln sind teilweise von Isaac Asimovs Drei Gesetzen der Robotik inspiriert, von denen das wichtigste ist, dass ein Roboter „einem Menschen keinen Schaden zufügen darf“. Sicherheitsvorschriften verlangen außerdem, dass Roboter keine Aufgaben ausführen dürfen, an denen Menschen, Tiere, scharfe Gegenstände oder Elektrogeräte beteiligt sind.
Allein die Arbeit an den Aufforderungswörtern kann die Sicherheitsprobleme bei der tatsächlichen Anwendung des Roboters nicht vollständig garantieren. Daher umfasst das AutoRT-System auch eine Ebene praktischer Sicherheitsmaßnahmen, die ein klassisches Design der Robotik darstellt. Beispielsweise sind kollaborative Roboter so programmiert, dass sie automatisch anhalten, wenn die Kräfte auf ihre Gelenke einen bestimmten Schwellenwert überschreiten, und alle autonom gesteuerten Roboter können über einen physischen Deaktivierungsschalter auf die Sichtlinie eines menschlichen Vorgesetzten beschränkt werden.
SARA-RT: Machen Sie den Roboter Transformer (RT) schneller und schlanker
Eine weitere Errungenschaft, SARA-RT, kann das Robotermodell Transformer (RT) in eine effizientere Version umwandeln.
Die vom Google-Team entwickelte RT-Neuronale Netzwerkarchitektur wurde in den neuesten Robotersteuerungssystemen verwendet, einschließlich des RT-2-Modells. Das beste SARA-RT-2-Modell ist 10,6 % genauer und 14 % schneller als das RT-2-Modell, wenn ein kurzer Bildverlauf berücksichtigt wird. Laut Google handelt es sich um den ersten skalierbaren Aufmerksamkeitsmechanismus, der die Rechenleistung erhöht, ohne die Qualität zu beeinträchtigen.
Transformer sind zwar leistungsstark, können jedoch durch Rechenanforderungen eingeschränkt werden, was die Entscheidungsfindung verlangsamt. Transformer basiert hauptsächlich auf dem Aufmerksamkeitsmodul quadratischer Komplexität. Dies bedeutet, dass sich die für die Verarbeitung dieser Eingaben erforderlichen Rechenressourcen vervierfachen, wenn die Eingaben in das RT-Modell verdoppelt werden (z. B. indem der Roboter mit mehr oder höher auflösenden Sensoren ausgestattet wird), was zu einer langsameren Entscheidungsfindung führt.
SARA-RT wendet eine neuartige Methode zur Modellfeinabstimmung („Up-Training“ genannt) an, um die Effizienz des Modells zu verbessern. Uptraining wandelt quadratische Komplexität in rein lineare Komplexität um und reduziert so den Rechenaufwand erheblich. Dieser Umbau verbessert nicht nur die Geschwindigkeit des Originalmodells, sondern behält auch dessen Qualität bei.
Google hofft, dass viele Forscher und Praktiker dieses praktische System auf die Robotik und andere Bereiche anwenden werden. Da SARA eine allgemeine Methode zur Beschleunigung von Transformern bereitstellt, ohne dass ein rechenintensives Vortraining erforderlich ist, hat dieser Ansatz das Potenzial, die Transformer-Technologie im großen Maßstab zu skalieren. SARA-RT erfordert keine zusätzliche Codierung, da verschiedene lineare Open-Source-Varianten verfügbar sind.
Wenn SARA-RT auf das SOTA RT-2-Modell mit Milliarden von Parametern angewendet wird, ermöglicht es eine schnellere Entscheidungsfindung und eine bessere Leistung bei einer Vielzahl von Roboteraufgaben:

für die Manipulation von SARA-RT-2 Modell der Mission. Die Aktionen des Roboters basieren auf Bildern und Textanweisungen.
Mit seiner soliden theoretischen Grundlage kann SARA-RT auf verschiedene Transformer-Modelle angewendet werden. Beispielsweise kann die Anwendung von SARA-RT auf den Point Cloud Transformer, der räumliche Daten von der Tiefenkamera eines Roboters verarbeitet, die Geschwindigkeit mehr als verdoppeln.
RT-Trajectory: Robotern bei der Verallgemeinerung helfen
Menschen können intuitiv verstehen und lernen, wie man Tische reinigt, aber Roboter benötigen viele Möglichkeiten, Anweisungen in tatsächliche physische Aktionen umzusetzen.
Traditionell basiert das Training von Roboterarmen auf der Abbildung abstrakter natürlicher Sprache (den Tisch abwischen) auf konkrete Aktionen (Greifer schließen, nach links bewegen, nach rechts bewegen), was es schwierig macht, das Modell auf neue Aufgaben zu übertragen. Im Gegensatz dazu ermöglicht das RT-Trajectory-Modell dem RT-Modell, zu verstehen, „wie“ eine Aufgabe erledigt wird, indem bestimmte Roboteraktionen (z. B. die in einem Video oder einer Skizze) interpretiert werden. Das
RT-Trajectory-Modell kann automatisch visuelle Umrisse hinzufügen, um Roboterbewegungen in Trainingsvideos zu beschreiben. RT-Trajectory überlagert jedes Video im Trainingsdatensatz mit einer 2D-Trajektorienskizze des Greifers, während der Roboterarm eine Aufgabe ausführt. Diese Trajektorien in Form von RGB-Bildern liefern einfache, praktische visuelle Hinweise für das Modell, um Robotersteuerungsstrategien zu erlernen.
Bei Tests an 41 Aufgaben, die in den Trainingsdaten nicht enthalten waren, verdoppelte der von RT-Trajectory gesteuerte Roboterarm die Leistung des bestehenden SOTA-RT-Modells mehr als: Die Aufgabenerfolgsquote erreichte 63 %, während RT-2 eine Erfolgsquote aufweist von nur 29 %.
Das System ist sehr vielseitig, RT-Trajectory kann auch Flugbahnen erstellen, indem es menschliche Demonstrationen der erforderlichen Aufgaben beobachtet, und akzeptiert sogar handgezeichnete Skizzen. Darüber hinaus ist eine Anpassung an unterschiedliche Roboterplattformen jederzeit möglich.
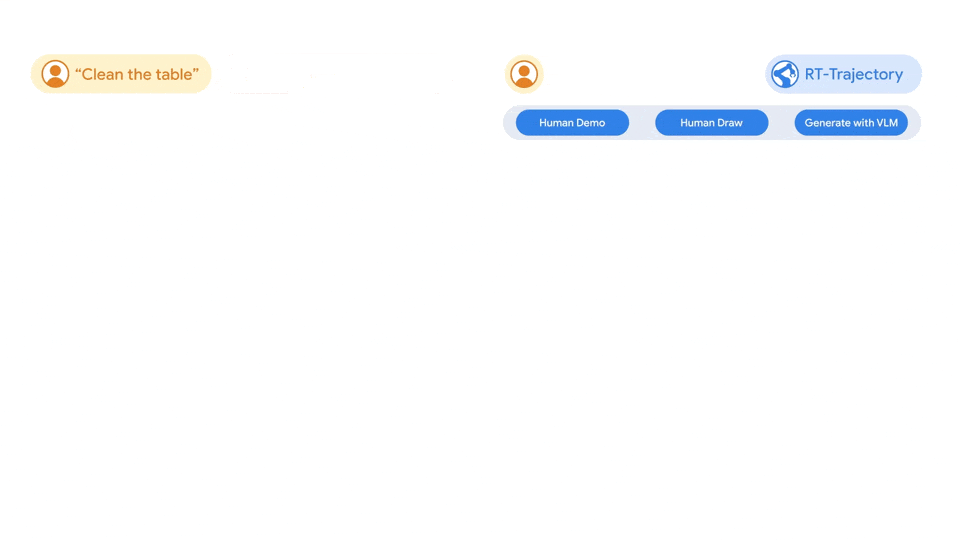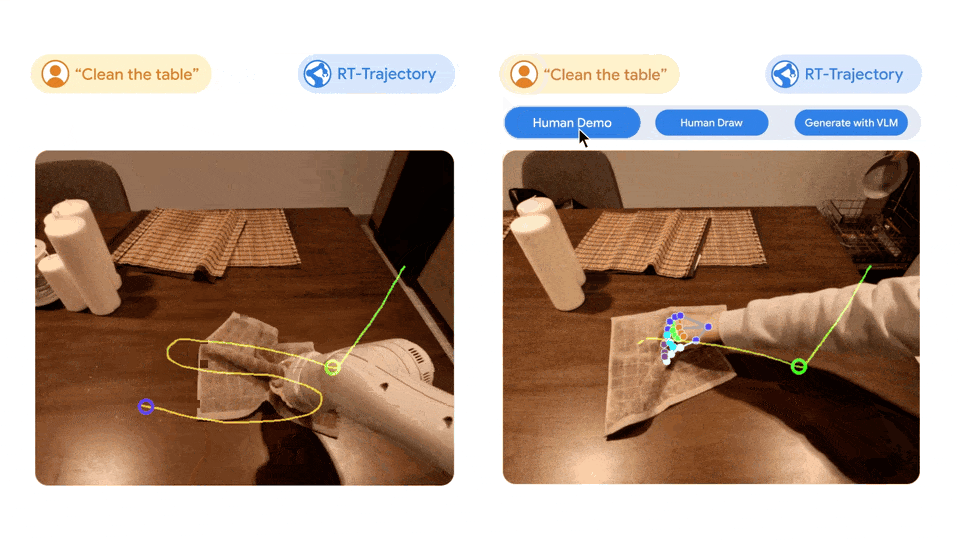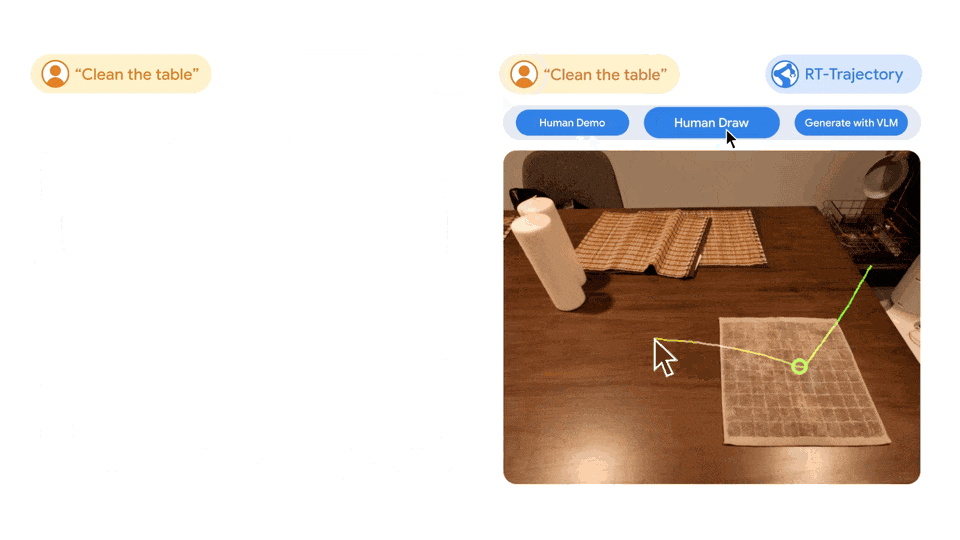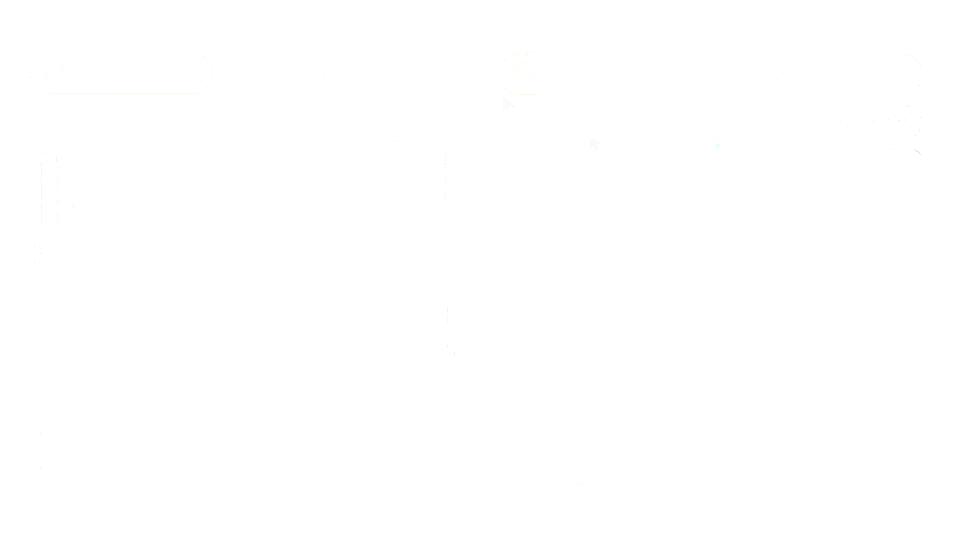 Linkes Bild: Der vom RT-Modell gesteuerte Roboter, der nur mit dem Datensatz in natürlicher Sprache trainiert wurde, war frustriert, als er die neue Aufgabe des Abwischens des Tisches ausführte, während der vom RT-Trajektorienmodell gesteuerte Roboter die Arbeit mit demselben Datensatz verbessert erledigte durch 2D-Trajektorien Nach dem Training wurde die Wischtrajektorie erfolgreich geplant und ausgeführt. Rechts: Ein trainiertes RT-Trajektorienmodell kann bei einer neuen Aufgabe (Abwischen des Tisches) auf verschiedene Weise 2D-Trajektorien erstellen, mit menschlicher Unterstützung oder allein mithilfe eines visuellen Sprachmodells.
Linkes Bild: Der vom RT-Modell gesteuerte Roboter, der nur mit dem Datensatz in natürlicher Sprache trainiert wurde, war frustriert, als er die neue Aufgabe des Abwischens des Tisches ausführte, während der vom RT-Trajektorienmodell gesteuerte Roboter die Arbeit mit demselben Datensatz verbessert erledigte durch 2D-Trajektorien Nach dem Training wurde die Wischtrajektorie erfolgreich geplant und ausgeführt. Rechts: Ein trainiertes RT-Trajektorienmodell kann bei einer neuen Aufgabe (Abwischen des Tisches) auf verschiedene Weise 2D-Trajektorien erstellen, mit menschlicher Unterstützung oder allein mithilfe eines visuellen Sprachmodells.
RT-Trajektorien nutzen die umfangreichen Roboterbewegungsinformationen, die in allen Roboterdatensätzen vorhanden sind, derzeit jedoch nicht ausreichend genutzt werden. RT-Trajectory stellt nicht nur einen weiteren Schritt auf dem Weg zur Entwicklung von Robotern dar, die sich für neue Aufgaben effizient und präzise bewegen, sondern ermöglicht auch die Gewinnung von Wissen aus vorhandenen Datensätzen.
Das obige ist der detaillierte Inhalt vonGoogle Deepmind stellt sich eine Zukunft vor, die Roboter neu erfindet und verkörperte Intelligenz in große Modelle bringt. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Leitartikel|Der Bedarf an Rechenleistung explodiert unter dem Boom großer KI-Modelle: Lingang will eine zig-Milliarden-Industrie aufbauen, und SenseTime wird der „Kettenmeister'
- Um die Entwicklung der Yuanverse-Branche zu unterstützen, wurde dieser Wettbewerb für innovative mobile Kommunikationsanwendungen ins Leben gerufen
- Untersuchung der Anwendung der Go-Sprache in der Smart-Car-Branche
- Ministerium für Industrie und Informationstechnologie: Der Umfang der KI-Kernindustrie meines Landes erreicht 500 Milliarden Yuan, und es wurden mehr als 2.500 digitale Werkstätten und intelligente Fabriken gebaut
- Das General Artificial Intelligence Large Model Industry Development Forum und die Enthüllungszeremonie des Clusterbereichs General Artificial Intelligence Large Model Industry im Bezirk Shijingshan wurden erfolgreich abgehalten