
Heim >Technologie-Peripheriegeräte >KI >Das erste universelle 3D-Grafik- und Textmodellsystem für Möbel und Haushaltsgeräte, das keiner Anleitung bedarf und visuelle Modelle zur Verallgemeinerung verwendet
Das erste universelle 3D-Grafik- und Textmodellsystem für Möbel und Haushaltsgeräte, das keiner Anleitung bedarf und visuelle Modelle zur Verallgemeinerung verwendet

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBnach vorne
- 2024-01-09 19:30:25759Durchsuche
Heutzutage wird die gesamte Hausarbeit von Robotern übernommen.
Der Roboter aus Stanford, der Töpfe benutzen kann, ist gerade aufgetaucht, und der Roboter, der Kaffeemaschinen bedienen kann, ist gerade angekommen, Abbildung-01.

Abbildung-01 Schauen Sie sich einfach das Demonstrationsvideo an und führen Sie eine 10-stündige Schulung durch, um die Kaffeemaschine kompetent bedienen zu können. Vom Einlegen der Kaffeekapsel bis zum Drücken der Starttaste ist alles in einem Rutsch erledigt.
Allerdings ist es ein schwieriges Problem, einem Roboter zu ermöglichen, selbstständig den Umgang mit verschiedenen Möbeln und Haushaltsgeräten zu erlernen, ohne dass Demonstrationsvideos erforderlich sind, wenn er ihnen begegnet. Dies erfordert vom Roboter eine starke visuelle Wahrnehmung und Entscheidungsplanungsfähigkeiten sowie präzise Manipulationsfähigkeiten.

Papierlink: https://arxiv.org/abs/2312.01307
Projekthomepage: https://geometry.stanford.edu/projects/sage/
Code: https://github.com/ geng-haoran/SAGE
Überblick über das Forschungsproblem

Abbildung 1: Nach menschlicher Anweisung kann der Roboterarm verschiedene Haushaltsgeräte ohne Anweisung bedienen.
Kürzlich haben PaLM-E und GPT-4V die Anwendung großer Grafikmodelle bei der Planung von Roboteraufgaben gefördert, und die durch visuelle Sprache gesteuerte allgemeine Robotersteuerung ist zu einem beliebten Forschungsgebiet geworden.
Eine gängige Methode in der Vergangenheit bestand darin, ein zweischichtiges System aufzubauen. Das große Grafikmodell der oberen Schicht übernimmt die Planung und Fähigkeitsplanung, und das Steuerungsstrategiemodell der unteren Schicht ist für die physische Ausführung von Aktionen verantwortlich. Wenn Roboter jedoch mit einer Vielzahl von Haushaltsgeräten konfrontiert werden, die sie noch nie zuvor gesehen haben und bei der Hausarbeit mehrstufige Vorgänge erfordern, sind sowohl die obere als auch die untere Ebene der vorhandenen Methoden hilflos.
Nehmen Sie als Beispiel das fortschrittlichste Grafikmodell GPT-4V. Obwohl es ein einzelnes Bild mit Text beschreiben kann, ist es immer noch voller Fehler, wenn es um die Erkennung, Zählung, Positionierung und Statusschätzung betriebsbereiter Teile geht. Die roten Markierungen in Abbildung 2 sind die verschiedenen Fehler, die GPT-4V bei der Beschreibung von Bildern von Kommoden, Öfen und Standschränken gemacht hat. Aufgrund der falschen Beschreibung ist die Fähigkeitsplanung des Roboters offensichtlich unzuverlässig. Abbildung 2: GP

Inspiriert durch die frühere CVPR-Highlight-Arbeit GAPartNet [1] des Teams von Professor Wang He konzentrierte sich das Forschungsteam auf gemeinsame Teile (GAParts) in verschiedenen Kategorien von Haushaltsgeräten. Obwohl sich Haushaltsgeräte ständig ändern, gibt es immer einige Teile, die unverzichtbar sind. Zwischen jedem Haushaltsgerät und diesen gemeinsamen Teilen bestehen ähnliche Geometrien und Interaktionsmuster. Als Ergebnis stellte das Forschungsteam das Konzept von GAPart in der Arbeit GAPartNet [1] vor. GAPart bezieht sich auf eine generalisierbare und interaktive Komponente. GAPart erscheint auf verschiedenen Kategorien von aufklappbaren Objekten. Beispielsweise finden sich aufklappbare Türen in Tresoren, Kleiderschränken und Kühlschränken. Wie in Abbildung 3 dargestellt, kommentiert GAPartNet [1] die Semantik und Pose von GAPart für verschiedene Objekttypen. Abbildung 3: GAPart: generalisierbare und interaktive Teile [1].
Basierend auf früheren Forschungen führte das Forschungsteam auf kreative Weise GAPart basierend auf dreidimensionalem Sehen in das Objektmanipulationssystem SAGE des Roboters ein. SAGE wird Informationen für VLM und LLM durch verallgemeinerbare 3D-Teileerkennung und genaue Posenschätzung bereitstellen. Auf der Entscheidungsebene löst die neue Methode das Problem unzureichender präziser Berechnungs- und Argumentationsfunktionen des zweidimensionalen Grafikmodells. Auf der Ausführungsebene erreicht die neue Methode verallgemeinerte Operationen für jeden Teil durch eine robuste API für physikalische Operationen GAPart-Posen.
SAGE stellt das erste dreidimensionale verkörperte Grafik- und Text-Großmodellsystem dar, das neue Ideen für die gesamte Verbindung von Robotern von der Wahrnehmung über die physische Interaktion bis hin zum Feedback liefert und neue Wege für Roboter erforscht, komplexe Objekte wie z B. Möbel und Haushaltsgeräte.
Systemeinführung
Abbildung 4 zeigt den grundlegenden Prozess von SAGE. Zunächst analysiert ein Befehlsinterpretationsmodul, das den Kontext interpretieren kann, die in den Roboter eingegebenen Anweisungen und seine Beobachtungen und wandelt diese Analysen in das nächste Roboteraktionsprogramm und die zugehörigen semantischen Teile um. Als nächstes ordnet SAGE den semantischen Teil (z. B. den Container) dem Teil zu, der bedient werden muss (z. B. die Schiebeschaltfläche) und generiert Aktionen (z. B. die Aktion „Drücken“ der Schaltfläche), um die Aufgabe abzuschließen.

Abbildung 4: Methodenübersicht.
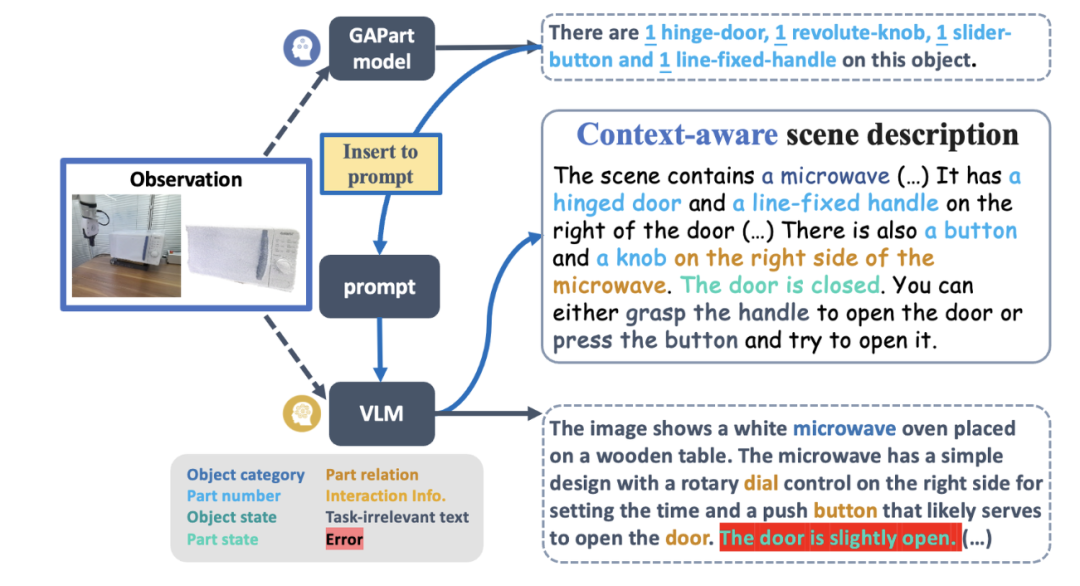
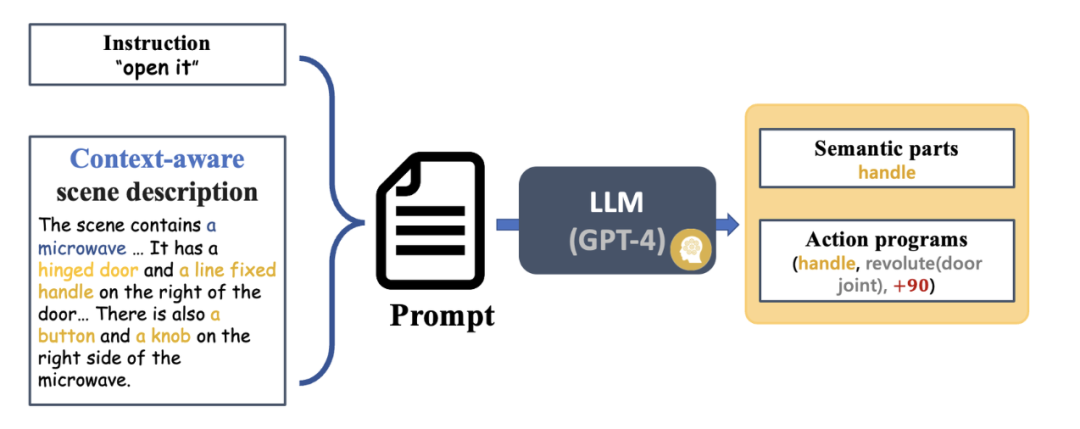
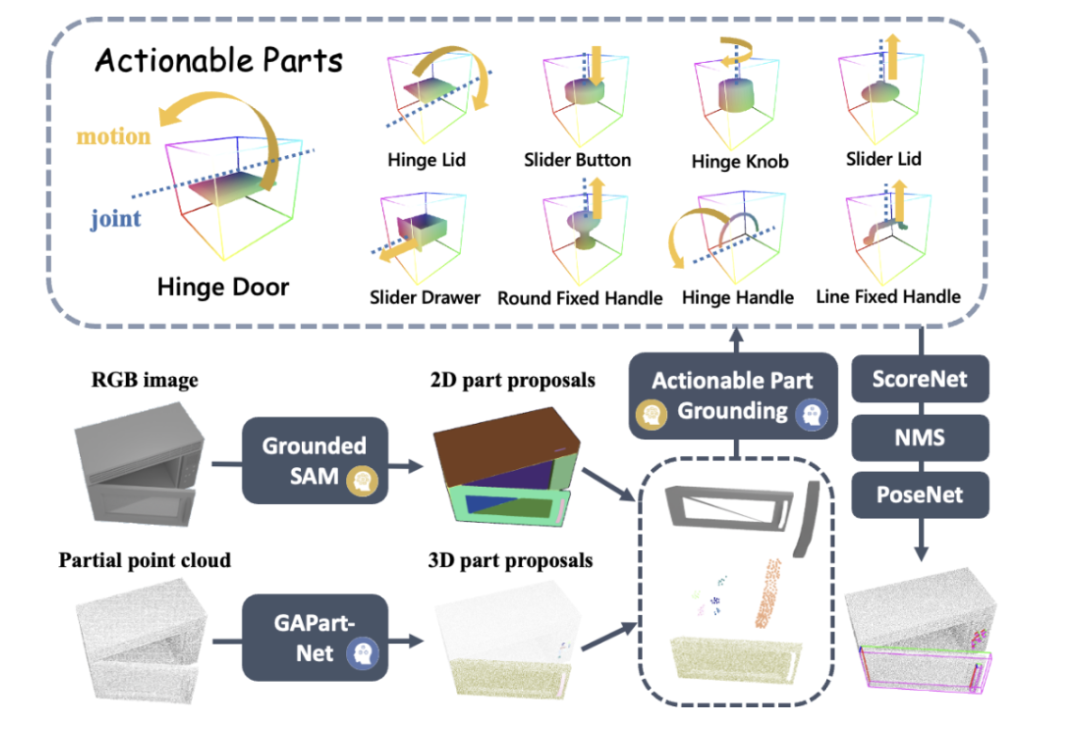



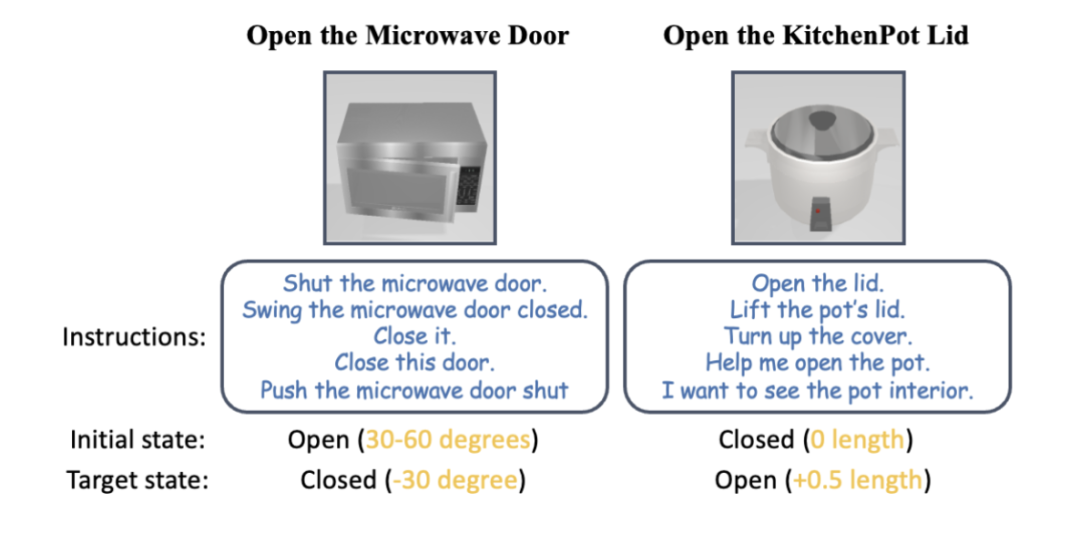
Abbildung 11: SAPIEN-Simulationsexperiment.
Sie nutzten die SAPIEN-Umgebung [4] zur Durchführung von Simulationsexperimenten und entwarfen 12 sprachgesteuerte Aufgaben zur Manipulation artikulierter Objekte. Für jede Kategorie von Mikrowellenherden, Aufbewahrungsmöbeln und Schränken wurden drei Aufgaben entworfen, darunter offene und geschlossene Zustände in unterschiedlichen Ausgangszuständen. Weitere Aufgaben sind „Topfdeckel öffnen“, „Taste auf der Fernbedienung drücken“ und „Mixer starten“. Experimentelle Ergebnisse zeigen, dass SAGE bei fast allen Aufgaben gute Leistungen erbringt.
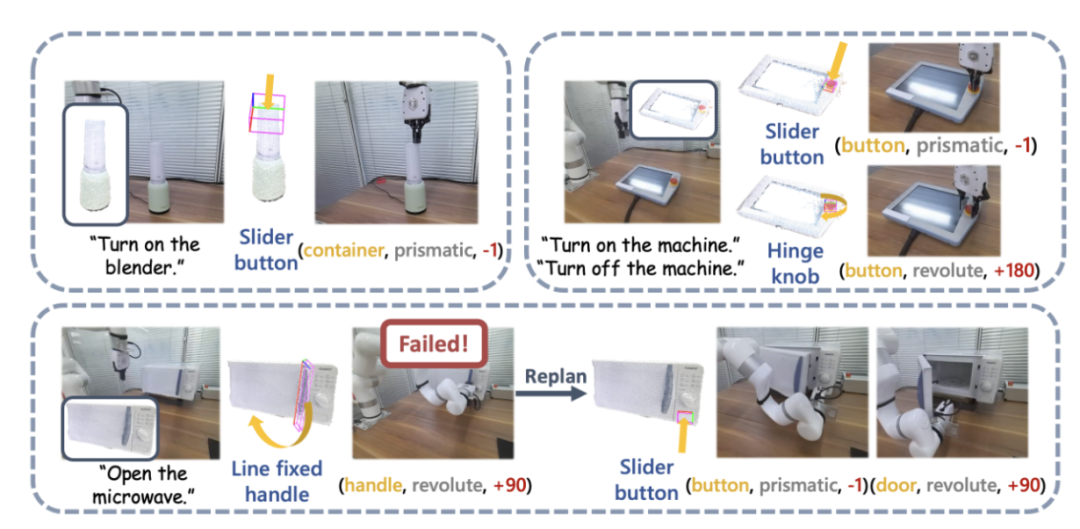
Zusammenfassung
SAGE ist das erste visuelle 3D-Sprachmodell-Framework, das allgemeine Manipulationsanweisungen für komplexe artikulierte Objekte wie Möbel und Haushaltsgeräte generieren kann. Es wandelt sprachgesteuerte Aktionen in ausführbare Manipulationen um, indem es Objektsemantik und Bedienbarkeitsverständnis auf Teileebene verbindet.
Teamvorstellung
SAGE Dieses Forschungsergebnis stammt aus dem Labor von Professor Leonidas Guibas von der Stanford University, dem Embodied Perception and Interaction (EPIC Lab) von Professor Wang He von der Peking University und dem Zhiyuan Artificial Intelligence Research Institute. Die Autoren des Papiers sind der Student der Universität Peking und Gastwissenschaftler der Stanford University, Geng Haoran (Co-Autor), der Doktorand der Universität Peking, Wei Songlin (Co-Autor), die Doktoranden der Stanford University, Deng Congyue und Shen Bokui, und die Betreuer sind Professor Leonidas Guibas und Professor Wang He.Referenzen:
[2] Kirillov, Alexander, Eric Mintun, Nikhila Ravi, Hanzi Mao, Chloe Rolland, Laura Gustafson, Tete Xiao et al. „Alles segmentieren.“ arXiv-Vorabdruck arXiv:2304.02643 (2023).
[3] Zhang, Hao, Feng Li, Shilong Liu, Lei Zhang, Hang Su, Jun Zhu, Lionel M. Ni und Heung-Yeung Shum Objekterkennung beenden.“ arXiv-Vorabdruck arXiv:2203.03605 (2022). [4] Xiang, Fanbo, Yuzhe Qin, Kaichun Mo, Yikuan interaktive Umgebung.“ In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, S. 11097-11107, 2020.
Das obige ist der detaillierte Inhalt vonDas erste universelle 3D-Grafik- und Textmodellsystem für Möbel und Haushaltsgeräte, das keiner Anleitung bedarf und visuelle Modelle zur Verallgemeinerung verwendet. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Einführung einer erweiterten Nachrichtenbox (MessageBoxEx) in C#, die zusätzliche Nachrichten übertragen kann
- Welche Kenntnisse müssen PHP-Ingenieure haben?
- Code für Postmessage in HTML5 zur Implementierung der Wertübertragung zwischen untergeordneten und übergeordneten Fenstern
- Wie alt ist das Alter, bevor man WEB-Frontend-Ingenieur werden kann?