
Heim >Technologie-Peripheriegeräte >KI >Erledige 13 visuelle Sprachaufgaben! Das Harbin Institute of Technology veröffentlicht das multimodale Großmodell „Jiutian' mit einer Leistungssteigerung um 5 %
Erledige 13 visuelle Sprachaufgaben! Das Harbin Institute of Technology veröffentlicht das multimodale Großmodell „Jiutian' mit einer Leistungssteigerung um 5 %

- 王林nach vorne
- 2023-12-04 14:14:50870Durchsuche
Um das Problem der unzureichenden visuellen Informationsextraktion in multimodalen großen Sprachmodellen zu lösen, schlugen Forscher des Harbin Institute of Technology (Shenzhen) ein zweischichtiges wissensverstärktes multimodales großes Sprachmodell vor – JiuTian-LION.

Der Inhalt, der neu geschrieben werden muss, ist: Papierlink: https://arxiv.org/abs/2311.11860
GitHub: https://github.com/rshaojimmy/JiuTian
Projekt-Homepage: https://rshaojimmy.github.io/Projects/JiuTian-LION
Im Vergleich zu bestehenden Arbeiten analysierte JiuTian zum ersten Mal die internen Konflikte zwischen Verständnisaufgaben auf Bildebene und Positionierungsaufgaben auf Regionsebene und schlug eine Feinabstimmungsstrategie für segmentierte Anweisungen und einen Hybridadapter vor, um eine gegenseitige Verbesserung der beiden Aufgaben zu erreichen.
Durch die Integration einer feinkörnigen räumlichen Wahrnehmung und semantischen visuellen Wissens auf hohem Niveau hat Jiutian erhebliche Leistungsverbesserungen bei 17 visuellen Sprachaufgaben erzielt, darunter Bildbeschreibung, visuelle Probleme und visuelle Lokalisierung (z. B. bis zu 5 beim visuellen räumlichen Denken). ) % Leistungsverbesserung), Erreichen des internationalen Spitzenniveaus in 13 Bewertungsaufgaben. Der Leistungsvergleich ist in Abbildung 1 dargestellt.
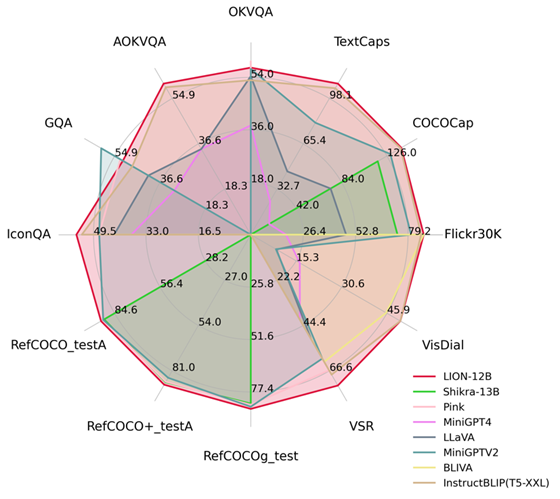
Abbildung 1: Im Vergleich zu anderen MLLMs hat Jiutian bei den meisten Aufgaben eine optimale Leistung erzielt.
JiuTian-LION
Durch die Bereitstellung multimodaler Wahrnehmungsfähigkeiten für große Sprachmodelle (LLMs) haben einige Arbeiten zur Generierung multimodaler großer Sprachmodelle (MLLMs) begonnen und bei vielen visuellen Sprachaufgaben bahnbrechende Fortschritte erzielt. Bestehende MLLMs verwenden jedoch hauptsächlich visuelle Encoder, die auf Bild-Text-Paaren vorab trainiert wurden, wie z. B. CLIP-ViT
Die Hauptaufgabe dieser visuellen Encoder besteht darin, die grobkörnige modale Ausrichtung von Bild und Text auf Bildebene zu lernen Ihnen fehlen umfassende visuelle Wahrnehmungs- und Informationsextraktionsfähigkeiten und sie sind nicht in der Lage, ein feinkörniges visuelles Verständnis durchzuführen Verständnis von MLLMs. Es gibt viele Mängel, wie z. B. Objektillusion, wie in Abbildung 2 dargestellt
Im Vergleich zu bestehenden multimodalen großen Sprachmodellen (MLLMs) verbessert Jiutian effektiv die visuellen Verständnisfähigkeiten von MLLMs, indem es feinkörniges visuelles Wissen über räumliches Bewusstsein und semantische visuelle Beweise auf hoher Ebene einfügt, genauere Textantworten generiert und reduziert Das Halluzinationsphänomen von MLLMs
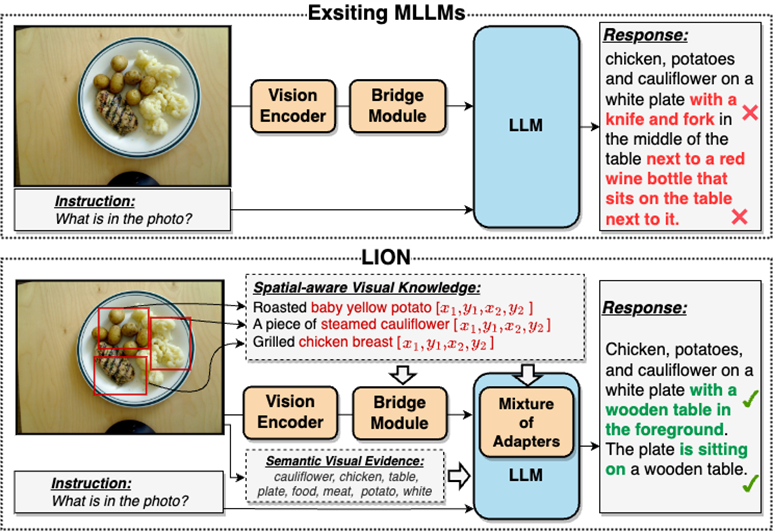 Doppelschichtiges visuelles wissensverstärktes multimodales großes Sprachmodell-JiuTian-LION
Doppelschichtiges visuelles wissensverstärktes multimodales großes Sprachmodell-JiuTian-LION
Um die Mängel von MLLMs bei der Extraktion und dem Verständnis visueller Informationen zu beheben, schlugen Forscher A Es wird eine zweischichtige, durch visuelles Wissen erweiterte MLLM-Methode namens JiuTian-LION vorgeschlagen. Das spezifische Methodengerüst ist in Abbildung 3 dargestellt
Diese Methode verbessert MLLMs hauptsächlich unter zwei Aspekten: progressive Integration von feinkörnigem räumlich bewusstem visuellem Wissen (Progressive Integration von feinkörnigem räumlich bewusstem visuellem Wissen) und hoher Ebene Software unter Soft Prompts Soft Prompting von semantischen visuellen Beweisen auf hoher Ebene.
Konkret schlugen die Forscher eine Strategie zur Feinabstimmung segmentierter Anweisungen vor, um den internen Konflikt zwischen der Verständnisaufgabe auf Bildebene und der Lokalisierungsaufgabe auf Regionsebene zu lösen. Sie bringen nach und nach feinkörniges räumliches Bewusstseinswissen in MLLMs ein. Gleichzeitig fügten sie MLLMs Bildbeschriftungen als semantische visuelle Beweise auf hoher Ebene hinzu und verwendeten Soft-Prompting-Methoden, um die negativen Auswirkungen falscher Beschriftungen abzumildern. Das Rahmendiagramm des JiuTian-LION-Modells sieht wie folgt aus:
Diese Arbeit verwendet eine segmentierte Trainingsstrategie, um zunächst das Verständnis auf Bildebene und Positionierungsaufgaben auf Regionsebene basierend auf den Zweigen Q-Former und Vision Aggregator-MLP zu erlernen, und verwendet dann einen Hybridadapter mit einem Routing-Mechanismus, um verschiedene Aufgaben dynamisch zusammenzuführen in der letzten Trainingsphase Durchführung des verzweigten Wissensverbesserungsmodells an zwei Aufgaben.
Diese Arbeit extrahiert auch Bildbeschriftungen als semantische visuelle Beweise auf hoher Ebene über den RAM und schlägt dann eine Soft-Prompting-Methode vor, um den Effekt der semantischen Injektion auf hoher Ebene zu verbessern Wissen
Bei der direkten Durchführung eines einstufigen gemischten Trainings zu Verständnisaufgaben auf Bildebene (einschließlich Bildbeschreibung und visueller Beantwortung von Fragen) und Lokalisierungsaufgaben auf Regionsebene (einschließlich gerichtetem Ausdrucksverständnis, gerichteter Ausdruckserzeugung usw.), MLLMs Es kommt zu internen Konflikten zwischen den beiden Aufgaben. Daher kann nicht bei allen Aufgaben eine bessere Gesamtleistung erzielt werden.
Forscher glauben, dass dieser interne Konflikt hauptsächlich durch zwei Probleme verursacht wird. Das erste Problem ist das Fehlen eines Vortrainings für die modale Ausrichtung auf regionaler Ebene. Derzeit verwenden die meisten MLLMs mit Positionierungsfunktionen auf regionaler Ebene zunächst eine große Menge relevanter Daten für das Vortraining Modale Ausrichtung basierend auf begrenzten Trainingsressourcen. Visuelle Funktionsanpassung an Aufgaben auf Regionsebene.
Ein weiteres Problem ist der Unterschied in den Eingabe-Ausgabe-Mustern zwischen Verständnisaufgaben auf Bildebene und Lokalisierungsaufgaben auf Regionsebene. Letztere erfordern, dass das Modell zusätzlich bestimmte kurze Sätze über Objektkoordinaten versteht (in Form von
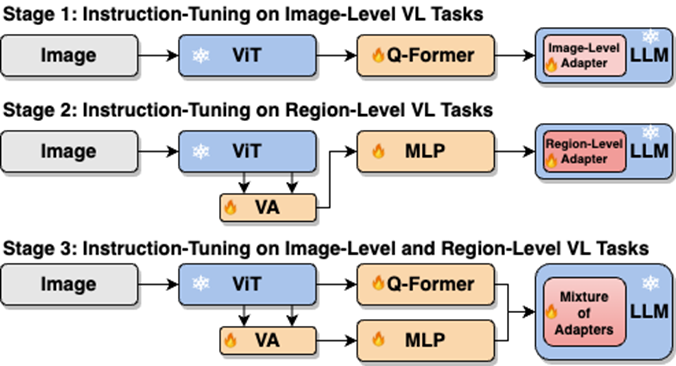
). . Um die oben genannten Probleme zu lösen, schlugen die Forscher eine Strategie zur Feinabstimmung segmentierter Anweisungen und einen Hybridadapter mit einem Routing-Mechanismus vor. Wie in Abbildung 4 dargestellt, haben die Forscher den einstufigen Feinabstimmungsprozess der Anweisungen in drei Phasen unterteilt:
Wie in Abbildung 4 dargestellt, haben die Forscher den einstufigen Feinabstimmungsprozess der Anweisungen in drei Phasen unterteilt:
Verwenden Sie ViT, Q-Former und einen Bildebenenadapter, um die Aufgabe des Verstehens auf Bildebene zu erlernen Globales visuelles Wissen; Verwendung von Vision Aggregator, MLP und Adaptern auf regionaler Ebene zum Erlernen von Positionierungsaufgaben auf regionaler Ebene mit feinkörnigem raumbezogenem visuellem Wissen. Es wird ein Hybridadapter mit einem Routing-Mechanismus vorgeschlagen, um visuelles Wissen unterschiedlicher Granularität dynamisch zu integrieren Geäst. Tabelle 3 zeigt die Leistungsvorteile der Feinabstimmungsstrategie für segmentierte Anweisungen gegenüber dem einstufigen Training. Abbildung 4: Die Feinabstimmungsstrategie für segmentierte Anweisungen für das Injizieren von Weichteilen fordert Die semantischen visuellen Beweise auf hoher Ebene müssen neu geschrieben werden
Die Forscher schlugen vor, Bildetiketten als wirksame Ergänzung zu den semantischen visuellen Beweisen auf hoher Ebene zu verwenden, um die globale visuelle Wahrnehmungsverständnisfähigkeit von MLLMs weiter zu verbessern
 Konkret extrahieren Sie zunächst die Tags des Bildes über den RAM und verwenden Sie dann die spezifische Befehlsvorlage „Gemäß
Konkret extrahieren Sie zunächst die Tags des Bildes über den RAM und verwenden Sie dann die spezifische Befehlsvorlage „Gemäß
“ in dieser Befehlsvorlage wird durch einen lernbaren Soft-Prompt-Vektor ersetzt.
In Verbindung mit dem spezifischen Ausdruck „verwenden oder teilweise verwenden“ in der Vorlage kann der Soft-Hint-Vektor das Modell anleiten, die potenziellen negativen Auswirkungen falscher Bezeichnungen abzumildern.
Experimentelle Ergebnisse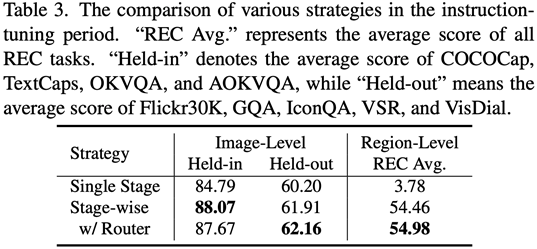
Die Forscher führten Auswertungen zu 17 Aufgaben-Benchmark-Sets durch, darunter Bildunterschrift, visuelle Fragebeantwortung (VQA) und instruktives Ausdrucksverständnis (REC).
Experimentelle Ergebnisse zeigen, dass Jiutian in 13 Bewertungssätzen das international führende Niveau erreicht hat. Insbesondere im Vergleich zu InstructBLIP und Shikra hat Jiutian umfassende und konsistente Leistungsverbesserungen bei Verständnisaufgaben auf Bildebene bzw. Positionierungsaufgaben auf Regionsebene erzielt und kann bei Aufgaben zum visuellen räumlichen Denken (VSR) eine Verbesserung von bis zu 5 % erzielen.
Wie aus Abbildung 5 ersichtlich ist, gibt es Unterschiede in den Fähigkeiten von Jiutian und anderen MLLMs bei verschiedenen multimodalen Aufgaben in visueller Sprache, was darauf hindeutet, dass Jiutian bessere Leistungen im Hinblick auf feinkörniges visuelles Verständnis und visuelle räumliche Denkfähigkeiten erbringt und dazu in der Lage ist Ausgabe mit weniger halluzinierender Textantwort

Der neu geschriebene Inhalt ist: Die fünfte Abbildung zeigt eine qualitative Analyse der Unterschiede in den Fähigkeiten des Jiutian Large Model, InstructBLIP und Shikra
Abbildung 6 Durch Stichprobenanalyse Es zeigt, dass das Jiutian-Modell sowohl bei visuellen Sprachaufgaben auf Bildebene als auch auf regionaler Ebene über hervorragende Verständnis- und Erkennungsfähigkeiten verfügt.

Das sechste Bild: Durch die Analyse weiterer Beispiele werden die Fähigkeiten des Jiutian-Großmodells aus der Perspektive des Bildes und des visuellen Verständnisses auf regionaler Ebene demonstriert
Zusammenfassung
(1) Dies Die Arbeit schlägt ein neues multimodales großes Sprachmodell vor – Jiutian: ein multimodales großes Sprachmodell, das durch zweischichtiges visuelles Wissen erweitert wird.
(2) Diese Arbeit wurde anhand von 17 Benchmark-Sets für visuelle Sprachaufgaben bewertet, einschließlich Bildbeschreibung, Beantwortung visueller Fragen und Verständnis des instruktiven Ausdrucks, von denen 13 Bewertungssets die derzeit beste Leistung erzielten.
(3) Diese Arbeit schlägt eine segmentierte Strategie zur Feinabstimmung von Anweisungen vor, um den internen Konflikt zwischen Bildebenenverständnis und Lokalisierungsaufgaben auf Regionsebene zu lösen und eine gegenseitige Verbesserung zwischen den beiden Aufgaben zu erreichen
(4) Dies Die Arbeit integriert erfolgreich das Verständnis auf Bildebene und Positionierungsaufgaben auf regionaler Ebene, um visuelle Szenen auf mehreren Ebenen umfassend zu verstehen. In Zukunft kann diese umfassende visuelle Verständnisfähigkeit auf verkörperte intelligente Szenen angewendet werden, um Robotern dabei zu helfen, besser und umfassender zu identifizieren und zu arbeiten die aktuelle Umgebung verstehen, um wirksame Entscheidungen zu treffen.
Das obige ist der detaillierte Inhalt vonErledige 13 visuelle Sprachaufgaben! Das Harbin Institute of Technology veröffentlicht das multimodale Großmodell „Jiutian' mit einer Leistungssteigerung um 5 %. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Was soll ich tun, wenn die Menüleiste oben in meiner KI fehlt?
- Mit welcher Software können AI-Dateien geöffnet und bearbeitet werden?
- Was ist die Tastenkombination für die AI-Sperrschicht?
- Maßgeschneidertes Training von Deep-Learning-Modellen mithilfe von Transfer-Learning-Techniken
- Google schlägt ein datenfreies NAS vor, das nur ein vorab trainiertes Modell für die Websuche erfordert