
Heim >Technologie-Peripheriegeräte >KI >Durchbrechen der Auflösungsgrenze: Byte und die University of Science and Technology of China enthüllen ein großes multimodales Dokumentenmodell
Durchbrechen der Auflösungsgrenze: Byte und die University of Science and Technology of China enthüllen ein großes multimodales Dokumentenmodell

- 王林nach vorne
- 2023-12-04 14:14:591065Durchsuche
Jetzt gibt es sogar große multimodale hochauflösende Dokumente!
Diese Technologie kann nicht nur Informationen in Bildern genau identifizieren, sondern auch eine eigene Wissensdatenbank aufrufen, um Fragen entsprechend den Benutzeranforderungen zu beantworten.
Wenn Sie beispielsweise die Mario-Benutzeroberfläche auf dem Bild sehen, können Sie direkt antworten, von wo sie stammt Nintendo-Arbeit.

Dieses Modell wurde gemeinsam von ByteDance und der University of Science and Technology of China erforscht und am 24. November 2023 auf arXiv hochgeladen
In dieser Forschung schlug das Autorenteam DocPedia vor, ein einheitliches hochauflösendes Multimodales Dokument-Großmodell DocPedia.

In dieser Studie verwendete der Autor eine neue Methode, um die Mängel bestehender Modelle zu beheben, die hochauflösende Dokumentbilder nicht analysieren können.
DocPedia hat eine Auflösung von bis zu 2560 x 2560. Die fortschrittlichen multimodalen Großmodelle der Branche wie LLaVA und MiniGPT-4 haben jedoch eine Obergrenze der Bildverarbeitungsauflösung von 336 x 336 und können keine hochauflösenden Dokumente analysieren Bilder.
Wie funktioniert dieses Modell und welche Optimierungsmethode wird verwendet?
Deutliche Verbesserung verschiedener Bewertungsergebnisse
In diesem Artikel zeigt der Autor ein Beispiel für das Verständnis hochauflösender Bilder und Texte von DocPedia. Es ist zu beobachten, dass DocPedia in der Lage ist, den Befehlsinhalt zu verstehen und relevante Grafik- und Textinformationen aus hochauflösenden Dokumentbildern und natürlichen Szenenbildern genau zu extrahieren. In diesem Satz von Bildern konnte DocPedia beispielsweise problemlos das Nummernschild ermitteln. Textinformationen wie Computerkonfiguration und sogar handgeschriebener Text können genau beurteilt werden.
 In Kombination mit Textinformationen in Bildern kann DocPedia auch umfangreiche Modellschlussfolgerungsfunktionen nutzen, um Probleme basierend auf dem Kontext zu analysieren.
In Kombination mit Textinformationen in Bildern kann DocPedia auch umfangreiche Modellschlussfolgerungsfunktionen nutzen, um Probleme basierend auf dem Kontext zu analysieren.
 Nach dem Lesen der Bildinformationen wird DocPedia auf der Grundlage seiner umfangreichen Weltwissensdatenbank auch auf den erweiterten Inhalt antworten, der nicht im Bild angezeigt wird.
Nach dem Lesen der Bildinformationen wird DocPedia auf der Grundlage seiner umfangreichen Weltwissensdatenbank auch auf den erweiterten Inhalt antworten, der nicht im Bild angezeigt wird.
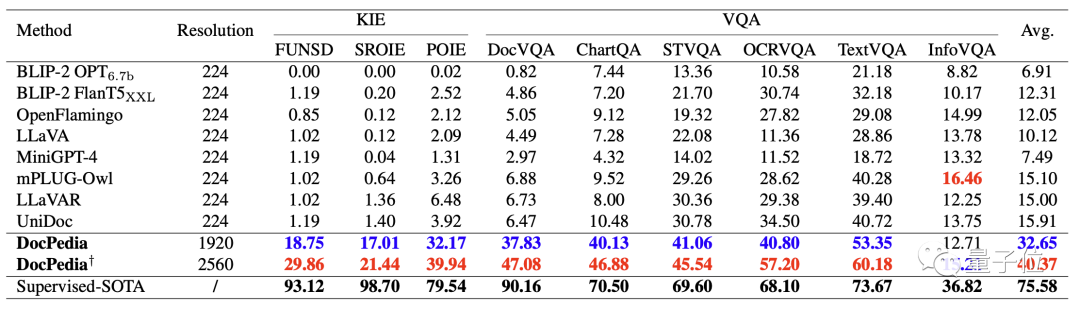
 In der folgenden Tabelle werden einige vorhandene multimodale große Modelle und der Schlüssel von DocPedia quantitativ verglichen Informationsextraktion (KIE) und visuelle Fragebeantwortung (VQA).
In der folgenden Tabelle werden einige vorhandene multimodale große Modelle und der Schlüssel von DocPedia quantitativ verglichen Informationsextraktion (KIE) und visuelle Fragebeantwortung (VQA).
Durch die Erhöhung der Auflösung und die Einführung effektiver Trainingsmethoden können wir sehen, dass DocPedia in verschiedenen Test-Benchmarks deutliche Verbesserungen erzielt hat
 Wie erzielt DocPedia also einen solchen Effekt?
Wie erzielt DocPedia also einen solchen Effekt?
Lösen Sie das Auflösungsproblem aus dem Frequenzbereich.
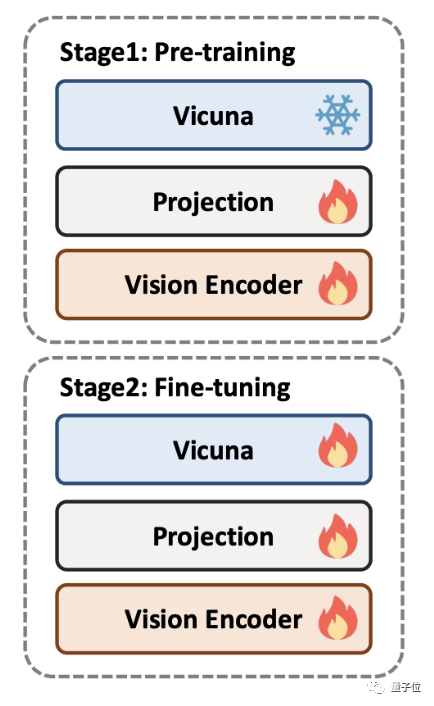
Das Training von DocPedia ist in zwei Phasen unterteilt: Vortraining und Feinabstimmung. Um DocPedia zu trainieren, sammelte das Autorenteam eine große Menge an Grafikdaten mit verschiedenen Dokumenttypen und erstellte einen Datensatz zur Feinabstimmung der Anweisungen.
In der Vortrainingsphase wird das große Sprachmodell eingefroren und nur der Teil des visuellen Encoders wird optimiert, um seinen Ausgabe-Token-Darstellungsraum mit dem großen Sprachmodell in Einklang zu bringen.
In dieser Phase hat das Autorenteam schlägt vor, hauptsächlich die Wahrnehmungsfähigkeiten von DocPedia zu trainieren, einschließlich der Wahrnehmung von Text und natürlichen Szenen.
Zu den Aufgaben vor dem Training gehören Texterkennung, Texterkennung, End-to-End-OCR, Absatzlesen, Volltextlesen und Bildunterschriften.
In der Feinabstimmungsphase wird das groß angelegte Sprachmodell aufgehoben und eine durchgängige Gesamtoptimierung durchgeführt
Das Autorenteam schlug eine gemeinsame Trainingsstrategie für Wahrnehmung und Verständnis vor: basierend auf den ursprünglichen Wahrnehmungsaufgaben auf niedriger Ebene Es wurden zwei Arten von Dokumentenverständnis und Szenenbildern hinzugefügt. Aufgaben zum partiellen semantischen Verständnis höherer Ordnung
Eine solche gemeinsame Trainingsstrategie für Wahrnehmung und Verständnis verbessert die Leistung von DocPedia weiter.
 In Bezug auf die Strategie zur Lösung von Problemen löst DocPedia diese im Gegensatz zu bestehenden Methoden aus der Perspektive des
In Bezug auf die Strategie zur Lösung von Problemen löst DocPedia diese im Gegensatz zu bestehenden Methoden aus der Perspektive des
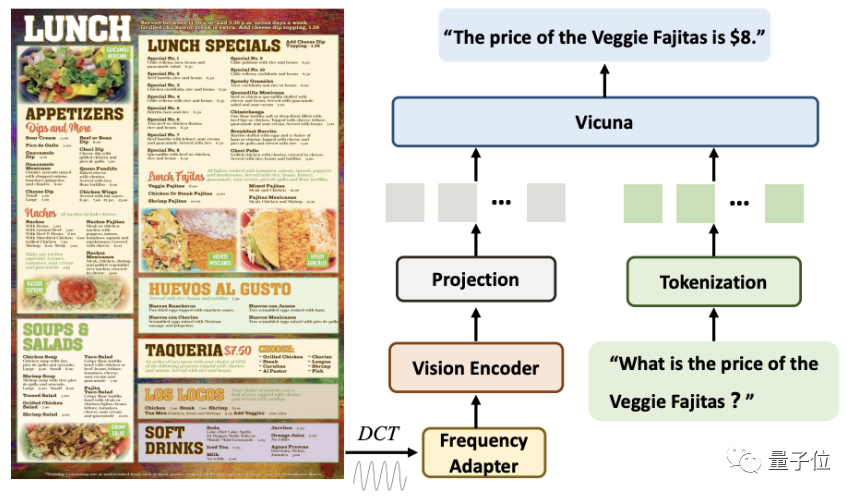
. Bei der Verarbeitung hochauflösender Dokumentbilder extrahiert DocPedia zunächst seine DCT-Koeffizientenmatrix. Diese Matrix kann die räumliche Auflösung um das Achtfache heruntersampeln, ohne die Textinformationen des Originalbilds zu verlieren. Nach diesem Schritt verwenden wir den kaskadierten Frequenzbereichsadapter (Frequenzadapter), um das Eingangssignal für eine tiefere Auflösungskomprimierung zu übertragen und Feature-Extraktion
Mit dieser Methode kann ein 2560×2560-Bild durch 1600 Token dargestellt werden.
Verglichen mit der direkten Eingabe des Originalbilds in einen visuellen Encoder (z. B. Swin Transformer) reduziert diese Methode die Anzahl der Token um das Vierfache.
Abschließend werden diese Token mit den aus den Anweisungen in der Sequenzdimension konvertierten Token verkettet und zur Antwort in das große Modell eingegeben.
Die Ergebnisse des Ablationsexperiments zeigen, dass die Erhöhung der Auflösung und die Durchführung einer gemeinsamen Feinabstimmung von Wahrnehmung und Verständnis zwei wichtige Faktoren zur Verbesserung der Leistung von DocPedia sind.
Die folgende Abbildung vergleicht die Leistung von DocPedia auf einem Papierbild und einem ähnlichen Bild Befehl auf verschiedenen Eingängen. Antworten auf der Skala. Es ist ersichtlich, dass DocPedia genau dann richtig antwortet, wenn die Auflösung auf 2560×2560 erhöht wird.

Das Bild unten vergleicht die Modellreaktionen von DocPedia auf dasselbe Szenentextbild und dieselbe Anweisung unter verschiedenen Feinabstimmungsstrategien.
Aus diesem Beispiel geht hervor, dass das durch Wahrnehmung und Verständnis gemeinsam verfeinerte Modell eine genaue Texterkennung und semantische Frage und Antwort durchführen kann

Bitte klicken Sie auf den folgenden Link, um das Papier anzuzeigen: https ://arxiv.org/abs/ 2311.11810
Das obige ist der detaillierte Inhalt vonDurchbrechen der Auflösungsgrenze: Byte und die University of Science and Technology of China enthüllen ein großes multimodales Dokumentenmodell. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Detaillierte Erläuterung des PyTorch-Batch-Trainings und des Optimierervergleichs
- So löschen Sie eine Tabelle in der Datenbank in MySQL
- Programmierer sind in Gefahr! Es heißt, dass OpenAI weltweit Outsourcing-Truppen rekrutiert und ChatGPT-Code-Farmer Schritt für Schritt schult
- Yunshenchen und Shengteng CANN arbeiten zusammen, um ein ROS-Trainingslager für die Entwicklung vierbeiniger Roboterhunde zu eröffnen