
Heim >Technologie-Peripheriegeräte >KI >Beliebige gemischte Text-, Bild- und Audiogenerierung, multimodal mit einer leistungsstarken Basis-Engine CoDi-2
Beliebige gemischte Text-, Bild- und Audiogenerierung, multimodal mit einer leistungsstarken Basis-Engine CoDi-2

- PHPznach vorne
- 2023-12-04 12:39:58862Durchsuche
Forscher wiesen darauf hin, dass CoDi-2 einen großen Durchbruch auf dem Gebiet der Entwicklung umfassender multimodaler Basismodelle darstellt
Im Mai dieses Jahres schlugen die University of North Carolina in Chapel Hill und Microsoft eine Composable Diffusion (Composable Das Diffusionsmodell (als CoDi bezeichnet) ermöglicht es, mehrere Modalitäten in einem Modell zu vereinen. CoDi unterstützt nicht nur die Generierung von Einzelmodalität zu Einzelmodalität, sondern kann auch mehrere bedingte Eingaben und die Generierung multimodaler Verbindungen empfangen.
Kürzlich haben viele Forscher von der UC Berkeley, Microsoft Azure AI, Zoom und der University of North Carolina in Chapel Hill das CoDi-System auf die CoDi-2-Version aktualisiert

Papieradresse: https:// arxiv.org/pdf/2311.18775.pdf
Projektadresse: https://codi-2.github.io/

Schreiben Sie den Inhalt neu, ohne die ursprüngliche Bedeutung zu ändern In die chinesische Sprache umgeschrieben, muss der Originalsatz nicht erscheinen
Laut Zineng Tangs Artikel folgt CoDi-2 komplexen multimodalen verschachtelten Kontextanweisungen, um jede Modalität (Text, Bild und Audio) mit Zero-Shot oder zu generieren Wenige Interaktionen

Dieser Link ist die Bildquelle: https://twitter.com/ZinengTang/status/1730658941414371820
Man kann sagen, dass es sich um eine vielseitige und interaktive multimodale große Sprache handelt Modell (MLLM) kann CoDi-2 kontextuelles Lernen, Denken, Chatten, Bearbeiten und andere Aufgaben in einem modalen Any-to-Any-Input-Output-Paradigma durchführen. Durch die Ausrichtung von Modalitäten und Sprachen während der Kodierung und Generierung ermöglicht CoDi-2 LLM nicht nur, komplexe modale Verschachtelungsanweisungen und kontextbezogene Beispiele zu verstehen, sondern auch autoregressiv eine sinnvolle und kohärente multimodale Ausgabe innerhalb eines kontinuierlichen Merkmalsraums zu generieren.
Um CoDi-2 zu trainieren, erstellten die Forscher einen großen generativen Datensatz, der kontextbezogene multimodale Anweisungen in Text, Bild und Audio enthält. CoDi-2 demonstriert eine Reihe von Zero-Shot-Funktionen für die multimodale Generierung, wie z. B. kontextuelles Lernen, Argumentation und Any-to-Any-Modalgenerierungskombinationen durch mehrere Runden interaktiven Dialogs. Unter anderem übertrifft es frühere domänenspezifische Modelle bei Aufgaben wie der themengesteuerten Bildgenerierung, der visuellen Transformation und der Audiobearbeitung.

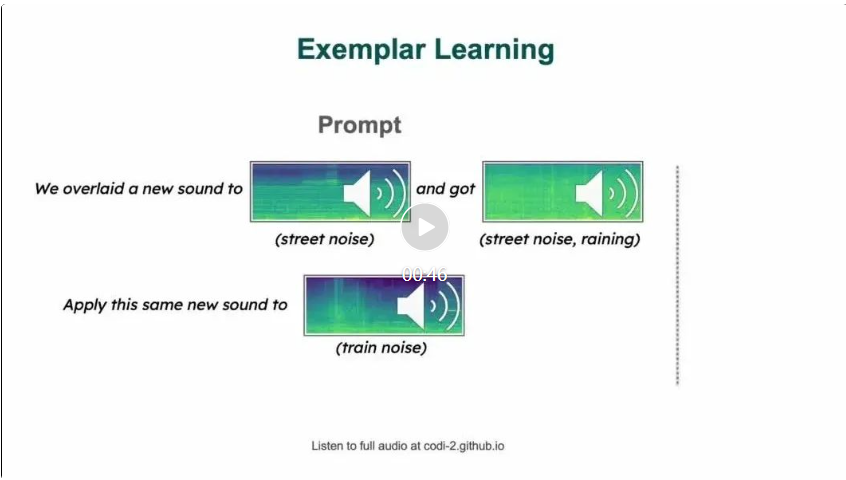
Mehrere Dialogrunden zwischen Menschen und CoDi-2 bieten kontextbezogene multimodale Anweisungen zur Bildbearbeitung.
Was neu geschrieben werden muss, ist: Modellarchitektur
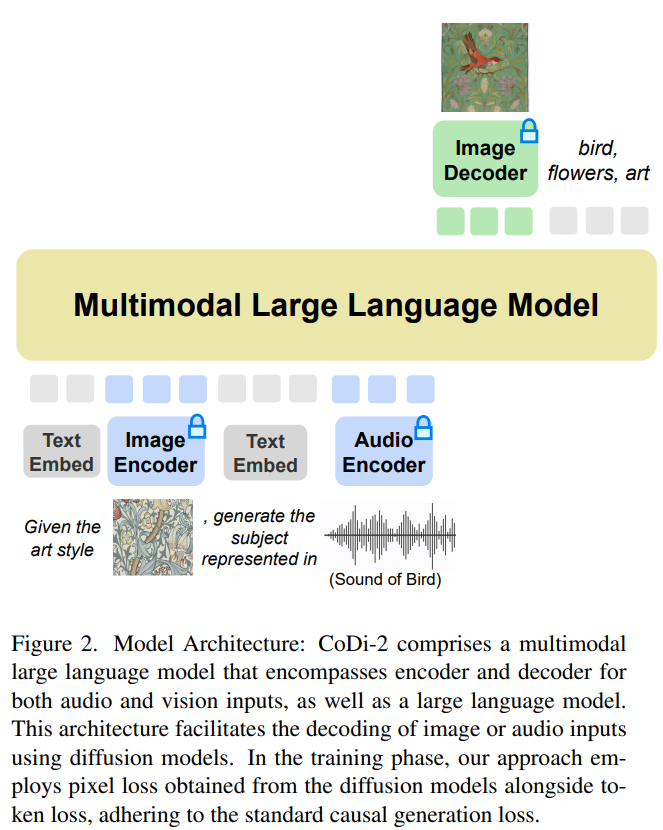
CoDi-2 ist darauf ausgelegt, multimodale Eingaben wie Text, Bilder und Audio im Kontext zu verarbeiten und dabei spezifische Anweisungen zu verwenden, um kontextbezogenes Lernen zu fördern und entsprechenden Text zu generieren , Bild- und Audioausgabe. Was für CoDi-2 neu geschrieben werden muss, ist: Das Modellarchitekturdiagramm sieht wie folgt aus.
Verwendung eines multimodalen großen Sprachmodells als Basis-Engine
Dieses Any-to-Any-Basismodell kann verschachtelte modale Eingaben verarbeiten, komplexe Anweisungen verstehen und darüber nachdenken (z. B. Konversationen mit mehreren Runden, kontextbezogene). Beispiele) und interagieren mit dem multimodalen Diffusor. Voraussetzung dafür ist ein leistungsstarker Basismotor. Als Engine schlugen die Forscher MLLM vor, das eine multimodale Wahrnehmung für Nur-Text-LLMs ermöglichen soll.
Mithilfe einer ausgerichteten multimodalen Encoderzuordnung können Forscher LLM nahtlos auf modal verschachtelte Eingabesequenzen aufmerksam machen. Insbesondere verwenden sie bei der Verarbeitung multimodaler Eingabesequenzen zunächst multimodale Encoder, um multimodale Daten Feature-Sequenzen zuzuordnen, und fügen dann vor und nach der Feature-Sequenz spezielle Token hinzu, z. B. „〈Audio〉 [Audio-Feature-Sequenz“. „] 〈/audio〉“.
Die Grundlage der multimodalen Generierung ist MLLM
Forscher schlugen vor, das Diffusionsmodell (DM) in MLLM zu integrieren, um eine multimodale Ausgabe zu generieren. Während dieses Prozesses wurden detaillierte multimodale verschachtelte Anweisungen und Eingabeaufforderungen befolgt. Die Trainingsziele des Diffusionsmodells sind wie folgt:
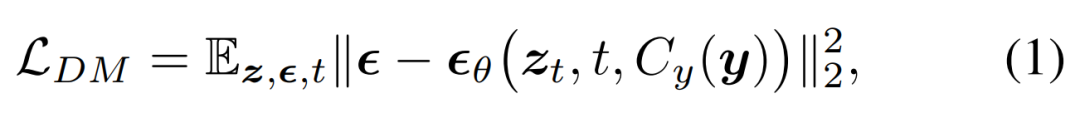
Sie schlugen dann vor, ein MLLM zu trainieren, um bedingte Merkmale c = C_y (y) zu generieren, die in ein Diffusionsmodell eingespeist werden, um die Zielausgabe x zu synthetisieren. Auf diese Weise wird der generative Verlust des Diffusionsmodells zum Trainieren des MLLM genutzt.
Aufgabentypen
Das Modell demonstriert starke Fähigkeiten in den folgenden Beispielaufgabentypen, die einen einzigartigen Ansatz bieten, der das Modell dazu veranlasst, multimodale Inhalte im Kontext zu generieren oder zu transformieren, einschließlich Text, Bilder, Audio, Video und dergleichen Kombination
Der umgeschriebene Inhalt lautet: 1. Null-Stichproben-Inferenz. Bei Zero-Shot-Inferenzaufgaben muss das Modell ohne vorherige Beispiele argumentieren und neue Inhalte generieren
2. Eine oder mehrere Beispielaufforderungen stellen dem Modell ein oder mehrere Beispiele zur Verfügung, aus denen es lernen kann, bevor ähnliche Aufgaben ausgeführt werden. Dieser Ansatz zeigt sich bei Aufgaben, bei denen das Modell erlernte Konzepte von einem Bild auf ein anderes anwendet oder ein neues Kunstwerk erstellt, indem es den im bereitgestellten Beispiel beschriebenen Stil versteht.
Experimente und Ergebnisse
Modelleinstellungen
Die Implementierung des Modells in diesem Artikel basiert auf Llama2, insbesondere Llama-2-7b-chat-hf. Die Forscher verwendeten ImageBind, das Bild-, Video-, Audio-, Text-, Tiefen-, Wärme- und IMU-Modus-Encoder ausgerichtet hat. Wir verwenden ImageBind, um Bild- und Audiofunktionen zu kodieren und sie durch ein mehrschichtiges Perzeptron (MLP) auf die Eingabedimensionen eines LLM (Llama-2-7b-chat-hf) zu projizieren. MLP besteht aus linearer Abbildung, Aktivierung, Normalisierung und einer weiteren linearen Abbildung. Wenn LLMs Bild- oder Audiofunktionen generieren, projizieren sie diese über einen anderen MLP zurück in die ImageBind-Funktionsdimension. Das Bilddiffusionsmodell in diesem Artikel basiert auf StableDiffusion2.1 (stabilityai/stable-diffusion-2-1-unclip), AudioLDM2 und zeroskop v2.
Um Original-Eingabebilder oder -Audios mit höherer Wiedergabetreue zu erhalten, geben Forscher diese in das Diffusionsmodell ein und generieren Merkmale durch Verkettung des Diffusionsrauschens. Diese Methode ist sehr effektiv, sie kann die Wahrnehmungseigenschaften des Eingabeinhalts weitestgehend bewahren und neue Inhalte hinzufügen oder den Stil ändern und andere Anweisungen bearbeiten
Der Inhalt, der neu geschrieben werden muss, ist: Bildgenerierung Auswertung
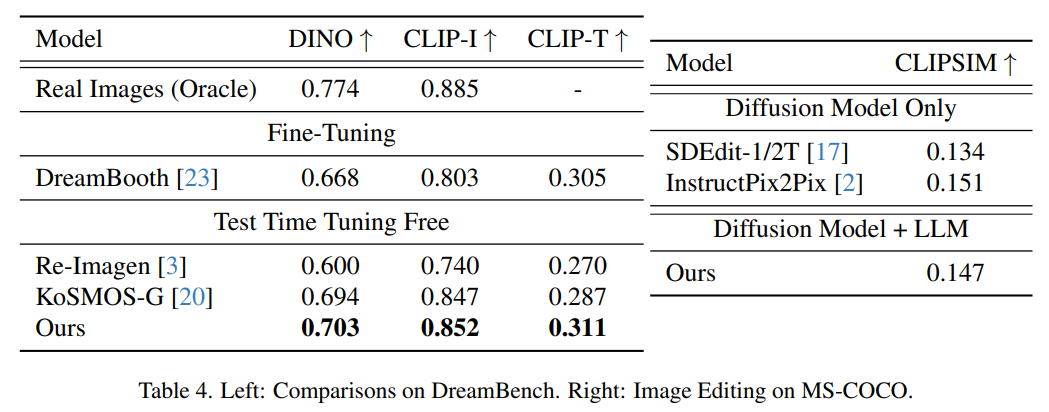
Die folgende Abbildung zeigt die Auswertungsergebnisse der themengesteuerten Bildgenerierung auf Dreambench und FID-Scores auf MSCOCO. Die Methode in diesem Artikel erreicht eine äußerst wettbewerbsfähige Zero-Shot-Leistung und demonstriert ihre Generalisierungsfähigkeit auf unbekannte neue Aufgaben.
Bewertung der Audiogenerierung
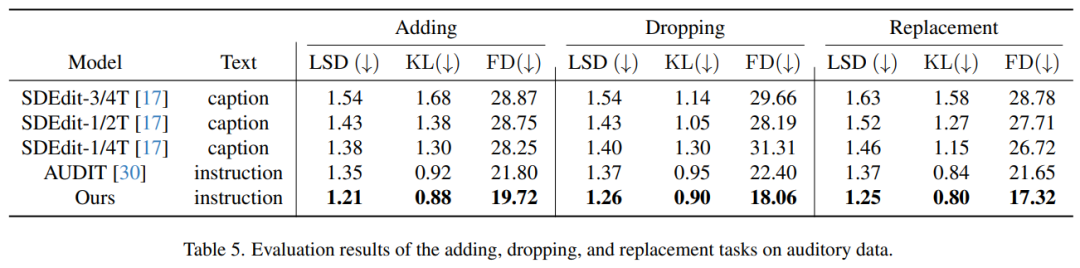
Tabelle 5 zeigt die Bewertungsergebnisse für die Audioverarbeitungsaufgabe, d. h. das Hinzufügen, Löschen und Ersetzen von Elementen in der Audiospur. Aus der Tabelle geht hervor, dass unsere Methode im Vergleich zu früheren Methoden eine hervorragende Leistung zeigt. Bemerkenswert ist, dass es bei allen drei Bearbeitungsaufgaben die niedrigsten Werte bei allen Metriken erzielte – Log Spectral Distance (LSD), Kullback-Leibler (KL) Divergence und Fréchet Distance (FD)
Lesen Sie den Originalartikel, um mehr technische Informationen zu erhalten Einzelheiten.
Das obige ist der detaillierte Inhalt vonBeliebige gemischte Text-, Bild- und Audiogenerierung, multimodal mit einer leistungsstarken Basis-Engine CoDi-2. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Stärken Sie die Modebranche mit Technologie und unterstützen Sie den Bezirk Futian beim Aufbau eines „Bay Area Fashion Headquarters Center'.
- Luxshare Precision: Das Unternehmen verfügt über ausgereifte Fähigkeiten und eine Geschäftsgrundlage für den Einstieg in aufstrebende Branchen wie humanoide Roboter
- Das Ministerium für Industrie und Informationstechnologie kündigte an: Beschleunigung der Entwicklung der Gehirn-Computer-Schnittstellenindustrie
- Die Größe der Computerindustrie meines Landes erreicht 2,6 Billionen Yuan, wobei in den letzten sechs Jahren mehr als 20,91 Millionen Allzweckserver und 820.000 KI-Server ausgeliefert wurden.
- Die 2023 Artificial Intelligence Computing Conference (AICC) fand in Peking statt und konzentrierte sich auf branchenrelevante Diskussionen über groß angelegte Modelle und intelligente Rechenleistung