
Heim >Technologie-Peripheriegeräte >KI >DetZero: Waymo belegt den ersten Platz in der 3D-Erkennungsliste, vergleichbar mit manueller Annotation!
DetZero: Waymo belegt den ersten Platz in der 3D-Erkennungsliste, vergleichbar mit manueller Annotation!

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBnach vorne
- 2023-12-04 11:33:52861Durchsuche

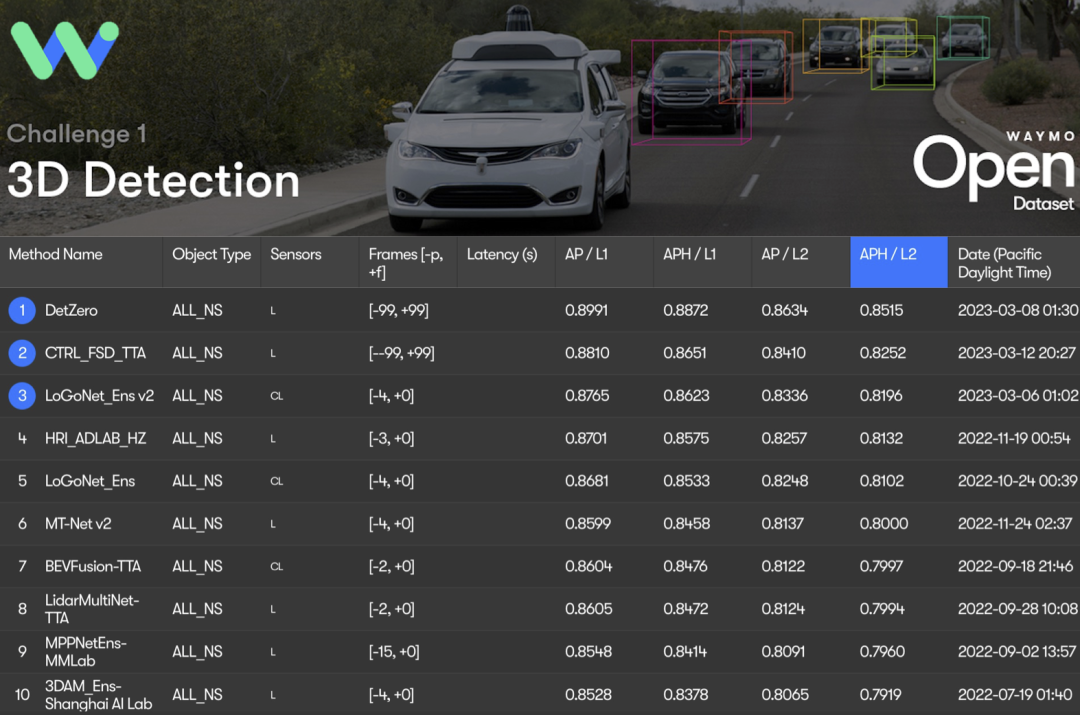
Dieser Artikel schlägt eine Reihe von Offline-3D-Objekterkennungsalgorithmen DetZero vor. Durch umfassende Recherche und Auswertung des öffentlichen Datensatzes von Waymo kann DetZero kontinuierliche und vollständige Objekttrajektoriensequenzen generieren und langfristige Punktwolken vollständig nutzen. Funktionen verbessern die Qualität der wahrgenommenen Ergebnisse erheblich. Gleichzeitig belegte es mit einer Leistung von 85,15 mAPH (L2) den ersten Platz in der Rangliste der WOD-3D-Objekterkennung. Darüber hinaus kann DetZero eine hochwertige automatische Kennzeichnung für das Online-Modelltraining bereitstellen, und seine Ergebnisse haben das Niveau der manuellen Kennzeichnung erreicht oder sogar übertroffen.
Dies ist der Papierlink: https://arxiv.org/abs/2306.06023
Der Inhalt, der neu geschrieben werden muss, ist: Codelink: https://github.com/PJLab-ADG/DetZero
Bitte besuchen der Homepage-Link: https://superkoma.github.io/detzero-page
1 Einführung
Um die Effizienz der Datenanmerkung zu verbessern, haben wir eine neue Methode untersucht. Diese Methode basiert auf Deep Learning und unüberwachtem Lernen und kann automatisch annotierte Daten generieren. Mithilfe großer Mengen unbeschrifteter Daten können wir ein autonomes Fahrwahrnehmungsmodell trainieren, um Objekte auf der Straße zu erkennen und zu erkennen. Diese Methode kann nicht nur die Kosten für die Kennzeichnung von Daten senken, sondern auch die Effizienz der Nachbearbeitung verbessern. Wir haben Waymos Offline-3D-Objekterkennungsmethode 3DAL[] als Vergleichsbasis für unsere Experimente verwendet und die Ergebnisse zeigen, dass unsere vorgeschlagene Methode erhebliche Verbesserungen in Bezug auf Genauigkeit und Effizienz aufweist. Wir glauben, dass diese Methode eine wichtige Rolle in der zukünftigen autonomen Fahrtechnologie spielen wird. Objekterkennung (
Erkennung): Geben Sie eine kleine Menge kontinuierlicher Punktwolken-Rahmendaten ein und geben Sie den Begrenzungsrahmen und die Kategorieinformationen des 3D-Objekts in jedem Rahmen aus ;- Mehrfache Zielverfolgung (Tracking): Ordnen Sie die erkannten Objekte in jedem Bild zu, um eine Objektsequenz zu bilden und weisen Sie eine eindeutige Objekt-ID zu.
- Bewegungsklassifizierung (Bewegungsklassifizierung): Bestimmen Sie die Bewegungszustand des Objekts (stationär oder bewegt);
- Objektzentrierte Verfeinerung: Extrahieren Sie basierend auf dem vom vorherigen Modul vorhergesagten Bewegungszustand die Zeitreihen-Punktwolkenmerkmale von stationären bzw. sich bewegenden Objekten, um einen genauen Begrenzungsrahmen vorherzusagen. Schließlich wird der optimierte 3D-Begrenzungsrahmen über die Posenmatrix zurück in das Koordinatensystem jedes Frames übertragen, in dem sich das Objekt befindet.
- Allerdings haben viele gängige Online-3D-Objekterkennungsmethoden durch die Nutzung der zeitlichen Kontextmerkmale von Punktwolken bessere Ergebnisse erzielt als bestehende Offline-3D-Objekterkennungsmethoden. Wir haben jedoch festgestellt, dass diese Methoden die Eigenschaften langer Sequenzpunktwolken nicht effektiv nutzen konnten. Aktuelle Zielerkennungs- und -verfolgungsalgorithmen konzentrieren sich hauptsächlich auf Leistungsindikatoren auf der Begrenzungsrahmenebene (Box-Ebene) und werden durch den Online-3D-Erkennungsalgorithmus geleitet TTA. Eine große Anzahl redundanter Frames, die nach der Fusion mit mehreren Modellen generiert werden, werden als Eingabe für den Tracking-Algorithmus verwendet, was normalerweise leicht zu schwerwiegenden Problemen wie Trajektoriensegmentierung, ID-Umschaltung und falscher Zuordnung führt vollständige Objektsequenzen, wodurch die Nutzung langfristiger Punktwolkenmerkmale, die Objekten entsprechen, behindert wird. Wie in der Abbildung unten dargestellt, wird die ursprüngliche Flugbahn eines Objekts in mehrere Teilsequenzen (T1, T2, T3) unterteilt, was dazu führt, dass die Merkmale des T1-Segments mit mehr Informationen nicht zwischen T2 und T3 im optimierten Frame geteilt werden können Im T4-Segment können auch verlorene Fragmente nicht zurückgerufen werden; der optimierte Frame im T5-Fragment bleibt FP, nachdem er an die ursprüngliche FP-Position verschoben wurde.
- Das auf der Bewegungszustandsklassifizierung basierende Optimierungsmodell nutzt die zeitlichen Eigenschaften des Objekts nicht vollständig aus. Beispielsweise bleibt die Größe eines starren Objekts über die Zeit konstant und eine genauere Größenschätzung kann durch die Erfassung von Daten aus verschiedenen Winkeln erreicht werden. Die Bewegungsbahn des Objekts sollte bestimmten kinematischen Einschränkungen folgen, was sich in der Glätte der Flugbahn widerspiegelt . Wie in Abbildung (a) unten gezeigt, berücksichtigt der auf Schiebefenstern basierende Optimierungsmechanismus für dynamische Objekte nicht die Konsistenz der Objektgeometrie und aktualisiert den Begrenzungsrahmen nur durch die Zeitreihen-Punktwolkeninformationen mehrerer benachbarter Frames in der vorhergesagten geometrischen Größe auftritt. Im Beispiel von (b) können durch Aggregation aller Punktwolken des Objekts dichte Zeitreihen-Punktwolkenmerkmale erhalten und die genaue geometrische Größe des Begrenzungsrahmens für jeden Frame vorhergesagt werden.
Das auf dem Bewegungszustand basierende Optimierungsmodell sagt die Größe des Objekts voraus (a), und das geometrische Optimierungsmodell sagt die Größe des Objekts nach der Aggregation aller Punktwolken aus verschiedenen Perspektiven voraus (b)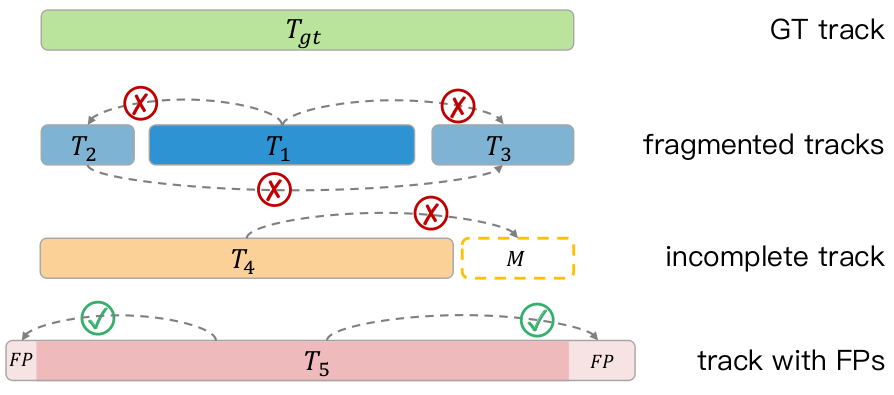
2 Methode
In diesem Artikel wird ein neues Offline-Algorithmus-Framework für die 3D-Objekterkennung namens DetZero vorgeschlagen. Dieses Framework weist die folgenden Merkmale auf: (1) Verwenden Sie Multi-Frame-3D-Detektoren und Offline-Tracker als Upstream-Module, um eine genaue und vollständige Objektverfolgung bereitzustellen, wobei der Schwerpunkt auf einem hohen Rückruf von Objektsequenzen (Track-Level-Recall) liegt Enthält ein auf dem Aufmerksamkeitsmechanismus basierendes Optimierungsmodell, das langfristige Punktwolkenfunktionen verwendet, um verschiedene Attribute von Objekten zu lernen und vorherzusagen, einschließlich verfeinerter geometrischer Abmessungen, Positionen glatter Bewegungsbahnen und aktualisierter Konfidenzwerte
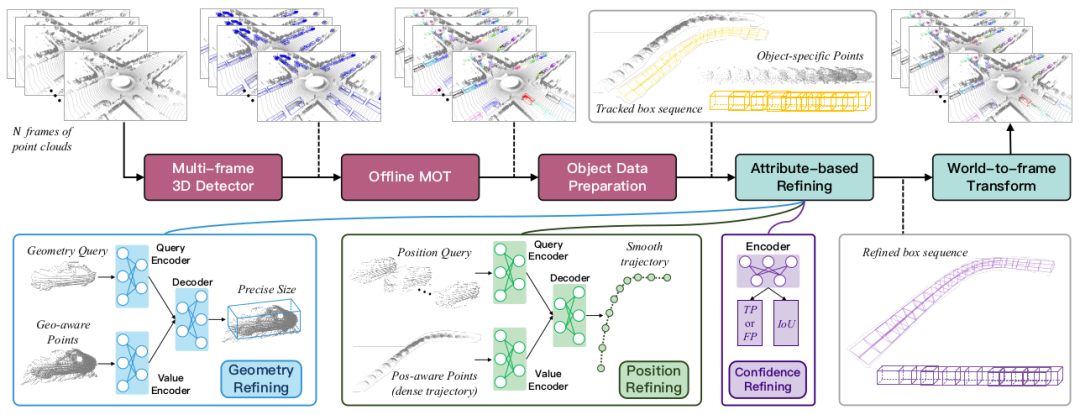
2.1 Generieren Sie a vollständige Objektsequenz
Wir verwenden den öffentlichen CenterPoint[] als Basisdetektor. Um mehr Erkennungskandidatenrahmen bereitzustellen, haben wir ihn in drei Aspekten verbessert: (1) Verwendung verschiedener Rahmenpunktwolkenkombinationen als Eingabe, um die Leistung zu maximieren Reduzieren der Leistung; (2) Verwenden Sie Punktwolkendichteinformationen, um die ursprünglichen Punktwolkenmerkmale und Voxelmerkmale in einem zweistufigen Modul zusammenzuführen, um die Grenzergebnisse der ersten Stufe zu optimieren. (3) Verwenden Sie die Inferenzstufen-Datenerweiterung (TTA). -Modell-Ergebnisfusion (Ensemble) und andere Technologien werden verwendet, um die Anpassungsfähigkeit des Modells an komplexe Umgebungen zu verbessern. Im Offline-Tracking-Modul wird eine zweistufige Korrelationsstrategie eingeführt, um falsche Übereinstimmungen zu reduzieren zum Vertrauen, und die hohe Gruppe besteht darin, dass Assoziationen vorhandene Trajektorien aktualisieren, und nicht aktualisierte Trajektorien sind mit niedrigen Gruppierungen verbunden. Gleichzeitig kann die Länge der Objekttrajektorie bis zum Ende der Sequenz andauern, wodurch Probleme beim ID-Wechsel vermieden werden. Darüber hinaus führen wir den Tracking-Algorithmus in umgekehrter Reihenfolge aus, um einen weiteren Satz von Trajektorien zu generieren, diese durch Positionsähnlichkeit zu verknüpfen und schließlich die WBF-Strategie zu verwenden, um die erfolgreich abgeglichenen Trajektorien zu verschmelzen, um die Integrität des Anfangs und Endes der Sequenz weiter zu verbessern. Schließlich wird für die differenzierte Objektsequenz die entsprechende Punktwolke jedes Frames extrahiert und gespeichert; die nicht aktualisierten redundanten Boxen und einige kürzere Sequenzen werden ohne nachgelagerte Optimierung direkt in die endgültige Ausgabe eingefügt.
2.2 Objektoptimierungsmodul basierend auf AttributvorhersageDas bisherige objektzentrierte Optimierungsmodell ignorierte die Korrelation zwischen Objekten in verschiedenen Bewegungszuständen, wie z. B. die Konsistenz geometrischer Formen und die Bewegung von Objekten in benachbarten Momenten. Basierend auf diesen Beobachtungen zerlegen wir die traditionelle Bounding-Box-Regressionsaufgabe in drei Module: Vorhersage der Geometrie-, Standort- und Konfidenzattribute von Objekten Aussehen und Form des gesamten Objekts. Zuerst wird eine lokale Koordinatentransformation durchgeführt, um die Objektpunktwolke an lokalen Rahmen an verschiedenen Positionen auszurichten, und der Projektionsabstand jedes Punktes zu den sechs Oberflächen des Begrenzungsrahmens wird berechnet, um die Informationsdarstellung des Begrenzungsrahmens zu verstärken, und dann direkt Alle Punktwolken verschiedener Frames zusammenführen Als Schlüssel und Wert geometrischer Merkmale mit mehreren Ansichten werden t Stichproben zufällig aus der Objektsequenz als Abfrage für geometrische Merkmale mit einer Ansicht ausgewählt. Die geometrische Abfrage wird an die Selbstaufmerksamkeitsschicht gesendet, um die Unterschiede untereinander zu sehen, und dann an die Queraufmerksamkeitsschicht gesendet, um die Merkmale der erforderlichen Perspektive zu ergänzen und die genaue geometrische Größe vorherzusagen.
Interaktion zwischen lokalen und globalen Positionen: Wählen Sie zufällig eine beliebige Box in der Objektsequenz als Ursprung aus, übertragen Sie alle anderen Boxen und entsprechenden Objektpunktwolken in dieses Koordinatensystem und berechnen Sie die Summe jedes Punktes zum Mittelpunkt der jeweiligen Begrenzung Box Der Abstand zwischen den acht Eckpunkten dient als Schlüssel und Wert des globalen Positionsmerkmals. Jedes Beispiel in der Objektsequenz wird als Positionsabfrage verwendet und an die Selbstaufmerksamkeitsschicht gesendet, um den relativen Abstand zwischen der aktuellen Position und anderen Positionen zu bestimmen. Anschließend wird es in die Queraufmerksamkeitsschicht eingegeben, um die Kontextbeziehung zu simulieren Lokale zu globalen Positionen und prognostizieren Sie den Versatz zwischen jedem anfänglichen Mittelpunkt und dem wahren Mittelpunkt sowie die Kurswinkeldifferenz.
- Konfidenzoptimierung: Der Klassifizierungszweig wird verwendet, um zu klassifizieren, ob das Objekt TP oder FP ist. Der IoU-Regressionszweig sagt die IoU-Größe zwischen einem Objekt und der Grundwahrheitsbox voraus, nachdem er durch das geometrische Modell und das Positionsmodell optimiert wurde. Der endgültige Konfidenzwert ist das geometrische Mittel dieser beiden Zweige. 3 Experimente Als fortschrittlichster multimodaler Fusions-3D-Detektor hat DetZero erhebliche Leistungsvorteile gezeigt
- Waymo 3D-Erkennungsranking-Ergebnisse, alle Ergebnisse verwenden TTA- oder Ensemble-Technologie, † bezieht sich auf das Offline-Modell, ‡ bezieht sich auf das Punktwolken-Bildfusionsmodell, * bedeutet anonym Einreichungsergebnisse
- In ähnlicher Weise haben wir dank der Genauigkeit des Erkennungsrahmens und der Integrität der Objektverfolgungssequenz mit 75,05 MOTA (L2) die erste Leistung in der Waymo 3D-Tracking-Rangliste erzielt.
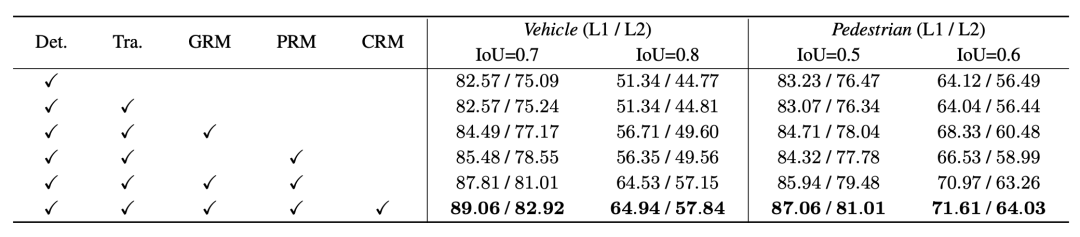
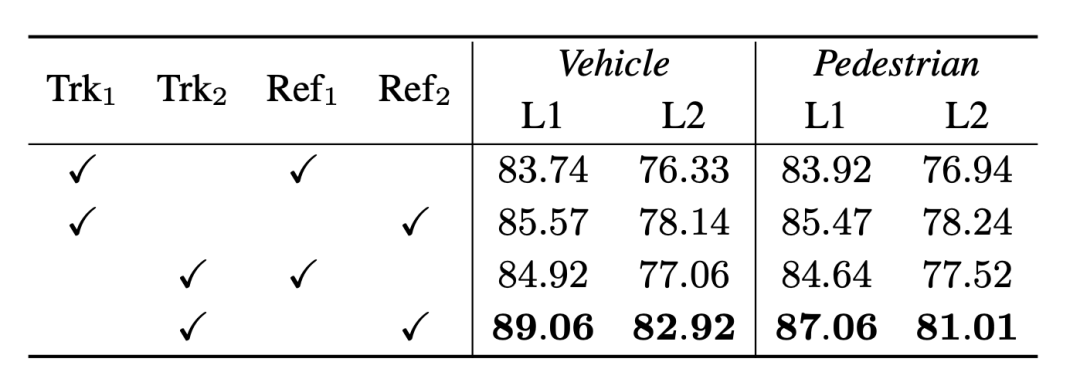
Waymo 3D-Tracking-Rankings, * bedeutet anonyme Übermittlung der Ergebnisse3.2 Ablationsexperiment führte dies für Fahrzeuge und Fußgänger durch und wählte den Standardwert (0,7 und 0,5) und den strengen Wert (0,8 und 0,6) für den IoU-Schwellenwert. Gleichzeitig wählten wir für denselben Satz von Erkennungsergebnissen den Tracker und die Optimierung aus Es wurde eine Cross-Combination-Verifizierung des Modells in 3DAL und DetZero durchgeführt, und die Ergebnisse zeigten weiterhin, dass der Tracker und der Optimierer von DetZero eine bessere Leistung erbringen und die Kombination der beiden größere Vorteile aufwies.
Kreuzvalidierungsexperimente verschiedener Upstream- und Downstream-Modulkombinationen, die Indizes 1 und 2 repräsentieren 3DAL bzw. DetZero und der Indikator ist 3D APH
Unser Offline-Tracker achtet mehr auf die Integrität der Objektsequenz, obwohl die Die MOTA-Leistung der beiden ist gering, aber die Leistung von Recall@track ist einer der Gründe für den großen Unterschied in der endgültigen Optimierungsleistung. Leistungsvergleich der Leistung des Offline-Trackers (Trk2) und des 3DAL-Trackers (Trk1). von MOTA und Recall@track
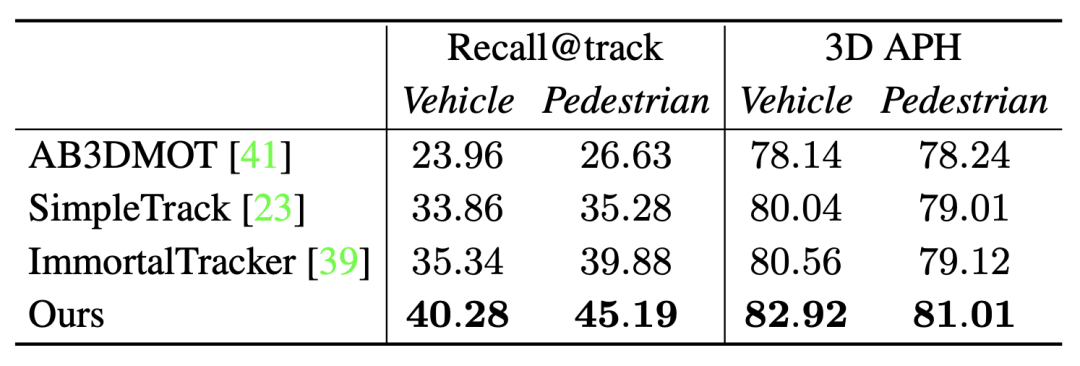
Darüber hinaus zeigt sich dies auch im Vergleich zu anderen hochmodernen Trackern 
Recall@track ist der vom Tracking-Algorithmus verarbeitete Sequenzabruf, 3D APH ist die endgültige Leistung, die von verarbeitet wird das gleiche Optimierungsmodell
3.3 Generalisierungsleistung
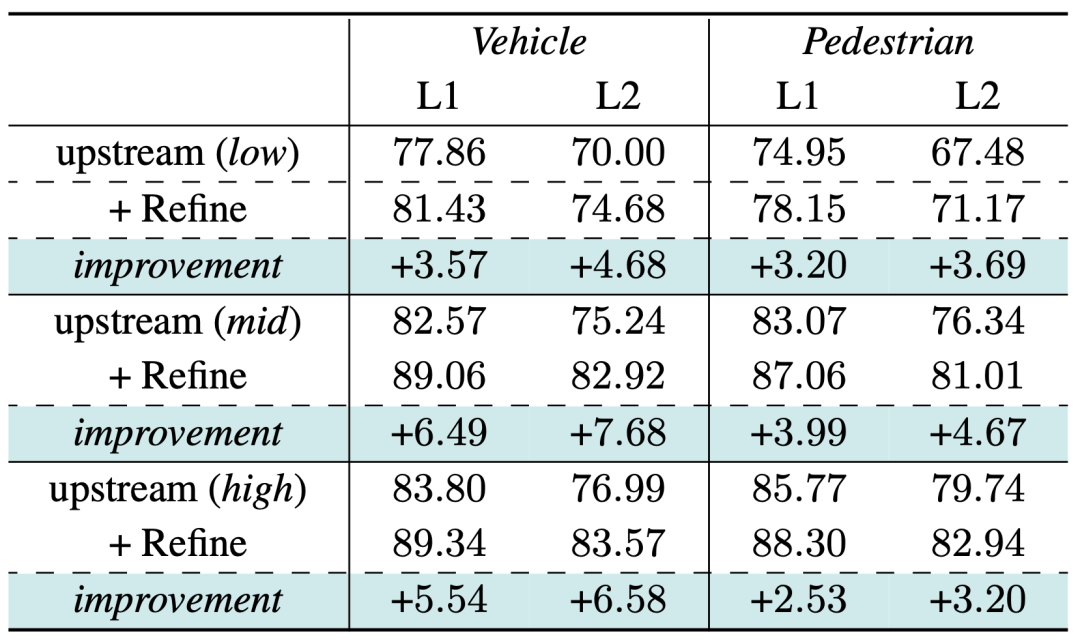
Um zu überprüfen, ob unser Optimierungsmodell fest an einen bestimmten Upstream-Ergebnissatz angepasst werden kann, haben wir Upstream-Erkennungsverfolgungsergebnisse mit unterschiedlicher Leistung als Eingabe ausgewählt. Die Ergebnisse zeigen, dass wir erhebliche Leistungsverbesserungen erzielt haben, was ein weiterer Beweis dafür ist, dass unser Optimierer die Eigenschaften seiner Zeitreihen-Punktwolke effektiv zur Optimierung nutzen kann, solange das Upstream-Modul immer vollständigere Objektsequenzen abrufen kann
Waymo-Validierungssatz Überprüfung der Generalisierungsleistung, der Indikator ist 3D APH
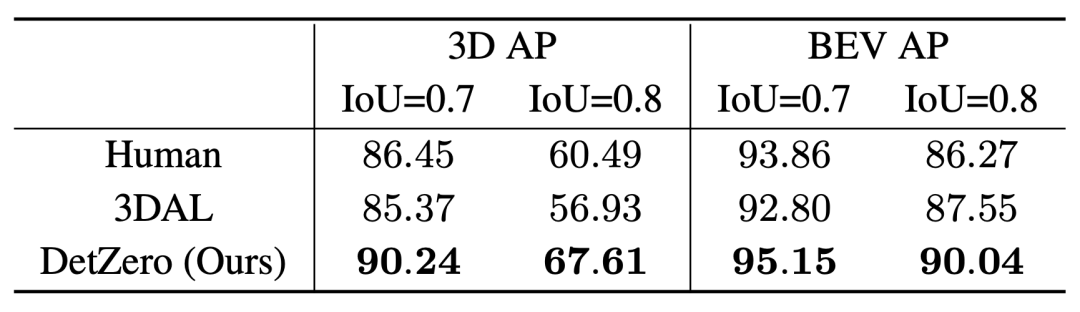
3.4 Vergleich mit der menschlichen Markierungsfähigkeit
Wir werden die AP-Leistung von DetZero in 5 angegebenen Sequenzen basierend auf den experimentellen Einstellungen von 3DAL melden, indem wir die menschliche Leistung anhand eines einzelnen Frames vergleichen gemessen an der Konsistenz der neu gekennzeichneten Ergebnisse mit den ursprünglich als Grundwahrheit gekennzeichneten Ergebnissen. Im Vergleich zu 3DAL und Menschen hat DetZero Vorteile bei verschiedenen Leistungsindikatoren gezeigt
Leistungsvergleich von 3D-AP und BEV-AP unter verschiedenen IoU-Schwellenwerten für die Fahrzeugkategorie Um zu überprüfen, ob hochwertige automatische Annotationsergebnisse das Handbuch ersetzen können Die Anmerkungsergebnisse wurden für das Online-Modelltraining verwendet und wir führten eine halbüberwachte Lernüberprüfung mit dem Waymo-Überprüfungssatz durch. Wir haben 10 % der Trainingsdaten zufällig als Trainingsdaten für das Lehrermodell (DetZero) ausgewählt und eine Inferenz auf die restlichen 90 % der Daten durchgeführt, um automatische Anmerkungsergebnisse zu erhalten, die als Beschriftungen für das Schülermodell verwendet werden. Als Studentenmodell haben wir das Single-Frame-CenterPoint gewählt. In der Fahrzeugkategorie liegen die Ergebnisse des Trainings mit 90 % automatischen Labels und 10 % echten Labels nahe an den Ergebnissen des Trainings mit 100 % echten Labels, während in der Fußgängerkategorie die Ergebnisse des mit automatischen Labels trainierten Modells bereits besser sind als die Originale. Das Ergebnis zeigt, dass die automatische Kennzeichnung für das Online-Modelltraining verwendet werden kann
Halbüberwachte experimentelle Ergebnisse auf dem Waymo-Validierungssatz
3.5 Visualisierte Ergebnisse
Das rote Feld stellt die Upstream-Eingabe dar Ergebnisse, und das blaue Kästchen stellt das optimierte Modell dar. Die AusgabeergebnisseDie erste Zeile stellt die Upstream-Eingabeergebnisse dar, die zweite Zeile stellt die Ausgabeergebnisse des Optimierungsmodells dar und die Objekte innerhalb der gepunkteten Linien stellen die Orte dar, an denen der Unterschied offensichtlich ist vor und nach der Optimierung
Originallink: https://mp.weixin.qq.com/s/HklBecJfMOUCC8gclo-t7Q
 3.3 Generalisierungsleistung
3.3 Generalisierungsleistung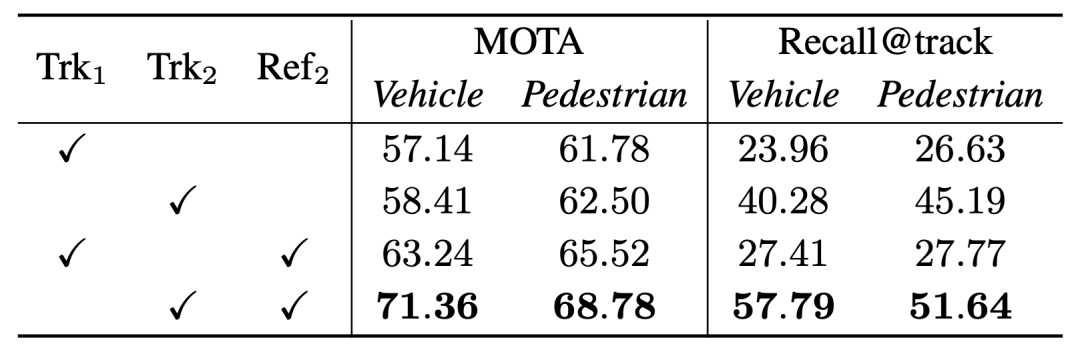
 Die erste Zeile stellt die Upstream-Eingabeergebnisse dar, die zweite Zeile stellt die Ausgabeergebnisse des Optimierungsmodells dar und die Objekte innerhalb der gepunkteten Linien stellen die Orte dar, an denen der Unterschied offensichtlich ist vor und nach der Optimierung
Die erste Zeile stellt die Upstream-Eingabeergebnisse dar, die zweite Zeile stellt die Ausgabeergebnisse des Optimierungsmodells dar und die Objekte innerhalb der gepunkteten Linien stellen die Orte dar, an denen der Unterschied offensichtlich ist vor und nach der OptimierungDas obige ist der detaillierte Inhalt vonDetZero: Waymo belegt den ersten Platz in der 3D-Erkennungsliste, vergleichbar mit manueller Annotation!. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!