
Heim >Technologie-Peripheriegeräte >KI >Kleiner Maßstab, hohe Effizienz: DeepMind bringt multimodale Lösung Mirasol 3B auf den Markt
Kleiner Maßstab, hohe Effizienz: DeepMind bringt multimodale Lösung Mirasol 3B auf den Markt

- PHPznach vorne
- 2023-11-28 14:19:291057Durchsuche
Eine der größten Herausforderungen beim multimodalen Lernen ist die Notwendigkeit, heterogene Modalitäten wie Text, Audio und Video zu kombinieren. Multimodale Modelle müssen Signale aus verschiedenen Quellen kombinieren. Diese Modalitäten weisen jedoch unterschiedliche Merkmale auf und lassen sich nur schwer in einem einzigen Modell kombinieren. Beispielsweise haben Video und Text unterschiedliche Abtastraten
Kürzlich hat das Forschungsteam von Google DeepMind das multimodale Modell in mehrere unabhängige, spezialisierte autoregressive Modelle entkoppelt, um sie entsprechend den Merkmalen verschiedener Modalitäten zu verarbeiten.
Konkret schlägt die Studie ein multimodales Modell namens Mirasol3B vor. Mirasol3B besteht aus zeitsynchronisierten autoregressiven Komponenten für Audio und Video sowie autoregressiven Komponenten für kontextuelle Modalitäten. Diese Modalitäten sind nicht unbedingt zeitlich ausgerichtet, sondern sequentiell angeordnet. Adresse des Papiers: https://arxiv.org/abs/2311.05698 Durch das Erlernen kompakterer Darstellungen, die Steuerung der Sequenzlänge von Audio-Video-Feature-Darstellungen und die Modellierung auf der Grundlage zeitlicher Korrespondenzen ist Mirasol3B in der Lage, die hohen Rechenanforderungen multimodaler Eingaben effektiv zu erfüllen.
 Einführung in die Methode
Einführung in die Methode
Mirasol3B ist ein multimodales Audio-Video-Text-Modell, bei dem die autoregressive Modellierung in autoregressive Komponenten für zeitlich ausgerichtete Modalitäten (z. B. Audio, Video) und autoregressive Komponenten für nicht autoregressive Komponenten von entkoppelt ist zeitlich ausgerichtete kontextuelle Modalitäten (z. B. Text). Mirasol3B verwendet Kreuzaufmerksamkeitsgewichte, um den Lernprozess dieser Komponenten zu koordinieren. Diese Entkopplung macht die Parameterverteilung innerhalb des Modells vernünftiger, weist den Modalitäten (Video und Audio) genügend Kapazität zu und macht das Gesamtmodell leichter.
Wie in Abbildung 1 dargestellt, besteht Mirasol3B aus zwei Hauptlernkomponenten: der autoregressiven Komponente und der Eingabekombinationskomponente. Unter anderem ist die autoregressive Komponente darauf ausgelegt, nahezu gleichzeitige multimodale Eingaben wie Video und Audio für zeitnahe Eingabekombinationen zu verarbeiten Ändern Sie die Sprache auf Chinesisch. Die Studie schlägt vor, die zeitlich ausgerichteten Modalitäten in Zeitabschnitte zu segmentieren und gemeinsame Audio-Video-Darstellungen in den Zeitabschnitten zu lernen. Konkret schlägt diese Forschung einen Mechanismus zum Lernen modaler Gelenkmerkmale namens „Combiner“ vor. „Combiner“ verschmilzt modale Merkmale innerhalb desselben Zeitraums, um eine kompaktere Darstellung zu generieren Empfangen Sie multimodale Eingaben mit unterschiedlichen Raten und erzielen Sie eine gute Leistung bei der Verarbeitung längerer Videos.
„Combiner“ erfüllt effektiv den Bedarf an einer effizienten und informativen modalen Darstellung. Es kann Ereignisse und Aktivitäten in Video- und anderen gleichzeitigen Modalitäten vollständig abdecken und kann in nachfolgenden autoregressiven Modellen verwendet werden, um langfristige Abhängigkeiten zu lernen.
Um Video- und Audiosignale zu verarbeiten und an längere Video-/Audioeingänge anzupassen, werden diese in (zeitlich grob synchronisierte) kleine Stücke geteilt und dann gemeinsame audiovisuelle Darstellungen durch „Combiner“ erlernt. . Die zweite Komponente verarbeitet Kontext oder zeitlich falsch ausgerichtete Signale wie globale Textinformationen, die oft noch kontinuierlich sind. Es ist außerdem autoregressiv und nutzt den kombinierten latenten Raum als Queraufmerksamkeitseingabe.
 Die Lernkomponente enthält Video und Audio und ihre Parameter sind 3B, während die Komponente ohne Audio 2,9B beträgt. Unter diesen werden die meisten Parameter in autoregressiven Audio- und Videomodellen verwendet. Mirasol3B verarbeitet normalerweise Videos mit 128 Bildern und kann aufgrund des Designs der Partition und der „Combiner“-Modellarchitektur auch längere Videos verarbeiten, indem mehr Bilder hinzugefügt oder die Größe und Anzahl der Blöcke usw. erhöht werden. Nur die Parameter werden leicht erhöht, wodurch das Problem gelöst wird, dass längere Videos mehr Parameter und größeren Speicher erfordern.
Die Lernkomponente enthält Video und Audio und ihre Parameter sind 3B, während die Komponente ohne Audio 2,9B beträgt. Unter diesen werden die meisten Parameter in autoregressiven Audio- und Videomodellen verwendet. Mirasol3B verarbeitet normalerweise Videos mit 128 Bildern und kann aufgrund des Designs der Partition und der „Combiner“-Modellarchitektur auch längere Videos verarbeiten, indem mehr Bilder hinzugefügt oder die Größe und Anzahl der Blöcke usw. erhöht werden. Nur die Parameter werden leicht erhöht, wodurch das Problem gelöst wird, dass längere Videos mehr Parameter und größeren Speicher erfordern.
Experimente und Ergebnisse
Die Studie bewertete Mirasol3B anhand des Standard-VideoQA-Benchmarks, des VideoQA-Benchmarks für lange Videos und des Audio+Video-Benchmarks.
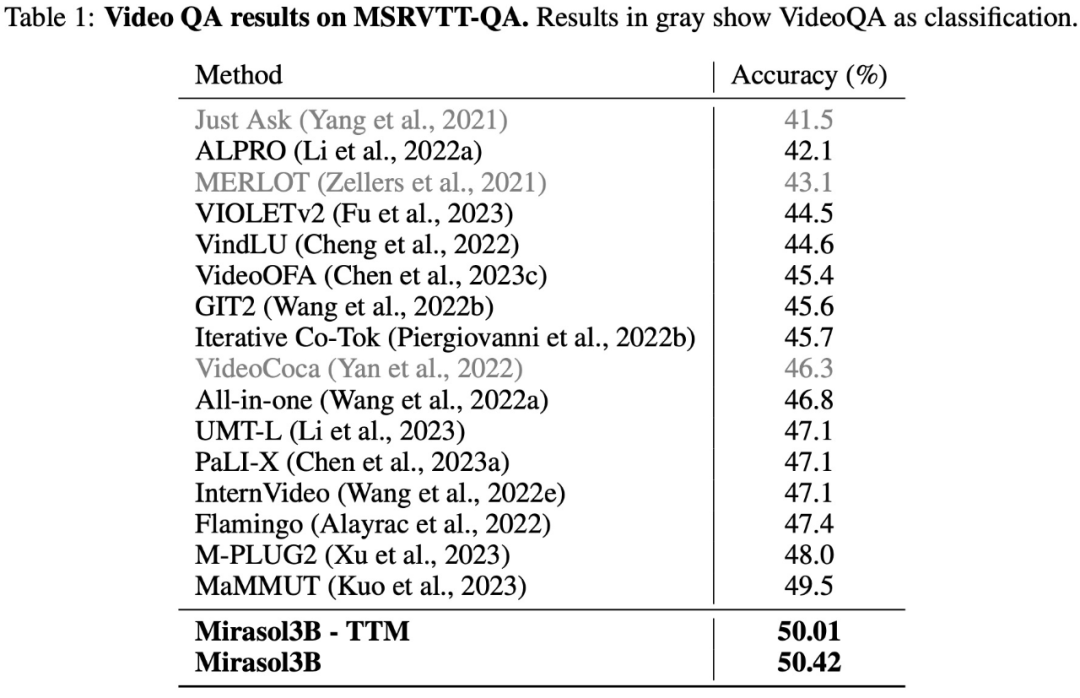
Die Testergebnisse für den VideoQA-Datensatz MSRVTTQA sind in Tabelle 1 unten aufgeführt. Mirasol3B übertrifft das aktuelle SOTA-Modell sowie größere Modelle wie PaLI-X und Flamingo.
In Bezug auf lange Videofragen und -antworten testete und bewertete diese Studie Mirasol3B anhand der ActivityNet-QA- und NExTQA-Datensätze. Die Ergebnisse sind in Tabelle 2 unten aufgeführt:

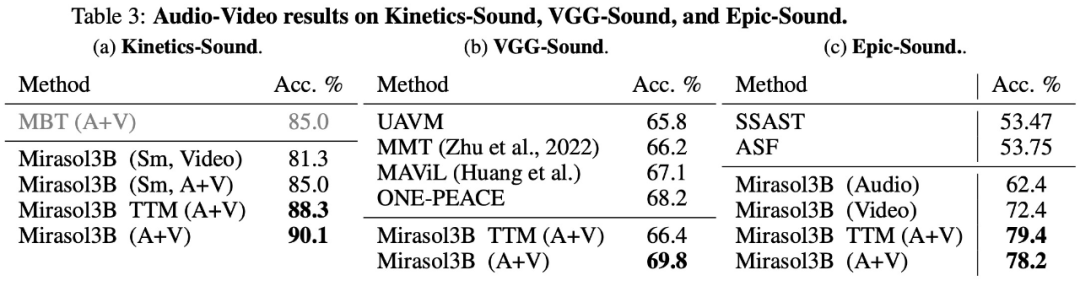
In der Am Ende wurden die Studien KineticsSound, VGG-Sound und Epic-Sound für das Audio-Video-Benchmarking ausgewählt und die Open-Generation-Bewertung übernommen. Die experimentellen Ergebnisse sind in Tabelle 3 unten aufgeführt:
Interessierte Leser können den Originaltext des Artikels lesen, um mehr über den Forschungsinhalt zu erfahren.
Das obige ist der detaillierte Inhalt vonKleiner Maßstab, hohe Effizienz: DeepMind bringt multimodale Lösung Mirasol 3B auf den Markt. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Welche sind die am häufigsten verwendeten relationalen Datenbanken?
- Welche Art von Speicher verliert Daten, wenn die Stromversorgung unterbrochen wird?
- So extrahieren und summieren Sie Daten, die demselben Namen entsprechen
- Googles führender KI-Experte schließt sich OpenAI an und warnt Google davor, ChatGPT-Daten zum Trainieren von Bard zu verwenden
- Anwendung und Erforschung der Branchensuche basierend auf einem vorab trainierten Sprachmodell