
Heim >Technologie-Peripheriegeräte >KI >LLMLingua: Integrieren Sie LlamaIndex, komprimieren Sie Hinweise und stellen Sie effiziente Inferenzdienste für große Sprachmodelle bereit
LLMLingua: Integrieren Sie LlamaIndex, komprimieren Sie Hinweise und stellen Sie effiziente Inferenzdienste für große Sprachmodelle bereit

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBnach vorne
- 2023-11-27 17:13:551013Durchsuche
Das Aufkommen großer Sprachmodelle (LLM) hat Innovationen in mehreren Bereichen angeregt. Die zunehmende Komplexität von Eingabeaufforderungen, die durch Strategien wie CoT-Eingabeaufforderungen (Chain-of-Think) und kontextuelles Lernen (ICL) vorangetrieben werden, stellt jedoch rechnerische Herausforderungen dar. Diese langwierigen Eingabeaufforderungen erfordern erhebliche Ressourcen für die Argumentation und erfordern daher effiziente Lösungen. In diesem Artikel wird die Integration von LLMLingua mit dem proprietären LlamaIndex vorgestellt, um eine effiziente Inferenz durchzuführen. Methoden zur Fähigkeit, Schlüsselinformationen wahrzunehmen.
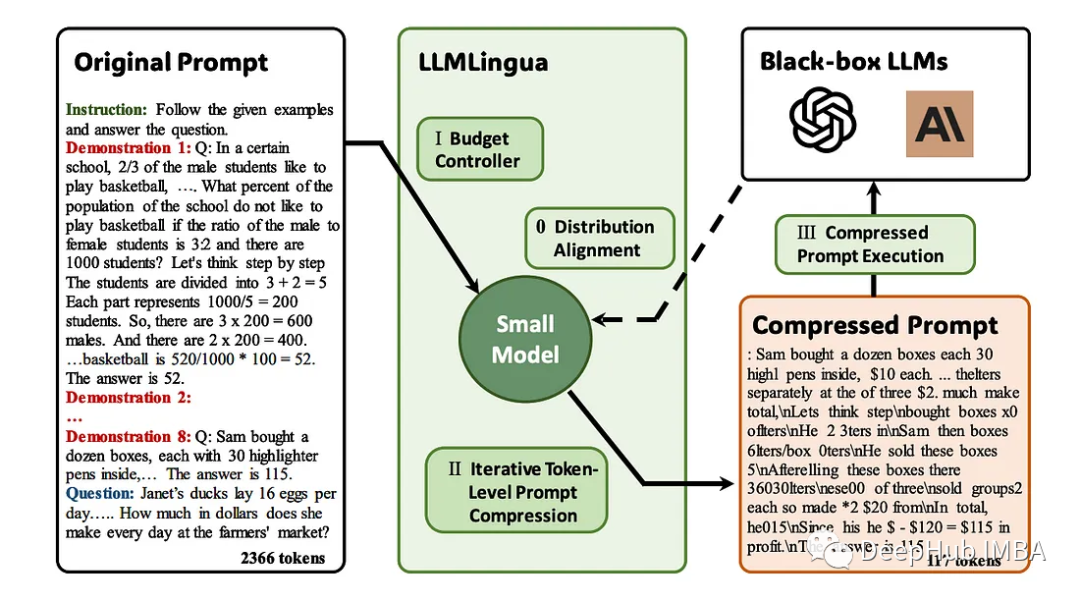 LLMLingua arbeitet mit llamindex zusammen
LLMLingua arbeitet mit llamindex zusammen
LLMLingua erweist sich als bahnbrechende Lösung für ausführliche Eingabeaufforderungen in LLM-Anwendungen. Dieser Ansatz konzentriert sich auf die Komprimierung langer Eingabeaufforderungen bei gleichzeitiger Gewährleistung der semantischen Integrität und einer Erhöhung der Inferenzgeschwindigkeit. Es kombiniert verschiedene Komprimierungsstrategien, um eine subtile Möglichkeit zu bieten, Hinweislänge und Recheneffizienz in Einklang zu bringen.
Folgende Vorteile der Integration von LLMLingua und LlamaIndex:
Die Integration von LLMLingua und LlamaIndex markiert für llm einen wichtigen Schritt in der schnellen Optimierung. LlamaIndex ist ein spezialisiertes Repository, das voroptimierte Hinweise enthält, die auf eine Vielzahl von LLM-Anwendungen zugeschnitten sind. Durch diese Integration kann LLMLingua auf einen umfangreichen Satz domänenspezifischer, fein abgestimmter Hinweise zugreifen und so seine Hinweiskomprimierungsfunktionen verbessern.
LLMLingua verbessert die Effizienz von LLM-Anwendungen durch Synergien mit der Bibliothek von Optimierungshinweisen von LlamaIndex. Mithilfe der speziellen Hinweise von LLAMA kann LLMLingua seine Komprimierungsstrategie optimieren, um sicherzustellen, dass der domänenspezifische Kontext erhalten bleibt und gleichzeitig die Länge der Hinweise reduziert wird. Diese Zusammenarbeit beschleunigt die Inferenz erheblich und behält gleichzeitig wichtige Domänennuancen bei.
Die Integration von LLMLingua mit LlamaIndex erweitert seine Wirkung auf umfangreiche LLM-Anwendungen. Durch die Nutzung der Expertentipps von LLAMA hat LLMLingua seine Komprimierungstechnologie optimiert und so den Rechenaufwand für die Verarbeitung langer Tipps reduziert. Diese Integration beschleunigt nicht nur die Inferenz, sondern gewährleistet auch die Beibehaltung kritischer domänenspezifischer Informationen.
Workflow zwischen LLMLingua und LlamaIndex
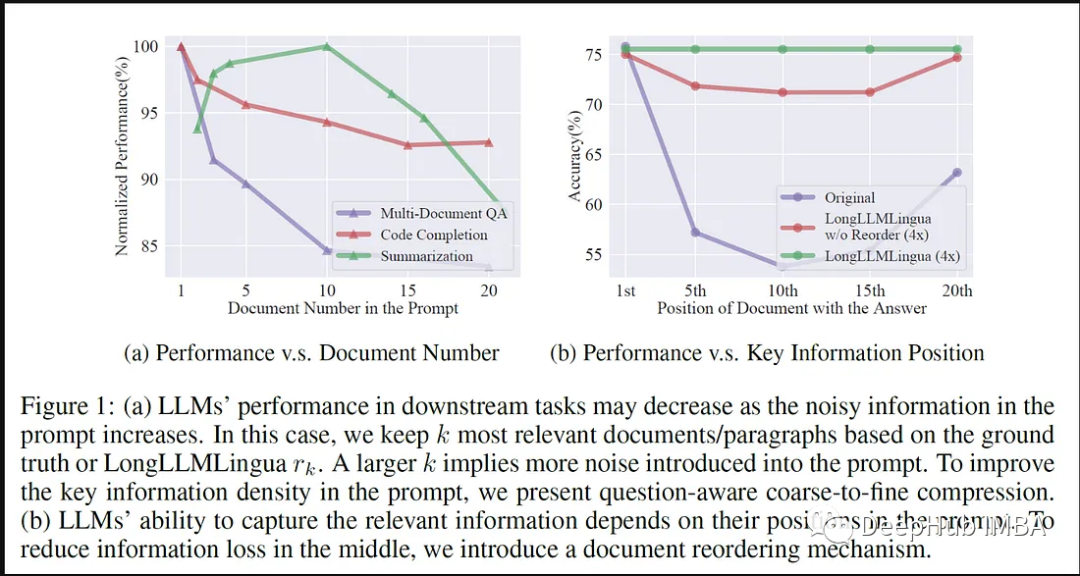 Die Verwendung von LlamaIndex zur Implementierung von LLMLingua erfordert eine Reihe strukturierter Prozesse, einschließlich der Verwendung einer speziellen Hinweisbibliothek, um eine effiziente Hinweiskomprimierung und eine verbesserte Inferenzgeschwindigkeit zu erreichen
Die Verwendung von LlamaIndex zur Implementierung von LLMLingua erfordert eine Reihe strukturierter Prozesse, einschließlich der Verwendung einer speziellen Hinweisbibliothek, um eine effiziente Hinweiskomprimierung und eine verbesserte Inferenzgeschwindigkeit zu erreichen
1 . Framework-Integration
Zuerst müssen Sie eine Verbindung zwischen LLMLingua und LlamaIndex herstellen. Dazu gehören Zugriffsrechte, API-Konfiguration und der Aufbau von Verbindungen für einen zeitnahen Abruf.
2. Abruf von Tipps zur Voroptimierung
LlamaIndex dient als spezialisiertes Repository mit Tipps zur Voroptimierung, die auf verschiedene LLM-Anwendungen zugeschnitten sind. LLMLingua greift auf dieses Repository zu, ruft domänenspezifische Hinweise ab und nutzt diese Hinweise zur Komprimierung
3. Hinweiskomprimierungstechnologie
LLMLingua verwendet seine Hinweiskomprimierungsmethode, um die abgerufenen Hinweise zu vereinfachen. Der Schwerpunkt dieser Techniken liegt auf der Komprimierung langer Eingabeaufforderungen bei gleichzeitiger Gewährleistung der semantischen Konsistenz, wodurch die Inferenzgeschwindigkeit erhöht wird, ohne den Kontext oder die Relevanz zu beeinträchtigen.
4. Feinabstimmung der Komprimierungsstrategie
LLMLlingua optimiert seine Komprimierungsstrategie basierend auf speziellen Tipps, die es von LlamaIndex erhält. Dieser Verfeinerungsprozess stellt sicher, dass domänenspezifische Nuancen erhalten bleiben und gleichzeitig die Eingabeaufforderungslänge effizient reduziert wird.
5. Ausführung und Inferenz
Nach der Komprimierung mit der benutzerdefinierten Strategie von LLMLingua und in Kombination mit den Voroptimierungshinweisen von LlamaIndex können die resultierenden Hinweise für LLM-Inferenzaufgaben verwendet werden. In dieser Phase führen wir Komprimierungshinweise innerhalb des LLM-Frameworks durch, um eine effiziente kontextbezogene Inferenz zu ermöglichen. Dieser Prozess umfasst die Verbesserung des Komprimierungsalgorithmus, die Optimierung des Abrufs von Hinweisen aus LlamaIndex und die Feinabstimmung der Integration, um Konsistenz und verbesserte Leistung komprimierter Hinweise und LLM-Inferenz sicherzustellen.
7. Tests und Verifizierung
Bei Bedarf können auch Tests und Verifizierungen durchgeführt werden, sodass die Effizienz und Wirksamkeit der Integration von LLMLingua und LlamaIndex bewertet werden kann. Leistungsmetriken werden ausgewertet, um sicherzustellen, dass Komprimierungshinweise die semantische Integrität bewahren und die Inferenzgeschwindigkeit erhöhen, ohne die Genauigkeit zu beeinträchtigen.
Code-Implementierung
Wir beginnen, uns mit der Code-Implementierung von LLMLingua und LlamaIndex zu befassen
Installationspaket:
# Install dependency. !pip install llmlingua llama-index openai tiktoken -q # Using the OAI import openai openai.api_key = "<insert_openai_key>"</insert_openai_key>Daten abrufen:
!wget "https://www.dropbox.com/s/f6bmb19xdg0xedm/paul_graham_essay.txt?dl=1" -O paul_graham_essay.txt
Modell laden:
from llama_index import (VectorStoreIndex,SimpleDirectoryReader,load_index_from_storage,StorageContext, ) # load documents documents = SimpleDirectoryReader(input_files=["paul_graham_essay.txt"] ).load_data()Vektorspeicher:
index = VectorStoreIndex.from_documents(documents) retriever = index.as_retriever(similarity_top_k=10) question = "Where did the author go for art school?" # Ground-truth Answer answer = "RISD" contexts = retriever.retrieve(question) contexts = retriever.retrieve(question) context_list = [n.get_content() for n in contexts] len(context_list) #Output #10Ursprüngliche Eingabeaufforderung und Rückgabe
# The response from original prompt from llama_index.llms import OpenAI llm = OpenAI(model="gpt-3.5-turbo-16k") prompt = "\n\n".join(context_list + [question]) response = llm.complete(prompt) print(str(response)) #Output The author went to the Rhode Island School of Design (RISD) for art school.LLMLingua einrichten
from llama_index.query_engine import RetrieverQueryEngine from llama_index.response_synthesizers import CompactAndRefine from llama_index.indices.postprocessor import LongLLMLinguaPostprocessor node_postprocessor = LongLLMLinguaPostprocessor(instruction_str="Given the context, please answer the final question",target_token=300,rank_method="longllmlingua",additional_compress_kwargs={"condition_compare": True,"condition_in_question": "after","context_budget": "+100","reorder_context": "sort", # enable document reorder,"dynamic_context_compression_ratio": 0.3,}, )
通过LLMLingua进行压缩
retrieved_nodes = retriever.retrieve(question) synthesizer = CompactAndRefine() from llama_index.indices.query.schema import QueryBundle # postprocess (compress), synthesize new_retrieved_nodes = node_postprocessor.postprocess_nodes(retrieved_nodes, query_bundle=QueryBundle(query_str=question) ) original_contexts = "\n\n".join([n.get_content() for n in retrieved_nodes]) compressed_contexts = "\n\n".join([n.get_content() for n in new_retrieved_nodes]) original_tokens = node_postprocessor._llm_lingua.get_token_length(original_contexts) compressed_tokens = node_postprocessor._llm_lingua.get_token_length(compressed_contexts)
打印2个结果对比:
print(compressed_contexts) print() print("Original Tokens:", original_tokens) print("Compressed Tokens:", compressed_tokens) print("Comressed Ratio:", f"{original_tokens/(compressed_tokens + 1e-5):.2f}x")
打印的结果如下:
next Rtm's advice hadn' included anything that. I wanted to do something completely different, so I decided I'd paint. I wanted to how good I could get if I focused on it. the day after stopped on YC, I painting. I was rusty and it took a while to get back into shape, but it was at least completely engaging.1] I wanted to back RISD, was now broke and RISD was very expensive so decided job for a year and return RISD the fall. I got one at Interleaf, which made software for creating documents. You like Microsoft Word? Exactly That was I low end software tends to high. Interleaf still had a few years to live yet. [] the Accademia wasn't, and my money was running out, end year back to thelot the color class I tookD, but otherwise I was basically myself to do that for in993 I dropped I aroundidence bit then my friend Par did me a big A rent-partment building New York. Did I want it Itt more my place, and York be where the artists. wanted [For when you that ofs you big painting of this type hanging in the apartment of a hedge fund manager, you know he paid millions of dollars for it. That's not always why artists have a signature style, but it's usually why buyers pay a lot for such work. [6] Original Tokens: 10719 Compressed Tokens: 308 Comressed Ratio: 34.80x
验证输出:
response = synthesizer.synthesize(question, new_retrieved_nodes) print(str(response)) #Output #The author went to RISD for art school.
总结
LLMLingua与LlamaIndex的集成证明了协作关系在优化大型语言模型(LLM)应用程序方面的变革潜力。这种协作彻底改变了即时压缩方法和推理效率,为上下文感知、简化的LLM应用程序铺平了道路。
这种集成不仅可以提升推理速度,而且可以保证在压缩提示中保持语义的完整性。通过对基于LlamaIndex特定领域提示的压缩策略进行微调,我们平衡了提示长度的减少和基本上下文的保留,从而提高了LLM推理的准确性
从本质上讲,LLMLingua与LlamaIndex的集成超越了传统的提示压缩方法,为未来大型语言模型应用程序的优化、上下文准确和有效地针对不同领域进行定制奠定了基础。这种协作集成预示着大型语言模型应用程序领域中效率和精细化的新时代的到来。
Das obige ist der detaillierte Inhalt vonLLMLingua: Integrieren Sie LlamaIndex, komprimieren Sie Hinweise und stellen Sie effiziente Inferenzdienste für große Sprachmodelle bereit. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Was ist künstliche Python-Intelligenz?
- Der Zweck künstlicher Intelligenz besteht darin, Maschinen leistungsfähig zu machen
- Der ICML-Aufruf zur Einreichung von Beiträgen verbietet die Verwendung großer Sprachmodelle. LeCun leitete weiter: Können kleine und mittlere Modelle verwendet werden?
- Studie zeigt, dass große Sprachmodelle Probleme mit dem logischen Denken haben
- Es gibt Hinweise darauf, dass große Sprachmodelle ≠ zufällige Papageien tatsächlich Semantik lernen können.