
Heim >Technologie-Peripheriegeräte >KI >Es gibt Hinweise darauf, dass große Sprachmodelle ≠ zufällige Papageien tatsächlich Semantik lernen können.
Es gibt Hinweise darauf, dass große Sprachmodelle ≠ zufällige Papageien tatsächlich Semantik lernen können.

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBnach vorne
- 2023-05-23 08:01:051090Durchsuche
Während große vorab trainierte Sprachmodelle (LLMs) eine deutlich verbesserte Leistung bei einer Reihe nachgelagerter Aufgaben gezeigt haben, stellt sich die Frage, ob sie wirklich die Semantik des Textes verstehen, den sie verwenden und generieren?
Die KI-Community ist in dieser Frage seit langem tief gespalten. Eine Vermutung ist, dass Sprachmodelle, die ausschließlich auf der Form der Sprache trainiert werden (z. B. die bedingte Verteilung von Token in einem Trainingskorpus), keine Semantik erwerben. Stattdessen generieren sie lediglich Text auf der Grundlage oberflächlicher statistischer Korrelationen, die aus Trainingsdaten gewonnen werden, wobei ihre starken Emergenzfähigkeiten auf die Größe des Modells und der Trainingsdaten zurückzuführen sind. Diese Leute bezeichnen LLM als „zufälligen Papagei“.
Aber es gibt einige Leute, die dieser Ansicht nicht zustimmen. Eine kürzlich durchgeführte Studie zeigte, dass etwa 51 % der Befragten der NLP-Community zustimmten, dass „einige generative Modelle, die ausschließlich auf Text trainiert werden, bei ausreichenden Daten und Rechenressourcen die Natur auf sinnvolle Weise verstehen können (über statistische Korrelationen auf Oberflächenebene hinaus, einschließlich Verständnis). der Semantik und Konzepte hinter der Sprache)“.
Um diese unbeantwortete Frage zu untersuchen, führten Forscher vom MIT CSAIL eine detaillierte Studie durch.

Papieradresse: https://paperswithcode.com/paper/evidence-of-meaning-in-lingual-models
Das in dieser Studie verwendete Sprachmodell wird nur trainiert zu Text werden Ein Modell, das das nächste Token vorhersagt und zwei Hypothesen formuliert:
- H1: LMs, die ausschließlich durch Vorhersagen des nächsten Tokens auf Text trainiert werden, sind grundsätzlich durch die Wiederholung statistischer Korrelationen auf Oberflächenebene in ihrem Trainingskorpus eingeschränkt
- H2LM ist nicht in der Lage, dem Text, den es verarbeitet und generiert, eine Bedeutung zuzuordnen.
Um die Richtigkeit der beiden Hypothesen H1 und H2 zu untersuchen, wendet diese Studie die Sprachmodellierung auf die Programmsyntheseaufgabe an, d. h. die Synthese von Programmen anhand der formalen Spezifikation von Eingabe- und Ausgabebeispielen. Diese Studie verfolgt diesen Ansatz vor allem deshalb, weil die Bedeutung (und Korrektheit) eines Programms vollständig durch die Semantik der Programmiersprache bestimmt wird.
Konkret trainiert diese Studie ein Sprachmodell (LM) auf einem Korpus von Programmen und deren Spezifikationen und verwendet dann einen linearen Klassifikator, um den verborgenen Zustand des LM für die semantische Darstellung des Programms zu erkennen. Die Studie ergab, dass die Fähigkeit des Detektors, Semantik zu extrahieren, bei der Initialisierung stochastisch ist und dann während des Trainings einen Phasenwechsel durchläuft, der stark mit der Fähigkeit des LM korreliert, korrekte Programme zu generieren, ohne die Spezifikation gesehen zu haben. Darüber hinaus präsentiert die Studie Ergebnisse eines interventionellen Experiments, die zeigen, dass Semantik in Modellzuständen dargestellt wird (und nicht über Sonden gelernt wird).
Zu den Hauptbeiträgen dieser Forschung gehören:
1 Experimentelle Ergebnisse zeigen, dass in LM sinnvolle Darstellungen erscheinen, die die Aufgabe der Vorhersage des nächsten Tokens übernehmen. Konkret verwendet die Studie einen trainierten LM, um anhand mehrerer Eingabe-Ausgabe-Beispiele Programme zu generieren, und trainiert dann einen linearen Detektor, um Informationen über den Programmstatus aus dem Modellstatus zu extrahieren. Forscher fanden heraus, dass die interne Darstellung die folgende lineare Kodierung enthält: (1) abstrakte Semantik (abstrakte Interpretation) – Verfolgung spezifizierter Eingaben während der Programmausführung (2) zukünftige Programmstatusvorhersagen, die noch nicht generierten Programm-Tokens entsprechen; Während des Trainings entwickeln sich diese linearen Darstellungen der Semantik parallel zur Fähigkeit des LM, während des Trainingsschritts korrekte Programme zu generieren.
2. In dieser Studie wurde eine neuartige Interventionsmethode entwickelt und evaluiert, um den Beitrag von LM und Detektoren bei der Bedeutungsextraktion aus Darstellungen zu untersuchen. Konkret versucht diese Studie zu analysieren, welche der folgenden beiden Fragen zutrifft: (1) LM-Darstellungen enthalten reine (syntaktische) Transkripte, während der Detektor lernt, die Transkripte zu interpretieren, um auf die Bedeutung zu schließen; (2) LM-Darstellungen enthalten einfach semantische Zustände Bedeutung aus semantischen Zuständen extrahieren. Die experimentellen Ergebnisse zeigen, dass die LM-Darstellung tatsächlich an der ursprünglichen Semantik ausgerichtet ist (und nicht nur einige lexikalische und syntaktische Inhalte kodiert), was zeigt, dass Hypothese H2 falsch ist.
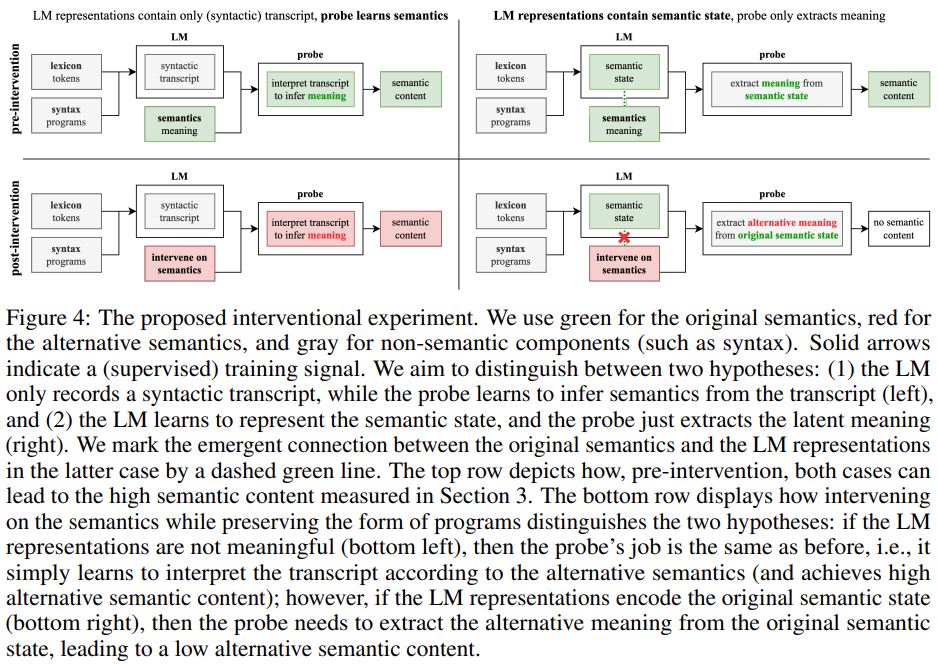
3. Diese Studie zeigt, dass sich die Ausgabe von LM von der Trainingsverteilung unterscheidet, insbesondere darin, dass LM tendenziell kürzere Programme generiert als die im Trainingssatz (und dennoch korrekt sind). Obwohl sich die Fähigkeit von LM, korrekte Programme zu synthetisieren, verbessert hat, bleibt die Ratlosigkeit von LM hinsichtlich der Programme im Trainingssatz hoch, was darauf hindeutet, dass Hypothese H1 falsch ist.
Insgesamt schlägt diese Studie einen Rahmen für die empirische Untersuchung von LM vor, der auf der Semantik von Programmiersprachen basiert. Dieser Ansatz ermöglicht es uns, Konzepte anhand der präzisen formalen Semantik der zugrunde liegenden Programmiersprache zu definieren, zu messen und damit zu experimentieren und so zum Verständnis der neuen Fähigkeiten aktueller LMs beizutragen.
Forschungshintergrund
Diese Forschung verwendet Tracing-Semantik als Programmbedeutungsmodell. Als grundlegendes Thema der Programmiersprachentheorie untersucht die formale Semantik, wie Strings in einer Sprache formal Semantik zugewiesen werden kann. Das in dieser Studie verwendete semantische Modell besteht darin, die Ausführung eines Programms zu verfolgen: Bei einer Reihe von Eingaben (d. h. Variablenzuweisungen) wird die Bedeutung eines (syntaktischen) Programms durch semantische Werte identifiziert, die aus den Ausdrücken und der Spur berechnet werden wird basierend auf den Eingaben ausgeführt. Eine vom Programm generierte Folge von Zwischenwerten.
Es gibt mehrere wichtige Gründe für die Verwendung von Tracing-Trajektorien für Programmbedeutungsmodelle: Erstens steht die Fähigkeit, einen Codeabschnitt genau zu verfolgen, in direktem Zusammenhang mit der Fähigkeit, den Code zu interpretieren; zweitens legt die Informatikausbildung auch Wert auf Tracing Eine wichtige Methode zum Verstehen der Programmentwicklung und zum Auffinden von Argumentationsfehlern. Drittens basiert die professionelle Programmentwicklung auf einem Trace-basierten Debugger (Dbugger).
Der in dieser Studie verwendete Trainingssatz enthält 1 Million zufällig ausgewählte Karel-Programme. In den 1970er Jahren entwarf der Absolvent der Stanford University, Rich Pattis, eine Programmierumgebung, die es Studenten ermöglichte, Robotern beizubringen, einfache Probleme zu lösen. Dieser Roboter wurde Karel-Roboter genannt.
Diese Studie erstellt ein Referenzprogramm von Trainingsstichproben durch Zufallsstichproben, erfasst dann 5 Zufallseingaben und führt das Programm aus, um die entsprechenden 5 Ausgaben zu erhalten. Der LM ist darauf trainiert, die nächste Token-Vorhersage für einen Probenkorpus durchzuführen. Zum Zeitpunkt des Tests stellt diese Studie nur Eingabe- und Ausgabepräfixe für LM bereit und verwendet gierige Dekodierung, um das Programm zu vervollständigen. Abbildung 1 unten zeigt den Abschluss eines tatsächlichen Referenzprogramms und des trainierten LM.
Diese Studie trainierte ein vorgefertigtes Transformer-Modell, um eine Vorhersage des nächsten Tokens für den Datensatz durchzuführen. Nach 64.000 Trainingsschritten und etwa 1,5 Epochen erreichte der schließlich trainierte LM auf dem Testsatz eine Generierungsgenauigkeit von 96,4 %. Alle 2000 Trainingsschritte erfasste die Studie einen Trace-Datensatz. Für jeden Trainingstrajektoriendatensatz trainiert die Studie einen linearen Detektor, um den Programmstatus anhand des Modellstatus vorherzusagen.
Die Entstehung von Bedeutung
Die Forscher untersuchten die folgende Hypothese: Beim Training eines Sprachmodells zur Durchführung der nächsten Token-Vorhersage erscheint die Darstellung des semantischen Zustands als Nebenprodukt im Modellzustand. Wenn man bedenkt, dass das endgültig trainierte Sprachmodell eine Generierungsgenauigkeit von 96,4 % erreicht hat, wäre diese Hypothese bei Ablehnung mit H2 konsistent, d. h. das Sprachmodell hat gelernt, „nur“ Oberflächenstatistiken zu verwenden, um konsistent korrekte Programme zu generieren.
Um diese Hypothese zu testen, trainierten die Forscher einen linearen Detektor, um den semantischen Zustand aus dem Modellzustand als 5 unabhängige 4-Wege-Aufgaben zu extrahieren (jede Eingabe zeigt in eine Richtung), wie in Abschnitt 2.2 beschrieben.
Die Bedeutungsentstehung korreliert positiv mit der Generierungsgenauigkeit
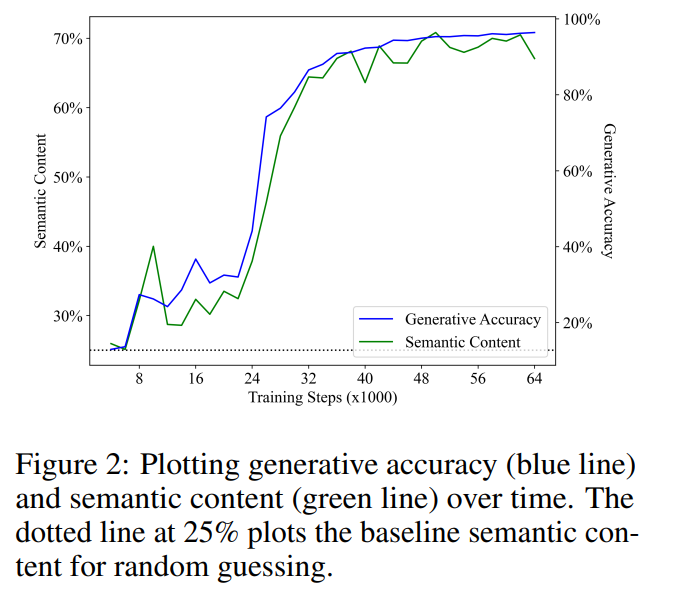
Abbildung 2 zeigt die Hauptergebnisse. Unsere erste Beobachtung ist, dass der semantische Inhalt bei der Grundleistung des Zufallsratens (25 %) beginnt und während des Trainings deutlich zunimmt. Dieses Ergebnis zeigt, dass der verborgene Zustand des Sprachmodells tatsächlich eine (lineare) Kodierung des semantischen Zustands enthält, und entscheidend ist, dass diese Bedeutung in einem Sprachmodell entsteht, das ausschließlich zur Durchführung von Vorhersagen des nächsten Tokens für Text verwendet wird.
Es wurde eine lineare Regression zwischen der Generierungsgenauigkeit und dem semantischen Inhalt durchgeführt. Die beiden zeigten eine unerwartet starke und statistisch signifikante lineare Korrelation im Trainingsschritt (R2 = 0,968, p
Darstellung ist eine Vorhersage zukünftiger Programmsemantik
Im vorherigen Abschnitt wurde erläutert, ob ein Sprachmodell die Bedeutung des von ihm generierten Textes darstellen kann. Die Ergebnisse dieser Arbeit geben eine positive Antwort auf die Frage, ob Sprachmodelle in der Lage sind, die generierten Programme (abstrakt) zu erklären. Der Interpreter ist jedoch nicht dasselbe wie der Synthesizer, und die Fähigkeit zu verstehen allein reicht nicht aus, um etwas zu generieren. Was die Entstehung der menschlichen Sprache betrifft, besteht weitgehend Konsens darüber, dass Sprache aus einer nonverbalen Botschaft im Kopf entsteht, die dann in eine Äußerung umgewandelt wird, die das ursprüngliche Konzept widerspiegelt. Die Forscher gehen davon aus, dass der Generierungsprozess des trainierten Sprachmodells einem ähnlichen Mechanismus folgt, d. h. die Darstellung des Sprachmodells kodiert die Semantik des noch nicht generierten Textes.
Um diese Hypothese zu testen, trainierten sie einen linearen Detektor mit der gleichen Methode wie oben, um zukünftige semantische Zustände vorherzusagen, die aus dem Modellzustand abgeleitet wurden. Beachten Sie, dass der zukünftige semantische Zustand ebenfalls deterministisch ist und die Aufgabe somit genau definiert ist, da sie eine gierige Decodierungsstrategie verwenden.
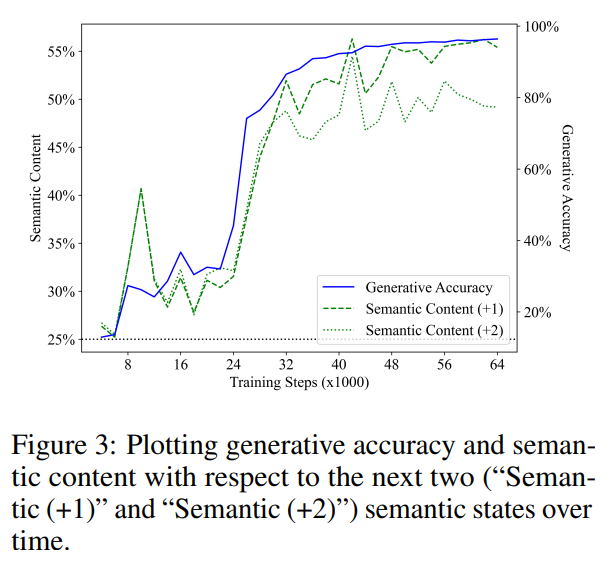
Abbildung 3 zeigt die Leistung des linearen Detektors bei der Vorhersage des semantischen Zustands der nächsten Schritte 1 und 2 (die grüne Segmentlinie steht für „Semantik (+1)“, die grüne gepunktete Linie steht für „Semantik (+2)“) "). Ähnlich wie bei früheren Ergebnissen begann die Leistung des Detektors mit einer Basislinie zufälliger Schätzungen und verbesserte sich dann mit dem Training erheblich. Außerdem stellten sie fest, dass der semantische Inhalt zukünftiger Zustände während des Trainingsschritts eine starke Korrelation mit der Generierungsgenauigkeit (blaue Linie) aufwies. Sex. Die durch lineare Regressionsanalyse des semantischen Inhalts und der Generierungsgenauigkeit erhaltenen R2-Werte betragen 0,919 bzw. 0,900, was dem semantischen Status von 1 Schritt und 2 Schritten in der Zukunft entspricht, und die p-Werte beider liegen unter 0,001.
Sie berücksichtigten auch die Annahme, dass die Darstellung des Modells nur den aktuellen semantischen Zustand kodiert und der Detektor einfach den zukünftigen semantischen Zustand aus dem aktuellen semantischen Zustand vorhersagt. Um diese Hypothese zu testen, berechneten sie einen optimalen Klassifikator, der die Blickrichtung der Grundwahrheit im aktuellen Programm auf eine von vier Blickrichtungen in zukünftigen Programmen abbildet.
Es ist zu beachten, dass bei drei der fünf Vorgänge die Blickrichtung beibehalten wird und der nächste Token gleichmäßig abgetastet wird. Daher erwarteten sie, dass für die Situation 1 Schritt in die Zukunft der optimale Klassifikator zur Vorhersage des zukünftigen semantischen Zustands eine Genauigkeit von 60 % erreichen sollte, indem er vorhersagt, dass die Blickrichtung unverändert bleibt. Tatsächlich fanden sie durch direkte Anpassung des Testsatzes heraus, dass die Obergrenzen für die Vorhersage zukünftiger semantischer Zustände aus dem aktuellen semantischen Zustand bei 62,2 % bzw. 40,7 % liegen (entsprechend den Fällen 1 Schritt und 2 Schritte in die Zukunft). Im Vergleich dazu waren die Detektoren bei der Vorhersage zukünftiger Zustände zu 68,4 % bzw. 61,0 % genau, vorausgesetzt, der Detektor hat den aktuellen Zustand korrekt vorhergesagt.
Dies zeigt, dass die Fähigkeit des Detektors, zukünftige semantische Zustände aus Modellzuständen zu extrahieren, nicht allein aus Darstellungen aktueller semantischer Zustände abgeleitet werden kann. Daher zeigen ihre Ergebnisse, dass Sprachmodelle lernen, die Bedeutung von Token darzustellen, die noch nicht generiert wurden, was die Idee zurückweist, dass Sprachmodelle keine Bedeutung lernen können (H2), und auch zeigt, dass der Generierungsprozess nicht auf reinen Oberflächenstatistiken basiert (H1).
Die generierte Ausgabe unterscheidet sich von der Trainingsverteilung
Als nächstes liefern die Forscher Beweise zur Widerlegung von H1, indem sie die vom trainierten Sprachmodell generierte Programmverteilung mit der Programmverteilung im Trainingssatz vergleichen. Wenn H1 zutrifft, gehen sie davon aus, dass die beiden Verteilungen ungefähr gleich sein sollten, da das Sprachmodell lediglich die statistischen Korrelationen des Textes im Trainingssatz wiederholt.
Abbildung 6a zeigt die durchschnittliche Länge von LM-generierten Programmen im Zeitverlauf (durchgezogene blaue Linie) im Vergleich zur durchschnittlichen Länge des Referenzprogramms im Trainingssatz (gestrichelte rote Linie). Sie fanden einen statistisch signifikanten Unterschied, der darauf hindeutet, dass sich die Ausgabeverteilung des LM tatsächlich von der Programmverteilung in seinem Trainingssatz unterscheidet. Dies widerspricht dem in H1 erwähnten Punkt, dass LM nur statistische Korrelationen in seinen Trainingsdaten reproduzieren kann.
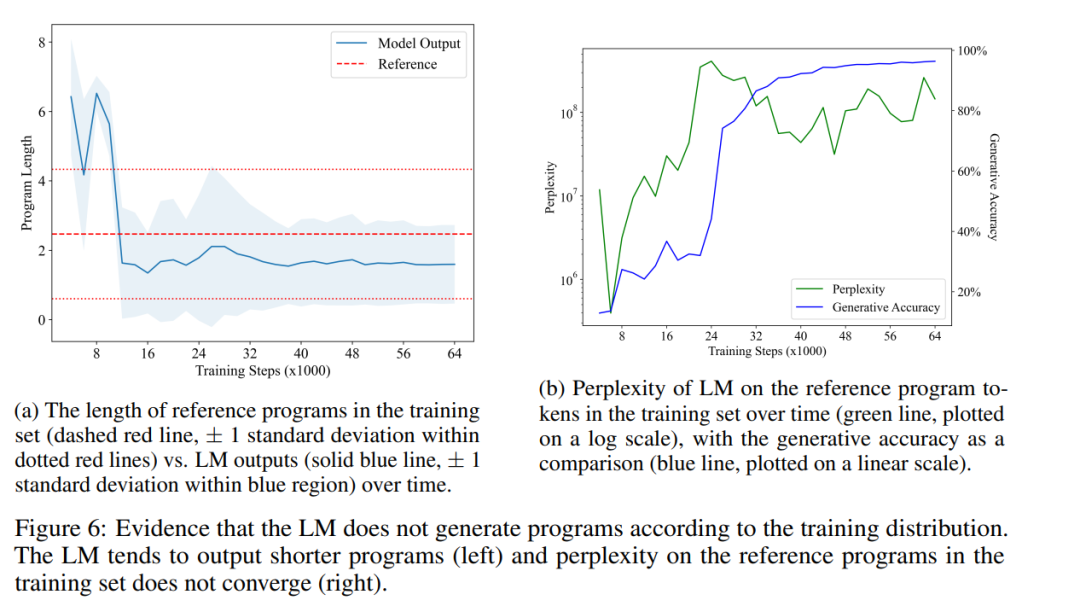
Schließlich haben sie auch gemessen, wie sich die Ratlosigkeit von LM auf dem Programm im Trainingsset im Laufe der Zeit verändert hat. Abbildung 6b zeigt ihre Ergebnisse. Wie man sieht, lernt LM nie, die Verteilung der Programme im Trainingssatz gut anzupassen, was H1 weiter widerlegt. Dies kann daran liegen, dass die zufällig ausgewählten Programme im Trainingssatz viele No-Op-Anweisungen enthalten, während LM es vorzieht, prägnantere Programme zu generieren. Interessanterweise scheint ein starker Anstieg der Ratlosigkeit – wenn LM über das Imitationsstadium hinausgeht – zu Verbesserungen der Generierungsgenauigkeit (und des semantischen Inhalts) zu führen. Da das Problem der Programmäquivalenz eng mit der Programmsemantik zusammenhängt, zeigt die Fähigkeit von LM, kurze und korrekte Programme zu generieren, dass es tatsächlich einige Aspekte der Semantik gelernt hat.
Einzelheiten entnehmen Sie bitte dem Originalpapier.
Das obige ist der detaillierte Inhalt vonEs gibt Hinweise darauf, dass große Sprachmodelle ≠ zufällige Papageien tatsächlich Semantik lernen können.. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Technologietrends, die Sie im Jahr 2023 im Auge behalten sollten
- Wie künstliche Intelligenz Rechenzentrumsteams neue Alltagsaufgaben beschert
- Können künstliche Intelligenz oder Automatisierung das Problem der geringen Energieeffizienz in Gebäuden lösen?
- OpenAI-Mitbegründer im Interview mit Huang Renxun: Die Argumentationsfähigkeiten von GPT-4 haben noch nicht die Erwartungen erfüllt
- Dank der OpenAI-Technologie übertrifft Bing von Microsoft Google im Suchverkehr