
Heim >Technologie-Peripheriegeräte >KI >Ein Überblick über visuelle Methoden zur Flugbahnvorhersage
Ein Überblick über visuelle Methoden zur Flugbahnvorhersage

- PHPznach vorne
- 2023-05-22 23:54:161543Durchsuche
Ein aktueller Übersichtsartikel „Trajectory-Prediction With Vision: A Survey“ stammt von Hyundai und Aptivs Unternehmen Motional; er bezieht sich jedoch auf den Übersichtsartikel „Vision-based Intention and Trajectory Prediction in Autonomous Vehicles: A Survey“ der Universität Oxford.
Die Vorhersageaufgabe ist im Wesentlichen in zwei Teile unterteilt: 1) Absicht, eine Klassifizierungsaufgabe, die eine Reihe von Absichtsklassen für den Agenten vorab entwirft, die normalerweise als überwachtes Lernproblem angesehen werden, und die möglichen Klassifizierungsabsichten davon Der Agent muss markiert werden. 2) Die Flugbahn erfordert die Vorhersage einer Reihe möglicher Positionen des Agenten in nachfolgenden zukünftigen Frames, die als Wegpunkte bezeichnet werden. Dies stellt die Interaktion zwischen Agenten und zwischen Agenten und Straßen dar.
Frühere Verhaltensvorhersagemodelle können in drei Kategorien unterteilt werden: physikbasierte, manöverbasierte und Interaktionswahrnehmungsmodelle. Dieser Satz kann wie folgt umgeschrieben werden: Mithilfe der dynamischen Gleichungen des physikalischen Modells werden künstlich steuerbare Bewegungen für verschiedene Arten von Agenten entworfen. Diese Methode kann nicht die potenziellen Zustände der gesamten Situation modellieren, sondern konzentriert sich in der Regel nur auf einen bestimmten Agenten. In der Ära vor Deep Learning war dieser Trend jedoch SOTA. Manöverbasierte Modelle sind Modelle, die auf der Art der vom Agenten erwarteten Bewegung basieren. Ein interaktionsbewusstes Modell ist typischerweise ein auf maschinellem Lernen basierendes System, das für jeden Agenten in der Szene eine paarweise Inferenz durchführt und interaktionsbewusste Vorhersagen für alle dynamischen Agenten generiert. Es besteht ein hoher Grad an Korrelation zwischen verschiedenen Agentenzielen in der Nähe des Tatorts. Die Modellierung komplexer Aufmerksamkeitsmodule für die Agentenbahn kann zu einer besseren Verallgemeinerung führen.
Die Vorhersage zukünftiger Handlungen oder Ereignisse kann implizit ausgedrückt werden, oder ihr zukünftiger Verlauf kann explizit sein. Die Absichten des Agenten können beeinflusst werden durch: a) die eigenen Überzeugungen oder Wünsche (die oft nicht beobachtet werden und daher schwer zu modellieren sind); b) soziale Interaktionen, die auf unterschiedliche Weise modelliert werden können, z. B. durch Pooling, grafische neuronale Netze, Aufmerksamkeit usw.; c) Umgebungsbedingungen wie Straßenlayout, die durch hochauflösende (HD-)Karten codiert werden können; d) Hintergrundinformationen in Form von RGB-Bildrahmen, Lidar-Punktwolken, optischem Fluss, Segmentierungsabbildung usw. Andererseits ist die Flugbahnvorhersage ein anspruchsvolleres Problem, da sie im Gegensatz zur Absichtserkennung eher eine (kontinuierliche) Regression als Klassifizierungsprobleme beinhaltet.
Flugbahn und Absicht müssen vom Interaktionsbewusstsein ausgehen. Eine vernünftige Annahme ist, dass ein vorbeifahrendes Fahrzeug möglicherweise stark bremst, wenn man versucht, aggressiv auf eine Autobahn mit starkem Verkehr zu fahren. Modellieren. Es ist besser, im BEV-Raum zu modellieren, der eine Flugbahnvorhersage ermöglicht, aber auch in der Bildansicht (auch Perspektive genannt). Dieser Satz kann wie folgt umgeschrieben werden: „Dies liegt daran, dass Regionen von Interesse (RoIs) in Form eines Gitters einem dedizierten Entfernungsbereich zugeordnet werden können.“ Aufgrund der perspektivischen Fluchtlinie kann die Bildperspektive den RoI jedoch theoretisch unendlich erweitern. Der BEV-Raum eignet sich besser zur Modellierung der Okklusion, da er die Bewegung linearer modelliert. Durch die Durchführung einer Lageschätzung (Translation und Drehung des eigenen Fahrzeugs) kann die Kompensation der Eigenbewegung einfach durchgeführt werden. Darüber hinaus bewahrt dieser Raum die Bewegung und Skalierung des Agenten, d. h. die umgebenden Fahrzeuge belegen unabhängig von ihrer Entfernung vom eigenen Fahrzeug die gleiche Anzahl an BEV-Pixeln. Dies ist jedoch bei der Bildperspektive nicht der Fall. Um die Zukunft vorherzusagen, muss man die Vergangenheit verstehen. Dies kann in der Regel durch Nachverfolgung oder mithilfe historischer aggregierter BEV-Funktionen erfolgen.
Die folgende Abbildung zeigt einige Komponenten und das Datenflussblockdiagramm des Vorhersagemodells:
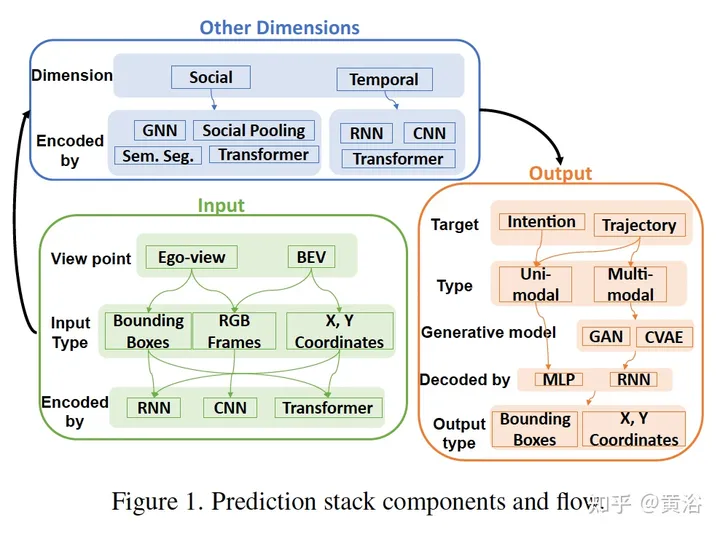
Die folgende Tabelle ist eine Zusammenfassung des Vorhersagemodells:
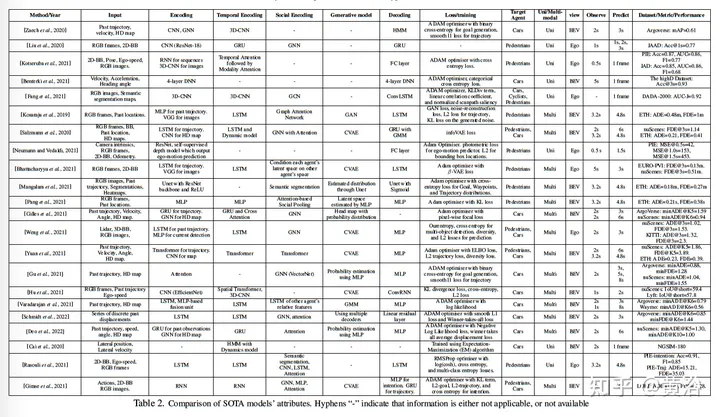
Im Folgenden wird das Vorhersagemodell grundsätzlich ausgehend von der Eingabe/ Ausgabe:
1) Tracklets: Das Wahrnehmungsmodul sagt den aktuellen Status aller dynamischen Agenten voraus. Dieser Zustand umfasst 3D-Zentrum, Abmessungen, Geschwindigkeit, Beschleunigung und andere Attribute. Tracker können diese Daten nutzen und temporäre Verknüpfungen herstellen, sodass jeder Tracker einen Verlauf des Status aller Agenten speichern kann. Jetzt stellt jedes Tracklet die vergangenen Bewegungen des Agenten dar. Diese Form des Vorhersagemodells ist die einfachste, da ihre Eingabe nur aus spärlichen Trajektorien besteht. Ein guter Tracker ist in der Lage, einen Agenten zu verfolgen, selbst wenn er im aktuellen Frame verdeckt ist. Da herkömmliche Tracker auf nicht maschinellen Lernnetzwerken basieren, wird es sehr schwierig, ein End-to-End-Modell zu implementieren.
2) Rohe Sensordaten: Dies ist eine End-to-End-Methode. Das Modell erhält rohe Sensordateninformationen und sagt die Flugbahnvorhersage jedes Agenten in der Szene direkt voraus. Diese Methode kann über Hilfsausgänge und deren Verluste zur Überwachung komplexer Schulungen verfügen oder auch nicht. Der Nachteil dieses Ansatzes besteht darin, dass die Eingabe informationsintensiv und rechenintensiv ist. Dies ist auf die Verschmelzung der drei Probleme Wahrnehmung, Verfolgung und Vorhersage zurückzuführen, was die Entwicklung des Modells erschwert und es noch schwieriger macht, Konvergenz zu erreichen.
3) Kamera vs. BEV: Die BEV-Methode verarbeitet Daten aus einer kartenähnlichen Draufsicht, und der Kameravorhersagealgorithmus nimmt die Welt aus der Perspektive des eigenen Fahrzeugs wahr. Letzteres ist normalerweise anspruchsvoller als Ersteres Aus mehreren Gründen: Erstens können durch die Erfassung durch das BEV ein breiteres Sichtfeld und umfassendere Vorhersageinformationen erhalten werden. Im Vergleich dazu ist das Sichtfeld der Kamera kürzer, was den Vorhersagebereich einschränkt, da das Auto nicht außerhalb des Sichtfelds planen kann Darüber hinaus ist es wahrscheinlicher, dass die Kamera blockiert wird, sodass sie sich von der kamerabasierten Methode unterscheidet. Zweitens leidet die BEV-Methode unter weniger „partiellen Observability“-Problemen, sofern keine Lidar-Daten verfügbar sind macht es für den Algorithmus schwierig, auf die Tiefe des betreffenden Agenten zu schließen, was ein wichtiger Hinweis für die Vorhersage seines Verhaltens ist. Schließlich bewegt sich die Kamera, was die Verarbeitung der Bewegung des Agenten und des eigenen Fahrzeugs erfordert, was unterschiedlich ist aus dem statischen BEV; Erwähnung: Als Nachteil weist die BEV-Darstellungsmethode immer noch das Problem der akkumulierten Fehler bei der Verarbeitung der Kameraansicht auf. Sie ist jedoch immer noch praktischer als BEVs und Autos selten Sie haben Zugriff auf Kameras, die den Standort von BEVs anzeigen und Agenten auf der Straße beobachten. Die Schlussfolgerung ist, dass das Vorhersagesystem in der Lage sein sollte, die Welt aus der Perspektive des eigenen Fahrzeugs zu sehen, einschließlich Lidar- und/oder Stereokameras, deren Daten für die Wahrnehmung der Welt in 3D von Vorteil sein können Zeit, wenn Aufmerksamkeit einbezogen werden muss Bei der Vorhersage der Position des Agenten ist es besser, die Position des Begrenzungsrahmens anstelle des reinen Mittelpunkts zu verwenden, da die Koordinaten des ersteren auch Änderungen im relativen Abstand zwischen dem Fahrzeug und dem Fußgänger implizieren als Eigenbewegung der Kamera; mit anderen Worten, als Agent: Wenn sich der Körper dem eigenen Fahrzeug nähert, wird der Begrenzungsrahmen größer und liefert eine zusätzliche (wenn auch vorläufige) Schätzung der Tiefe.
4) Eigenbewegungsvorhersage: Modellieren Sie die Eigenbewegung des Fahrzeugs, um eine genauere Flugbahn zu generieren. Andere Ansätze verwenden tiefe Netzwerke oder dynamische Modelle, um die Bewegung des interessierenden Agenten zu modellieren, und nutzen dabei zusätzliche Größen, die aus der Datensatzeingabe berechnet werden, wie etwa Posen, optischer Fluss, semantische Karten und Wärmekarten.
5) Kodierung im Zeitbereich: Da die Fahrumgebung dynamisch ist und es viele aktive Agenten gibt, ist es notwendig, die Zeitdimension des Agenten zu kodieren, um ein besseres Vorhersagesystem aufzubauen, das das, was in der Vergangenheit passiert ist, mit dem verbindet, was in der Zukunft passieren wird Zukunft durch die Gegenwart Wenn man weiß, woher der Agent kommt, kann man erraten, wohin der Agent als nächstes gehen könnte, während Vorhersagemodelle für längere Zeitskalen eine komplexere Struktur erfordern.
6) Soziale Kodierung: Um die „Multi-Agenten“-Herausforderung zu bewältigen, verwenden die meisten der leistungsstärksten Algorithmen verschiedene Arten von graphischen neuronalen Netzen (GNN), um soziale Interaktionen zwischen Agenten zu kodieren; die meisten Methoden kodieren Zeit getrennt und soziale Dimensionen - entweder mit der zeitlichen Dimension beginnen und dann die soziale Dimension berücksichtigen, oder in umgekehrter Reihenfolge gibt es ein Transformer-basiertes Modell, das beide Dimensionen gleichzeitig kodieren kann;
7) Vorhersage basierend auf erwarteten Zielen: Verhaltensabsichtsvorhersagen werden, wie der Szenenkontext, normalerweise von verschiedenen erwarteten Zielen beeinflusst und sollten durch Erklärungen für zukünftige Vorhersagen abgeleitet werden, die auf erwarteten Zielen basieren. Dieses Ziel wird durch die Art der gewünschten Bewegung modelliert ein zukünftiger Zustand (definiert als Zielkoordinaten) oder für einen Agenten; Forschungen in den Bereichen Neurowissenschaften und Computer Vision zeigen, dass Menschen typischerweise zielorientierte Agenten sind, während sie Entscheidungen treffen, die einer kontinuierlichen Reihenfolge folgen und letztendlich kurz formulieren -Termische oder langfristige Pläne; auf dieser Grundlage kann diese Frage in zwei Kategorien unterteilt werden: Die erste ist kognitiv und beantwortet die Frage, wohin der Agent geht seine angestrebten Ziele.
8) Multimodale Vorhersage: Da die Straßenumgebung stochastisch ist, kann sich eine frühere Trajektorie in verschiedene zukünftige Trajektorien verwandeln sind Methoden zur latenten Raummodellierung diskreter Variablen. Multimodalität wird nur auf Trajektorien angewendet und zeigt ihr Potenzial bei der Absichtsvorhersage. Es wird ein Aufmerksamkeitsmechanismus übernommen, der zur Berechnung von Gewichten verwendet werden kann.
Das obige ist der detaillierte Inhalt vonEin Überblick über visuelle Methoden zur Flugbahnvorhersage. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Technologietrends, die Sie im Jahr 2023 im Auge behalten sollten
- Wie künstliche Intelligenz Rechenzentrumsteams neue Alltagsaufgaben beschert
- Können künstliche Intelligenz oder Automatisierung das Problem der geringen Energieeffizienz in Gebäuden lösen?
- OpenAI-Mitbegründer im Interview mit Huang Renxun: Die Argumentationsfähigkeiten von GPT-4 haben noch nicht die Erwartungen erfüllt
- Dank der OpenAI-Technologie übertrifft Bing von Microsoft Google im Suchverkehr