
Heim >Technologie-Peripheriegeräte >KI >Lassen Sie uns über Wissensextraktion sprechen. Haben Sie es gelernt?
Lassen Sie uns über Wissensextraktion sprechen. Haben Sie es gelernt?

- PHPznach vorne
- 2023-11-13 20:13:02758Durchsuche
1. Einführung
Wissensextraktion bezieht sich normalerweise auf das Extrahieren strukturierter Informationen aus unstrukturiertem Text, wie z. B. Tags und Phrasen, die umfangreiche semantische Informationen enthalten. Dies wird in der Branche häufig in Szenarien wie dem Inhaltsverständnis und dem Produktverständnis verwendet, indem wertvolle Tags aus benutzergenerierten Textinformationen extrahiert und auf Inhalte oder Produkte angewendet werden. Die Wissensextraktion geht normalerweise mit der Extraktion extrahierter Tags oder Phrasen einher Die Klassifizierung wird normalerweise als Erkennungsaufgabe für benannte Entitäten modelliert. Eine häufige Aufgabe zur Erkennung benannter Entitäten besteht darin, benannte Entitätskomponenten zu identifizieren und die Komponenten in Ortsnamen, Personennamen, Organisationsnamen usw. zu klassifizieren Wörter einteilen in domänendefinierte Kategorien wie Serie (Air Force One, Sonic 9), Marke (Nike, Li Ning), Typ (Schuhe, Kleidung, Digital), Stil (INS-Stil, Retro-Stil, nordischer Stil), usw.
Der Einfachheit halber werden die informationsreichen Tags oder Phrasen im Folgenden zusammenfassend als Tag-Wörter bezeichnet.
2. Klassifizierung der Wissensextraktion
Dieser Artikel stellt die klassische Methode der Wissensextraktion aus zwei Perspektiven vor: Tag-Word-Mining und Tag-Wortklassifizierung. Tag-Word-Mining-Methoden werden in unbeaufsichtigte Methoden, überwachte Methoden und Fernüberwachungsmethoden unterteilt, wie in Abbildung 1 dargestellt. Tag-Wort-Mining wählt Tag-Wörter mit hoher Bewertung in zwei Schritten aus: Kandidatenwort-Mining und Phrasenbewertung. In der Regel werden die Tag-Wort-Extraktion und -Klassifizierung gemeinsam modelliert und in eine Sequenzannotationsaufgabe zur Erkennung benannter Entitäten umgewandelt. Abbildung 1: Klassifizierung von Wissensextraktionsmethoden Wörter Führen Sie N- durch Grammkombinationen als Kandidatenwörter und bewerten Sie die Kandidatenwörter dann anhand statistischer Merkmale.
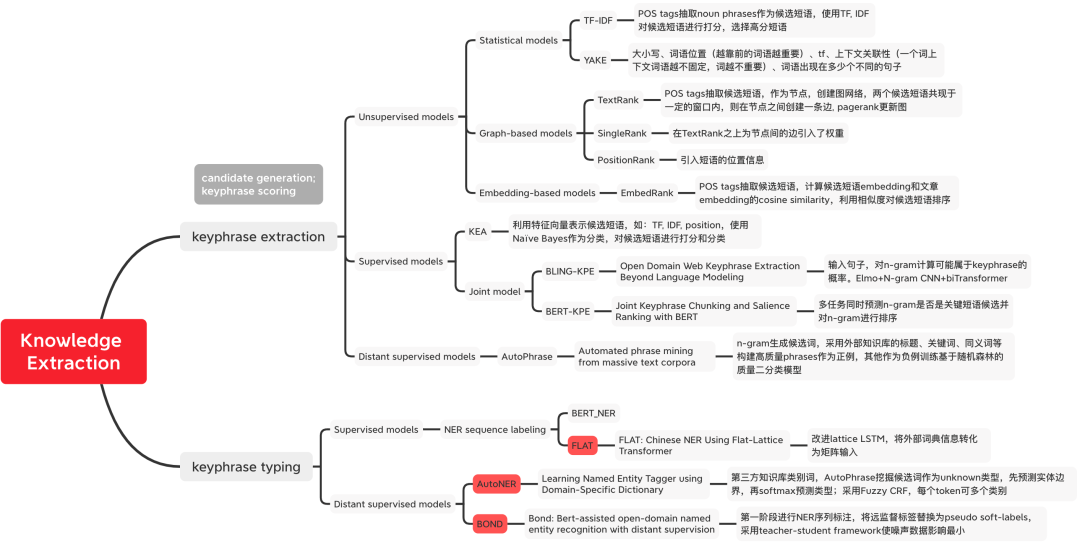 Umgeschriebener Inhalt: Berechnungsmethode: tfidf(t, d, D) = tf(t, d) * idf(t, D), wobei tf(t, d) = log(1 + freq(t), d )), freq(t,d) stellt die Häufigkeit dar, mit der das Kandidatenwort t im aktuellen Dokument d vorkommt, idf(t,D) = log(N/count(d∈D:t∈D)) stellt das Kandidatenwort t dar In wie vielen Dokumenten kommt es vor? Es wird verwendet, um die Seltenheit eines Wortes anzuzeigen. Wenn ein Wort nur in einem Dokument vorkommt, bedeutet dies, dass das Wort selten ist und umfangreichere Informationen enthält Um Kandidatenwörter zu analysieren, führen Sie zunächst eine Screening-Runde durch, indem Sie beispielsweise Wortartmarkierungen verwenden, um Substantive zu screenen.
Umgeschriebener Inhalt: Berechnungsmethode: tfidf(t, d, D) = tf(t, d) * idf(t, D), wobei tf(t, d) = log(1 + freq(t), d )), freq(t,d) stellt die Häufigkeit dar, mit der das Kandidatenwort t im aktuellen Dokument d vorkommt, idf(t,D) = log(N/count(d∈D:t∈D)) stellt das Kandidatenwort t dar In wie vielen Dokumenten kommt es vor? Es wird verwendet, um die Seltenheit eines Wortes anzuzeigen. Wenn ein Wort nur in einem Dokument vorkommt, bedeutet dies, dass das Wort selten ist und umfangreichere Informationen enthält Um Kandidatenwörter zu analysieren, führen Sie zunächst eine Screening-Runde durch, indem Sie beispielsweise Wortartmarkierungen verwenden, um Substantive zu screenen.
YAKE[1]: Zur Erfassung von Keyword-Features werden fünf Features definiert, die heuristisch kombiniert werden, um jedem Keyword eine Bewertung zuzuweisen. Je niedriger die Punktzahl, desto wichtiger ist das Schlüsselwort. 1) Großbuchstaben: Begriffe in Großbuchstaben (mit Ausnahme des Anfangsworts jedes Satzes) sind wichtiger als Begriffe in Kleinbuchstaben, was der Anzahl der fett gedruckten Wörter im Chinesischen entspricht. 2) Wortposition: Jeder Absatz des Textes. Einige Wörter am Anfang sind wichtiger als nachfolgende Wörter; 3) Worthäufigkeit, zählt die Häufigkeit des Wortvorkommens 4) Wortkontext, wird verwendet, um die Anzahl verschiedener Wörter zu messen, die unter einer festen Fenstergröße erscheinen -vorkommen, je geringer die Bedeutung des Wortes ist; 5) Je öfter ein Wort in verschiedenen Sätzen vorkommt, desto wichtiger ist es.
Graph-Based ModelTextRank[2]: Führen Sie zunächst eine Wortsegmentierung und Teil-of-Speech-Kennzeichnung für den Text durch und filtern Sie Stoppwörter heraus, so dass nur Wörter mit einem bestimmten Teil-of-Speech übrig bleiben einen Graphen erstellen. Jeder Knoten ist ein Wort, und Kanten stellen Beziehungen zwischen Wörtern dar, die durch die Definition des gemeinsamen Vorkommens von Wörtern innerhalb eines beweglichen Fensters einer vorgegebenen Größe erstellt werden. Verwenden Sie PageRank, um die Gewichtung der Knoten bis zur Konvergenz zu aktualisieren. Sortieren Sie die Knotengewichte in umgekehrter Reihenfolge, um die wichtigsten k-Wörter als Kandidatenschlüsselwörter zu erhalten. Markieren Sie die Kandidatenwörter im Originaltext und kombinieren Sie sie zu mehreren Schlüsselwörtern Phrasen für Phrasen.
- Darstellungsbasierte Methode Einbettungsbasiertes Modell
EmbedRank[3]: Wählen Sie Kandidatenwörter durch Wortsegmentierung und Wortart-Tagging aus, verwenden Sie vorab trainiertes Doc2Vec und Sent2vec als Vektordarstellungen von Kandidatenwörtern und -dokumenten und berechnen Sie die Kosinusähnlichkeit, um Kandidatenwörter einzustufen. In ähnlicher Weise ersetzt KeyBERT[4] die Vektordarstellung von EmbedRank durch BERT.
- Prüfen Sie zunächst Kandidatenwörter und verwenden Sie dann die Tag-Wortklassifizierung: Das klassische Modell KEA[5] verwendet Naive Bayes als Klassifikator, um N-Gramm-Kandidatenwörter mithilfe von vier entworfenen Funktionen zu bewerten.
- Gemeinsames Training des Kandidatenwort-Screenings und der Tag-Wort-Erkennung: BLING-KPE[6] verwendet den Originalsatz als Eingabe, verwendet CNN und Transformer, um die N-Gramm-Phrase des Satzes zu codieren, und berechnet die Wahrscheinlichkeit, dass die Phrase a ist Tag-Wort und ob es sich um ein Tag-Wort handelt, werden manuell beschriftet. BERT-KPE[7] Basierend auf der Idee von BLING-KPE wird ELMO durch BERT ersetzt, um den Vektor des Satzes besser darzustellen.
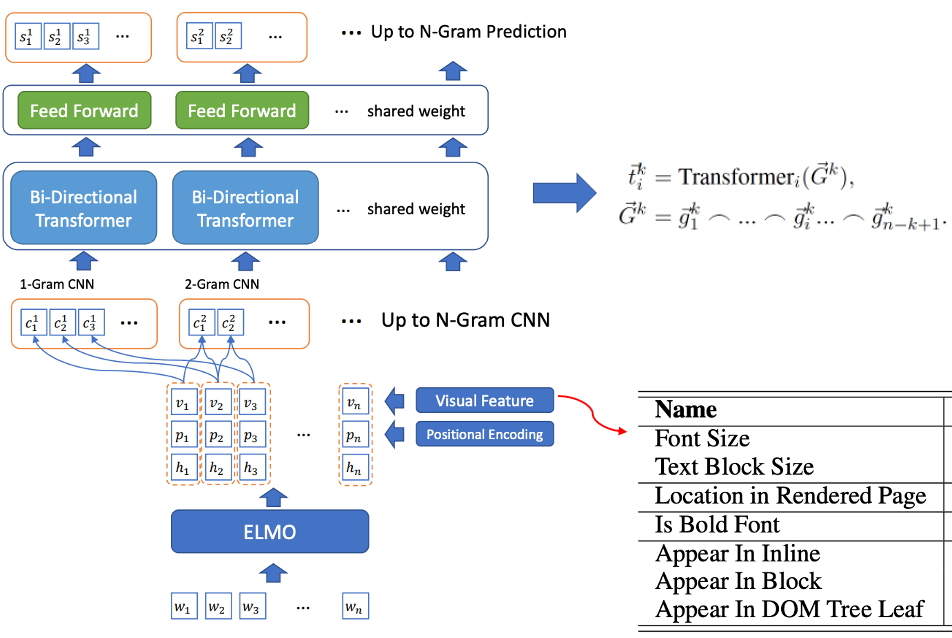 Abbildung 2 BLING-KPE-Modellstruktur
Abbildung 2 BLING-KPE-Modellstruktur
Fernüberwachungsmethode
AutoPhrase
In diesem Artikel definieren wir hochwertige Phrasen als Wörter mit vollständiger Semantik, wenn die folgenden vier Bedingungen gleichzeitig erfüllt sind:
- Beliebtheit: Die Häufigkeit des Vorkommens im Dokument ist hoch genug.
- Konkordanz: Die Häufigkeit von Token-Kollokationen ist nach dem Ersetzen viel höher als bei anderen Kollokationen, d : Phrase und ihre Unterzeichen Phrasen müssen vollständig sein.
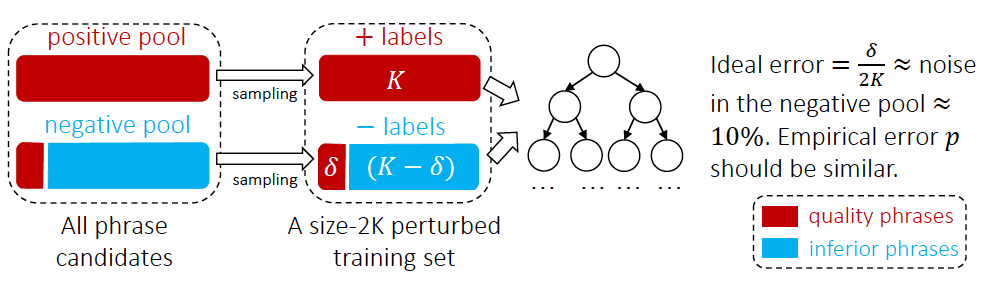
- Der AutoPhrase-Tag-Mining-Prozess ist in Abbildung 3 dargestellt. Zunächst verwenden wir die Kennzeichnung von Wortarten, um hochfrequente N-Gramm-Wörter als Kandidaten zu prüfen. Anschließend klassifizieren wir die Kandidatenwörter durch Fernüberwachung. Schließlich verwenden wir die oben genannten vier Bedingungen, um qualitativ hochwertige Phrasen herauszufiltern (Neuschätzung der Phrasenqualität). andere Phrasen als negativer Pool Laut den experimentellen Statistiken des Artikels befinden sich beispielsweise 10 % hochwertiger Phrasen im Negativbeispielpool, da sie in der Wissensdatenbank nicht in negative Beispiele eingeordnet werden. Daher verwendet der Artikel a Random Forest Ensemble-Klassifikator, wie in Abbildung 4 gezeigt, um die Auswirkungen der Klassifizierung zu reduzieren. In Industrieanwendungen kann beim Klassifikatortraining auch die Zwei-Klassifizierungsmethode für Aufgaben zur Beziehung zwischen Sätzen verwendet werden, die auf dem Pre-Training-Modell BERT [13] basiert.
IV. Tag-Wortklassifizierung 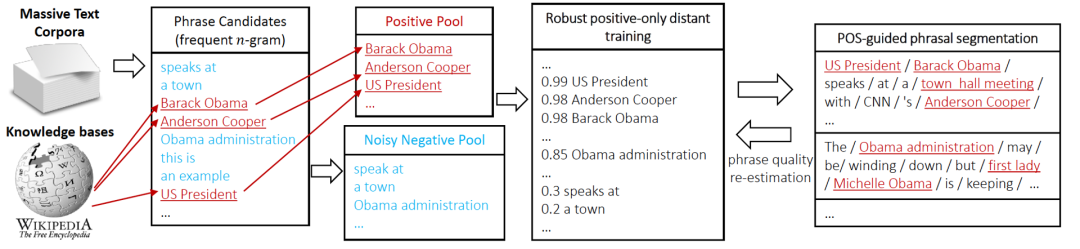
NER-Sequenzannotationsmodell
Lattice LSTM[8] ist die erste Arbeit, die Vokabularinformationen für chinesische NER-Aufgaben einführt. Lattice ist ein gerichteter azyklischer Graph. Die Anfangs- und Endzeichen des Vokabulars bestimmen die Rasterposition beim Abgleichen eines Satzes durch Vokabelinformationen. kann eine gitterartige Struktur erhalten werden, wie in Abbildung 5(a) dargestellt. Die Lattice-LSTM-Struktur verschmilzt Vokabelinformationen mit dem nativen LSTM, wie in 5(b) gezeigt. Für das aktuelle Zeichen werden alle externen Wörterbuchinformationen, die mit diesem Zeichen enden, verschmolzen Informationen zum Thema „Apotheke“. Für jedes Zeichen verwendet Lattice LSTM einen Aufmerksamkeitsmechanismus, um eine variable Anzahl von Worteinheiten zu verschmelzen. Obwohl Lattice-LSTM die Leistung von NER-Aufgaben effektiv verbessert, kann die RNN-Struktur keine Fernabhängigkeiten erfassen und die Einführung lexikalischer Informationen ist verlustbehaftet. Gleichzeitig kann die dynamische Lattice-Struktur die GPU-Parallelität nicht vollständig ausführen hat diese beiden Fragen effektiv verbessert. Wie in Abbildung 5(c) dargestellt, erfasst das Flat-Modell Fernabhängigkeiten durch die Transformer-Struktur und entwirft eine Positionskodierung, um die durch Zeichen übereinstimmenden Wörter in Sätze zu integrieren. Konstrukt zwei Kopfpositionskodierung und Schwanzpositionskodierung glätten die Gitterstruktur von einem gerichteten azyklischen Graphen zu einer flachen Flat-Gitter-Transformator-Struktur. Abbildung 5 NER-Modell zur Einführung von Vokabularinformationen Entitätsgrenzenerkennung (Entity Span Recognition) und dann Entitätsklassifizierung (Entity Classification). Bei der Erstellung des externen Wörterbuchs kann die externe Wissensdatenbank direkt verwendet werden oder die AutoPhrase-Mining-Methode verwendet werden, um zunächst ein Offline-Tag-Wort-Mining durchzuführen und dann das AutoNER-Modell zu verwenden, um die Tag-Wörter schrittweise zu aktualisieren.
Um das Lärmproblem bei der Fernüberwachung zu lösen, verwenden wir das Entity-Grenzen-Identifizierungsschema von Tie or Break, um die BIOE-Kennzeichnungsmethode zu ersetzen. Unter diesen bedeutet Tie, dass das aktuelle Wort und das vorherige Wort zur selben Entität gehören, und Break bedeutet, dass das aktuelle Wort und das vorherige Wort nicht mehr zur selben Entität gehören. In der Entitätsklassifizierungsphase wird Fuzzy CRF verwendet mit den vielfältigen Merkmalen einer Entität. 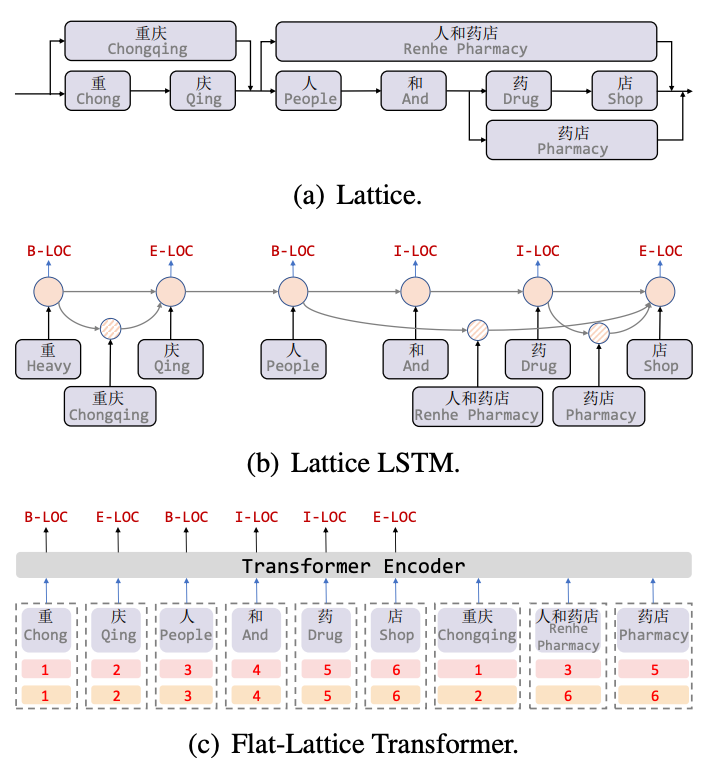
BOND
BOND [12] ist ein zweistufiges Entitätserkennungsmodell, das auf fernüberwachtem Lernen basiert. In der ersten Stufe werden Fernetiketten verwendet, um das vorab trainierte Sprachmodell an die NER-Aufgabe anzupassen. In der zweiten Stufe werden zunächst das Schülermodell und das Lehrermodell mit dem in Stufe 1 trainierten Modell und dann das Pseudomodell initialisiert -Vom Teacher-Modell generierte Etiketten werden verwendet, um das Student-Modell zu koppeln. Führen Sie Schulungen durch, um die Auswirkungen von Lärmproblemen zu minimieren, die durch entfernte Aufsicht verursacht werden.
Bilder
Der Inhalt, der neu geschrieben werden muss, ist: Abbildung 7 BOND-Trainingsablaufdiagramm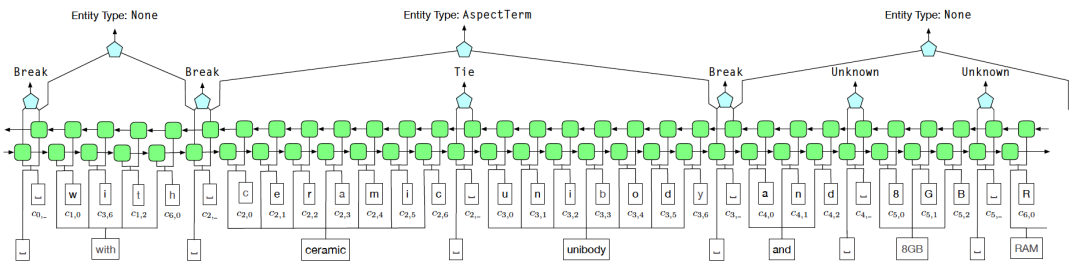 V. ZusammenfassungIn diesem Artikel werden die klassischen Methoden der Wissensextraktion aus den beiden Perspektiven Tag Word Mining und Tag Word vorgestellt Klassifizierung, einschließlich der in der Branche weit verbreiteten unbeaufsichtigten und fernüberwachten klassischen Methoden TF-IDF und TextRank, die auf manuell annotierten Daten basieren, AutoPhrase, AutoNER usw., können Referenzen für das Inhaltsverständnis, die Wörterbuchkonstruktion usw. der Branche liefern NER für das Abfrageverständnis.
V. ZusammenfassungIn diesem Artikel werden die klassischen Methoden der Wissensextraktion aus den beiden Perspektiven Tag Word Mining und Tag Word vorgestellt Klassifizierung, einschließlich der in der Branche weit verbreiteten unbeaufsichtigten und fernüberwachten klassischen Methoden TF-IDF und TextRank, die auf manuell annotierten Daten basieren, AutoPhrase, AutoNER usw., können Referenzen für das Inhaltsverständnis, die Wörterbuchkonstruktion usw. der Branche liefern NER für das Abfrageverständnis.
Referenzen
【2】Mihalcea R, Tarau P. Textrank: Bringing Order into Text[C]//Proceedings of the 2004 Conference on Empirical Methods in Natural Language Processing 2004: 404-411.
【3】Bennani-Smires K, Musat C, Hossmann A, et al. Einfache unbeaufsichtigte Schlüsselwortextraktion mithilfe von Satzeinbettungen[J]. 】Witten I H, Paynter G W, Frank E, et al. KEA: Practical Automatic Keyphrase Extraction[C]//Proceedings of the four ACM Conference on Digital Libraries 1999: 254-255.
Übersetzungsinhalt:【6】Xiong L , Hu C, Xiong C, et al. Open-Domain-Web-Keyword-Extraktion über Sprachmodelle hinaus[J]. arXiv-Vorabdruck arXiv:1911.02671, 2019
【7】Sun, S., Xiong, C., Liu, Z., Liu, Z., & Bao, J. (2020). Gemeinsames Keyphrase Chunking und Salience Ranking mit BERT. arXiv-Vorabdruck arXiv:2004.13639.
Der Inhalt, der neu geschrieben werden muss, ist: [8] Zhang Y, Yang J. Erkennung benannter chinesischer Entitäten mithilfe des Gitters LSTM[C]. ACL 2018
【9】Li X, Yan H, Qiu X, et al. FLAT: Chinesisches NER mit Flachgittertransformator[C]. al. al. Automatisiertes Phrasen-Mining aus massiven Textkorpora[J]. IEEE Transactions on Knowledge and Data Engineering, 2018, 30(10): 1825-1837 . Lernen benannter Entitäts-Tagger unter Verwendung eines domänenspezifischen Wörterbuchs.
【12】Liang C, Yu Y, Jiang H, et al. C] //Proceedings of the 26th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining 2020: 1054-1064.
【13】Erforschung und Praxis der NER-Technologie in Meituan Search, https://zhuanlan.zhihu.com/ p /163256192
Das obige ist der detaillierte Inhalt vonLassen Sie uns über Wissensextraktion sprechen. Haben Sie es gelernt?. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!