
Heim >Technologie-Peripheriegeräte >KI >Apples Diffusionsmodell im „Matroschka'-Stil reduziert die Anzahl der Trainingsschritte um 70 %!
Apples Diffusionsmodell im „Matroschka'-Stil reduziert die Anzahl der Trainingsschritte um 70 %!

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBnach vorne
- 2023-10-25 14:13:01996Durchsuche
Eine aktuelle Studie von Apple hat die Leistung von Diffusionsmodellen bei hochauflösenden Bildern erheblich verbessert.
Mit dieser Methode wird die Anzahl der Trainingsschritte für Bilder mit derselben Auflösung um mehr als 70 % reduziert.
Bei der Auflösung von 1024×1024 ist die Bildqualität direkt satt und die Details sind klar erkennbar.

Apple nannte diesen Erfolg MDM, DM ist die Abkürzung für Diffusion Model und das erste M steht für Matroschka.
Genau wie bei einer echten Matroschka-Puppe verschachtelt MDM einen Prozess mit niedriger Auflösung in einem Prozess mit hoher Auflösung und ist in mehreren Ebenen verschachtelt.
Die Diffusionsprozesse mit hoher und niedriger Auflösung werden gleichzeitig ausgeführt, was den Ressourcenverbrauch des traditionellen Diffusionsmodells im hochauflösenden Prozess erheblich reduziert.

Für ein Bild mit einer Auflösung von 256 x 256 erfordert das herkömmliche Diffusionsmodell in einer Umgebung mit einer Stapelgröße von 1024 1,5 Millionen Trainingsschritte, während das MDM nur 390.000 Schritte erfordert, was einer Reduzierung um mehr als 70 % entspricht. .
Darüber hinaus nutzt MDM ein End-to-End-Training und ist nicht auf bestimmte Datensätze und vorab trainierte Modelle angewiesen. Es verbessert die Geschwindigkeit und gewährleistet gleichzeitig die Generierungsqualität und ist flexibel einsetzbar.

Sie können nicht nur hochauflösende Bilder zeichnen, sondern auch 16×256²-Videos synthetisieren.

Einige Internetnutzer kommentierten, dass Apple endlich Text mit Bildern verknüpft habe.
Wie genau funktioniert die „Matroschka“-Technologie von MDM?
Übergreifend und progressiv kombinieren
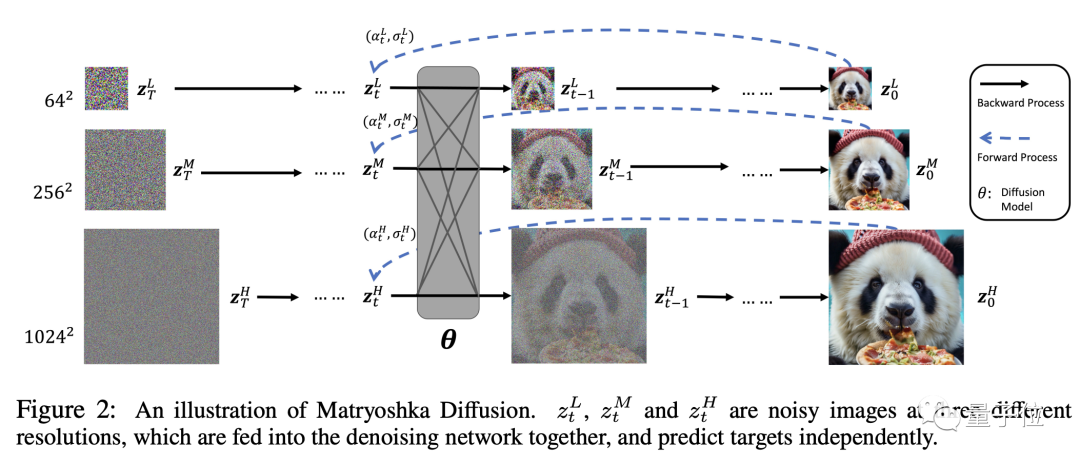
Vor Beginn des Trainings müssen die Daten mit einem bestimmten Algorithmus vorverarbeitet werden, um Versionen mit unterschiedlichen Auflösungen zu erhalten.
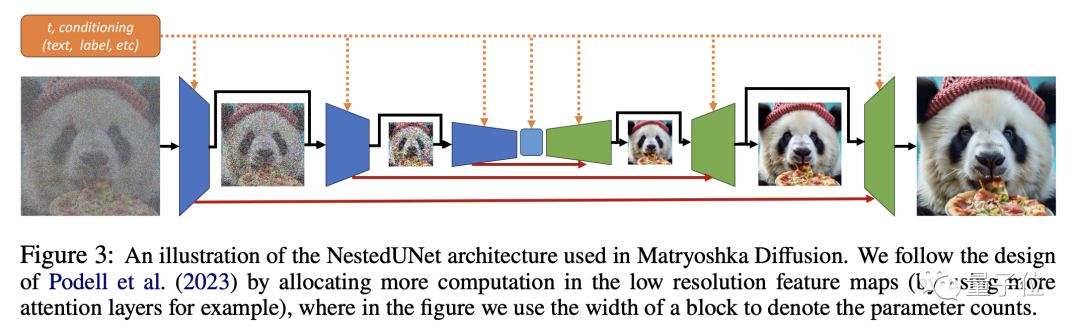
Dann verwenden wir diese Daten unterschiedlicher Auflösung für die gemeinsame UNet-Modellierung. Das kleine UNet verarbeitet niedrige Auflösungen und wird in das große UNet verschachtelt, das hohe Auflösungen verarbeitet.
Durch auflösungsübergreifende Verbindungen können Funktionen und Parameter zwischen UNets unterschiedlicher Größe gemeinsam genutzt werden.

MDM-Training ist ein Schritt-für-Schritt-Prozess.
Obwohl die Modellierung gemeinsam durchgeführt wird, wird der Trainingsprozess zu Beginn nicht für eine hohe Auflösung durchgeführt, sondern schrittweise von einer niedrigen Auflösung aus erweitert.
Dies kann eine große Menge an Berechnungen vermeiden und ermöglicht außerdem das Vortraining von UNet mit niedriger Auflösung, um den Trainingsprozess mit hoher Auflösung zu beschleunigen.
Während des Trainingsprozesses werden nach und nach Trainingsdaten mit höherer Auflösung zum Gesamtprozess hinzugefügt, sodass sich das Modell an die zunehmend höhere Auflösung anpassen und reibungslos zum endgültigen hochauflösenden Prozess übergehen kann.
Aber insgesamt ist das MDM-Training nach der schrittweisen Hinzufügung des hochauflösenden Prozesses immer noch ein durchgängiger gemeinsamer Prozess.
Beim gemeinsamen Training mit unterschiedlichen Auflösungen nehmen Verlustfunktionen mit mehreren Auflösungen gemeinsam an Parameteraktualisierungen teil und vermeiden so die Anhäufung von Fehlern, die durch mehrstufiges Training verursacht werden.
Jede Auflösung hat einen entsprechenden Rekonstruktionsverlust des Datenelements. Die Verluste verschiedener Auflösungen werden gewichtet und zusammengeführt. Um die Generierungsqualität sicherzustellen, hat der Verlust niedriger Auflösung ein größeres Gewicht.
In der Inferenzphase verfolgt MDM auch eine Strategie, die Parallelität und Progression kombiniert.
Darüber hinaus verwendet MDM auch ein vorab trainiertes Bildklassifizierungsmodell (CFG), um die Optimierung generierter Stichproben in eine vernünftigere Richtung zu lenken, und fügt Rauschen zu Stichproben mit niedriger Auflösung hinzu, um sie näher an die Verteilung mit hoher Auflösung heranzuführen Proben.
Was bewirkt also MDM?
Weniger Parameter konkurrieren mit SOTA
In Bezug auf Bilder sind in den ImageNet- und CC12M-Datensätzen die FID (je niedriger der Wert, desto besser der Effekt) und die CLIP-Leistung von MDM deutlich besser als beim gewöhnlichen Diffusionsmodell.
Unter anderem wird FID verwendet, um die Qualität des Bildes selbst zu bewerten, und CLIP veranschaulicht den Grad der Übereinstimmung zwischen Bild und Textanweisungen.
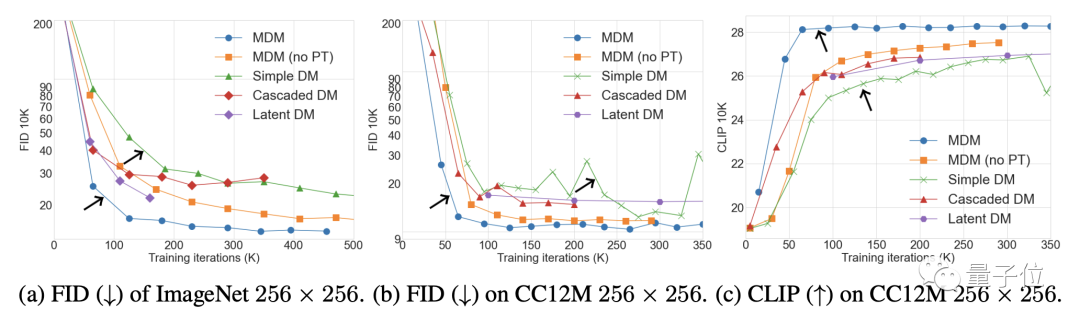
Verglichen mit SOTA-Modellen wie DALL E und IMAGEN ist die Leistung von MDM ebenfalls sehr ähnlich, aber die Trainingsparameter von MDM sind weitaus geringer als bei diesen Modellen.
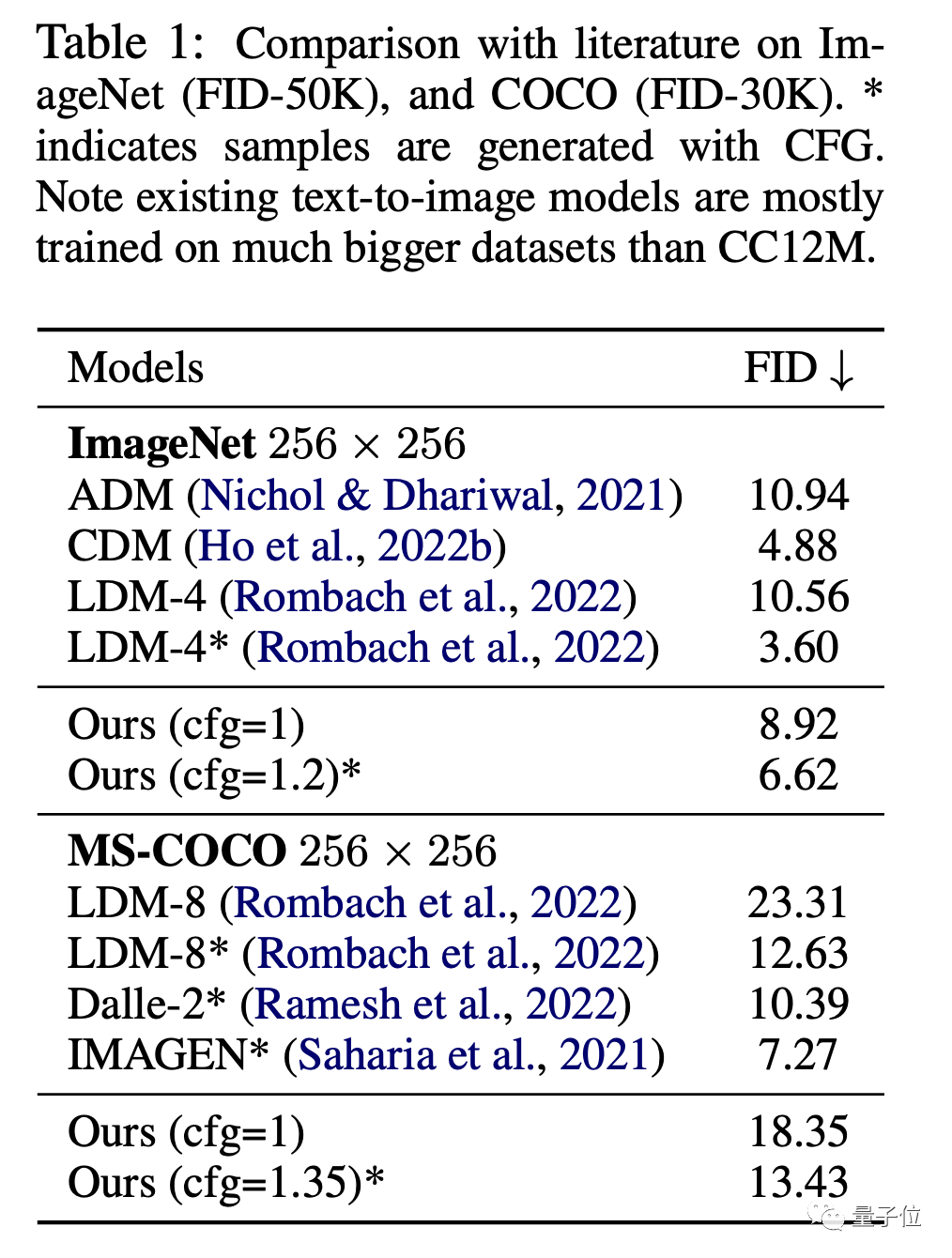
Es ist nicht nur besser als das gewöhnliche Diffusionsmodell, die Leistung von MDM übertrifft auch andere Kaskadendiffusionsmodelle.
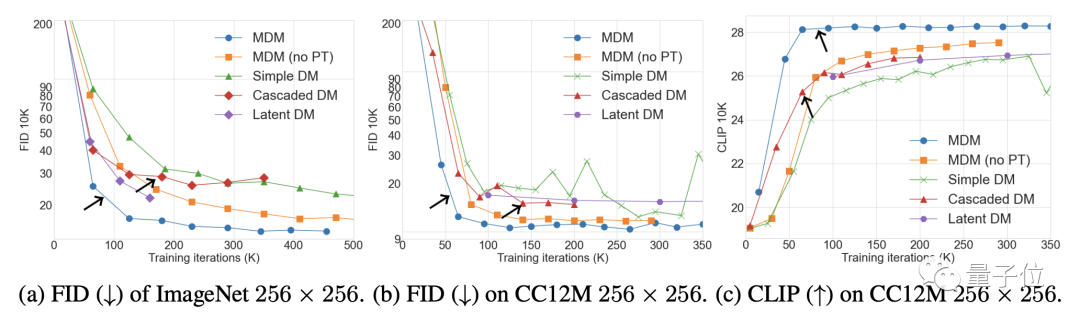
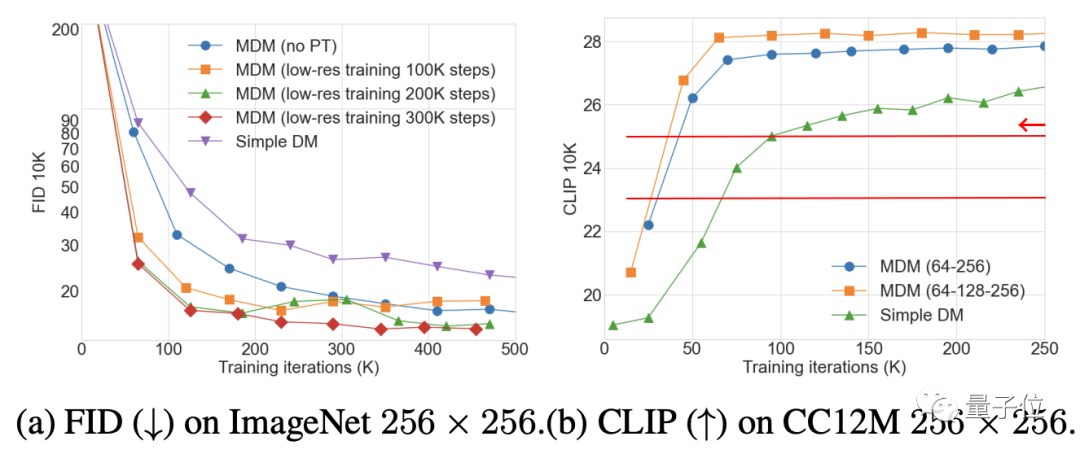
Die Ergebnisse des Ablationsexperiments zeigen, dass die Verbesserung des MDM-Effekts umso offensichtlicher ist, je mehr Schritte des Trainings mit niedriger Auflösung erforderlich sind. Andererseits ist die Anzahl der Trainingsschritte umso geringer, die erforderlich sind, um denselben CLIP zu erreichen Punktzahl. .
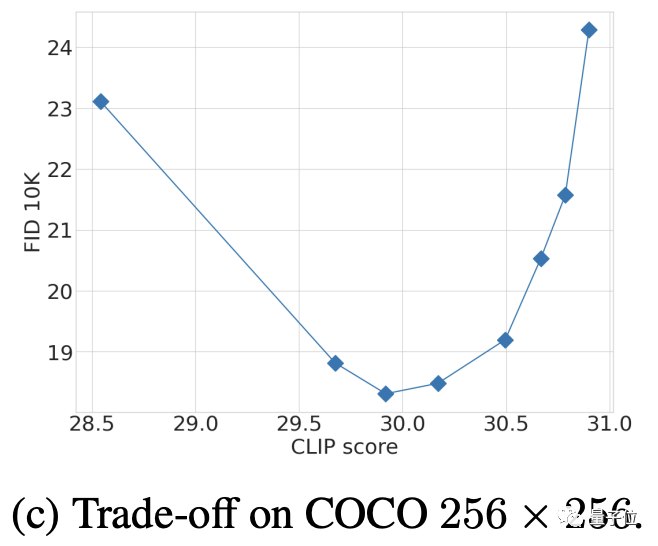
Die Auswahl der CFG-Parameter ist ein Ergebnis des Kompromisses zwischen FID und CLIP nach mehreren Tests (ein hoher CLIP-Score entspricht einer Erhöhung der CFG-Stärke).
Das obige ist der detaillierte Inhalt vonApples Diffusionsmodell im „Matroschka'-Stil reduziert die Anzahl der Trainingsschritte um 70 %!. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Funktionen des TCP/IP-Vierschichtmodells
- Welche Datenmodelle werden am häufigsten verwendet?
- So berechnen Sie die Größe des CSS-Box-Modells
- So importieren Sie das Layout eines CAD-Modells
- Eine weitere Revolution im Reinforcement Learning! DeepMind schlägt eine „Algorithmus-Destillation' vor: einen erforschbaren, vorab trainierten Reinforcement-Learning-Transformer