
Heim >Technologie-Peripheriegeräte >KI >Die innovative Arbeit des Teams von Chen Danqi: Die Beschaffung von SOTA zu 5 % Kosten löste eine Begeisterung für die „Alpaka-Schur' aus
Die innovative Arbeit des Teams von Chen Danqi: Die Beschaffung von SOTA zu 5 % Kosten löste eine Begeisterung für die „Alpaka-Schur' aus

- 王林nach vorne
- 2023-10-12 14:29:04808Durchsuche
Es verbraucht nur 3 % des Berechnungsbetrags und 5 % der Kosten, um SOTA zu erhalten, und dominiert damit die großen Open-Source-Modelle im Maßstab 1B-3B.
Dieses Ergebnis stammt vom Team von Princeton Chen Danqi und heißt LLM-ShearingLarge Model Pruning Method.

Basierend auf Alpaca LLaMA 2 7B werden die 1.3B- und 3B-beschnittenen Sheared-LLama-Modelle durch gerichtetes strukturiertes Beschneiden erhalten.

Um das Vorgängermodell der gleichen Größenordnung bei der nachgelagerten Aufgabenbewertung zu übertreffen, muss es neu geschrieben werden
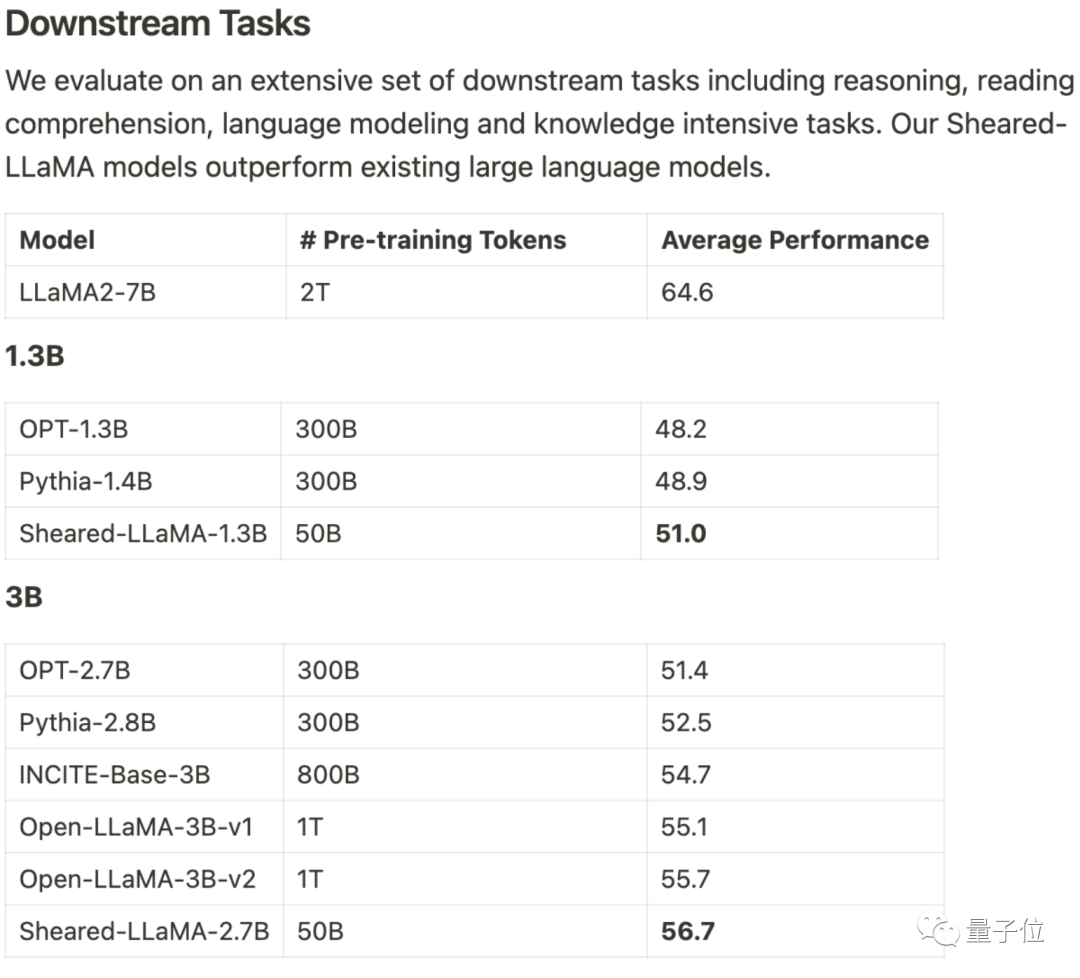
Xia Mengzhou, die Erstautorin, sagte: „Es ist viel kostengünstiger als das Vortraining.“ von Grund auf.“

Das Papier gibt auch ein Beispiel für die beschnittene Sheared-LLaMA-Ausgabe und zeigt, dass trotz der Größe von nur 1,3 B und 2,7 B bereits kohärente und reichhaltige Antworten generiert werden können.
Für die gleiche Aufgabe, „die Rolle eines Analysten der Halbleiterindustrie zu spielen“, ist die Antwortstruktur von Version 2.7B noch klarer.

Das Team gab an, dass, obwohl derzeit nur die Version Llama 2 7B für Beschneidungsexperimente verwendet wurde, die Methode auf andere Modellarchitekturen und auch auf jeden Maßstab erweitert werden kann. Ein zusätzlicher Vorteil nach dem Beschneiden besteht darin, dass Sie hochwertige Datensätze für das weitere Vortraining auswählen können
 Einige Entwickler sagten, dass noch vor 6 Monaten fast jeder dachte, dass Modelle unter 65B keinen praktischen Nutzen hätten
Einige Entwickler sagten, dass noch vor 6 Monaten fast jeder dachte, dass Modelle unter 65B keinen praktischen Nutzen hätten
 Behandeln Sie das Beschneiden als eingeschränkte Optimierung
Behandeln Sie das Beschneiden als eingeschränkte Optimierung
LLM-Shearing, insbesondere eine Art
direktionales strukturiertes Beschneiden, das ein großes Modell auf eine bestimmte Zielstruktur beschneidet. Frühere Bereinigungsmethoden können zu einer Verschlechterung der Modellleistung führen, da einige Strukturen gelöscht werden, was sich auf die Ausdrucksfähigkeit auswirkt.
Wir schlagen eine neue Methode vor, bei der das Beschneiden als eingeschränktes Optimierungsproblem behandelt wird. Wir suchen nach Subnetzwerken, die der angegebenen Struktur entsprechen, indem wir die Beschneidungsmaskenmatrix lernen, und zielen darauf ab, die Leistung zu maximieren.
Zu diesem Zeitpunkt stellte das Team fest, dass das beschnittene Modell und das von Grund auf neu trainierte Modell unterschiedliche Verlustreduzierungsraten für verschiedene Datensätze aufwiesen, was zu dem Problem einer geringen Datennutzungseffizienz führte.
Zu diesem Zweck schlug das Team 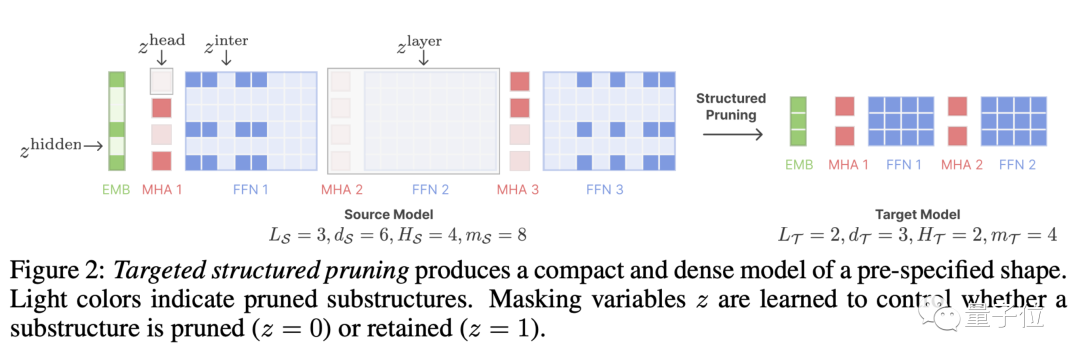
(Dynamic Batch Loading)
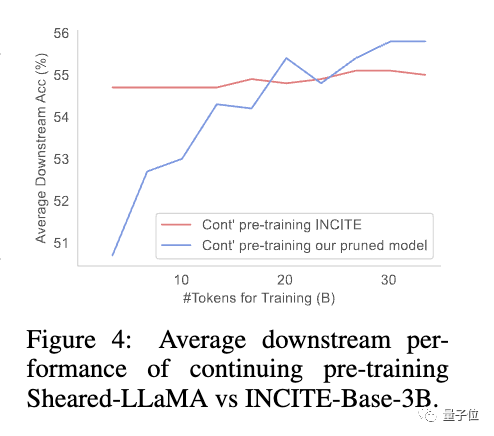
vor, das den Datenanteil in jeder Domäne entsprechend der Verlustreduzierungsrate des Modells für verschiedene Domänendaten dynamisch anpasst und so die Effizienz der Datennutzung verbessert.Die Studie ergab, dass beschnittene Modelle im Vergleich zu Modellen gleicher Größe, die von Grund auf neu trainiert wurden, zwar eine schlechte Anfangsleistung aufweisen, sich aber mit fortgesetztem Vortraining schnell verbessern und schließlich übertreffen können Dies zeigt, dass das Beschneiden von einem starken Basismodell ausgeht , was bessere Initialisierungsbedingungen für die Fortsetzung des Vortrainings bieten kann.
wird weiterhin aktualisiert, kommen Sie und schneiden Sie einen nach dem anderen ab
Die Autoren des Artikels sind Princeton-Doktoranden Xia Mengzhou, Gao Tianyu, Tsinghua Zhiyuan Zeng, Prince Tonne Assistenzprofessor Chen Dan琦 .
Xia Mengzhou schloss ihr Studium an der Fudan-Universität mit einem Bachelor-Abschluss und an der CMU mit einem Master-Abschluss ab.
Gao Tianyu ist ein Student, der seinen Abschluss an der Tsinghua-Universität gemacht hat. Er hat 2019 den Tsinghua-Sonderpreis gewonnen.
Beide sind Schüler von Chen Danqi, und Chen Danqi ist derzeit Assistenzprofessor an der Princeton University und Mitglied des Princeton Natural Sprachverarbeitungsgruppe Die Co-Leiterin von
Vor kurzem hat Chen Danqi auf ihrer persönlichen Homepage ihre Forschungsrichtung aktualisiert.
„Dieser Zeitraum konzentriert sich hauptsächlich auf die Entwicklung groß angelegter Modelle. Zu den Forschungsthemen gehören: „
- Wie das Abrufen eine wichtige Rolle in Modellen der nächsten Generation spielen und den Realismus, die Anpassungsfähigkeit, die Interpretierbarkeit und die Glaubwürdigkeit verbessern kann.“
- Kostengünstiges Training und Einsatz großer Modelle, verbesserte Trainingsmethoden, Datenverwaltung, Modellkomprimierung und Optimierung der nachgelagerten Aufgabenanpassung.
- Auch an Arbeiten interessiert, die das Verständnis der Fähigkeiten und Grenzen aktueller großer Modelle sowohl empirisch als auch theoretisch wirklich verbessern.

Sheared-Llama ist bereits auf Hugging Face verfügbar
Das Team sagte, dass sie die Open-Source-Bibliothek weiterhin aktualisieren werden
Wenn weitere große Modelle veröffentlicht werden, schneiden Sie sie einzeln ab und fahren Sie fort Veröffentlichung leistungsstarker kleiner Modelle.

One More Thing
Ich muss sagen, dass die großen Modelle jetzt wirklich zu lockig sind.
Mengzhou / /arxiv.org/abs/2310.06694
Link zur Projekt-Homepage: https://xiamengzhou.github.io/sheared-llama/
Das obige ist der detaillierte Inhalt vonDie innovative Arbeit des Teams von Chen Danqi: Die Beschaffung von SOTA zu 5 % Kosten löste eine Begeisterung für die „Alpaka-Schur' aus. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Neue Methode der 3D-Modellsegmentierung macht Ihre Hände frei! Es ist keine manuelle Kennzeichnung erforderlich, es ist nur eine Schulung erforderlich, und auch nicht gekennzeichnete Kategorien können HKU und Byte erkennen
- Implementieren Sie Edge-Training mit weniger als 256 KB Speicher, und die Kosten betragen weniger als ein Tausendstel von PyTorch
- Metaforscher unternehmen einen neuen Versuch der KI: Sie bringen Robotern das physische Navigieren bei, ohne Karten oder Training
- Verwendung von Pytorch zur Implementierung des kontrastiven Lernens von SimCLR für selbstüberwachtes Vortraining
- Die neue Arbeit des Teams von Tsinghua Zhu Jun: Verwenden Sie 4-stellige Ganzzahlen, um Transformer zu trainieren, was 2,2-mal schneller als FP16 und 35,1 % schneller ist und die Einführung von AGI beschleunigt!