
Heim >Technologie-Peripheriegeräte >KI >Sieben Schritte zur Vorbereitung von Datensätzen für Bild-KI-Projekte
Sieben Schritte zur Vorbereitung von Datensätzen für Bild-KI-Projekte

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBnach vorne
- 2023-09-26 23:45:041024Durchsuche
Übersetzer |.
Chonglou |. Ich frage mich, ob Ihnen aufgefallen ist, dass der Datensatz möglicherweise der am meisten übersehene Teil des maschinellen Lernprojekts ist. Für die meisten Menschen ist ein Datensatz nichts anderes als eine Sammlung vorgefertigter Bilder, die schnell zusammengestellt oder heruntergeladen wurden. Tatsächlich sind Datensätze der Grundstein jedes bildbasierten Projekts zur künstlichen Intelligenz (KI). Für jedes Machine-Learning-Projekt, das eine hohe Genauigkeit anstrebt, ist die Erstellung und Verwaltung eines ausgewogenen und gut strukturierten Datensatzes von entscheidender Bedeutung.
Allerdings ist die Erstellung eines Datensatzes nicht so einfach wie das Sammeln von Hunderten von Bildern. Wenn wir versuchen, ein KI-Projekt zu starten, stoßen wir wahrscheinlich auf verschiedene versteckte Gefahren. Im Folgenden bespreche ich sieben typische Schritte, die Sie zum Erstellen Ihres eigenen Datensatzes unternehmen können, damit Sie einen Einblick in die Bedeutung der Datensatzgröße, mögliche Datenauslassungen und die Konvertierung eines Datensatzes in eine Datenbank erhalten.
Hinweis: Diese Schritte gelten hauptsächlich für Objekterkennungs- und -klassifizierungsprojekte, die Bilddatensätze enthalten. Andere Projekttypen wie NLP
oder Grafikprojekte erfordern eine andere Herangehensweise.Schritt 1
: BildgrößeNormalerweise können neuronale Netze nur Bilder einer bestimmten Größe verarbeiten, und Bilder, die einen Schwellenwert überschreiten, müssen verkleinert werden. Dies bedeutet, dass wir vor der Verwendung des Datensatzes ein geeignetes neuronales Netzwerk auswählen und die Größe des Bildes entsprechend ändern müssen
Wie Sie wissen, kann eine Reduzierung der Bildgröße zu einem enormen Genauigkeitsverlust führen, selbst wenn es klein ist Objekte auf dem Bild verschwinden, wodurch der gesamte Erkennungsprozess beeinträchtigt wird. Wie unten gezeigt, müssen Sie das Nummernschild im von der Überwachungskamera aufgenommenen Bild erkennen und das Nummernschild nimmt nur einen kleinen Teil des gesamten Bildes ein. Wenn das neuronale Netzwerk das Bild verkleinert, kann es daher sein, dass das Nummernschild sehr klein wird und nicht mehr erkannt wird. Wie in der folgenden Abbildung gezeigt, kann die Bildgröße, die das Netzwerk verwenden kann, verstanden werden , Hilft Ihnen, das entsprechende Datensatzbild zuzuschneiden.
Obwohl die meisten neuronalen Netze kleinere Bildgrößen verarbeiten können, sind die neuesten neuronalen Netze, wie z. B.
Yolo v5x6
Yolo v5xs
6 in der Lage, Bilder mit einer Breite von bis zu
in der Lage, Bilder mit einer Breite von bis zu
1280 Pixeln zu verarbeiten. 🎙 Bei der Einstellung des Datensatzes müssen Sie auf folgende Faktoren achten: Die Art der Kamera, ob es sich um eine Smartphone-Kamera oder eine Überwachungskamera handelt Die Größe des Bildes
Der Standort der Kamera, ist sie drinnen oder draußenWetterbedingungen wie Licht, Regen, Nebel, Schnee usw. Mit einem klaren Verständnis der realen Bilder, die vom neuronalen Netzwerk verarbeitet werden sollen, können wir einen Datensatz erstellen, der die interessierenden Objekte und ihre Umgebung genau widerspiegelt.
Das Sammeln gängiger Bilder von Google gilt möglicherweise als die einfachste und schnellste Möglichkeit, einen großen Datensatz zusammenzustellen. Allerdings ist es mit dieser Methode tatsächlich schwierig, hohe Genauigkeitsanforderungen zu erfüllen. Wie in der Abbildung unten gezeigt, werden Bilder in Google oder Fotodatenbanken im Vergleich zu Bildern, die mit echten Kameras aufgenommen wurden, normalerweise „schön“ verarbeitet
- Und ein Datensatz, der zu „hübsch“ ist, führt wahrscheinlich dazu höhere Testgenauigkeit. Dies bedeutet, dass das neuronale Netzwerk nur bei Testdaten (einer Sammlung von aus dem Datensatz bereinigten Bildern) eine gute Leistung erbringt, unter realen Bedingungen jedoch eine schlechte Leistung erbringt und zu einer schlechten Genauigkeit führt.
- Schritt 3:
- Formatierung und Anmerkung
Ein weiterer wichtiger Aspekt, auf den wir achten müssen, ist: das Format des Bildes. Prüfen Sie vor Beginn Ihres Projekts, welche Formate Ihr gewähltes Framework unterstützt und ob Ihre Bilder diese Anforderungen erfüllen können. Obwohl das aktuelle Framework mehrere Bildformate unterstützen kann, gibt es immer noch Probleme mit Formaten wie .jfif
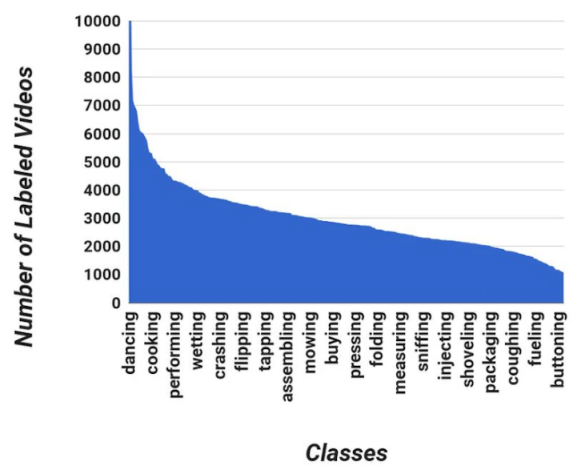
.Anmerkungsdaten können verwendet werden, um Begrenzungsrahmen, Dateinamen und verschiedene Strukturen anzugeben, die übernommen werden können. Im Allgemeinen erfordern unterschiedliche neuronale Netze und Frameworks unterschiedliche Annotationsmethoden. Einige erfordern absolute Koordinaten, die die Position des Begrenzungsrahmens enthalten, andere erfordern relative Koordinaten, andere erfordern, dass jedem Bild eine separate .txt-Datei mit den Anmerkungen beigefügt ist, während andere nur eine einzige .txt-Datei mit den Anmerkungen erfordern Alle Anmerkungen-Datei. Wie Sie sehen, ist es selbst dann nicht hilfreich, wenn Ihr Datensatz über gute Bilder verfügt, wenn Ihr Framework die Anmerkungen nicht verarbeiten kann. Schritt Trainingsteilmenge - Obwohl dieser Ansatz weit verbreitet ist und nachweislich gute Ergebnisse erzielt, bevorzugen wir einen anderen Ansatz, indem wir den Datensatz wie folgt in Teilmengen aufteilen: Trainingsteilmenge - 70% der Gesamtzahl der Bilder Eine der am häufigsten verwendeten Methoden zur Segmentierung von Datensätzen besteht darin, die Daten zufällig zu mischen, dann die ersten der Bilder auszuwählen und sie in die Trainingsteilmenge einzufügen, und die restlichen 30 % Dazu können wir ein einfaches Skript verwenden, um die Duplikatentfernung automatisch durchzuführen. Natürlich können Sie den Duplikatschwellenwert anpassen, zum Beispiel: Löschen Sie nur vollständig doppelte Bilder oder Bilder mit einer Ähnlichkeit von bis zu 90 % usw. Im Allgemeinen gilt: Je mehr doppelte Inhalte entfernt werden, desto genauer wird das neuronale Netzwerk produzieren. Wenn Ihr Datensatz ziemlich groß ist, zum Beispiel: mehr als 10 Millionen Bilder und wie viele für Für zehn Objektklassen und Unterklassen empfehlen wir die Erstellung einer einfachen Datenbank zum Speichern von Datensatzinformationen. Der Grund dafür ist eigentlich ganz einfach: Bei großen Datenmengen ist es schwierig, den Überblick über alle Daten zu behalten. Daher können wir die Daten ohne eine strukturierte Verarbeitung nicht genau analysieren. Über die Datenbank können Sie den Datensatz schnell diagnostizieren und Folgendes herausfinden: Zu wenige Bilder in einer bestimmten Kategorie erschweren das Erkennen von Objekten durch das neuronale Netzwerk; die Verteilung der Bilder zwischen den Kategorien ist nicht gleichmäßig genug; in einer bestimmten Kategorie gibt es zu viele Google-Bilder, was zu einer niedrigen Genauigkeitsbewertung für diese Kategorie führt. Mit einer einfachen Datenbank können wir die folgenden Informationen einschließen: Die Datenbank ist für das Sammeln von Datensätzen unverzichtbar und statistische Datentools. Dadurch können wir schnell und einfach erkennen, wie ausgewogen der Datensatz ist und wie viele qualitativ hochwertige Bilder in jeder Kategorie enthalten sind (aus Sicht eines neuronalen Netzwerks). Mit Daten wie den unten visuell dargestellten können wir sie schneller analysieren und mit den Erkennungsergebnissen vergleichen, um die Grundursache für die geringe Genauigkeit herauszufinden Der Inhalt, der neu geschrieben werden muss, ist: Eins Bemerkenswert ist, dass der Grund für die geringe Genauigkeit möglicherweise in einer geringeren Anzahl von Bildern oder einem höheren Anteil von Google Fotos in einer bestimmten Kategorie liegt. Durch die Erstellung einer solchen Datenbank kann die Zeit für Produktion, Tests und Modellumschulung erheblich reduziert werden Bildertechnologie, Datenerweiterung ist der Prozess der Durchführung einfacher oder komplexer Transformationen an Daten, z. B. durch Umdrehen oder Stiltransformation, können wir die Gültigkeit der Daten verbessern. Der auf dieser Grundlage erhaltene effektive Datensatz erfordert kein übermäßiges Training. Wie im Bild unten gezeigt, kann diese Art der Datentransformation so einfach sein wie das einfache Drehen des Bildes um 90 -Bibliothek speziell für die Datenerweiterung vorbereiten. Derzeit gibt es zwei Arten der Datenerweiterung: Erweiterung vor dem Training In-Training-Verbesserung- verwendet ein Framework ähnlich der integrierten Bildtransformationstechnologie von Obwohl für diejenigen, die KI auf Unternehmen anwenden möchten, der Datensatz der am wenigsten aufregende Teil ist. Es ist jedoch unbestreitbar, dass Datensätze ein wichtiger Bestandteil jedes Bilderkennungsprojekts sind. Darüber hinaus nimmt die Verwaltung und Organisation von Datensätzen in den meisten Bilderkennungsprojekten oft viel Zeit vom Team in Anspruch. Lassen Sie uns abschließend zusammenfassen, wie Sie die besten Ergebnisse aus Ihren KI-Projekten erzielen können, indem Sie Ihre Datensätze ordnungsgemäß entsorgen: , Autor: Oleg Kokorin
Für Trainingszwecke wird der Datensatz normalerweise in zwei Teilmengen unterteilt:
Das ist es eine Reihe von Bildern. Das neuronale Netzwerk wird anhand dieses Bildsatzes trainiert. Sein Anteil reicht von


Schritt 6: Große Datensatzdatenbank
Normalerweise werden solche erweiterten Konvertierungen automatisch durchgeführt. Beispielsweise können wir eine Python
 Bevor der Trainingsprozess beginnt, werden die Daten erweitert und der Trainingsteilmenge hinzugefügt. Natürlich können wir solche Ergänzungen erst vornehmen, nachdem der Datensatz in Trainings- und Validierungsteilmengen unterteilt wurde, um die zuvor erwähnten Datenauslassungen zu vermeiden.
Bevor der Trainingsprozess beginnt, werden die Daten erweitert und der Trainingsteilmenge hinzugefügt. Natürlich können wir solche Ergänzungen erst vornehmen, nachdem der Datensatz in Trainings- und Validierungsteilmengen unterteilt wurde, um die zuvor erwähnten Datenauslassungen zu vermeiden. PyTorch
KleinerKnoten
Originaltitel:
7 Schritte zur Vorbereitung eines Datensatzes für ein bildbasiertes KI-Projekt
Das obige ist der detaillierte Inhalt vonSieben Schritte zur Vorbereitung von Datensätzen für Bild-KI-Projekte. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Was sind die Entwicklungstrends der künstlichen Intelligenz?
- Das Wesen der künstlichen Intelligenz besteht darin, die menschliche Intelligenz zu simulieren oder sogar zu übertreffen, oder?
- Das Verstehen natürlicher Sprache ist ein wichtiges Anwendungsgebiet der künstlichen Intelligenz. Was ist ihr Ziel?
- Was ist das Grundkonzept der künstlichen Intelligenz?
- Eine einfache Möglichkeit, große Datensätze für maschinelles Lernen in Python zu verarbeiten