
Heim >Technologie-Peripheriegeräte >KI >Neuer Titel: TextDiffuser: Keine Angst vor Text in Bildern, sorgt für eine qualitativ hochwertigere Textwiedergabe
Neuer Titel: TextDiffuser: Keine Angst vor Text in Bildern, sorgt für eine qualitativ hochwertigere Textwiedergabe

- 王林nach vorne
- 2023-09-26 23:53:081566Durchsuche
Der Bereich Text-to-Image hat in den letzten Jahren enorme Fortschritte gemacht, insbesondere im Zeitalter der durch künstliche Intelligenz generierten Inhalte (AIGC). Mit dem Aufkommen des DALL-E-Modells sind in der akademischen Gemeinschaft immer mehr Text-to-Image-Modelle entstanden, wie z. B. Imagen, Stable Diffusion, ControlNet und andere Modelle. Trotz der rasanten Entwicklung des Text-zu-Bild-Bereichs stehen bestehende Modelle jedoch immer noch vor einigen Herausforderungen bei der stabilen Generierung von Bildern mit Text
Nachdem wir das vorhandene Sota-Text-zu-Bild-Modell ausprobiert haben, können wir feststellen, dass der Textteil Die vom Modell generierten Daten sind grundsätzlich unleserlich und ähneln verstümmelten Zeichen, was sich stark auf die Gesamtästhetik des Bildes auswirkt.

Die vom bestehenden Sota-Textgenerierungsmodell generierten Textinformationen sind schlecht lesbar
Nach einer Untersuchung gibt es in der akademischen Gemeinschaft weniger Forschung in diesem Bereich. Tatsächlich sind Bilder mit Text im täglichen Leben weit verbreitet, beispielsweise auf Postern, Buchumschlägen und Straßenschildern. Wenn KI solche Bilder effektiv erzeugen kann, wird sie Designer bei ihrer Arbeit unterstützen, Design-Inspirationen anregen und den Designaufwand reduzieren. Darüber hinaus möchten Benutzer möglicherweise nur den Textteil der Ergebnisse des Vincent-Diagrammmodells ändern und die Ergebnisse in anderen Nicht-Textbereichen beibehalten.
Um die ursprüngliche Bedeutung nicht zu verändern, muss der Inhalt ins Chinesische umgeschrieben werden. Der Originalsatz muss nicht erscheinen. textdiffuser/

- Code-Adresse: https://github.com/microsoft/unilm/tree/master/textdiffuser
- Demo-Adresse: https://huggingface.co/spaces/microsoft/TextDiffuser
- Drei Funktionen von TextDiffuser
- In diesem Artikel wird das TextDiffuser-Modell vorgeschlagen, das zwei Stufen enthält: Die erste Stufe generiert das Layout und die zweite Stufe generiert Bilder.
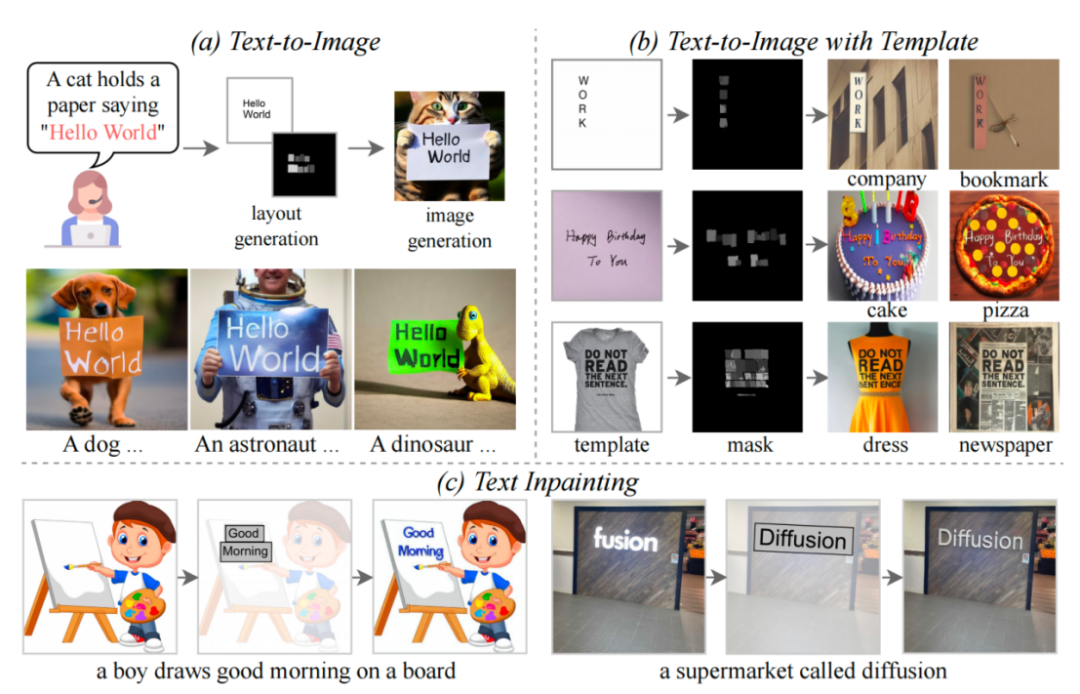
Das Modell akzeptiert eine Textaufforderung und bestimmt dann das Layout (dh das Koordinatenfeld) jedes Schlüsselworts basierend auf den Schlüsselwörtern in die Aufforderung. Die Forscher verwendeten Layout Transformer, verwendeten ein Encoder-Decoder-Formular, um das Koordinatenfeld der Schlüsselwörter autoregressiv auszugeben, und verwendeten die PILLOW-Bibliothek von Python zum Rendern des Textes. In diesem Prozess können Sie auch die vorgefertigte API von Pillow verwenden, um die Koordinatenbox jedes Zeichens abzurufen, was dem Abrufen der Segmentierungsmaske auf Zeichenebene auf Boxebene entspricht. Basierend auf diesen Informationen versuchten die Forscher, die stabile Diffusion zu optimieren.
Sie betrachteten zwei Situationen: Die eine besteht darin, dass der Benutzer das gesamte Bild direkt generieren möchte (sogenannte Whole-Image-Generierung). Eine andere Situation ist die Part-Image-Generierung, auch Text-Inpainting im Papier genannt, was bedeutet, dass der Benutzer ein Bild vorgibt und bestimmte Textbereiche im Bild ändern muss.
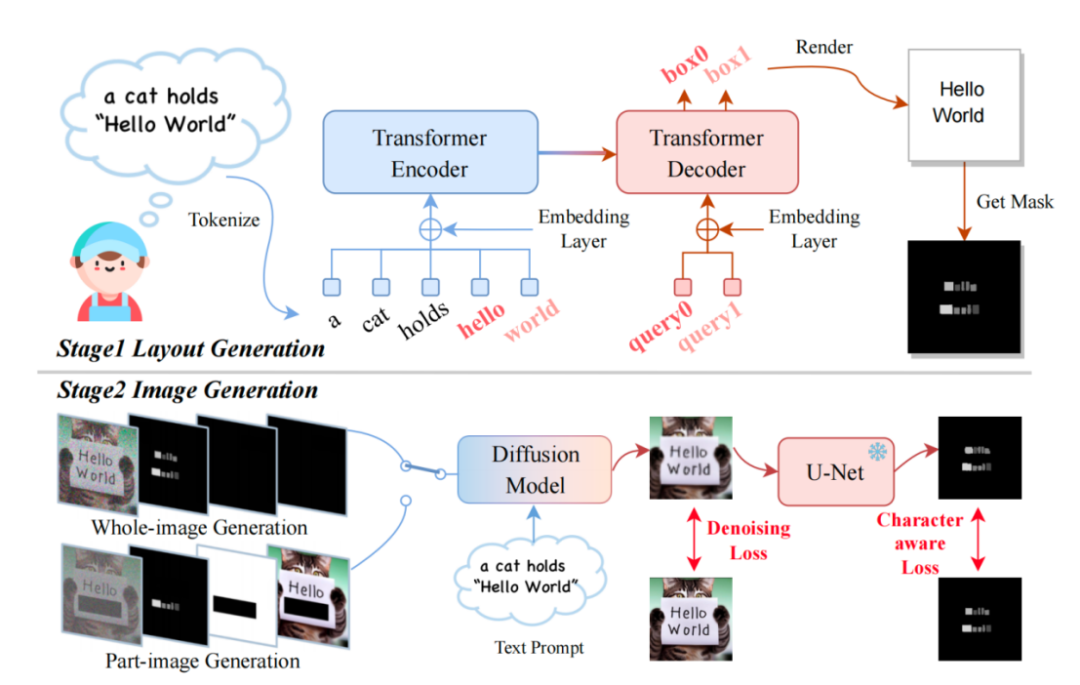 Um die beiden oben genannten Ziele zu erreichen, haben die Forscher die Eingabefunktionen neu gestaltet und die Dimension von ursprünglich 4 Dimensionen auf 17 Dimensionen erhöht. Dazu gehören vierdimensionale verrauschte Bildmerkmale, achtdimensionale Zeicheninformationen, eindimensionale Bildmasken und vierdimensionale unmaskierte Bildmerkmale. Handelt es sich um eine ganze Bildgeneration, legen die Forscher den Maskenbereich auf das gesamte Bild fest, handelt es sich hingegen um eine Teilbildgeneration, wird nur ein Teil des Bildes maskiert. Der Trainingsprozess des Diffusionsmodells ähnelt dem von LDM. Interessierte Freunde können sich auf die Methodenbeschreibung im Originalartikel beziehen
Um die beiden oben genannten Ziele zu erreichen, haben die Forscher die Eingabefunktionen neu gestaltet und die Dimension von ursprünglich 4 Dimensionen auf 17 Dimensionen erhöht. Dazu gehören vierdimensionale verrauschte Bildmerkmale, achtdimensionale Zeicheninformationen, eindimensionale Bildmasken und vierdimensionale unmaskierte Bildmerkmale. Handelt es sich um eine ganze Bildgeneration, legen die Forscher den Maskenbereich auf das gesamte Bild fest, handelt es sich hingegen um eine Teilbildgeneration, wird nur ein Teil des Bildes maskiert. Der Trainingsprozess des Diffusionsmodells ähnelt dem von LDM. Interessierte Freunde können sich auf die Methodenbeschreibung im Originalartikel beziehen
In der Inferenzphase verfügt TextDiffuser über eine sehr flexible Verwendungsweise, die unterteilt werden kann in drei Typen:
- Bilder basierend auf den Anweisungen des Benutzers erstellen. Darüber hinaus kann der Benutzer, wenn er mit dem im ersten Schritt der Layout-Generierung erstellten Layout nicht zufrieden ist, die Koordinaten und den Inhalt des Textes ändern, was die Steuerbarkeit des Modells erhöht.
- Starten Sie direkt ab der zweiten Etappe. Das Endergebnis wird basierend auf dem Vorlagenbild generiert, wobei das Vorlagenbild ein gedrucktes Textbild, ein handgeschriebenes Textbild oder ein Szenentextbild sein kann. Die Forscher trainierten speziell ein Zeichensatz-Segmentierungsnetzwerk, um das Layout aus Vorlagenbildern zu extrahieren.
- Beginnt ebenfalls mit der zweiten Stufe. Der Benutzer gibt das Bild an und gibt den Bereich und den Textinhalt an, der geändert werden muss. Und dieser Vorgang kann mehrmals durchgeführt werden, bis der Benutzer mit den generierten Ergebnissen zufrieden ist.

Konstruierte MARIO-Daten
Um TextDiffuser zu trainieren, sammelten die Forscher zehn Millionen Textbilder, wie in der Abbildung oben gezeigt, darunter drei Teilmengen: MARIO-LAION, MARIO-TMDB und MARIO - OpenLibrary
Die Forscher haben beim Filtern der Daten mehrere Aspekte berücksichtigt: Beispielsweise werden nach der OCR des Bildes nur Bilder mit einer Textmenge von [1,8] beibehalten. Sie haben Texte mit mehr als 8 Texten herausgefiltert, da diese Texte häufig eine große Menge an dichtem Text enthalten und die OCR-Ergebnisse im Allgemeinen weniger genau sind, beispielsweise bei Zeitungen oder komplexen Konstruktionszeichnungen. Darüber hinaus legen sie den Textbereich auf mehr als 10 % fest. Diese Regel soll verhindern, dass der Textbereich im Bild zu klein wird.
Nach dem Training mit dem MARIO-10M-Datensatz führten die Forscher quantitative und qualitative Vergleiche von TextDiffuser mit bestehenden Methoden durch. Bei der Gesamtbildgenerierungsaufgabe haben die von unserer Methode generierten Bilder beispielsweise einen klareren und lesbareren Text, und der Textbereich ist besser in den Hintergrundbereich integriert, wie in der folgenden Abbildung dargestellt bestehende Arbeit Rendering-Leistung
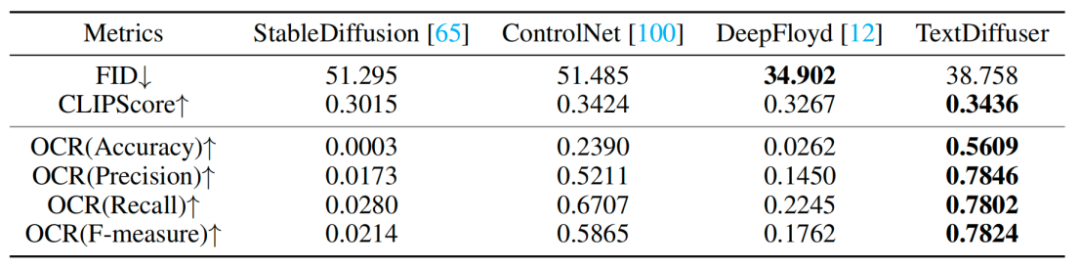
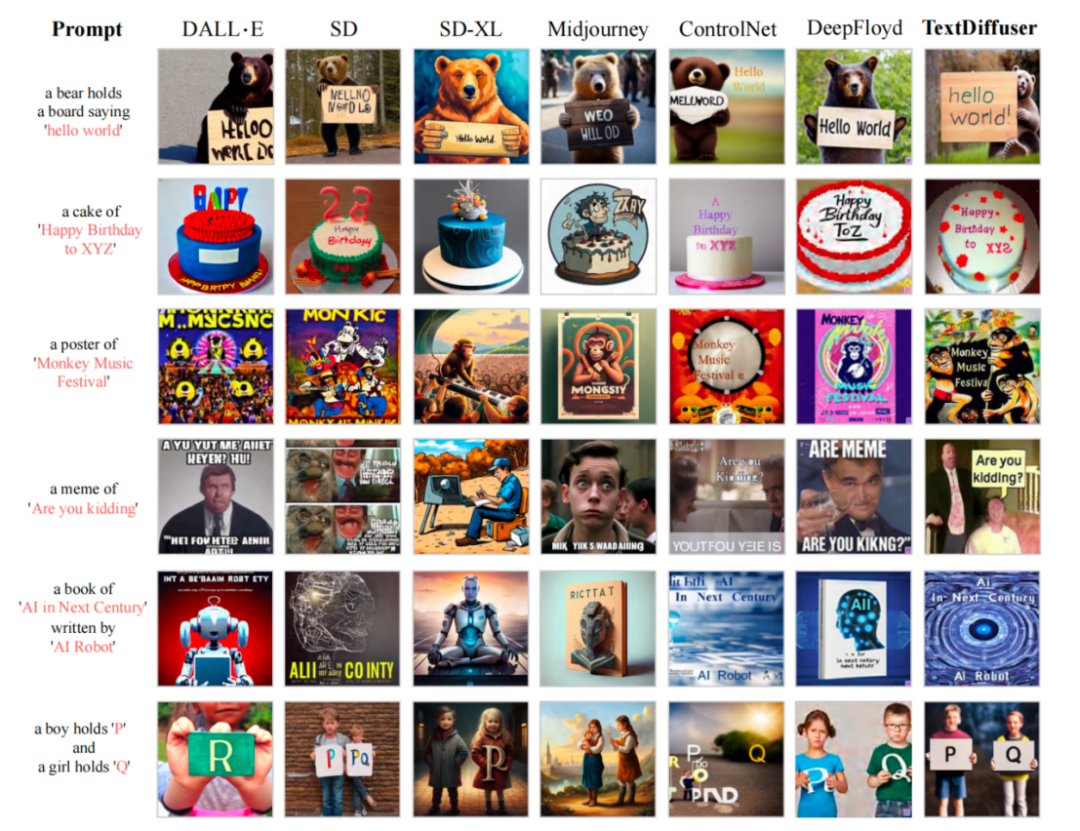 Die Forscher führten auch eine Reihe qualitativer Experimente durch, und die Ergebnisse sind in Tabelle 1 dargestellt. Zu den Bewertungsindikatoren gehören FID, CLIPScore und OCR. Insbesondere für den OCR-Index hat sich diese Forschungsmethode im Vergleich zur Vergleichsmethode deutlich verbessert. Der Forscher versucht, einem bestimmten Bild Zeichen hinzuzufügen oder zu ändern, und experimentelle Ergebnisse zeigen, dass TextDiffuser sehr natürliche Ergebnisse generiert.
Die Forscher führten auch eine Reihe qualitativer Experimente durch, und die Ergebnisse sind in Tabelle 1 dargestellt. Zu den Bewertungsindikatoren gehören FID, CLIPScore und OCR. Insbesondere für den OCR-Index hat sich diese Forschungsmethode im Vergleich zur Vergleichsmethode deutlich verbessert. Der Forscher versucht, einem bestimmten Bild Zeichen hinzuzufügen oder zu ändern, und experimentelle Ergebnisse zeigen, dass TextDiffuser sehr natürliche Ergebnisse generiert.
Visualisierung der Textreparaturfunktion
Insgesamt hat das in diesem Artikel vorgeschlagene TextDiffuser-Modell erhebliche Fortschritte im Bereich der Textwiedergabe gemacht und ist in der Lage, qualitativ hochwertige Bilder mit lesbarem Text zu generieren. Zukünftig werden Forscher die Wirkung von TextDiffuser weiter verbessern.
Das obige ist der detaillierte Inhalt vonNeuer Titel: TextDiffuser: Keine Angst vor Text in Bildern, sorgt für eine qualitativ hochwertigere Textwiedergabe. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!