
Heim >Technologie-Peripheriegeräte >KI >Salesforce arbeitet mit MIT-Forschern zusammen, um GPT-4-Revisions-Tutorials als Open-Source-Tutorials zu erstellen, um mehr Informationen mit weniger Worten bereitzustellen
Salesforce arbeitet mit MIT-Forschern zusammen, um GPT-4-Revisions-Tutorials als Open-Source-Tutorials zu erstellen, um mehr Informationen mit weniger Worten bereitzustellen

- 王林nach vorne
- 2023-09-19 20:33:13905Durchsuche
Die automatische Zusammenfassungstechnologie hat in den letzten Jahren erhebliche Fortschritte gemacht, hauptsächlich aufgrund von Paradigmenwechseln. In der Vergangenheit stützte sich diese Technologie hauptsächlich auf die überwachte Feinabstimmung annotierter Datensätze, nutzt heute jedoch große Sprachmodelle (LLM) für Zero-Shot-Prompts, wie z. B. GPT-4. Durch sorgfältige Eingabeaufforderungseinstellungen kann eine genaue Kontrolle der Zusammenfassungslänge, des Themas, des Stils und anderer Funktionen ohne zusätzliche Schulung erreicht werden. Ein Aspekt wird jedoch häufig übersehen: die Informationsdichte der Zusammenfassung. Theoretisch sollte eine Zusammenfassung als Komprimierung eines anderen Textes dichter sein, also mehr Informationen enthalten als die Quelldatei. Angesichts der hohen Latenz der LLM-Dekodierung ist es wichtig, mehr Informationen mit weniger Wörtern abzudecken, insbesondere für Echtzeitanwendungen.
Die Informationsdichte ist jedoch eine offene Frage: Wenn die Zusammenfassung nicht genügend Details enthält, ist sie gleichbedeutend mit keiner Information; wenn sie zu viele Informationen enthält, ohne die Gesamtlänge zu erhöhen, wird sie schwer zu verstehen. Um innerhalb eines festen Token-Budgets mehr Informationen zu übermitteln, ist es notwendig, Abstraktion, Komprimierung und Fusion zu kombinieren.
In einer aktuellen Forschung haben Forscher von Salesforce, MIT und anderen versucht, die Grenzen der zunehmenden Dichte zu bestimmen, indem sie menschliche Präferenzen für eine Reihe von Zusammenfassungen erfragten, die von GPT-4 generiert wurden. Diese Methode bietet viele Inspirationen zur Verbesserung der „Ausdrucksfähigkeit“ großer Sprachmodelle wie GPT-4. /huggingface.co/datasets/griffin/chain_of_density
Konkret erstellten die Forscher eine erste Zusammenfassung mit geringer Entitätsdichte, indem sie die durchschnittliche Anzahl von Entitäten pro Token als Proxy für die Dichte verwendeten. Anschließend identifizieren und fusionieren sie iterativ die 1–3 Entitäten, die in der vorherigen Zusammenfassung fehlten, ohne die Gesamtlänge zu erhöhen (das Fünffache der Gesamtlänge). Jeder Digest hat ein höheres Entitäts-Token-Verhältnis als der vorherige Digest. Basierend auf menschlichen Präferenzdaten stellten die Autoren letztendlich fest, dass Menschen Zusammenfassungen bevorzugen, die fast so dicht sind wie von Menschen geschriebene Zusammenfassungen und dichter als Zusammenfassungen, die durch gewöhnliche GPT-4-Hinweise generiert werden. Der Gesamtbeitrag der Studie kann wie folgt zusammengefasst werden:

- Was bedeutet CoD?
Der Autor hat eine einzelne Chain of Density (CoD)-Eingabeaufforderung formuliert, die eine erste Zusammenfassung generiert und die Entitätsdichte kontinuierlich erhöht. Insbesondere wird innerhalb einer festgelegten Anzahl von Interaktionen ein eindeutiger Satz hervorstechender Entitäten im Quelltext identifiziert und in die vorherige Zusammenfassung eingefügt, ohne die Länge zu erhöhen.
Beispiele für Eingabeaufforderungen und Ausgaben sind in Abbildung 2 dargestellt. Der Autor gibt die Art der Entität nicht explizit an, definiert die fehlende Entität jedoch als:
Spezifisch: prägnant und auf den Punkt gebracht (5 Wörter oder weniger); Einzigartig: In der vorherigen Zusammenfassung nicht erwähnt;
- Getreu: im Artikel vorhanden; Irgendwo: irgendwo im Artikel enthalten.
-
Der Autor wählte zufällig 100 Artikel aus dem CNN/DailyMail-Zusammenfassungstestsatz aus, um CoD-Zusammenfassungen für sie zu erstellen. Um die Referenz zu erleichtern, verglichen sie die CoD-Zusammenfassungsstatistiken mit von Menschen verfassten Referenzzusammenfassungen mit Stichpunkten und Zusammenfassungen, die von GPT-4 unter der normalen Aufforderung generiert wurden: „Schreiben Sie eine sehr kurze Zusammenfassung des Artikels. Nicht mehr als 70 Wörter.“
Statistische Situation -
In der Studie fasste der Autor zwei Aspekte zusammen: direkte Statistik und indirekte Statistik. Direkte Statistiken (Tokens, Entitäten, Entitätsdichte) werden direkt von CoD gesteuert, während indirekte Statistiken ein erwartetes Nebenprodukt der Verdichtung sind.
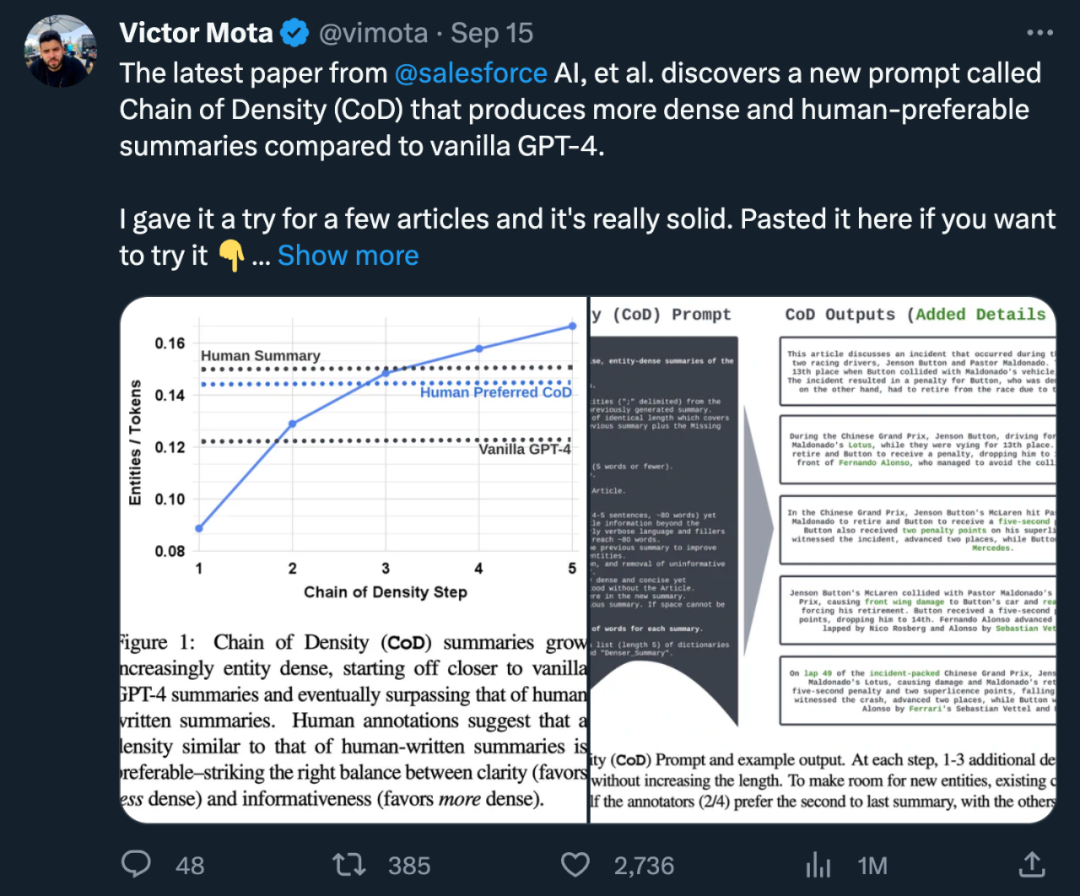
Direkte Statistiken. Wie in Tabelle 1 gezeigt, reduzierte der zweite Schritt die Länge um durchschnittlich 5 Token (von 72 auf 67), da unnötige Wörter aus der anfänglich langen Zusammenfassung entfernt wurden. Die Entitätsdichte beginnt bei 0,089 und ist zunächst niedriger als bei menschlichem und Vanille-GPT-4 (0,151 und 0,122) und steigt schließlich nach 5 Verdichtungsschritten auf 0,167 an.
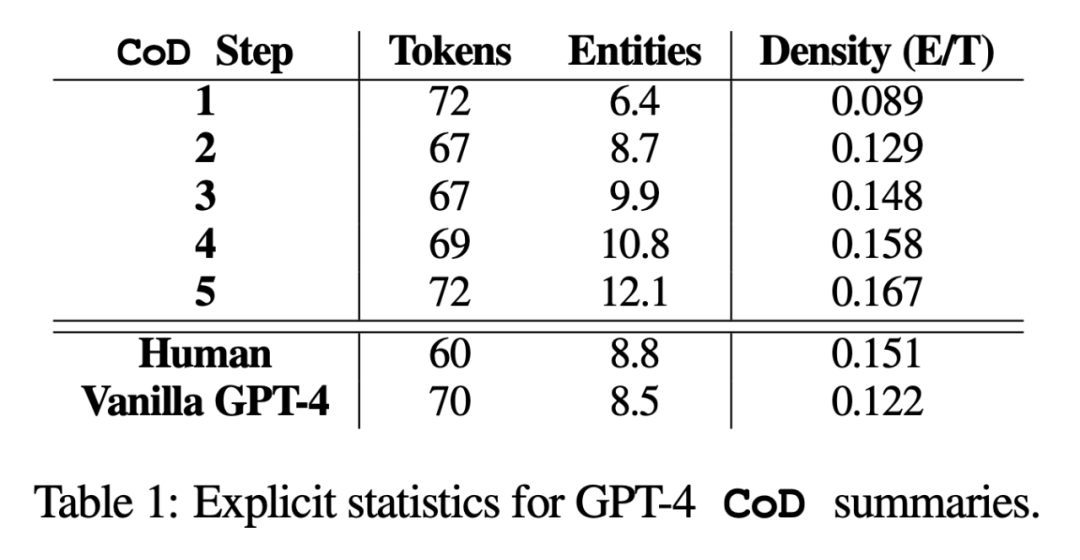 Indirekte Statistiken. Der Abstraktionsgrad sollte mit jedem CoD-Schritt steigen, da die Zusammenfassung immer wieder neu geschrieben wird, um Platz für jede zusätzliche Entität zu schaffen. Die Autoren messen die Abstraktion anhand der Extraktionsdichte: der durchschnittlichen Quadratlänge extrahierter Fragmente (Grusky et al., 2018). Ebenso sollte die Konzeptfusion monoton zunehmen, wenn Entitäten zu einer Zusammenfassung fester Länge hinzugefügt werden. Die Autoren drückten den Grad der Integration durch die durchschnittliche Anzahl der Quellsätze aus, die mit jedem zusammenfassenden Satz abgeglichen wurden. Zur Ausrichtung verwenden die Autoren die Methode der relativen ROUGE-Verstärkung (Zhou et al., 2018), die den Quellsatz so lange am Zielsatz ausrichtet, bis die relative ROUGE-Verstärkung der zusätzlichen Sätze nicht mehr positiv ist. Sie erwarteten auch Änderungen in der Inhaltsverteilung oder der Position innerhalb des Artikels, aus dem der zusammenfassende Inhalt stammt.
Indirekte Statistiken. Der Abstraktionsgrad sollte mit jedem CoD-Schritt steigen, da die Zusammenfassung immer wieder neu geschrieben wird, um Platz für jede zusätzliche Entität zu schaffen. Die Autoren messen die Abstraktion anhand der Extraktionsdichte: der durchschnittlichen Quadratlänge extrahierter Fragmente (Grusky et al., 2018). Ebenso sollte die Konzeptfusion monoton zunehmen, wenn Entitäten zu einer Zusammenfassung fester Länge hinzugefügt werden. Die Autoren drückten den Grad der Integration durch die durchschnittliche Anzahl der Quellsätze aus, die mit jedem zusammenfassenden Satz abgeglichen wurden. Zur Ausrichtung verwenden die Autoren die Methode der relativen ROUGE-Verstärkung (Zhou et al., 2018), die den Quellsatz so lange am Zielsatz ausrichtet, bis die relative ROUGE-Verstärkung der zusätzlichen Sätze nicht mehr positiv ist. Sie erwarteten auch Änderungen in der Inhaltsverteilung oder der Position innerhalb des Artikels, aus dem der zusammenfassende Inhalt stammt. Konkret gehen die Autoren davon aus, dass CoD-Abstracts zunächst einen starken „Lead Bias“ (Lead Bias) aufweisen, dann aber nach und nach beginnen, Entitäten ab der Mitte und am Ende des Artikels einzuführen. Um dies zu messen, verwendeten sie Alignment in Fusion, um Inhalte auf Chinesisch umzuschreiben, ohne dass der ursprüngliche Satz erschien, und maßen den durchschnittlichen Satzrang über alle ausgerichteten Quellsätze hinweg.
Abbildung 3 bestätigt diese Hypothesen: Mit zunehmender Anzahl der Umschreibeschritte nimmt die Abstraktion zu (das linke Bild zeigt eine geringere Extraktionsdichte), die Fusionsrate steigt (das mittlere Bild zeigt) und die Zusammenfassung beginnt, Inhalte aus der Mitte einzubeziehen und Ende des Artikels (rechts abgebildet). Interessanterweise sind alle CoD-Zusammenfassungen im Vergleich zu von Menschen verfassten Zusammenfassungen und Basiszusammenfassungen abstrakter Um den Kompromiss zwischen CoD-Zusammenfassungen zu verstehen, führten die Autoren eine präferenzbasierte Humanstudie durch und führten eine bewertungsbasierte Bewertung mit GPT-4 durch.
Menschliche Vorlieben. Konkret zeigte der Autor für dieselben 100 Artikel (5 Schritte * 100 = insgesamt 500 Abstracts) die „neu erstellten“ CoD-Abstracts und Artikel nach dem Zufallsprinzip den ersten vier Autoren des Papiers. Jeder Kommentator gab seine Lieblingszusammenfassung basierend auf der Definition einer „guten Zusammenfassung“ von Stiennon et al. (2020) ab. In Tabelle 2 sind die Erstplatzierungen jedes Annotators in der CoD-Phase sowie die Zusammenfassung jedes Annotators aufgeführt. Insgesamt umfassten 61 % der Abstracts mit dem ersten Platz (23,0+22,5+15,5) ≥3 Verdichtungsschritte. Die mittlere Anzahl der bevorzugten CoD-Schritte liegt im Mittelfeld (3), mit einer erwarteten Schrittzahl von 3,06.
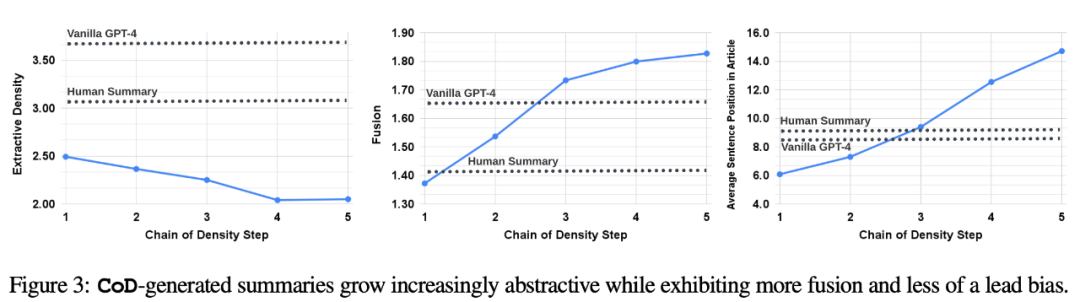
Basierend auf der durchschnittlichen Dichte im dritten Schritt beträgt die bevorzugte Entitätsdichte aller CoD-Kandidaten ungefähr 0,15. Wie aus Tabelle 1 ersichtlich ist, stimmt diese Dichte mit von Menschen verfassten Zusammenfassungen (0,151) überein, ist jedoch deutlich höher als mit Zusammenfassungen, die mit der einfachen GPT-4-Eingabeaufforderung (0,122) geschrieben wurden –
automatische Metrik. Als Ergänzung zur menschlichen Bewertung (unten) verwendeten die Autoren GPT-4, um CoD-Zusammenfassungen (1–5 Punkte) in fünf Dimensionen zu bewerten: Informativität, Qualität, Kohärenz, Zuordenbarkeit und Gesamtheit. Wie in Tabelle 3 gezeigt, korreliert die Dichte mit der Aussagekraft, allerdings bis zu einem gewissen Grad, wobei die Punktzahl bei Stufe 4 (4,74) ihren Höhepunkt erreicht.
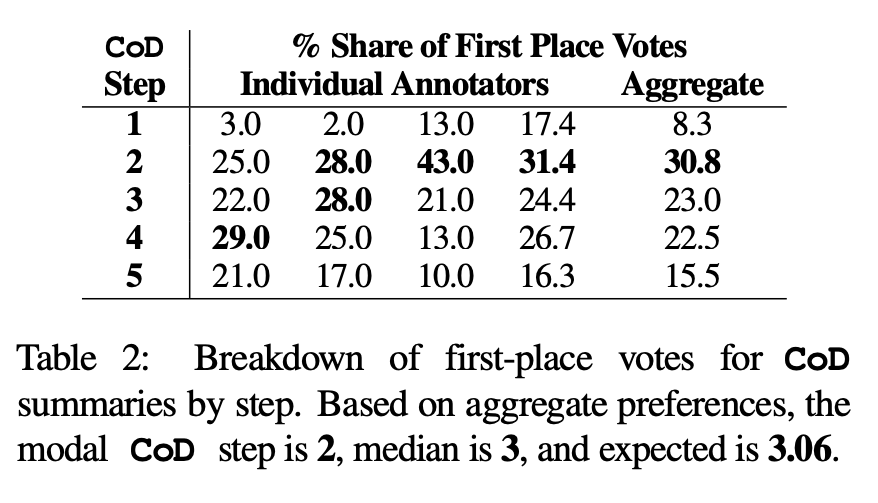 Aus den Durchschnittswerten jeder Dimension weisen die erste und letzte Stufe von CoD die niedrigsten Werte auf, während die mittleren drei Stufen nahe beieinander liegende Werte aufweisen (4,78, 4,77 bzw. 4,76).
Aus den Durchschnittswerten jeder Dimension weisen die erste und letzte Stufe von CoD die niedrigsten Werte auf, während die mittleren drei Stufen nahe beieinander liegende Werte aufweisen (4,78, 4,77 bzw. 4,76). Qualitative Analyse. Es gibt einen klaren Kompromiss zwischen abstrakter Kohärenz/Lesbarkeit und Informationsgehalt. In Abbildung 4 sind zwei CoD-Schritte dargestellt: Die Zusammenfassung eines Schritts wird durch mehr Details verbessert, während die Zusammenfassung des anderen Schritts beeinträchtigt wird. Im Durchschnitt erreichen CoD-Zwischenzusammenfassungen dieses Gleichgewicht am besten, dieser Kompromiss muss jedoch in zukünftigen Arbeiten noch genau definiert und quantifiziert werden.
Weitere Einzelheiten zum Papier finden Sie im Originalpapier.
Das obige ist der detaillierte Inhalt vonSalesforce arbeitet mit MIT-Forschern zusammen, um GPT-4-Revisions-Tutorials als Open-Source-Tutorials zu erstellen, um mehr Informationen mit weniger Worten bereitzustellen. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Was sind die Anforderungen an einen guten Front-End-Entwicklungsingenieur?
- Sind Softwareentwickler Programmierer?
- Welche Technologien müssen Java-Ingenieure beherrschen?
- Zum ersten Mal: Microsoft verwendet GPT-4 zur Feinabstimmung großer Modellanweisungen und die Zero-Sample-Leistung neuer Aufgaben wird weiter verbessert.
- Der Bing Chat-Chatbot von Microsoft wurde aktualisiert, um die neueste OpenAI GPT-4-Technologie zu verwenden