
Heim >Technologie-Peripheriegeräte >KI >Was ist die Quelle der kontextuellen Lernfähigkeiten von Transformer?
Was ist die Quelle der kontextuellen Lernfähigkeiten von Transformer?

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBnach vorne
- 2023-09-18 08:01:141483Durchsuche
Warum funktioniert der Transformator so gut? Woher kommt die In-Context-Learning-Fähigkeit, die es vielen großen Sprachmodellen bietet? Im Bereich der künstlichen Intelligenz hat sich der Transformer zum dominierenden Modell des Deep Learning entwickelt, die theoretischen Grundlagen für seine hervorragende Leistung sind jedoch nur unzureichend untersucht.
Kürzlich haben Forscher von Google AI, der ETH Zürich und Google DeepMind eine neue Studie durchgeführt, um zu versuchen, die Geheimnisse einiger Optimierungsalgorithmen in Google AI aufzudecken. In dieser Studie haben sie den Transformator rückentwickelt und einige Optimierungsmethoden gefunden. Dieses Papier heißt „Revealing the Mesa Optimization Algorithm in Transformer“
Link zum Papier: https://arxiv.org/abs/2309.05858
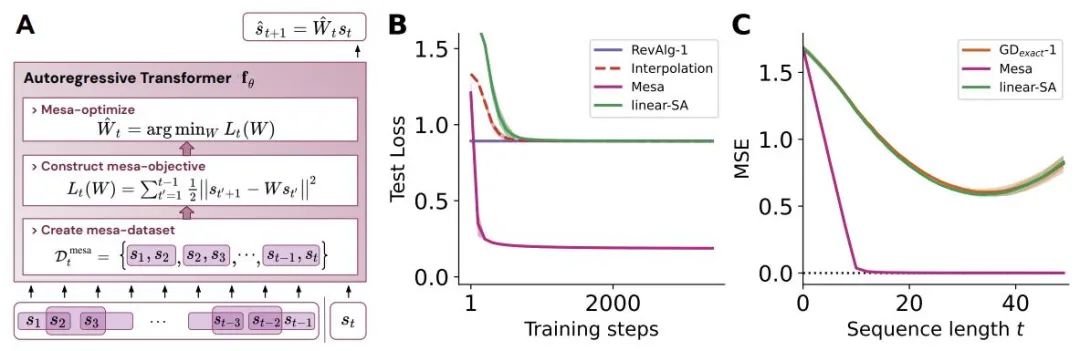
Der Autor beweist, dass die Minimierung des universellen autoregressiven Verlusts An erzeugt Hilfs-Gradienten-basierter Optimierungsalgorithmus, der im Vorwärtsdurchlauf des Transformers ausgeführt wird. Dieses Phänomen wurde kürzlich als „Mesa-Optimierung“ bezeichnet. Darüber hinaus stellten die Forscher fest, dass der resultierende Mesa-Optimierungsalgorithmus unabhängig von der Modellgröße kontextbezogene Small-Shot-Lernfähigkeiten aufwies. Die neuen Ergebnisse ergänzen daher die Prinzipien des Small-Shot-Lernens, die zuvor in großen Sprachmodellen zum Vorschein kamen.
Die Forscher glauben, dass der Erfolg von Transformers auf der architektonischen Ausrichtung des Mesa-Optimierungsalgorithmus basiert, den es im Vorwärtsdurchlauf implementiert: (i) Definition interner Lernziele und (ii) Optimierung dieser
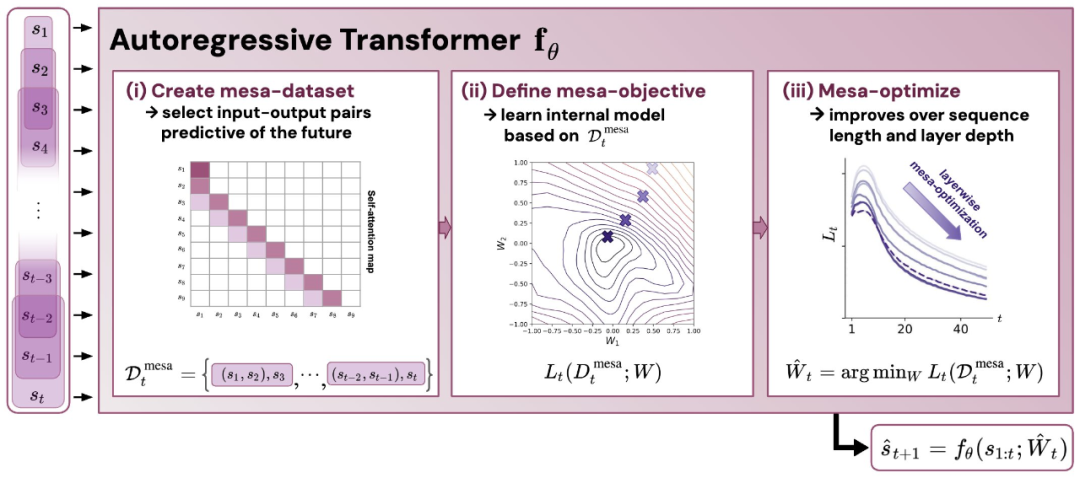
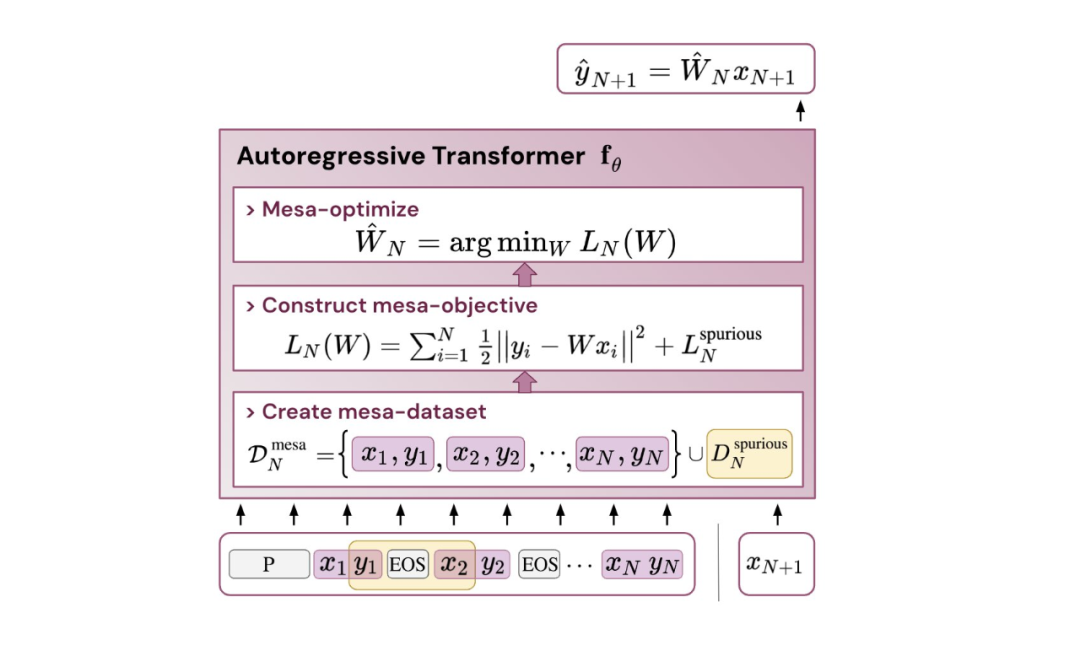
Abbildung 1: Illustration der neuen Hypothese: Die Optimierung der Gewichte θ des autoregressiven Transformators fθ führt zu einem Mesa-Optimierungsalgorithmus, der in der Vorwärtsausbreitung des Modells implementiert ist. Als Eingabesequenz s_1, . . , s_t wird bis zum Zeitschritt t verarbeitet, Transformer (i) erstellt einen internen Trainingssatz bestehend aus Eingabe-Ziel-Assoziationspaaren, (ii) definiert eine interne Zielfunktion über den Ergebnisdatensatz, die zur Messung der Leistung des internen Modells verwendet wird unter Verwendung der Gewichte W, (iii) Optimieren Sie dieses Ziel und verwenden Sie das erlernte Modell, um zukünftige Vorhersagen zu generieren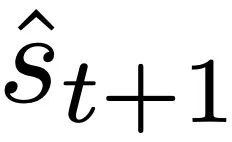 .
.
Die Beiträge dieser Studie umfassen Folgendes:
- Verallgemeinert die Theorie von Oswald et al. und zeigt, wie Transformer theoretisch intern konstruierte Ziele aus der Regression mithilfe von Gradienten-basierten Methoden optimieren und das nächste Element vorhersagen können Sequenz.
- Experimentell rückentwickelte Transformer trainierten einfache Sequenzmodellierungsaufgaben und fanden starke Beweise dafür, dass ihr Vorwärtsdurchlauf einen zweistufigen Algorithmus implementiert: (i) Frühe Selbstaufmerksamkeitsschicht über Gruppierungs- und Kopiermarkierungen baut den internen Trainingsdatensatz auf Der interne Trainingsdatensatz wird implizit erstellt. Definieren Sie interne Zielfunktionen und (ii) optimieren Sie diese Ziele auf einer tieferen Ebene, um Vorhersagen zu generieren.
- Ähnlich wie bei LLM zeigen Experimente, dass auch einfache autoregressive Trainingsmodelle zu Kontextlernern werden können, und spontane Anpassungen sind entscheidend für die Verbesserung des Kontextlernens von LLM und können auch die Leistung in bestimmten Umgebungen verbessern.
- Inspiriert durch die Entdeckung, dass Aufmerksamkeitsschichten versuchen, die interne Zielfunktion implizit zu optimieren, stellt der Autor die Mesa-Schicht vor, eine neue Art von Aufmerksamkeitsschicht, die das Optimierungsproblem der kleinsten Quadrate effektiv lösen kann, anstatt nur einzelne Gradientenschritte durchzuführen Optimalität zu erreichen. Experimente zeigen, dass eine einzelne Mesa-Schicht Deep-Linear- und Softmax-Selbstaufmerksamkeitstransformatoren bei einfachen sequentiellen Aufgaben übertrifft und gleichzeitig eine bessere Interpretierbarkeit bietet.

- Nach vorläufigen Sprachmodellierungsexperimenten wurde festgestellt, dass das Ersetzen der Standard-Selbstaufmerksamkeitsschicht durch die Mesa-Schicht vielversprechende Ergebnisse erzielte, was beweist, dass diese Schicht über starke kontextbezogene Lernfähigkeiten verfügt.
Basierend auf aktuellen Arbeiten, die zeigen, dass Transformatoren, die explizit darauf trainiert sind, kleine Aufgaben im Kontext zu lösen, Gradientenabstiegsalgorithmen (GD) implementieren können. Hier zeigen die Autoren, dass sich diese Ergebnisse auf die autoregressive Sequenzmodellierung übertragen lassen – einen typischen Ansatz zum Training von LLMs.
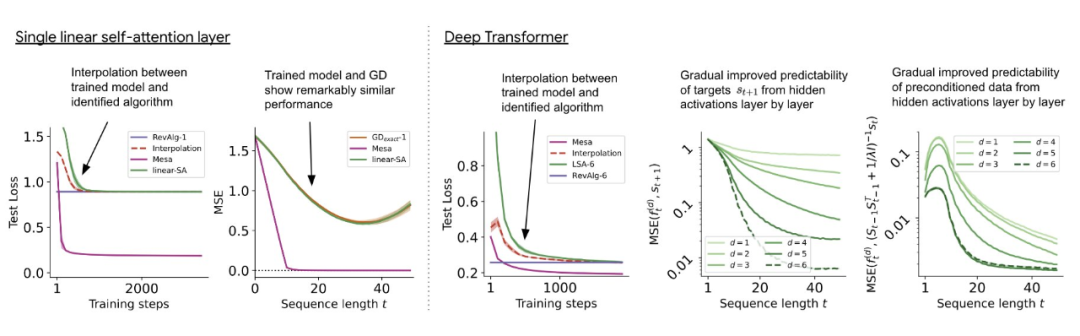
Analysieren Sie zunächst den auf einfache lineare Dynamik trainierten Transformer. In diesem Fall wird jede Sequenz von einem anderen W* generiert, um eine sequenzübergreifende Speicherung zu verhindern. In diesem einfachen Aufbau zeigen die Forscher, wie Transformer einen Mesa-Datensatz erstellt und vorverarbeitete GD verwendet, um das Mesa-Ziel zu optimieren
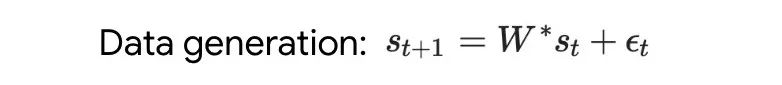
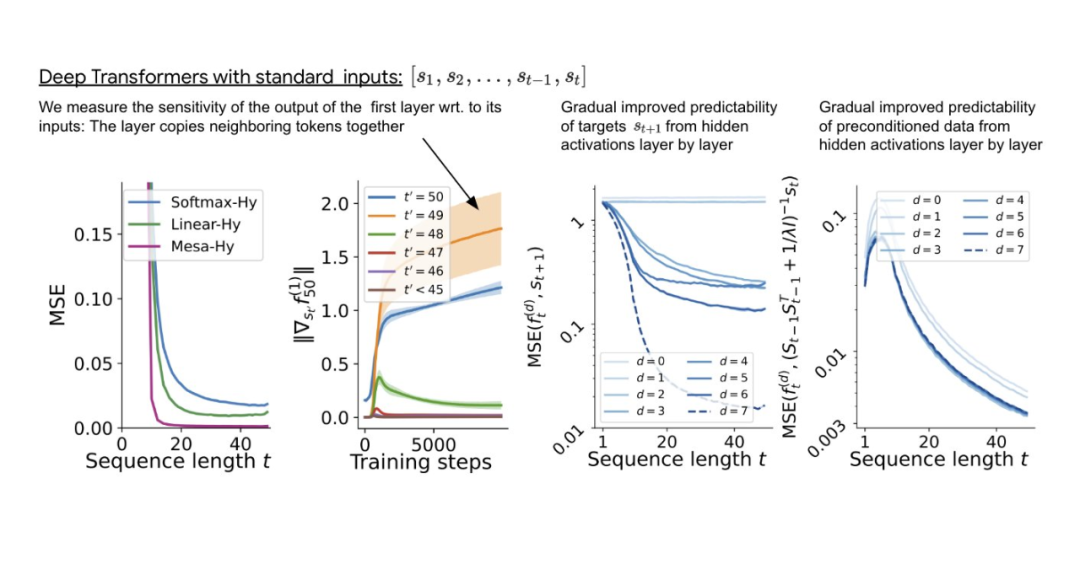
Der umgeschriebene Inhalt lautet: Wir können die Token-Struktur benachbarter Sequenzelemente aggregieren, indem wir einen Tiefentransformator trainieren. Interessanterweise führt diese einfache Vorverarbeitungsmethode zu einer sehr spärlichen Gewichtsmatrix (weniger als 1 % der Gewichte sind ungleich Null), was zu einem Reverse-Engineering-Algorithmus führt Gewichte Entspricht einem Gradientenabstiegsschritt. Für tiefe Transformer wird die Interpretierbarkeit schwierig. Die Studie basiert auf linearem Sondieren und untersucht, ob versteckte Aktivierungen in der Lage sind, autoregressive Ziele oder vorverarbeitete Eingaben vorherzusagen.
 Interessanterweise verbessert sich die Vorhersagbarkeit beider Sondierungsmethoden mit zunehmender Netzwerktiefe allmählich. Dieser Befund legt nahe, dass vorverarbeitete GD im Modell verborgen ist.
Interessanterweise verbessert sich die Vorhersagbarkeit beider Sondierungsmethoden mit zunehmender Netzwerktiefe allmählich. Dieser Befund legt nahe, dass vorverarbeitete GD im Modell verborgen ist.
Abbildung 2: Reverse Engineering einer trainierten linearen Selbstaufmerksamkeitsschicht.
 Die Studie ergab, dass die Trainingsschicht perfekt angepasst werden kann, wenn alle Freiheitsgrade in der Konstruktion genutzt werden, einschließlich nicht nur der erlernten Lernrate η, sondern auch einer Reihe erlernter Anfangsgewichte W_0. Wichtig ist, dass der erlernte einstufige Algorithmus, wie in Abbildung 2 dargestellt, immer noch eine weitaus bessere Leistung erbringt als eine einzelne Mesa-Schicht.
Die Studie ergab, dass die Trainingsschicht perfekt angepasst werden kann, wenn alle Freiheitsgrade in der Konstruktion genutzt werden, einschließlich nicht nur der erlernten Lernrate η, sondern auch einer Reihe erlernter Anfangsgewichte W_0. Wichtig ist, dass der erlernte einstufige Algorithmus, wie in Abbildung 2 dargestellt, immer noch eine weitaus bessere Leistung erbringt als eine einzelne Mesa-Schicht.
Mit einer einfachen Gewichtseinstellung können wir feststellen, dass es durch grundlegende Optimierung leicht ist, herauszufinden, dass diese Ebene diese Forschungsaufgabe optimal lösen kann. Dieses Ergebnis beweist, dass eine hartcodierte induktive Vorspannung für die Mesa-Optimierung von Vorteil ist
Mit theoretischen Einblicken in den Mehrschichtfall analysieren Sie zunächst Deep Linear und Softmax und achten Sie nur auf Transformer. Die Autoren formatieren die Eingabe gemäß einer 4-Kanal-Struktur,
, was der Wahl von W_0 = 0 entspricht.
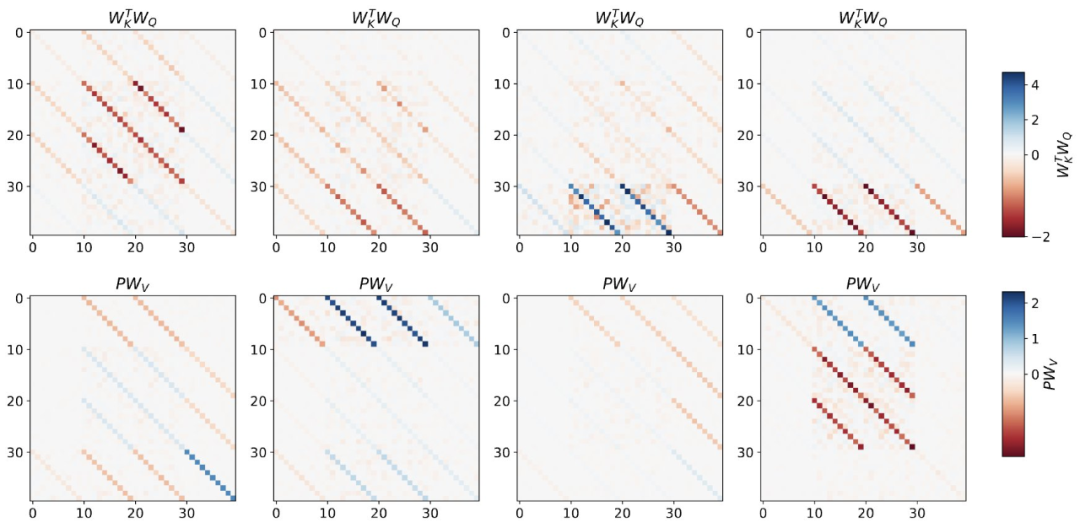
Wie beim einschichtigen Modell sehen die Autoren eine klare Struktur in den Gewichten des trainierten Modells. Als erste Reverse-Engineering-Analyse nutzt diese Studie diese Struktur und erstellt einen Algorithmus (RevAlg-d, wobei d die Anzahl der Schichten darstellt), der 16 Parameter pro Schichtkopf (anstelle von 3200) enthält. Die Autoren fanden heraus, dass dieser komprimierte, aber komplexe Ausdruck das trainierte Modell beschreiben kann. Insbesondere ermöglicht es eine nahezu verlustfreie Interpolation zwischen den tatsächlichen Transformer- und RevAlg-d-Gewichten 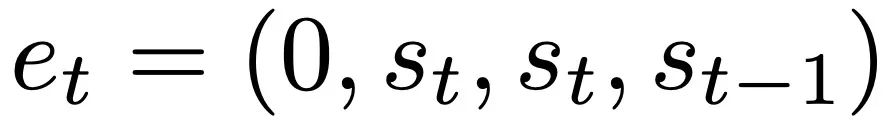 Während der RevAlg-d-Ausdruck einen trainierten mehrschichtigen Transformer mit einer kleinen Anzahl freier Parameter erklärt, ist die Konvertierung schwierig Seine Erklärung ist der Mesa-Optimierungsalgorithmus. Daher verwendeten die Autoren eine lineare Regressionsuntersuchungsanalyse (Alain & Bengio, 2017; Akyürek et al., 2023), um die Eigenschaften des hypothetischen Mesa-Optimierungsalgorithmus zu ermitteln.
Während der RevAlg-d-Ausdruck einen trainierten mehrschichtigen Transformer mit einer kleinen Anzahl freier Parameter erklärt, ist die Konvertierung schwierig Seine Erklärung ist der Mesa-Optimierungsalgorithmus. Daher verwendeten die Autoren eine lineare Regressionsuntersuchungsanalyse (Alain & Bengio, 2017; Akyürek et al., 2023), um die Eigenschaften des hypothetischen Mesa-Optimierungsalgorithmus zu ermitteln.
Auf dem in Abbildung 3 gezeigten tiefen linearen Selbstaufmerksamkeitstransformator können wir beobachten, dass beide Sonden zur linearen Dekodierung fähig sind und mit zunehmender Sequenzlänge und Netzwerktiefe auch die Dekodierungsleistung zunimmt. Daher haben wir einen grundlegenden Optimierungsalgorithmus entdeckt, der basierend auf dem ursprünglichen Mesa-Ziel Lt (W) Schicht für Schicht absteigt und gleichzeitig die Bedingungszahl des Mesa-Optimierungsproblems verbessert. Dies führt zu einem raschen Rückgang des Mesa-Ziel-Lt (W). Darüber hinaus können wir auch beobachten, dass sich die Leistung mit zunehmender Tiefe deutlich verbessert
Mit einer besseren Vorverarbeitung der Daten kann die autoregressive Zielfunktion Lt (W) schrittweise (über Schichten hinweg) optimiert werden, sodass ein schneller Rückgang berücksichtigt werden kann Dies wird durch diese Optimierung erreicht
Abbildung 3: Mehrschichtiges Transformer-Training für Reverse Engineering der konstruierten Token-Eingabe.
 Dies zeigt, dass der Transformator, wenn er auf dem erstellten Token trainiert wird, mit Mesa-Optimierung Vorhersagen trifft. Wenn Sequenzelemente direkt angegeben werden, erstellt der Transformator interessanterweise das Token selbst, indem er die Elemente gruppiert, was das Forschungsteam als „Erstellen des Mesa-Datensatzes“ bezeichnet.
Dies zeigt, dass der Transformator, wenn er auf dem erstellten Token trainiert wird, mit Mesa-Optimierung Vorhersagen trifft. Wenn Sequenzelemente direkt angegeben werden, erstellt der Transformator interessanterweise das Token selbst, indem er die Elemente gruppiert, was das Forschungsteam als „Erstellen des Mesa-Datensatzes“ bezeichnet.
Schlussfolgerung
Das Ergebnis dieser Studie ist, dass Gradienten-basierte Inferenzalgorithmen entwickelt werden können, wenn sie mit dem Transformer-Modell für Sequenzvorhersageaufgaben unter standardmäßigen autoregressiven Zielen trainiert werden. Daher können die neuesten Multitasking- und Meta-Learning-Ergebnisse auch auf traditionelle selbstüberwachte LLM-Trainingseinstellungen angewendet werden
Darüber hinaus ergab die Studie, dass der erlernte autoregressive Inferenzalgorithmus ohne erneutes Training neu abgestimmt werden kann um überwachte kontextuelle Lernaufgaben zu lösen und so die Ergebnisse in einem einheitlichen Rahmen zu interpretieren
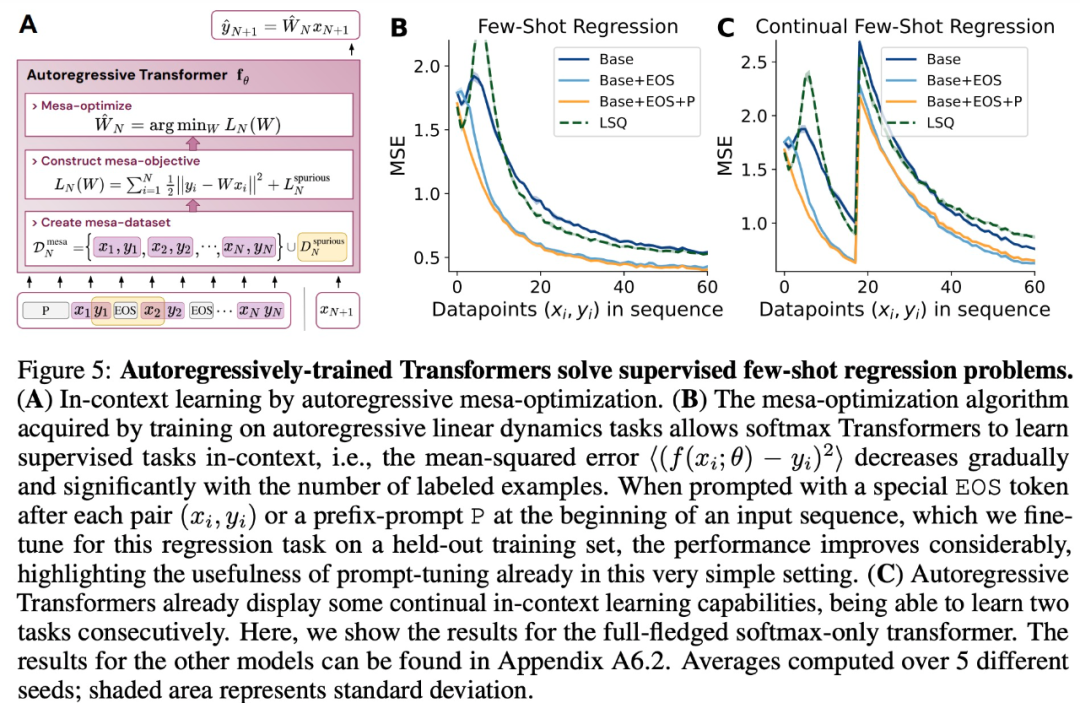
Was hat das also mit kontextuellem Lernen zu tun? Der Studie zufolge erreicht das Transformatormodell nach dem Training der autoregressiven Sequenzaufgabe eine angemessene Mesa-Optimierung und kann daher ein Kontextlernen mit wenigen Schüssen ohne Feinabstimmung durchführen. Die Studie geht davon aus, dass auch LLM existiert Mesa-Optimierung, wodurch die kontextbezogenen Lernfähigkeiten verbessert werden. Interessanterweise wurde in der Studie auch festgestellt, dass die effektive Anpassung von Eingabeaufforderungen für LLM auch zu erheblichen Verbesserungen der kontextuellen Lernfähigkeiten führen kann.
Interessierte Leser können den Originaltext des Artikels lesen, um mehr über den Forschungsinhalt zu erfahren.
Das obige ist der detaillierte Inhalt vonWas ist die Quelle der kontextuellen Lernfähigkeiten von Transformer?. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Welche Einsatzmöglichkeiten gibt es für künstliche Intelligenz in der Medizin?
- Beschreiben Sie kurz, was die Speichereinheit für Daten in einem Computer ist.
- Was sind die Hauptanwendungsrichtungen künstlicher Intelligenz im medizinischen Bereich?
- Was sind die grundlegenden Merkmale von Daten?
- Welche Beziehung besteht zwischen künstlicher Intelligenz, maschinellem Lernen und Deep Learning?