
Heim >Technologie-Peripheriegeräte >KI >Neuer Durchbruch in der „interaktiven Generierung von Personen und Szenen'! Tianda University und Tsinghua University veröffentlichen Narrator: textgesteuert, natürlich kontrollierbar |
Neuer Durchbruch in der „interaktiven Generierung von Personen und Szenen'! Tianda University und Tsinghua University veröffentlichen Narrator: textgesteuert, natürlich kontrollierbar |

- PHPznach vorne
- 2023-09-11 23:13:05960Durchsuche
Die Erzeugung natürlicher und kontrollierbarer Human Scene Interaction (HSI) spielt in vielen Bereichen wie der Erstellung von Virtual Reality/Augmented Reality (VR/AR)-Inhalten und der auf den Menschen ausgerichteten künstlichen Intelligenz eine wichtige Rolle.
Bestehende Methoden weisen jedoch eine begrenzte Steuerbarkeit, begrenzte Interaktionstypen und unnatürlich erzeugte Ergebnisse auf, was ihre Anwendungsszenarien im wirklichen Leben erheblich einschränkt.
In der Forschung von ICCV 2023 haben die Universitäten Tianjin und Tsinghua ein Team gebildet mit einer Lösung namens Narrator, um dieses Problem zu untersuchen. Diese Lösung konzentriert sich auf die herausfordernde Aufgabe, auf natürliche und kontrollierte Weise realistische und vielfältige Interaktionen zwischen Mensch und Szene aus Textbeschreibungen zu generieren. likun/projects/Narrator
Der umgeschriebene Inhalt lautet: Code-Link: https://github.com/HaibiaoXuan/Narrator
 Aus der Perspektive der menschlichen Kognition sollte das generative Modell idealerweise in der Lage sein, räumliche Beziehungen richtig zu beurteilen und erkunden Sie die Freiheitsgrade von Interaktionen.
Aus der Perspektive der menschlichen Kognition sollte das generative Modell idealerweise in der Lage sein, räumliche Beziehungen richtig zu beurteilen und erkunden Sie die Freiheitsgrade von Interaktionen.
Der umgeschriebene Inhalt lautet wie folgt: Gemäß Abbildung 1 kann der Erzähler auf natürliche und kontrollierte Weise semantisch konsistente und physikalisch sinnvolle Mensch-Szenen-Interaktionen erzeugen, die auf die folgenden Situationen anwendbar sind: (a) durch Raumbeziehung -Geführte Interaktion, (b) Interaktion, die durch mehrere Aktionen gesteuert wird, (c) Interaktion zwischen mehreren Personen und (d) Interaktion zwischen Person und Szene, die die oben genannten Interaktionstypen kombiniert
Konkret können räumliche Beziehungen verwendet werden, um die Wechselbeziehungen zwischen zu beschreiben verschiedene Objekte in einer Szene oder einem lokalen Bereich. Interaktive Aktionen werden durch den Zustand atomarer Körperteile spezifiziert, wie z. B. die Füße einer Person auf dem Boden, sich auf den Oberkörper stützen, mit der rechten Hand klopfen, den Kopf senken usw.
Mit diesem Ausgangspunkt wird die Der Autor verwendet Szenendiagramme, um räumliche Beziehungen darzustellen, und schlägt vor, dass er einen JGLSG-Mechanismus (Joint Global and Local Scene Graph) verwendet, um eine globale Positionserkennung für die nachfolgende Generation bereitzustellen. 
Abbildung 2 Übersicht über das Narrator-Framework
Wie in Abbildung 2 gezeigt, verwendet diese Methode einen auf Transformer basierenden Conditional Variational Autoencoder (cVAE), der hauptsächlich die folgenden Mehrere umfasst Teile:
Im Vergleich zu bestehenden Forschungsergebnissen entwerfen wir einen gemeinsamen Mechanismus für globale und lokale Szenendiagramme, um über komplexe räumliche Beziehungen nachzudenken und ein globales Positionierungsbewusstsein zu erreichen. 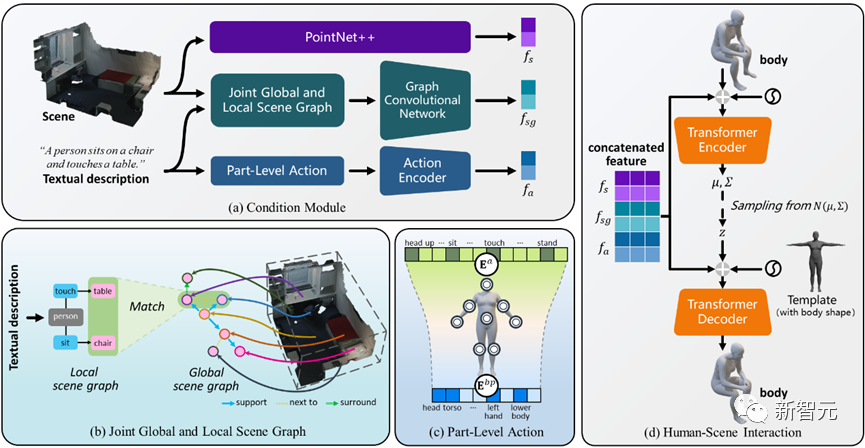
4) Erweitert sich weiter auf die Generierung von Mehrpersonen-Interaktionen und fördert letztendlich den ersten Schritt in der Mehrpersonen-Szeneninteraktion.
Kombinierter globaler und lokaler Szenendiagrammmechanismus
Die Begründung räumlicher Beziehungen kann dem Modell szenenspezifische Hinweise liefern, was eine wichtige Rolle bei der Erzielung einer natürlichen Steuerbarkeit der Interaktion zwischen Mensch und Szene spielt.
Um dieses Ziel zu erreichen, schlägt der Autor einen gemeinsamen Mechanismus für globale und lokale Szenendiagramme vor, der durch die folgenden drei Schritte implementiert wird:
1. Globale Szenendiagrammgenerierung: Verwenden Sie bei gegebener Szene vorab das Training Das Szenendiagrammmodell generiert ein globales Szenendiagramm, d. h.  , wobei
, wobei  ,
,  Objekte mit Kategoriebezeichnungen sind,
Objekte mit Kategoriebezeichnungen sind, 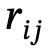 die Beziehung zwischen
die Beziehung zwischen 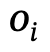 und
und 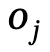 ist, n die Anzahl der Objekte ist, m die Anzahl der Beziehungen ist;
ist, n die Anzahl der Objekte ist, m die Anzahl der Beziehungen ist;
, wobei
das Triplett von Subjekt-Prädikat-Objekt definiert;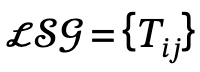
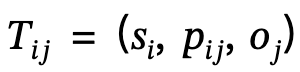
Der Autor nutzt geometrische und physikalische Einschränkungen für die szenenbezogene Optimierung, um die Generierungsergebnisse zu verbessern. Während des gesamten Optimierungsprozesses stellt diese Methode sicher, dass die generierte Pose nicht abweicht, während sie gleichzeitig den Kontakt mit der Szene fördert und den Körper einschränkt, um eine gegenseitige Durchdringung mit der Szene zu vermeiden
Angesichts der dreidimensionalen Szene S und der generierten SMPL-X-Parameter , der Optimierungsverlust beträgt:
Dazu gehört 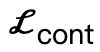 , dass Körperscheitelpunkte mit der Szene in Kontakt kommen;
, dass Körperscheitelpunkte mit der Szene in Kontakt kommen; 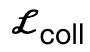 ist ein Kollisionsbegriff, der auf der vorzeichenbehafteten Distanz basiert; Szene und abgetasteter menschlicher Körper.
ist ein Kollisionsbegriff, der auf der vorzeichenbehafteten Distanz basiert; Szene und abgetasteter menschlicher Körper. 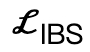 ist ein Regularisierungsfaktor, der verwendet wird, um Parameter zu bestrafen, die von der Initialisierung abweichen.
ist ein Regularisierungsfaktor, der verwendet wird, um Parameter zu bestrafen, die von der Initialisierung abweichen. 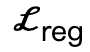
und interaktive Aktionen 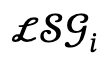 und definiert den Kandidatensatz als
und definiert den Kandidatensatz als 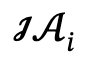 , wobei l die Anzahl der Personen ist.
, wobei l die Anzahl der Personen ist. 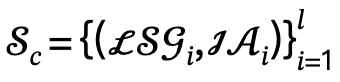
und dem entsprechenden globalen Szenendiagramm  in Narrator eingegeben und dann der Optimierungsprozess durchgeführt.
in Narrator eingegeben und dann der Optimierungsprozess durchgeführt. 
eingeführt, wobei 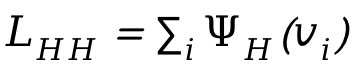 der vorzeichenbehaftete Abstand zwischen Personen ist.
der vorzeichenbehaftete Abstand zwischen Personen ist. 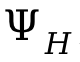
durch Hinzufügen menschlicher Knoten; andernfalls wird das generierte Ergebnis als nicht vertrauenswürdig betrachtet und aktualisiert  durch Abschirmung des entsprechenden Objektknotens.
durch Abschirmung des entsprechenden Objektknotens. 
 Bilder
Bilder
Abbildung 3 Qualitative Vergleichsergebnisse verschiedener Methoden
Abbildung 3 zeigt die qualitativen Vergleichsergebnisse von Narrator und drei Basislinien. Aufgrund der Darstellungsbeschränkungen von PiGraph-Text treten schwerwiegendere Penetrationsprobleme auf.
POSA-Text fällt während des Optimierungsprozesses häufig in lokale Minima, was zu schlechten interaktiven Kontakten führt. COINS-Text bindet Aktionen an bestimmte Objekte, es mangelt ihm an globalem Bewusstsein für die Szene, er führt zu einer Durchdringung mit nicht spezifizierten Objekten und es ist schwierig, mit komplexen räumlichen Beziehungen umzugehen.
Im Gegensatz dazu kann der Erzähler auf der Grundlage verschiedener Ebenen von Textbeschreibungen korrekte Überlegungen zu räumlichen Beziehungen anstellen und Körperzustände bei mehreren Aktionen analysieren, wodurch bessere Generierungsergebnisse erzielt werden.
In Bezug auf den quantitativen Vergleich übertrifft Narrator, wie in Tabelle 1 gezeigt, andere Methoden in fünf Indikatoren, was zeigt, dass die mit dieser Methode generierten Ergebnisse eine genauere Textkonsistenz und eine bessere physische Plausibilität aufweisen.
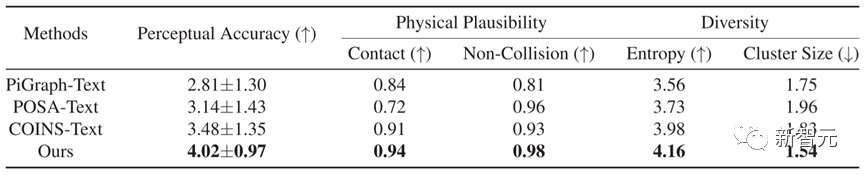 Tabelle 1 Quantitative Vergleichsergebnisse verschiedener Methoden
Tabelle 1 Quantitative Vergleichsergebnisse verschiedener Methoden
Darüber hinaus bietet der Autor detaillierte Vergleiche und Analysen, um die Wirksamkeit der vorgeschlagenen MHSI-Strategie besser zu verstehen.
Angesichts der Tatsache, dass es derzeit keine Arbeit an MHSI gibt, wählten sie einen unkomplizierten Ansatz als Basis, nämlich sequentielle Generierung und Optimierung mit COINS.
Um einen fairen Vergleich zu ermöglichen, wird auch ein künstlicher Kollisionsverlust eingeführt. Abbildung 4 und Tabelle 2 zeigen die qualitativen bzw. quantitativen Ergebnisse, die beide deutlich beweisen, dass die vom Autor vorgeschlagene Strategie auf MHSI semantisch konsistent und physikalisch sinnvoll ist.
 Abbildung 4 Qualitativer Vergleich mit MHSI unter Verwendung der sequentiellen Generierungs- und Optimierungsmethode von COINS
Abbildung 4 Qualitativer Vergleich mit MHSI unter Verwendung der sequentiellen Generierungs- und Optimierungsmethode von COINS

Über den Autor

Die Hauptrichtungen der Forschung umfassen drei -dimensionales Sehen, Computer Vision und Erzeugung von Interaktionen zwischen Mensch und Szene

Hauptforschungsrichtungen: dreidimensionales Sehen, Computer Vision, Rekonstruktion des menschlichen Körpers und der Kleidung

Die Forschungsrichtungen umfassen hauptsächlich dreidimensionales Sehen Vision, Computer Vision und Bilderzeugung. Die Forschungsrichtung konzentriert sich hauptsächlich auf menschzentrierte Computer Vision und Grafik. Hauptforschungsrichtungen: Computergrafik, dreidimensionales Sehen und Computerfotografie
Persönlicher Homepage-Link: https://liuyebin.com/
[ 1] Savva M, Chang A M, Ghosh P, Tesch J, et al. 14718.
 [3] Zhao K, Wang S, Zhang Y, et al. Kompositionelle Mensch-Szenen-Interaktionssynthese mit semantischer Kontrolle[C].
[3] Zhao K, Wang S, Zhang Y, et al. Kompositionelle Mensch-Szenen-Interaktionssynthese mit semantischer Kontrolle[C].
Das obige ist der detaillierte Inhalt vonNeuer Durchbruch in der „interaktiven Generierung von Personen und Szenen'! Tianda University und Tsinghua University veröffentlichen Narrator: textgesteuert, natürlich kontrollierbar |. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- So ändern Sie Szenen in PS-Fotos
- Welche anwendbaren Szenarien gibt es für das Singleton-Muster?
- Je nach Anwendungsszenario können Roboter in verschiedene Typen unterteilt werden
- Das Team von Zhu Jun hat das erste groß angelegte multimodale Diffusionsmodell auf Basis von Transformer an der Tsinghua-Universität als Open-Source-Lösung erstellt und es nach dem Umschreiben von Text und Bildern vollständig fertiggestellt.
- Empfohlene Reihe von KI-Lehrbüchern, die Industrie und Bildung integrieren ‖ Baidu schließt sich mit dem Tsinghua-Verlag zusammen, um bei der Förderung von KI-Talenten zu helfen