
Heim >Technologie-Peripheriegeräte >KI >Das Team von Zhu Jun hat das erste groß angelegte multimodale Diffusionsmodell auf Basis von Transformer an der Tsinghua-Universität als Open-Source-Lösung erstellt und es nach dem Umschreiben von Text und Bildern vollständig fertiggestellt.
Das Team von Zhu Jun hat das erste groß angelegte multimodale Diffusionsmodell auf Basis von Transformer an der Tsinghua-Universität als Open-Source-Lösung erstellt und es nach dem Umschreiben von Text und Bildern vollständig fertiggestellt.

- PHPznach vorne
- 2023-05-08 20:34:081531Durchsuche
Es wird berichtet, dass GPT-4 diese Woche veröffentlicht wird und Multimodalität zu einem seiner Highlights wird. Das aktuelle große Sprachmodell wird zu einer universellen Schnittstelle zum Verständnis verschiedener Modalitäten und kann Antworttexte basierend auf unterschiedlichen modalen Informationen liefern. Der vom großen Sprachmodell generierte Inhalt ist jedoch nur auf Text beschränkt. Andererseits haben die aktuellen Diffusionsmodelle DALL・E 2, Imagen, Stable Diffusion usw. eine Revolution in der visuellen Erstellung ausgelöst, aber diese Modelle unterstützen nur eine einzige modalübergreifende Funktion von Text zu Bild und sind noch weit davon entfernt aus einer universellen generativen Distanz. Das multimodale Großmodell wird in der Lage sein, die Fähigkeiten verschiedener Modalitäten zu erschließen und die Konvertierung zwischen beliebigen Modalitäten zu realisieren, was als zukünftige Entwicklungsrichtung universeller generativer Modelle angesehen wird.
Ein kürzlich veröffentlichter Artikel „One Transformer Fits All Distributions in Multi-Modal Diffusion at Scale“ vom TSAIL-Team unter der Leitung von Professor Zhu Jun vom Fachbereich Informatik bei Die Tsinghua-Universität wurde erstmals veröffentlicht. Einige Forschungsarbeiten zu multimodalen generativen Modellen haben zu einer gegenseitigen Transformation zwischen allen Modalitäten geführt.

# 🎜 🎜#Papierlink: https://ml.cs.tsinghua.edu.cn/diffusion/unidiffuser.pdf
Open Source Code: https://github.com/thu-ml/unidiffuser
Dieses Papier schlägt UniDiffuser vor, ein probabilistisches Modellierungsframework, das für Multimodalität entwickelt wurde. und übernahm die vom Team vorgeschlagene transformatorbasierte Netzwerkarchitektur U-ViT, um ein Modell mit einer Milliarde Parametern auf dem Open-Source-Grafikdatensatz LAION-5B zu trainieren, wodurch ein zugrunde liegendes Modell eine Vielzahl von Aufgaben mit hoher Qualität erledigen kann . Aufgaben generieren (Abbildung 1). Vereinfacht ausgedrückt kann es neben der einseitigen Bildgenerierung von Bildern auch mehrere Funktionen wie Bildgenerierung von Text, gemeinsame Bild-Text-Generierung, bedingungslose Bild-Text-Generierung, Bild-Text-Umschreibung usw. realisieren Verbessert die Produktionseffizienz von Text-Bild-Inhalten erheblich und verbessert die Anwendungseffizienz des Formelmodells weiter.
Der Erstautor dieser Arbeit, Bao Fan, ist derzeit Doktorand. Er war der vorherige Antragsteller von Analytic-DPM und gewann den ICLR 2022 Outstanding Paper Award ( Derzeit die einzige preisgekrönte Arbeit, die unabhängig von einer Einheit auf dem Festland verfasst wurde.
Darüber hinaus hat Machine Heart bereits über den vom TSAIL-Team vorgeschlagenen schnellen DPM-Solver-Algorithmus berichtet, der immer noch der schnellste Generierungsalgorithmus für Diffusionsmodelle ist. Das multimodale große Modell ist eine konzentrierte Darstellung der langfristigen, detaillierten Ansammlung von Algorithmen und Prinzipien tiefer probabilistischer Modelle durch das Team. Zu den Mitarbeitern dieser Arbeit gehören Li Chongxuan von der Hillhouse School of Artificial Intelligence der Renmin University, Cao Yue vom Beijing Zhiyuan Research Institute und andere.

Es ist erwähnenswert, dass die Papiere und der Code dieses Projekts Open Source.
EffektanzeigeAbbildung 8 unten zeigt die Wirkung von UniDiffuser auf die Bild- und Textverbindungsgenerierung: # 🎜🎜#
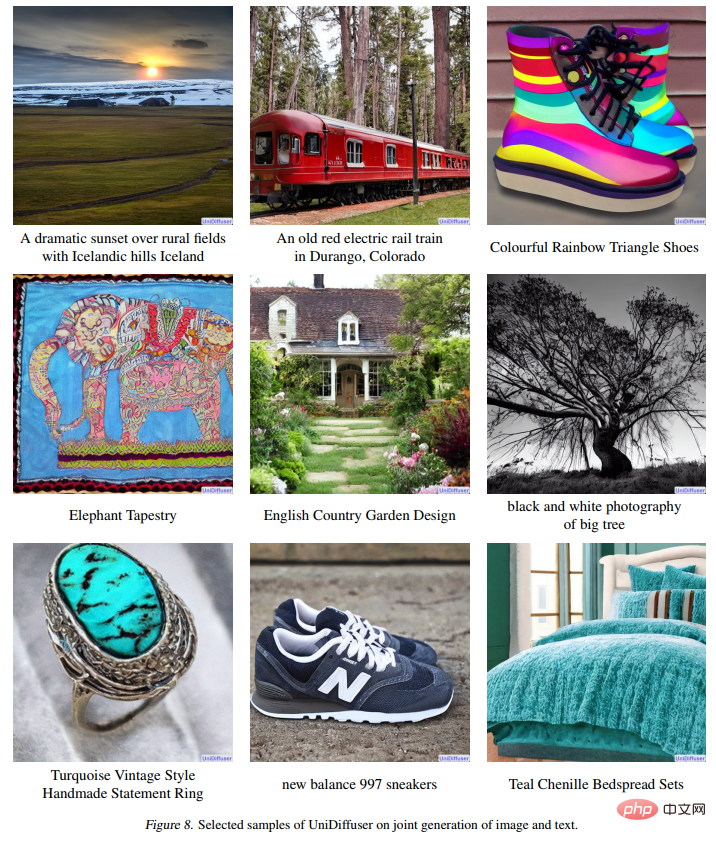
#🎜 🎜#

Abbildung 11 unten zeigt die Wirkung von UniDiffuser auf die bedingungslose Bilderzeugung:  #🎜 🎜##🎜 🎜#
#🎜 🎜##🎜 🎜#
Die folgende Abbildung 12 zeigt die Wirkung von UniDiffuser auf das Umschreiben von Bildern: 
Die folgende Abbildung 15 zeigt, dass UniDiffuser zwischen den beiden Bild- und Textmodi hin und her springen kann:

Abbildung 16 unten zeigt, dass UniDiffuser zwei reale Bilder interpolieren kann:
Methodenübersicht
Das Forschungsteam hat den Entwurf des allgemeinen generativen Modells in zwei Unterprobleme unterteilt:
- Probabilistischer Modellierungsrahmen: Ist es möglich, einen probabilistischen Modellierungsrahmen zu finden, der alle Verteilungen zwischen Modi, wie Randverteilungen, bedingte Verteilungen, gemeinsame Verteilungen zwischen Bildern und Texten usw., gleichzeitig modellieren kann?
- Netzwerkarchitektur: Kann eine einheitliche Netzwerkarchitektur so gestaltet werden, dass sie verschiedene Eingabemodalitäten unterstützt?
Probabilistisches Modellierungs-Framework
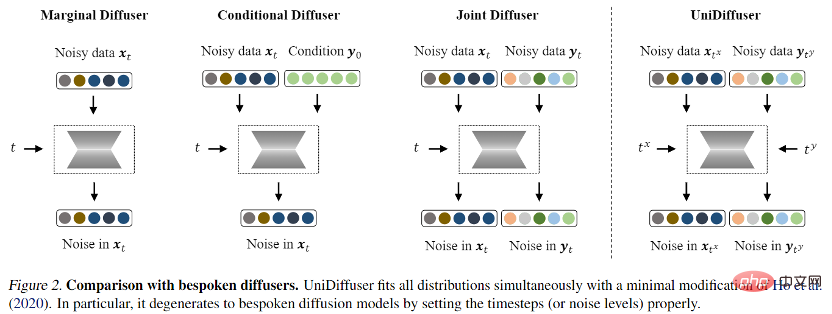
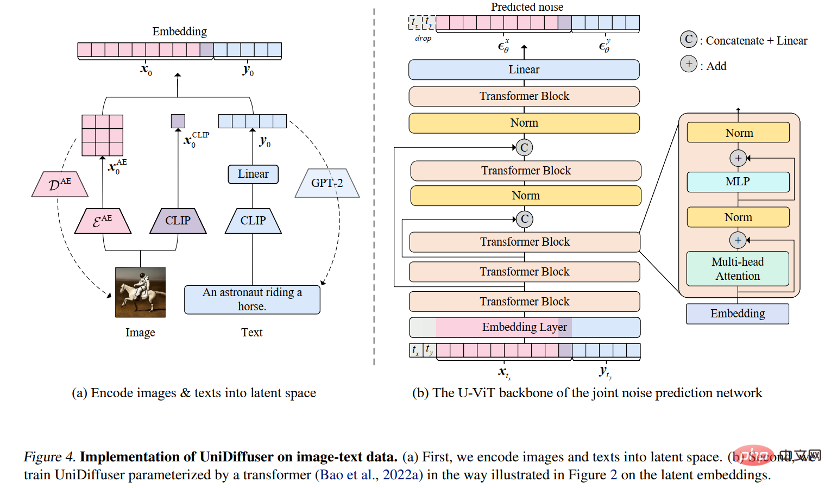
Für das probabilistische Modellierungs-Framework schlug das Forschungsteam UniDiffuser vor, ein probabilistisches Modellierungs-Framework, das auf dem Diffusionsmodell basiert. UniDiffuser kann alle Verteilungen in multimodalen Daten explizit modellieren, einschließlich Randverteilungen, bedingter Verteilungen und gemeinsamer Verteilungen. Das Forschungsteam fand heraus, dass das Diffusionsmodelllernen über unterschiedliche Verteilungen in einer Perspektive vereinheitlicht werden kann: Zuerst wird den Daten der beiden Modalitäten eine bestimmte Größe des Rauschens hinzugefügt und dann wird das Rauschen anhand der Daten der beiden Modalitäten vorhergesagt. Die Menge an Rauschen in den beiden Modaldaten bestimmt die spezifische Verteilung. Das Festlegen der Rauschgröße des Textes auf 0 entspricht beispielsweise der bedingten Verteilung des Vincentschen Diagramms; das Festlegen der Rauschgröße des Textes auf den Maximalwert entspricht der Einstellung der Rauschgröße des Bildes und; Der gleiche Textwert entspricht der gemeinsamen Verteilung von Bildern und Texten. Gemäß dieser einheitlichen Perspektive muss UniDiffuser nur geringfügige Änderungen am Trainingsalgorithmus des ursprünglichen Diffusionsmodells vornehmen, um alle oben genannten Verteilungen gleichzeitig zu lernen. Wie in der folgenden Abbildung gezeigt, fügt UniDiffuser allen Modi gleichzeitig Rauschen hinzu Geben Sie anstelle eines einzelnen Modus die Rauschgröße ein, die allen Modi entspricht, und das vorhergesagte Rauschen für alle Modi.
Am Beispiel des bimodalen Modus lautet die endgültige Trainingszielfunktion wie folgt:
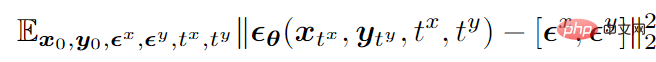
wobei

stellt Daten dar,

stellt das Standard-Gaußsche Rauschen dar, das den beiden Modi hinzugefügt wird,

stellt die Größe (d. h. Zeit) des Rauschens dar, das den beiden Modi hinzugefügt wird, und die beiden sind unabhängig von { 1, 2,…,T} mittlere Abtastung,
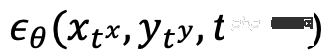
ist ein Lärmvorhersagenetzwerk, das Lärm auf zwei Modalitäten gleichzeitig vorhersagt.
Nach dem Training ist UniDiffuser in der Lage, eine bedingungslose, bedingte und gemeinsame Generierung zu erreichen, indem die entsprechende Zeit für die beiden Modi im Geräuschvorhersagenetzwerk eingestellt wird. Wenn Sie beispielsweise die Zeit des Textes auf 0 setzen, können Sie eine Text-zu-Bild-Generierung erreichen. Wenn Sie die Zeit des Texts auf den Maximalwert setzen, können Sie eine bedingungslose Bildgenerierung erreichen gemeinsame Generierung von Bildern und Texten.
Die Trainings- und Sampling-Algorithmen von UniDiffuser sind unten aufgeführt. Es ist ersichtlich, dass diese Algorithmen im Vergleich zum ursprünglichen Diffusionsmodell nur geringfügige Änderungen vorgenommen haben und einfach zu implementieren sind.

Da UniDiffuser außerdem sowohl bedingte als auch bedingungslose Verteilungen modelliert, unterstützt UniDiffuser natürlich eine klassifikatorfreie Führung. Abbildung 3 unten zeigt die Wirkung der bedingten Generierung und der gemeinsamen Generierung von UniDiffuser unter verschiedenen Führungsskalen:

Netzwerkarchitektur
Für die Netzwerkarchitektur schlug das Forschungsteam die Verwendung transformatorbasierter Architektur vor zur Parametrisierung von Lärmvorhersagenetzwerken. Konkret übernahm das Forschungsteam die kürzlich vorgeschlagene U-ViT-Architektur. U-ViT behandelt alle Eingaben als Token und fügt U-förmige Verbindungen zwischen Transformatorblöcken hinzu. Das Forschungsteam übernahm außerdem die Strategie der stabilen Diffusion, um Daten verschiedener Modalitäten in den latenten Raum umzuwandeln und dann das Diffusionsmodell zu modellieren. Es ist erwähnenswert, dass die U-ViT-Architektur ebenfalls von diesem Forschungsteam stammt und unter https://github.com/baofff/U-ViT als Open Source verfügbar ist.
Experimentelle Ergebnisse
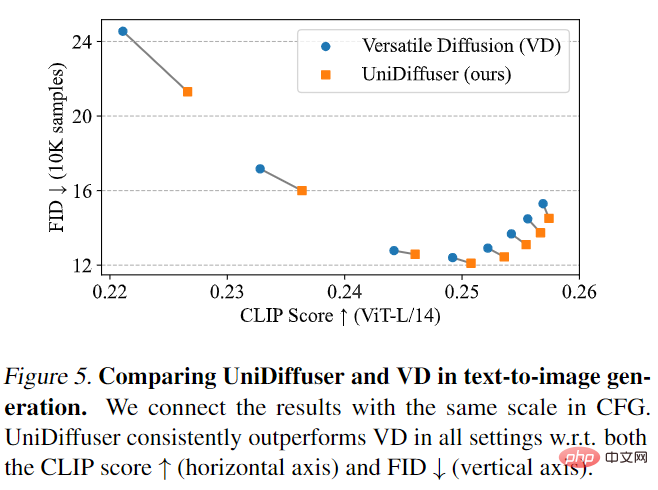
UniDiffuser zuerst im Vergleich mit Versatile Diffusion. Versatile Diffusion ist ein früheres multimodales Diffusionsmodell, das auf einem Multitask-Framework basiert. Zunächst wurden UniDiffuser und Versatile Diffusion hinsichtlich der Text-zu-Bild-Effekte verglichen. Wie in Abbildung 5 unten dargestellt, ist UniDiffuser sowohl beim CLIP-Score als auch bei den FID-Metriken unter verschiedenen klassifikatorfreien Orientierungsskalen besser als Versatile Diffusion.
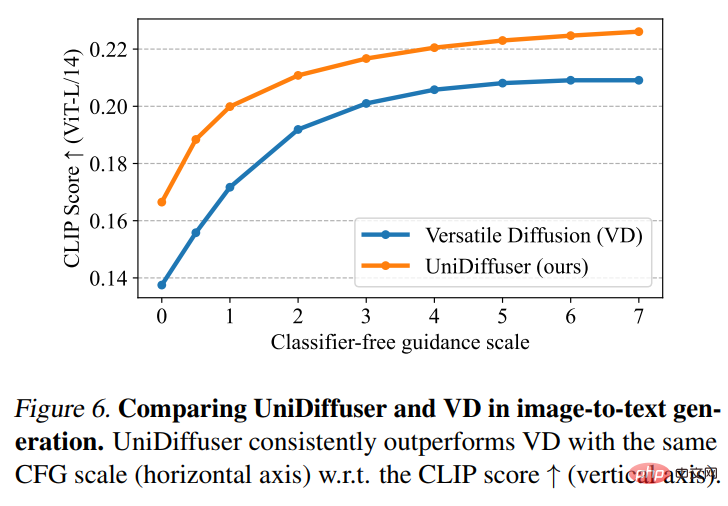
Dann führten UniDiffuser und Versatile Diffusion einen Bild-zu-Text-Effektvergleich durch. Wie in Abbildung 6 unten gezeigt, hat UniDiffuser einen besseren CLIP-Score beim Bild-zu-Text.
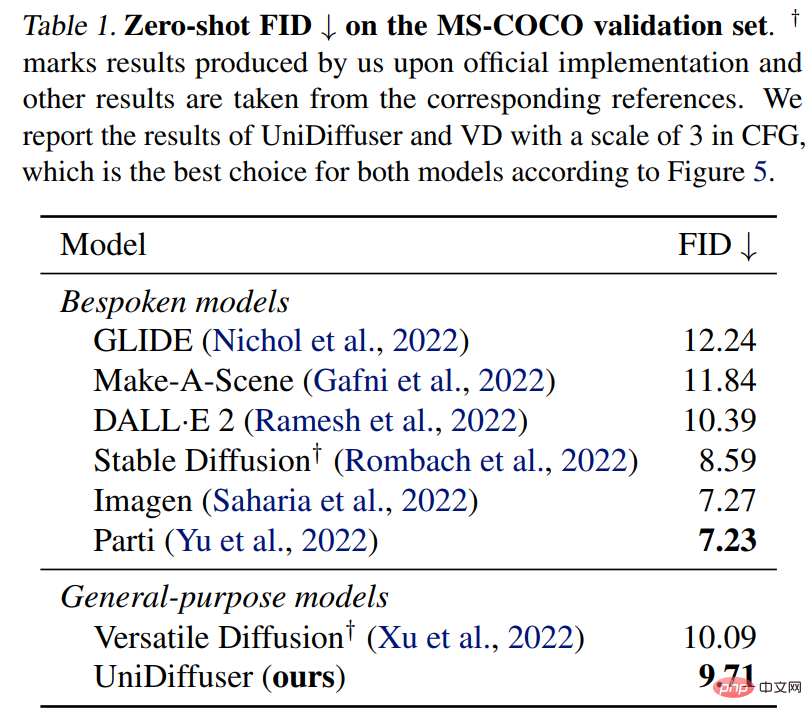
UniDiffuser wird auch mit einem speziellen Text-to-Graph-Modell für Zero-Shot-FID auf MS-COCO verglichen. Wie in Tabelle 1 unten gezeigt, kann UniDiffuser vergleichbare Ergebnisse mit speziellen Text-zu-Grafik-Modellen erzielen.
Das obige ist der detaillierte Inhalt vonDas Team von Zhu Jun hat das erste groß angelegte multimodale Diffusionsmodell auf Basis von Transformer an der Tsinghua-Universität als Open-Source-Lösung erstellt und es nach dem Umschreiben von Text und Bildern vollständig fertiggestellt.. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Technologietrends, die Sie im Jahr 2023 im Auge behalten sollten
- Wie künstliche Intelligenz Rechenzentrumsteams neue Alltagsaufgaben beschert
- Können künstliche Intelligenz oder Automatisierung das Problem der geringen Energieeffizienz in Gebäuden lösen?
- OpenAI-Mitbegründer im Interview mit Huang Renxun: Die Argumentationsfähigkeiten von GPT-4 haben noch nicht die Erwartungen erfüllt
- Dank der OpenAI-Technologie übertrifft Bing von Microsoft Google im Suchverkehr