Neu zum Ausdruck gebracht: Forschungsmotivation
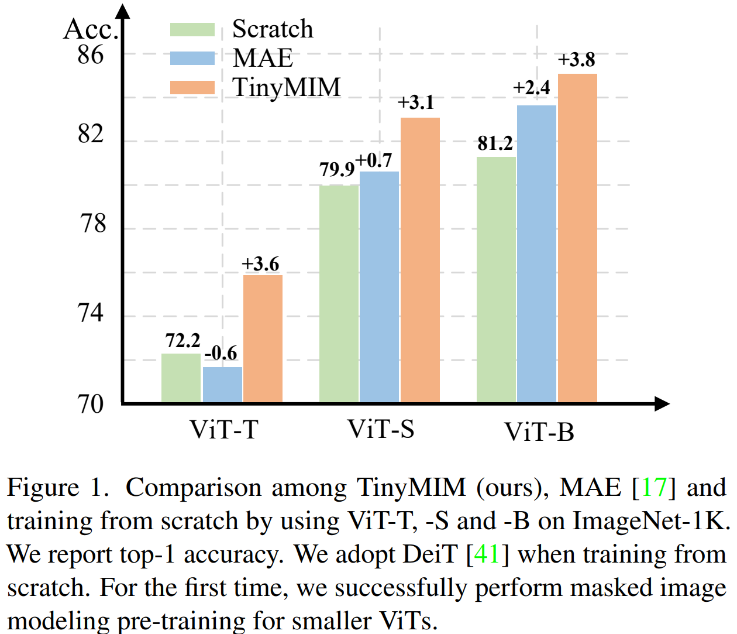
Maskenmodellierung (MIM, MAE) hat sich als sehr effektive selbstüberwachte Trainingsmethode erwiesen. Wie in Abbildung 1 dargestellt, funktioniert MIM jedoch bei größeren Modellen relativ besser. Wenn das Modell sehr klein ist (z. B. ViT-T 5M-Parameter, ein solches Modell ist für die reale Welt sehr wichtig), kann MIM die Wirkung des Modells sogar bis zu einem gewissen Grad reduzieren. Beispielsweise ist der Klassifizierungseffekt von ViT-L, der mit MAE auf ImageNet trainiert wurde, um 3,3 % höher als der des unter normaler Aufsicht trainierten Modells, aber der Klassifizierungseffekt von ViT-T, der mit MAE auf ImageNet trainiert wurde, ist 0,6 % niedriger als der des Modell unter normaler Aufsicht trainiert. In dieser Arbeit haben wir TinyMIM vorgeschlagen, das eine Destillationsmethode verwendet, um Wissen von großen Modellen auf ViT zu übertragen, während die Struktur unverändert bleibt und die Struktur nicht geändert wird, um andere induktive Verzerrungen einzuführen. Kleines Modell. ?? su /TinyMIM 
Wir haben systematisch die Auswirkungen von Destillationszielen, Datenverbesserung, Regularisierung, Hilfsverlustfunktionen usw. auf die Destillation untersucht. Wenn ausschließlich ImageNet-1K als Trainingsdaten verwendet wird (einschließlich des Lehrermodells, das ebenfalls nur ImageNet-1K-Training verwendet) und ViT-B als Modell verwendet wird, erzielt unsere Methode derzeit die beste Leistung. Wie in der Abbildung gezeigt: Vergleichen Sie unsere Methode (TinyMIM) mit der auf Maskenrekonstruktion basierenden Methode MAE und der überwachten Lernmethode DeiT, die von Grund auf trainiert wurde. Wenn das Modell relativ groß ist, führt MAE zu erheblichen Leistungsverbesserungen. Wenn das Modell jedoch relativ klein ist, ist die Verbesserung begrenzt und kann sogar den endgültigen Effekt des Modells beeinträchtigen. Unsere Methode TinyMIM erzielt erhebliche Verbesserungen über verschiedene Modellgrößen hinweg.
Unsere Beiträge sind wie folgt:
-
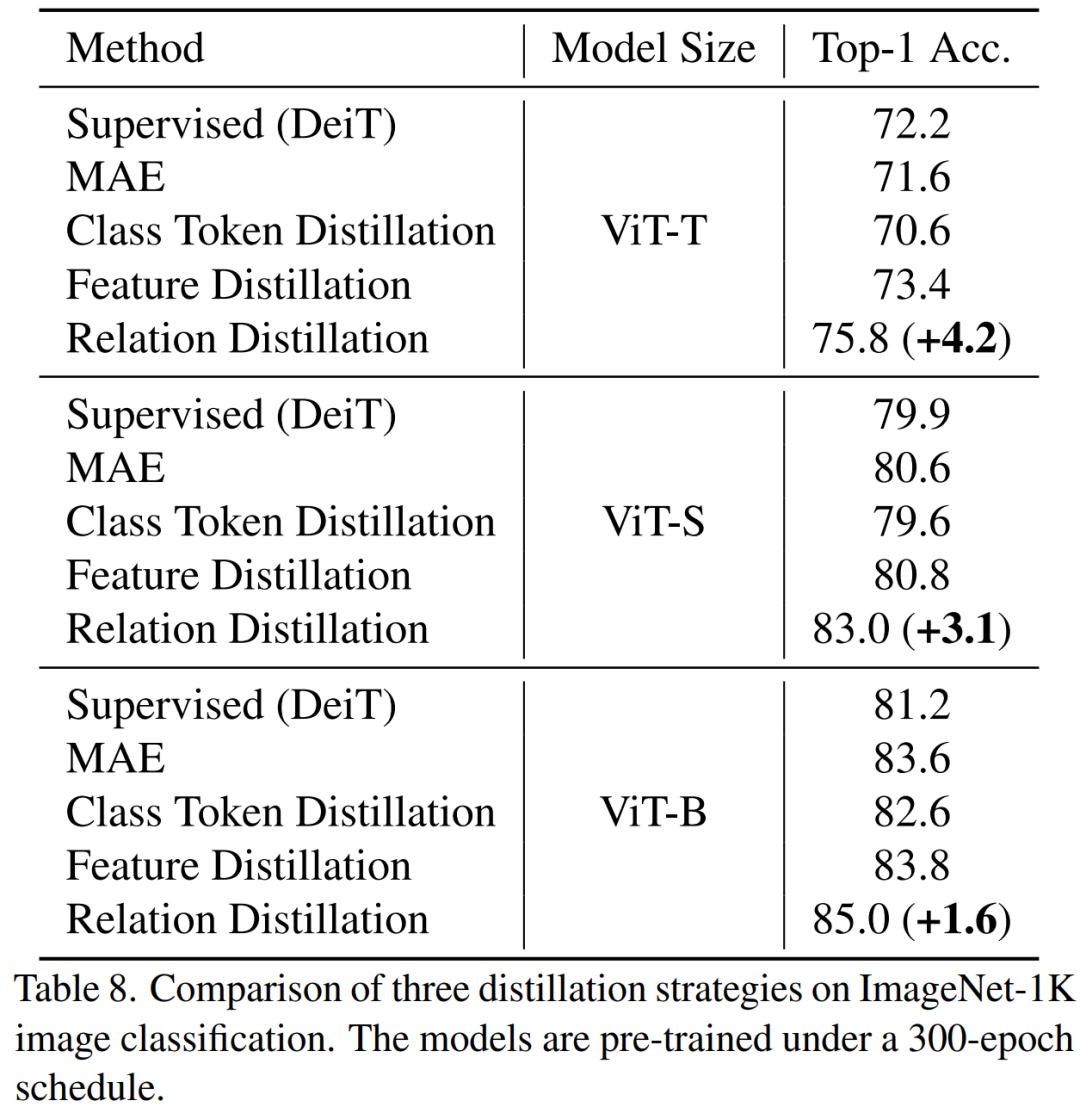
1. Das Destillieren der Beziehung zwischen Token ist effektiver als das Destillieren von Klassen-Token oder Feature-Maps allein. 2) Es ist effizienter, die Mitte zu verwenden Schicht als Ziel für die Destillation.
- 2. Datenverbesserung und Modellregularisierung (Daten- und Netzwerkregularisierung): 1) Der Effekt der Verwendung maskierter Bilder ist schlechter. 2) Das Schülermodell benötigt einen kleinen Drop-Pfad, das Lehrermodell jedoch nicht. 3. Hilfsverluste: MIM ist als Hilfsverlustfunktion bedeutungslos.
4. Makrodestillationsstrategie: Wir haben festgestellt, dass die serielle Destillation (ViT-B -> ViT-S -> ViT-T) am besten funktioniert.
Wir haben die Destillationsziele, Eingabebilder und Destillationszielmodule systematisch untersucht. 2.1 Faktoren, die den Destillationseffekt beeinflussen Verdammt Wenn i = L, bezieht es sich auf die Eigenschaften der Transformer-Ausgabeschicht. Wenn i b. Funktionen der Aufmerksamkeitsschicht (Attention) und Funktionen der Feed-Forward-Schicht (FFN)
Transformer Jeder Block verfügt über eine Aufmerksamkeitsschicht und eine FFN-Schicht und destilliert Verschiedene Ebenen haben unterschiedliche Effekte. c.QKV-Funktionen
Diese Funktionen werden zur Berechnung des Aufmerksamkeitsmechanismus verwendet Die direkte Destillation dieser Eigenschaften.
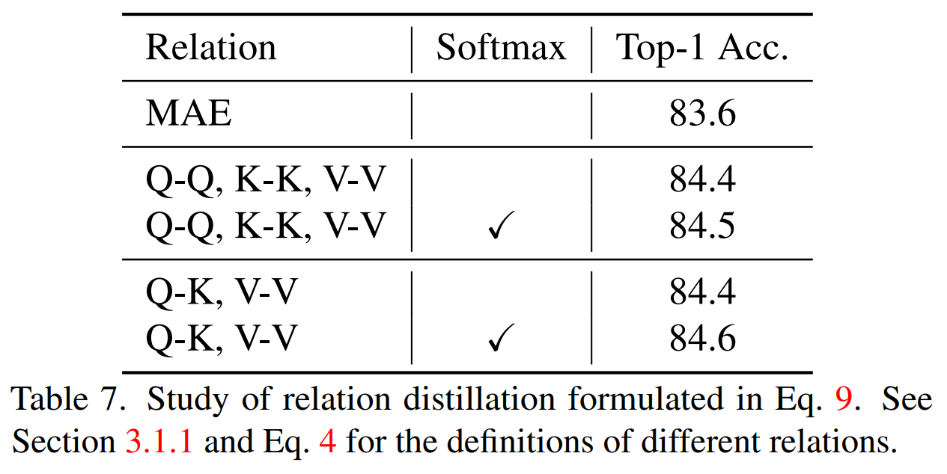
Q, K, V werden zur Berechnung der Aufmerksamkeitskarte verwendet, und die Beziehung zwischen diesen Merkmalen kann auch als Wissensziel verwendet werden Destillation. 3) Eingabe: Maskiert oder nicht Traditionelle Wissensdestillation besteht darin, das vollständige Bild direkt einzugeben. Unsere Methode besteht darin, das Modellierungsmodell der Destillationsmaske zu untersuchen. Daher untersuchen wir auch, ob maskierte Bilder als Eingaben für die Wissensdestillation geeignet sind. 2.2 Vergleich von Wissensdestillationsmethoden
auf das Klassentoken des Schülermodells und auf das Klassentoken des Lehrermodells bezieht. 2) Merkmalsdestillation: Zum Vergleich verweisen wir direkt auf die Merkmalsdestillation [1] Destillation: Wir haben auch The vorgeschlagen Standarddestillationsstrategie in diesem Artikel Unsere Methode ist auf ImageNet vorab trainiert. 1K, und das Lehrermodell ist ebenfalls auf ImageNet-1K vorab trainiert. Anschließend haben wir unser vorab trainiertes Modell auf nachgelagerte Aufgaben (Klassifizierung, semantische Segmentierung) verfeinert. Die Modellleistung ist wie in der Abbildung dargestellt:
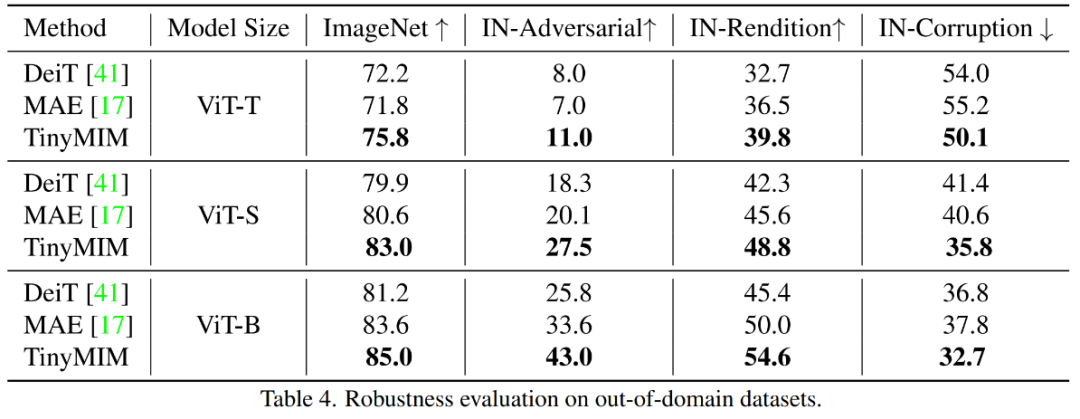
Unsere Methode übertrifft bisherige MAE-basierte Methoden deutlich, insbesondere für kleine Modelle. Insbesondere für das ultrakleine Modell ViT-T erreicht unsere Methode eine Klassifizierungsgenauigkeit von 75,8 %, was einer Verbesserung von 4,2 im Vergleich zum MAE-Basismodell entspricht. Für das kleine Modell ViT-S erreichen wir eine Klassifizierungsgenauigkeit von 83,0 %, was einer Verbesserung von 1,4 gegenüber der bisher besten Methode entspricht. Bei Modellen in Basisgröße übertrifft unsere Methode das MAE-Basismodell und das bisher beste Modell um CAE 4.1 bzw. 2.0. Gleichzeitig haben wir auch die Robustheit des Modells getestet, wie in der Abbildung gezeigt:
TinyMIM-B im Vergleich zu MAE-B in ImageNet -A und ImageNet- R verbesserten sich um +6,4 bzw. +4,6. 3.2 Ablationsexperiment Bei der Berechnung der Beziehung Best wird die QK-V-Beziehung sorgfältig destilliert Ergebnisse. 2) Verschiedene Destillationsstrategien Gleiches gilt für Modelle aller Größen. 3) Destillations-Mittelschicht
Wir haben festgestellt, dass die achtzehnte Destillationsschicht die besten Ergebnisse erzielte. IV. Fazit In diesem Artikel haben wir TinyMIM vorgeschlagen, das erste Modell, das es kleinen Modellen erfolgreich ermöglicht, von der Vorschulung zur Mask Reconstruction Modeling (MIM) zu profitieren. Anstatt die Maskenrekonstruktion als Aufgabe zu übernehmen, trainieren wir das kleine Modell vorab, indem wir das kleine Modell trainieren, um die Beziehungen des großen Modells auf eine Weise der Wissensdestillation zu simulieren. Der Erfolg von TinyMIM lässt sich auf eine umfassende Untersuchung verschiedener Faktoren zurückführen, die sich auf das TinyMIM-Vortraining auswirken können, einschließlich Destillationszielen, Destillationseingängen und Zwischenschichten. Durch umfangreiche Experimente kommen wir zu dem Schluss, dass die Relationsdestillation der Feature-Destillation und der Class-Label-Destillation usw. überlegen ist. Wir hoffen, dass unsere Methode mit ihrer Einfachheit und leistungsstarken Leistung eine solide Grundlage für zukünftige Forschungen bieten wird. [1] Wei, Y., Hu, H., Xie, Z., Zhang, Z., Cao, Y., Bao, J., ... & Guo, B. (2022) . Kontrastives Lernen konkurriert mit maskierter Bildmodellierung durch Feature-Destillation
Das obige ist der detaillierte Inhalt vonMicrosoft Research Asia führt TinyMIM ein: Verbesserung der Leistung kleiner ViT durch Wissensdestillation. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!



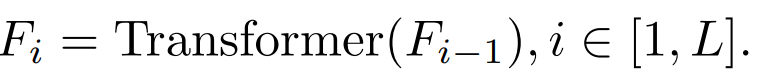
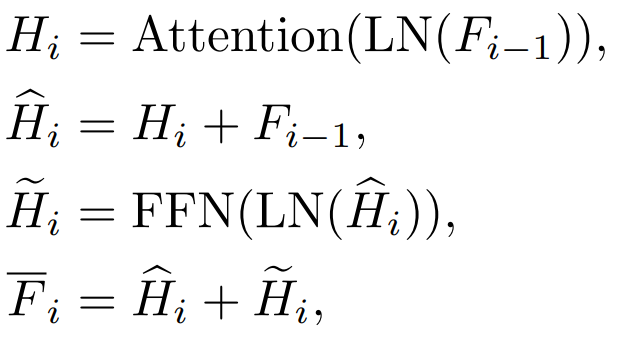
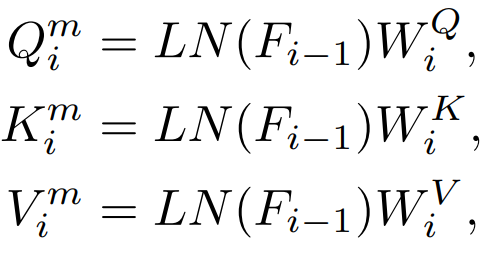

 [1] Wei, Y., Hu, H., Xie, Z., Zhang, Z., Cao, Y., Bao, J., ... & Guo, B. (2022) . Kontrastives Lernen konkurriert mit maskierter Bildmodellierung durch Feature-Destillation
[1] Wei, Y., Hu, H., Xie, Z., Zhang, Z., Cao, Y., Bao, J., ... & Guo, B. (2022) . Kontrastives Lernen konkurriert mit maskierter Bildmodellierung durch Feature-Destillation