
Heim >Technologie-Peripheriegeräte >KI >Der Server ist überfüllt, das große Rechtsmodell ChatLaw der Peking-Universität ist beliebt: Erzählen Sie direkt, wie Zhang San verurteilt wurde
Der Server ist überfüllt, das große Rechtsmodell ChatLaw der Peking-Universität ist beliebt: Erzählen Sie direkt, wie Zhang San verurteilt wurde

- PHPznach vorne
- 2023-07-05 09:21:161450Durchsuche
Das große Modell ist wieder „explodiert“.
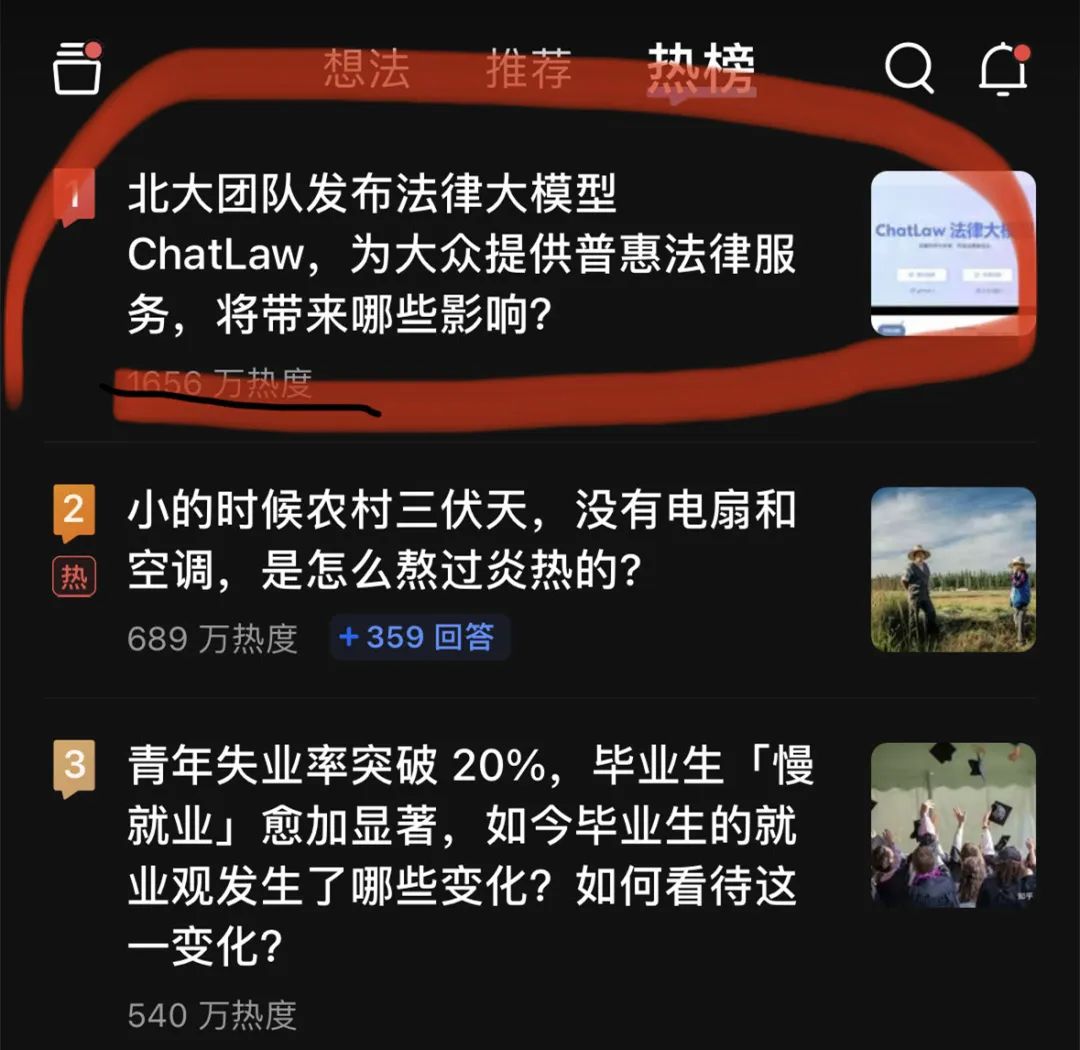
Gestern Abend stand ein großes Anwaltsmodell, ChatLaw, ganz oben auf der Zhihu-Hot-Search-Liste. Auf dem Höhepunkt erreichte die Popularität rund 20 Millionen.
Dieser ChatLaw wird vom Team der Peking-Universität veröffentlicht und setzt sich für die Bereitstellung inklusiver Rechtsdienstleistungen ein. Einerseits herrscht derzeit im ganzen Land ein Mangel an praktizierenden Anwälten, und das Angebot ist weitaus geringer als die gesetzliche Nachfrage. Andererseits haben die einfachen Menschen eine natürliche Lücke in den Rechtskenntnissen und -versorgungen und können diese nicht nutzen legale Waffen, um sich zu schützen.
Der jüngste Aufstieg großer Sprachmodelle bietet für normale Menschen eine hervorragende Gelegenheit, sich auf konversationelle Weise zu rechtlichen Fragen zu beraten.
Derzeit gibt es drei Versionen von ChatLaw:
- ChatLaw-13B, eine akademische Demoversion, die auf Jiang Ziya Ziya-LLaMA-13B-v1 basiert funktioniert sehr gut auf Chinesisch. Logisch komplexe juristische Fragen und Antworten sind jedoch nicht effektiv und müssen mit einem Modell mit größeren Parametern gelöst werden.
- ChatLaw-33B, ebenfalls eine akademische Demoversion, basiert auf Anima-33B und seiner Fähigkeit zum logischen Denken ist stark verbessert. Da Anima jedoch zu wenig chinesischen Korpus hat, erscheinen bei Fragen und Antworten häufig englische Daten Die Angaben entsprechen den entsprechenden gesetzlichen Bestimmungen.
- Laut der offiziellen Demonstration unterstützt ChatLaw Benutzer beim Hochladen von Dokumenten, Aufzeichnungen und anderen rechtlichen Materialien und hilft ihnen beim Zusammenfassen und Analysieren sowie beim Erstellen visueller Karten, Diagramme usw. Darüber hinaus kann ChatLaw faktenbasierte Rechtsberatung und Rechtsdokumente generieren. Das Projekt hat 1,1.000 Sterne auf GitHub.
Bilder
 Offizielle Website-Adresse: https://www.chatlaw.cloud/
Offizielle Website-Adresse: https://www.chatlaw.cloud/
Papieradresse: https://arxiv.org/pdf/2306.16092.pdf
Das ist Link zum GitHub-Projekt von uns: https://github.com/PKU-YuanGroup/ChatLaw
Aufgrund der Beliebtheit des ChatLaw-Projekts ist der Server derzeit vorübergehend abgestürzt und die Rechenleistung hat die Obergrenze erreicht. Das Team arbeitet an einer Lösung und interessierte Leser können das Beta-Modell auf GitHub bereitstellen.
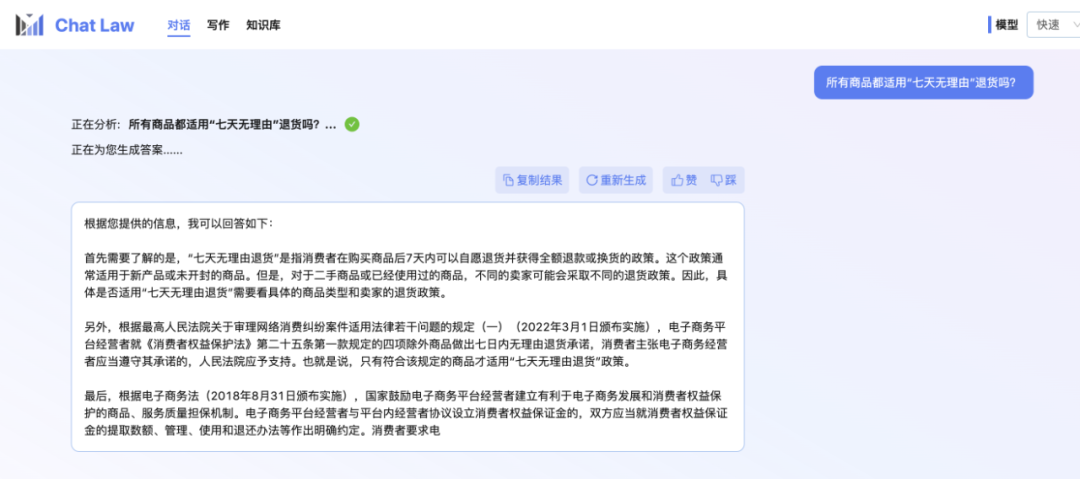
Der Redakteur selbst steht immer noch in der Warteschlange für den geschlossenen Betatest. Hier ist also ein offizielles Gesprächsbeispiel des ChatLaw-Teams über das Problem der „siebentägigen Rückgabe ohne Angabe von Gründen“, das beim Online-Einkauf auftreten kann. Ich muss sagen, dass die Antworten von ChatLaw recht umfassend sind.
Bilder
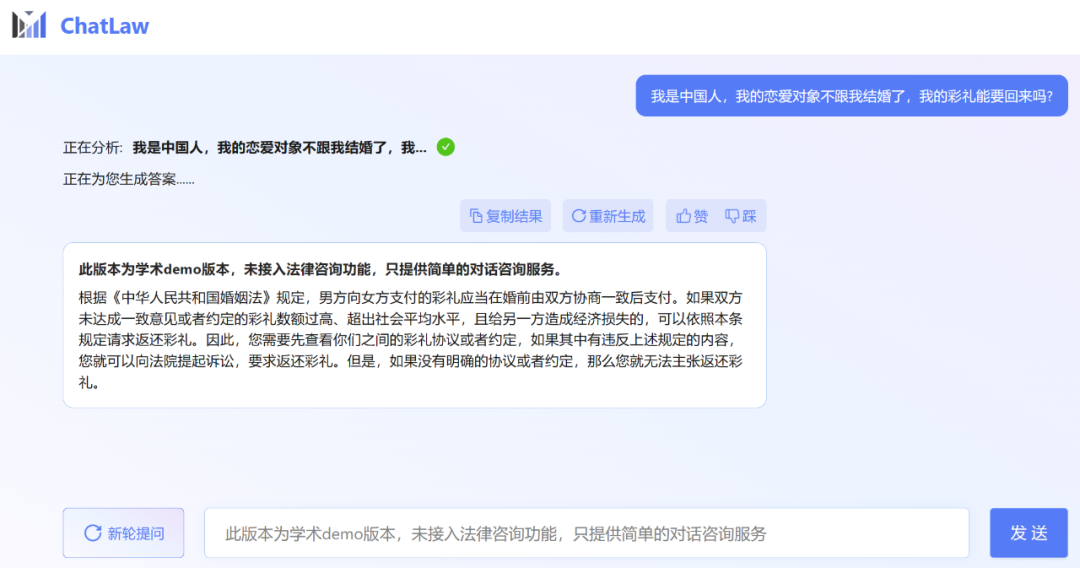
 Der Herausgeber stellte jedoch fest, dass die akademische Demoversion von ChatLaw leider keinen Zugriff auf die Rechtsberatungsfunktion hat und nur einfache Dialogberatungsdienste bietet. Hier sind ein paar Fragen zum Ausprobieren.
Der Herausgeber stellte jedoch fest, dass die akademische Demoversion von ChatLaw leider keinen Zugriff auf die Rechtsberatungsfunktion hat und nur einfache Dialogberatungsdienste bietet. Hier sind ein paar Fragen zum Ausprobieren.
Bilder
Tatsächlich ist die Peking-Universität nicht die einzige, die in letzter Zeit große Rechtsmodelle veröffentlicht hat. Ende letzten Monats veröffentlichten Power Law Intelligence und Zhipu AI das rechtliche vertikale Modell PowerLawGLM auf 100-Milliarden-Parameterebene. Es wird berichtet, dass das Modell einzigartige Vorteile in seiner Anwendungswirkung in chinesischen Rechtsszenarien gezeigt hat. 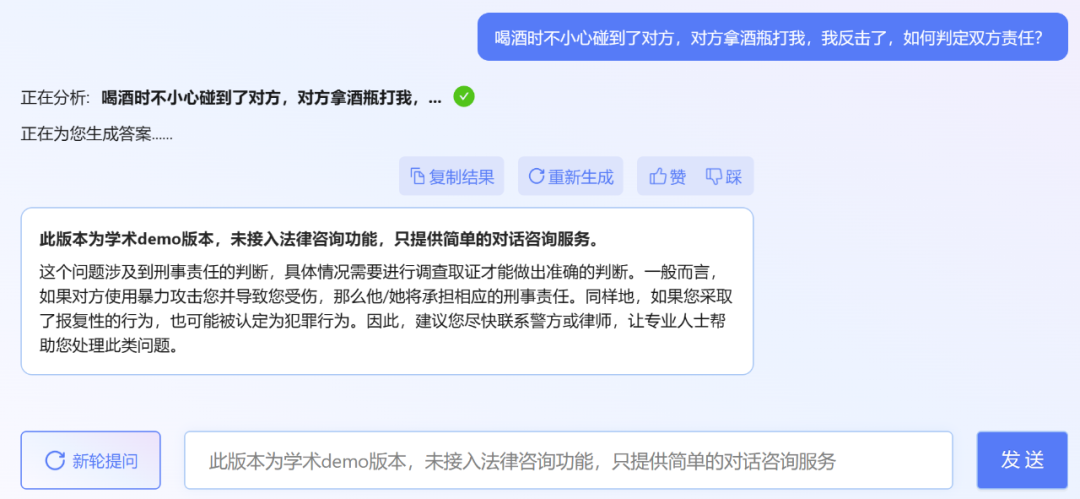
ChatLaws Datenquelle und Trainingsrahmen
Das erste ist die Datenzusammensetzung
. ChatLaw-Daten bestehen hauptsächlich aus Foren, Nachrichten, gesetzlichen Bestimmungen, gerichtlichen Auslegungen, Rechtsberatungen, rechtlichen Prüfungsfragen und Urteilsdokumenten. Sie werden dann zur Erstellung von Dialogdaten durch Bereinigung, Datenverbesserung usw. verwendet. Gleichzeitig kann das ChatLaw-Team durch die Zusammenarbeit mit der Peking University School of International Law und namhaften Anwaltskanzleien der Branche sicherstellen, dass die Wissensdatenbank zeitnah aktualisiert werden kann und gleichzeitig die Professionalität und Zuverlässigkeit der Daten gewährleistet ist. Schauen wir uns unten konkrete Beispiele an.Konstruktionsbeispiele basierend auf Gesetzen, Vorschriften und richterlichen Auslegungen:
Beispiel für die Erfassung echter Rechtsberatungsdaten:

Beispiel für die Erstellung von Multiple-Choice-Fragen für die Anwaltsprüfung:
 Bilder
Bilder
Dann gibt es noch die Modellebene. Um ChatLAW zu trainieren, hat das Forschungsteam es mithilfe der Low-Rank Adaptation (LoRA) basierend auf Ziya-LLaMA-13B verfeinert. Darüber hinaus stellt diese Studie auch die Rolle der Selbstsuggestion vor, um das Problem der Modellhalluzinationen zu lindern. Der Trainingsprozess wird auf mehreren A100-GPUs durchgeführt, wobei Deepspeed die Trainingskosten weiter senkt.
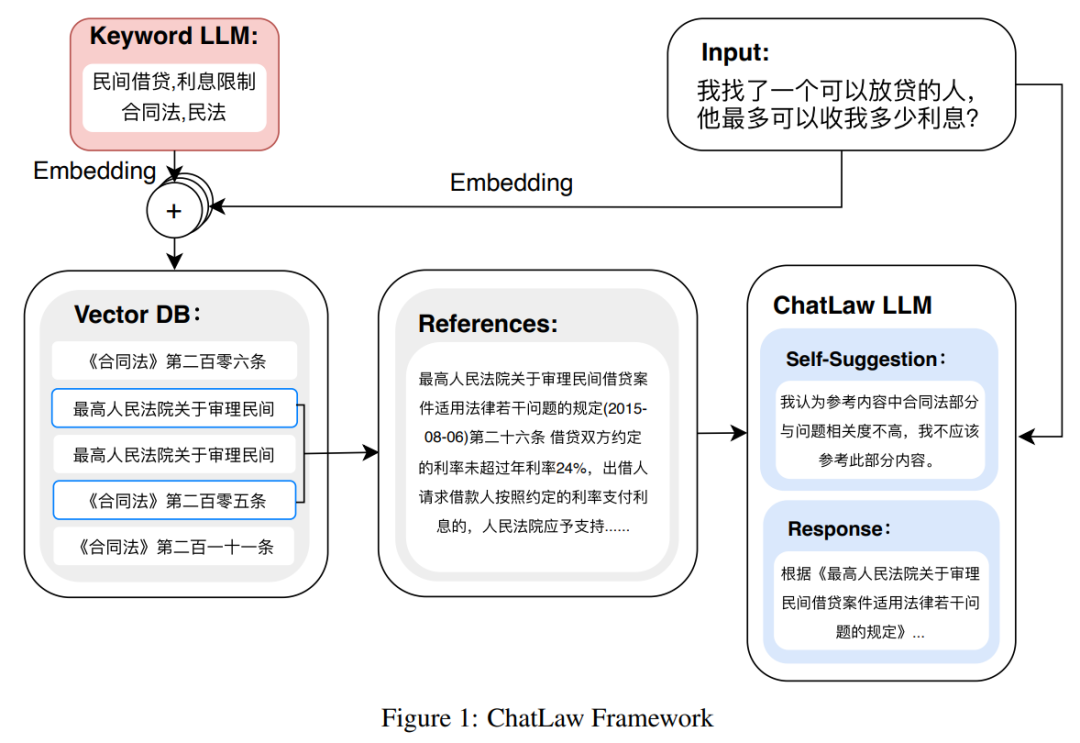
Die folgende Abbildung ist das Architekturdiagramm von ChatLAW. Diese Forschung fügt rechtliche Daten in das Modell ein und führt eine spezielle Verarbeitung und Erweiterung dieses Wissens durch. Gleichzeitig werden während der Argumentation mehrere Module eingeführt, um allgemeines Modell und Fachwissen zu kombinieren Modell integriert in die Wissensdatenbank.
Diese Studie hat das Modell auch während der Inferenz eingeschränkt, um sicherzustellen, dass das Modell korrekte Gesetze und Vorschriften generiert und Modellillusionen so weit wie möglich reduziert wird.
 Bilder
Bilder
Zunächst probierte das Forschungsteam traditionelle Softwareentwicklungsmethoden aus, beispielsweise die Verwendung von MySQL und Elasticsearch zum Abrufen, aber die Ergebnisse waren unbefriedigend. Daher begann diese Forschung mit dem Versuch, das BERT-Modell vorab für die Einbettung zu trainieren und dann Methoden wie Faiss zu verwenden, um die Kosinusähnlichkeit zu berechnen und die wichtigsten k Gesetze und Vorschriften im Zusammenhang mit der Benutzerabfrage zu extrahieren.
Dieser Ansatz führt oft zu suboptimalen Ergebnissen, wenn das Problem des Benutzers vage ist. Daher extrahieren Forscher wichtige Informationen aus Benutzeranfragen und entwerfen Algorithmen mithilfe der Vektoreinbettung dieser Informationen, um die Übereinstimmungsgenauigkeit zu verbessern.
Da große Modelle erhebliche Vorteile beim Verständnis von Benutzeranfragen haben, wurde in dieser Studie LLM verfeinert, um Schlüsselwörter aus Benutzeranfragen zu extrahieren. Nach Erhalt mehrerer Schlüsselwörter verwendete die Studie Algorithmus 1, um relevante gesetzliche Bestimmungen abzurufen.
 Bilder
Bilder
Experimentelle Ergebnisse
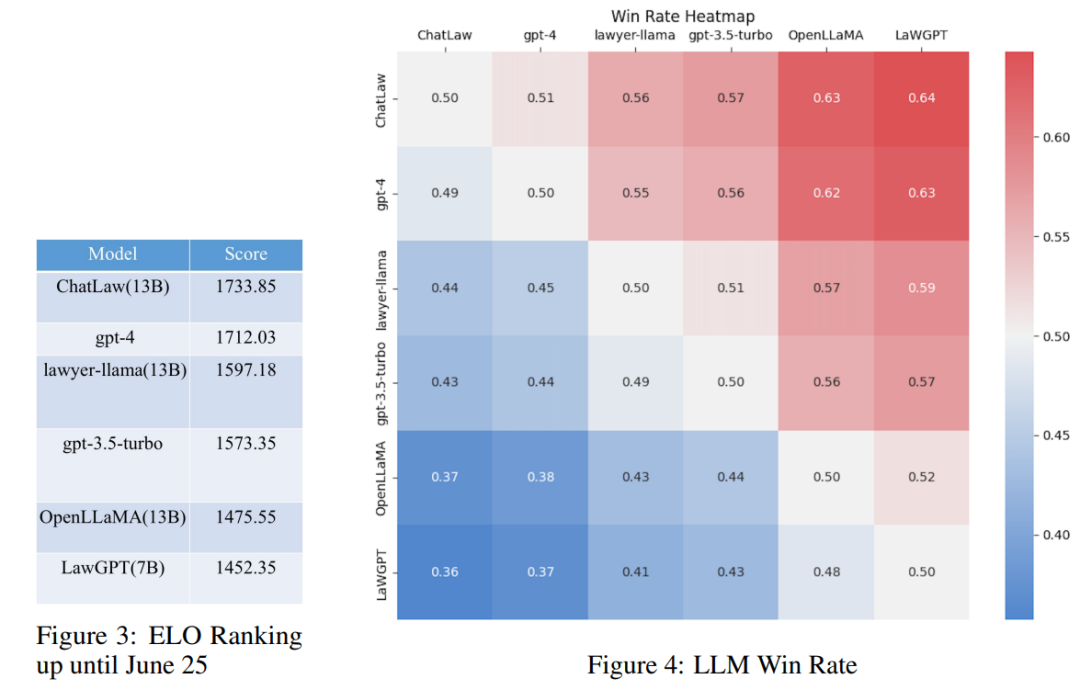
Diese Studie sammelte mehr als zehn Jahre lang nationale richterliche Prüfungsfragen und stellte einen Testdatensatz mit 2000 Fragen und ihren Standardantworten zusammen, um die Fähigkeit des Modells, mit Multiple-Choice umzugehen, zu messen rechtliche Fragen.
Untersuchungen haben jedoch ergeben, dass die Genauigkeit jedes Modells im Allgemeinen gering ist. In diesem Fall sagt der Vergleich der Genauigkeit allein nicht viel aus. Daher stützt sich diese Studie auf den ELO-Matching-Mechanismus von League of Legends und erstellt einen Modell-gegen-ELO-Mechanismus, um die Fähigkeit jedes Modells, rechtliche Multiple-Choice-Fragen zu bearbeiten, effektiver zu bewerten. Im Folgenden sind die ELO-Ergebnisse bzw. Gewinnratendiagramme aufgeführt:
 Bilder
Bilder
Durch die Analyse der oben genannten experimentellen Ergebnisse können wir die folgenden Beobachtungen ziehen
(1) Einführung in rechtliche Fragen und Antworten und Regulierungsbestimmungen Die Daten können die Leistung des Modells bei Multiple-Choice-Fragen bis zu einem gewissen Grad verbessern. Der Grund, warum das ChatLaw-Modell beispielsweise besser ist als GPT-4, liegt darin, dass der Artikel eine große Anzahl von Multiple-Choice-Fragen als Trainingsdaten verwendet Modelle mit größeren Parametern schneiden normalerweise besser ab.
Referenz-Zhihu-Link:
https://www.zhihu.com/question/610072848
Andere Referenzlinks:
https://mp.weixin.qq.com/ s /bXAFALFY6GQkL30j1sYCEQ
Das obige ist der detaillierte Inhalt vonDer Server ist überfüllt, das große Rechtsmodell ChatLaw der Peking-Universität ist beliebt: Erzählen Sie direkt, wie Zhang San verurteilt wurde. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Technologietrends, die Sie im Jahr 2023 im Auge behalten sollten
- Wie künstliche Intelligenz Rechenzentrumsteams neue Alltagsaufgaben beschert
- Können künstliche Intelligenz oder Automatisierung das Problem der geringen Energieeffizienz in Gebäuden lösen?
- OpenAI-Mitbegründer im Interview mit Huang Renxun: Die Argumentationsfähigkeiten von GPT-4 haben noch nicht die Erwartungen erfüllt
- Dank der OpenAI-Technologie übertrifft Bing von Microsoft Google im Suchverkehr