
Heim >Technologie-Peripheriegeräte >KI >Ein 38-Milliarden-US-Dollar-Datenriese will eine „KI'-Revolution in Unternehmen einleiten
Ein 38-Milliarden-US-Dollar-Datenriese will eine „KI'-Revolution in Unternehmen einleiten

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBnach vorne
- 2023-07-03 17:22:331098Durchsuche
Autor |. Wan Chen, Li Yuan
Herausgeber |. Jingyu
Am 28. Juni Ortszeit veranstaltete Databricks, eine bekannte amerikanische Datenplattform, seine eigene Jahreskonferenz – den Data and Artificial Intelligence Summit. Bei dem Treffen kündigte Databricks eine Reihe wichtiger neuer Produkte an, darunter LakehouseIQ, Lakehouse AI, Databricks Marketplace und Lakehouse Apps.
Ob es sich um den Namen des Gipfels oder die Benennung neuer Produkte handelt, es ist ersichtlich, dass diese bekannte Datenplattform das große Sprachmodell nutzt, um die Transformation zu KI zu beschleunigen.

Databricks-CEO Ali Ghodsi sagte die Inklusivität von Daten und KI|Databricks
„Was Databricks erreichen möchte, ist „Datenintegration“ und KI-Inklusivität. Ersteres ermöglicht es, dass Daten jeden Mitarbeiter erreichen, und letzteres ermöglicht, dass KI in jedes Produkt eindringt. Ali Ghodsi, CEO von Databricks, kündigte in seiner Rede die Mission des Teams an.
Kurz vor Beginn der Konferenz hatte Databricks gerade die Übernahme von MosaicML, einer neuen Kraft im KI-Bereich, für 1,3 Milliarden US-Dollar angekündigt und damit einen aktuellen Akquisitionsrekord im KI-Bereich aufgestellt, der die Stärke und Entschlossenheit des Unternehmens zeigt in der KI-Transformation.
PingCAP-Gründer und CEO Liu Qi, der an dem bevorstehenden Treffen teilnimmt, sagte gegenüber Geek Park, dass die Databricks-Plattform gerade KI-Anwendungen auf Unternehmensebene eingeführt habe und bereits mehr als 1.500 Unternehmen Modelle darauf trainieren. „Die Zahlen übertreffen die Erwartungen.“ " Gleichzeitig ist er davon überzeugt, dass Databricks‘ frühere Anhäufung von Daten + KI es dem Unternehmen ermöglichte, schnell neue Produkte auf Basis der vorherigen Plattform hinzuzufügen, als KI populär wurde, und schnell Dienste im Zusammenhang mit großen Modellen bereitzustellen.
„Das Wichtigste ist die Geschwindigkeit.“ Liu Qi sagte, dass es im Zeitalter großer Modelle derzeit möglicherweise die größte Herausforderung für alle Datenunternehmen sei, große Modelle schneller in bestehende Produkte zu integrieren und die Probleme der Benutzer zu lösen Es ist auch die größte Herausforderung für alle Datenunternehmen.
Gesprächsthemen
- Durch die Aktualisierung der interaktiven Schnittstelle können normale Menschen, die keine Datenanalysten sind, natürliche Sprache direkt zum Abfragen und Analysieren von Daten verwenden.
- Für Unternehmen wird es immer einfacher, große Modelle in Cloud-Datenbanken bereitzustellen, und es wird auch einfacher, fertige Tools für große Modelle direkt zur Datenanalyse zu verwenden.
- Mit der Weiterentwicklung der KI wird der Wert von Daten immer höher und das Potenzial von Daten wird weiter freigesetzt.
Datenbank begrüßt die Interaktion in natürlicher Sprache
Databricks veröffentlichte auf der Konferenz ein neues LakehouseIQ-Tool, das als „Artefakt“ gefeiert wurde. LakehouseIQ ist eine der größten jüngsten Bemühungen von Databricks – die Universalisierung der Datenanalyse. Das heißt, normale Menschen, die Python und SQL nicht beherrschen, können problemlos auf Unternehmensdaten zugreifen und Datenanalysen in natürlicher Sprache durchführen.
Um dieses Ziel zu erreichen, ist LakehouseIQ als eine Sammlung von Funktionen konzipiert, die sowohl von normalen Endbenutzern als auch von Entwicklern verwendet werden können, wobei unterschiedliche Funktionen für unterschiedliche Benutzer konzipiert sind.
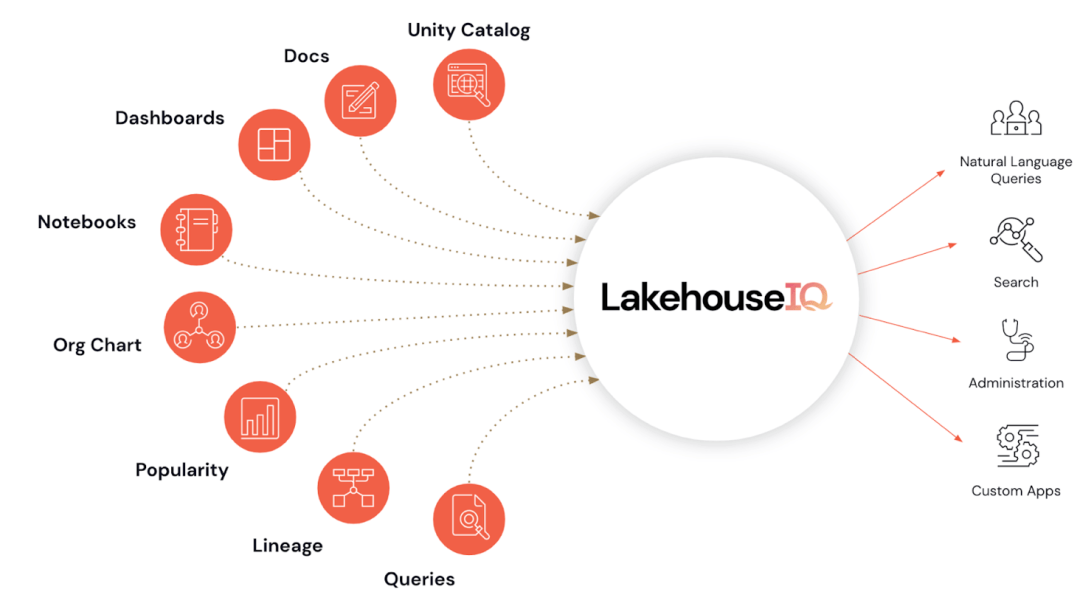
LakehouseIQ Produktbild|Databricks
Für Entwickler wurde LakehouseIQ in Notebooks veröffentlicht. Mit dieser Funktion kann LakehouseIQ große Sprachmodelle verwenden, um Entwicklern dabei zu helfen, Code zu vervollständigen, zu generieren und zu interpretieren sowie Codereparaturen, Debugging und Berichtserstellung durchzuführen.
Für normale Nicht-Programmierer bietet Databricks eine Schnittstelle, die direkt mit natürlicher Sprache interagieren kann. Es basiert auf einem großen Sprachmodell und kann natürliche Sprache direkt zum Suchen und Abfragen von Daten verwenden. Gleichzeitig ist diese Funktion in Unity Catalog integriert, sodass Unternehmen den Zugriff auf Datensuchen und -abfragen steuern und nur Daten zurückgeben können, zu deren Anzeige der Fragesteller berechtigt ist.
Seit der Einführung großer Modelle ist die Verwendung natürlicher Sprache zum Abfragen und Analysieren von Daten tatsächlich ein Hotspot in Richtung Datenanalyse, und viele Unternehmen haben Pläne in diese Richtung gemacht. Zusammen mit dem alten Rivalen Snowflake von Databricks konzentriert sich auch die gerade angekündigte Document AI-Funktion auf diese Richtung.
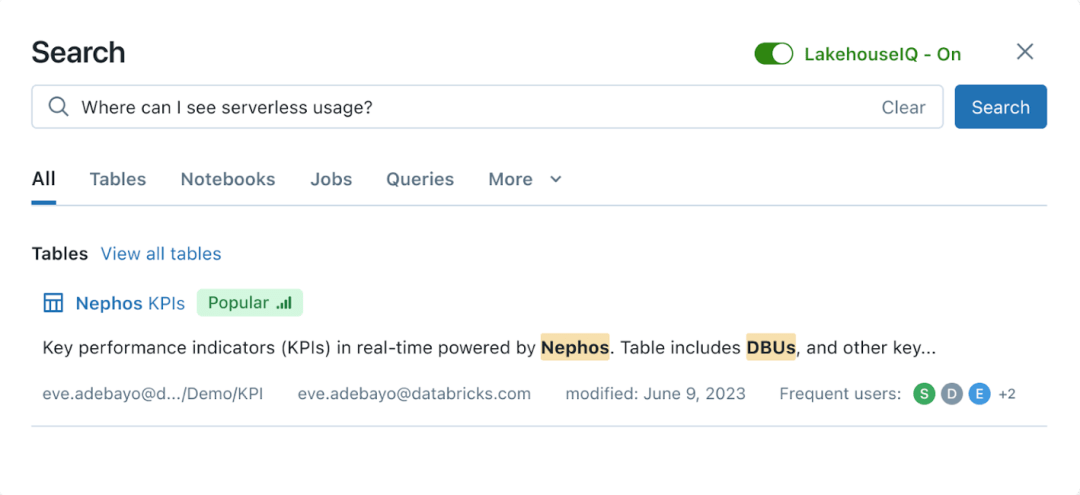
LakehouseIQ-Abfrageschnittstelle in natürlicher Sprache|Databricks
Databricks behauptet jedoch, dass LakehouseIQ funktional eine bessere Leistung erbringt. Es wird darauf hingewiesen, dass universell einsetzbare große Sprachmodelle beim Verständnis spezifischer Kundendaten, interner Terminologie und Nutzungsmuster Einschränkungen aufweisen. Die Technologie von Databricks nutzt kundeneigene Schemata, Dokumente, Abfragen, Beliebtheit, Threads, Notizbücher und Business-Intelligence-Dashboards, um Informationen zu gewinnen und mehr Abfragen zu beantworten.
Es gibt einen weiteren Unterschied zwischen den Funktionen von Databricks und Snowflake. Die Document AI-Funktion der Snowflake-Plattform ist auf die Abfrage unstrukturierter Daten in Dokumenten beschränkt, während LakehouseIQ für strukturierte Lakehouse-Daten und -Code geeignet ist.
02
Vom maschinellen Lernen bis zur KI
Die Ähnlichkeiten zwischen Databricks und Snowflake beim Start enden hier nicht.
Auf dieser Konferenz veröffentlichte Databricks Databricks Marketplace und Lakehouse AI, die vollständig mit dem Schwerpunkt der zweitägigen Konferenz von Snowflake übereinstimmen. Beide konzentrieren sich auf die Bereitstellung großer Sprachmodelle in Datenbankumgebungen.
In der Vision von Databricks kann Databricks Kunden nicht nur bei der zukünftigen Bereitstellung großer Modelle unterstützen, sondern auch fertige Tools für große Modelle bereitstellen.
Databricks hatte früher die Marke Databricks Machine Learning. Bei dieser Pressekonferenz hat Databricks seine Marke komplett neu positioniert und auf Lakehouse AI umgestellt, wobei der Schwerpunkt auf der Unterstützung von Kunden bei der Bereitstellung großer Modelle liegt.
Databricks Marketplace ist jetzt auf Databricks verfügbar. Im Databricks Marketplace können Benutzer auf eine große, geprüfte Sammlung von Open-Source-Sprachmodellen zugreifen, darunter MPT-7B, Falcon-7B und Stable Diffusion, und außerdem Datensätze und Datenbestände entdecken und abrufen. Lakehouse AI bietet auch einige LLMOps-Funktionen (Large Language Model Operations).
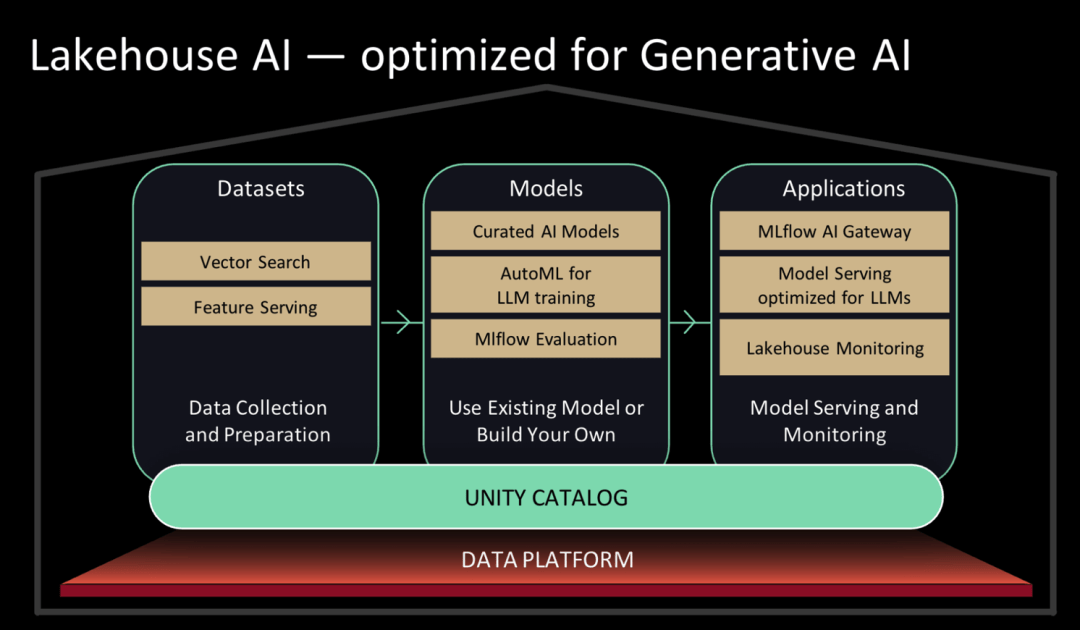
Lakehouse AI-Architekturdiagramm|Databricks
Snowflake setzt dies ebenfalls aktiv ein, mit ähnlichen Funktionen, die von Nvidia NeMo, Nvidia AI Enterprise, Dataiku und John Snow Labs bereitgestellt werden (die Zusammenarbeit mit Nvidia ist einer der Höhepunkte der Snowflake-Konferenz, siehe Bericht von Geek Park).
Snowflake und Databricks unterscheiden sich darin, Kunden bei der Bereitstellung großer Modelle zu unterstützen. Snowflake hat sich entschieden, aktiv mit Partnern zusammenzuarbeiten, während Databricks versucht hat, die Funktionalität als native Funktion seiner Kernplattform hinzuzufügen.
Bezüglich der Bereitstellung fertiger Tools kündigte Databricks an, dass der Databricks Marketplace künftig auch Lakehouse-Apps bereitstellen wird. Lakehouse Apps werden direkt auf den Databricks-Instanzen der Kunden ausgeführt, wo sie sich in die Daten der Kunden integrieren, Databricks-Dienste nutzen und erweitern und Benutzern die Interaktion über ein Single-Sign-On-Erlebnis ermöglichen können. Daten müssen nie die Instanz des Kunden verlassen und es gibt keine Datenverschiebungs- und Sicherheits-/Zugriffsprobleme.
Dies stimmt hinsichtlich Namensgebung und Funktionalität vollständig mit den Produkten von Snowflake überein. Snowflakes ähnlicher Snowflake Marketplace und die Snowflake Native App sind bereits online und gehören zu den Highlights der Einführung. Bloomberg kündigte auf der Snowflake-Konferenz eine von Bloomberg bereitgestellte Data License Plus (DL+)-APP an, die es Kunden ermöglicht, in wenigen Minuten eine gebrauchsfertige Umgebung in der Cloud mit vollständig modellierten Bloomberg-Abonnementdaten und ESG-Inhalten von mehreren Anbietern zu konfigurieren.
03
Die Datenplattform bringt neue Veränderungen mit sich
Bei der Eröffnungs-Keynote gab Databricks eine Zahl bekannt: In den vergangenen 30 Tagen haben mehr als 1.500 Kunden Transformer-Modelle auf der Databricks-Plattform trainiert.
Wenn man über diese beeindruckende Zahl spricht, glaubt PingCAP Liu Qi, dass dies zeigt, dass Unternehmen KI viel schneller als erwartet anwenden viel größer sein als diese (Anzahl)“
.Ein weiterer Gesichtspunkt ist, dass dies zeigt, dass die strategische Ausrichtung von Databricks im Bereich KI recht umfassend ist. Es ist mittlerweile mehr als nur ein Data Warehouse oder Data Lake. Jetzt bietet es auch: KI-Schulung, KI-Bereitstellung, Modellverwaltung usw. „

Ali Ghodsi nutzt die Revolution der Computer und des Internets, um die Transformation großer Modelle im maschinellen Lernen|Databricks
zu vergleichenMit anderen Worten: Das zugrunde liegende Modell kann auf der Databricks-Plattform trainiert werden, und das Modell der untersten Ebene kann durch einfaches Anpassen der Parameter trainiert werden. Für die zusätzlich zu diesem Modell erforderlichen KI-Dienste hat Databricks auch die entsprechende Infrastruktur bereitgestellt – heute wurden die Vektorsuche und der Feature Store veröffentlicht.
Databricks wurde vollständig auf große Modelle aktualisiert.
In der Vergangenheit hat Databricks viel Erfahrung im Bereich KI gesammelt, beispielsweise mit der Verwendung kleiner Modelle, um die Effizienz zu verbessern und die Latenz beim Erstellen von Indizes, beim Abfragen von Daten und beim Vorhersagen von Arbeitslasten zu reduzieren. Die Fähigkeit, große Modelle in einem so hohen Tempo aufzuholen, überrascht jedoch immer noch viele Menschen.
Bevor das KI-Layout auf dem heutigen Gipfel vollständig vorgestellt wurde, erwarb Databricks Okera (KI-Datenverwaltung), brachte sein eigenes Open-Source-Großmodell Dolly 2.0 auf den Markt und erwarb eine Reihe von Maßnahmen auf einmal.
Howie, ein Lehrer aus dem Silicon Valley, glaubt in diesem Zusammenhang, dass man an den beiden Konferenzen von Databricks und Snowflake deutlich erkennen kann: Die Gründer der beiden Unternehmen glauben, dass die Maßnahmen, die sie auf der Grundlage von Datenbanken und Data Lakes ergriffen haben, auf sie zukommen werden grundlegende Probleme in der Zukunft. So wie sie es vor einem Jahr gemacht haben, wird es in den nächsten Jahren nicht mehr funktionieren.
Entsprechend bedeutet die Fähigkeit, große Modelle schnell fertigzustellen, auch, dass der durch große Modelle geschaffene inkrementelle Markt erschlossen werden kann.
Liu Qi glaubt, dass das Aufkommen großer Modelle viele neue Anforderungen ausgelöst hat, die es vor der Einführung großer Modelle nicht gab. Ohne Datenunterstützung wird das Modell insbesondere im Hinblick auf die Differenzierung nicht funktionieren können. Wenn jeder ein großes Vorbild ist, gibt es möglicherweise keinen Unterschied zwischen Ihnen und anderen. „
Aber im Vergleich zu großen Modellen schien das Publikum auf dem Gipfel kleinen Modellen mehr Aufmerksamkeit zu schenken, da kleine Modelle mehrere Vorteile haben: Geschwindigkeit, Kosten und Sicherheit. Liu Qi sagte, dass er auf der Grundlage seiner eigenen einzigartigen Daten differenzierte Modelle erstellen kann. Das Modell muss klein genug sein, um diese drei Anforderungen zu erfüllen: billig genug, schnell genug und sicher genug.
Es ist erwähnenswert, dass sowohl Databricks als auch Snowflake kürzlich ihre Umsatzdaten bekannt gegeben haben und das jährliche Umsatzwachstum der Plattform mehr als 60 % beträgt. Diese Wachstumsrate spiegelt sich in der zunehmenden Konzentration auf Daten vor dem Hintergrund einer Verlangsamung der Softwareausgaben auf dem gesamten Markt wider. Mit dem Aufkommen groß angelegter Modelle wurde der Wert von Daten auf diesem Databricks Summit mit dem Thema Daten plus KI hervorgehoben.
Mit der Einführung groß angelegter Modelle wird eine automatische Datengenerierung möglich und die Datenmenge wird voraussichtlich exponentiell zunehmen. Die Frage, wie man einfach auf Daten zugreifen kann, wie man verschiedene Datenformate unterstützt und wie man den Wert hinter den Daten ausschöpft, wird immer häufiger benötigt.
Andererseits sind viele Unternehmen immer noch damit beschäftigt, große Modelle in Unternehmenssoftware zu integrieren. Angesichts der Sicherheit, des Datenschutzes und der Kosten trauen sich jedoch nur wenige, diese direkt zu nutzen. Sobald große Modelle direkt in Unternehmensdaten bereitgestellt werden, ohne Daten zu verschieben, wird der Schwellenwert für die Bereitstellung großer Modelle weiter gesenkt und die Menge und Geschwindigkeit des Datenverbrauchs wird weiter freigegeben.
Das obige ist der detaillierte Inhalt vonEin 38-Milliarden-US-Dollar-Datenriese will eine „KI'-Revolution in Unternehmen einleiten. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Technologietrends, die Sie im Jahr 2023 im Auge behalten sollten
- Wie künstliche Intelligenz Rechenzentrumsteams neue Alltagsaufgaben beschert
- Können künstliche Intelligenz oder Automatisierung das Problem der geringen Energieeffizienz in Gebäuden lösen?
- OpenAI-Mitbegründer im Interview mit Huang Renxun: Die Argumentationsfähigkeiten von GPT-4 haben noch nicht die Erwartungen erfüllt
- Dank der OpenAI-Technologie übertrifft Bing von Microsoft Google im Suchverkehr