
Heim >Technologie-Peripheriegeräte >KI >Neue Forschung des Teams von Tian Yuandong: Feinabstimmung von <1000 Schritten, Erweiterung des LLaMA-Kontexts auf 32K
Neue Forschung des Teams von Tian Yuandong: Feinabstimmung von <1000 Schritten, Erweiterung des LLaMA-Kontexts auf 32K

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBnach vorne
- 2023-06-30 15:26:132049Durchsuche
Da jeder seine eigenen großen Modelle weiter aktualisiert und iteriert, ist auch die Fähigkeit von LLM (Large Language Model) zur Verarbeitung von Kontextfenstern zu einem wichtigen Bewertungsindikator geworden.
Zum Beispiel bietet der gpt-3.5-turbo von OpenAI eine Kontextfensteroption mit 16.000 Token, und AnthropicAI hat Claudes Token-Verarbeitungskapazität auf 100.000 erhöht. Was ist das Konzept eines großen Modellverarbeitungskontextfensters? GPT-4 unterstützt beispielsweise 32.000 Token, was 50 Seiten Text entspricht, was bedeutet, dass GPT-4 beim Sprechen oder Generieren bis zu 50 Seiten Inhalt speichern kann Text.
Im Allgemeinen ist die Fähigkeit großer Sprachmodelle, mit der Größe des Kontextfensters umzugehen, vorbestimmt. Für das von Meta AI veröffentlichte LLaMA-Modell muss die Größe des Eingabetokens beispielsweise kleiner als 2048 sein.
Allerdings wird bei Anwendungen wie dem Führen langer Gespräche, dem Zusammenfassen langer Dokumente oder dem Ausführen langfristiger Pläne das voreingestellte Kontextfensterlimit häufig überschritten, weshalb LLMs, die längere Kontextfenster verarbeiten können, beliebter sind.
Aber dies steht vor einem neuen Problem. Die Ausbildung eines LLM mit einem langen Kontextfenster von Grund auf erfordert eine Menge Investitionen. Dies führt natürlich zu der Frage: Können wir das Kontextfenster bestehender vorab trainierter LLMs erweitern?
Ein einfacher Ansatz besteht darin, den vorhandenen vorab trainierten Transformer zu optimieren, um ein längeres Kontextfenster zu erhalten. Empirische Ergebnisse zeigen jedoch, dass sich auf diese Weise trainierte Modelle nur sehr langsam an lange Kontextfenster anpassen. Nach 10.000 Trainingschargen ist der Anstieg des effektiven Kontextfensters immer noch sehr gering, nur von 2048 auf 2560 (wie in Tabelle 4 im experimentellen Teil zu sehen ist). Dies deutet darauf hin, dass dieser Ansatz bei der Skalierung auf längere Kontextfenster ineffizient ist.
In diesem Artikel führten Forscher von Meta Position Interpolation (PI) ein, um das Kontextfenster einiger bestehender vorab trainierter LLMs (einschließlich LLaMA) zu erweitern. Die Ergebnisse zeigen, dass das LLaMA-Kontextfenster mit weniger als 1000 Feinabstimmungsschritten von 2k auf 32k skaliert werden kann.
 Bilder
Bilder
Papieradresse: https://arxiv.org/pdf/2306.15595.pdf
Die Schlüsselidee dieser Forschung besteht nicht darin, eine Extrapolation durchzuführen, sondern die Position direkt zu reduzieren index: Stellen Sie sicher, dass der maximale Positionsindex mit dem Kontextfensterlimit der Vortrainingsphase übereinstimmt. Mit anderen Worten: Um mehr Eingabetoken zu berücksichtigen, interpoliert diese Studie Positionskodierungen an benachbarten ganzzahligen Positionen und nutzt dabei die Tatsache aus, dass Positionskodierungen auf nicht ganzzahlige Positionen angewendet werden können, anstatt über die trainierten Positionen hinaus zu extrapolieren. Letzteres kann zu katastrophalen Werten führen.
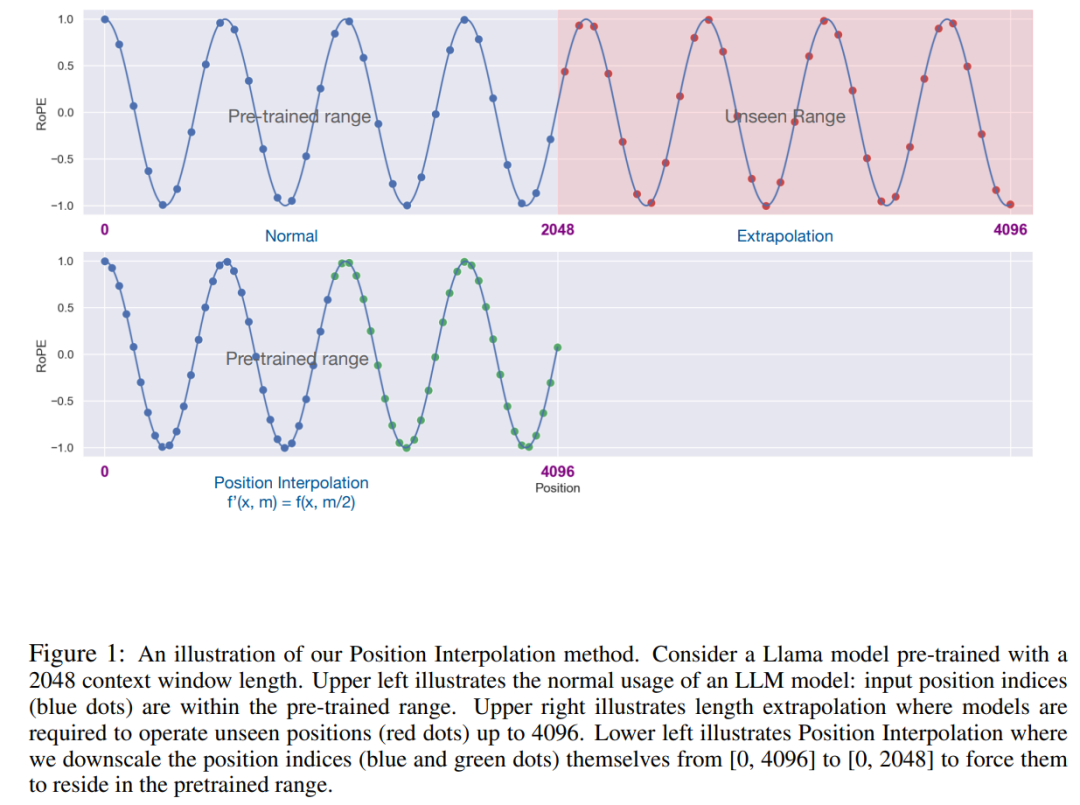
Die PI-Methode erweitert die Kontextfenstergröße von auf RoPE (Rotation Positional Encoding) basierenden vorab trainierten LLM wie LLaMA auf bis zu 32768 mit minimaler Feinabstimmung (innerhalb von 1000 Schritten). Diese Forschung liefert gute Ergebnisse zu einer Vielzahl von Aufgaben, die einen langen Kontext erfordern, einschließlich Retrieval, Sprachmodellierung und Zusammenfassung langer Dokumente von LLaMA 7B bis 65B. Gleichzeitig behält das von PI erweiterte Modell innerhalb seines ursprünglichen Kontextfensters eine relativ gute Qualität bei.
Methode
RoPE ist in großen Sprachmodellen wie LLaMA, ChatGLM-6B und PaLM vorhanden, mit denen wir vertraut sind. Diese Methode wurde von Su Jianlin und anderen von Zhuiyi Technology vorgeschlagen und durch absolute implementiert Kodierung. Relative Positionskodierung.
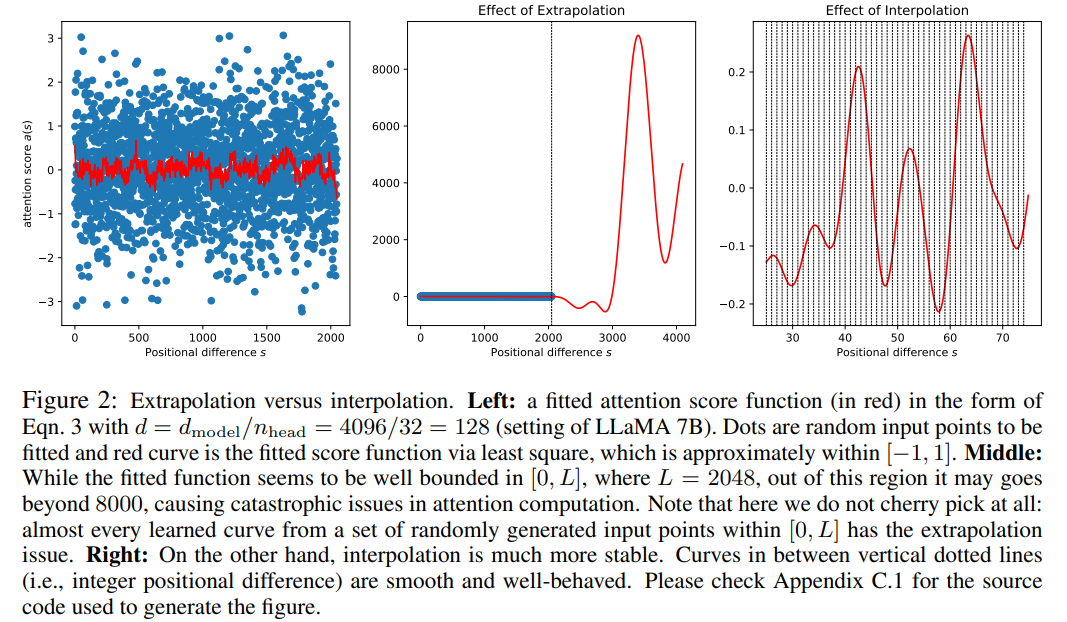
Obwohl der Aufmerksamkeitswert in RoPE nur von der relativen Position abhängt, ist seine Extrapolationsleistung nicht gut. Insbesondere bei der direkten Skalierung auf größere Kontextfenster kann die Verwirrung auf sehr hohe Zahlen (z. B. > 10^3) ansteigen.
Dieser Artikel verwendet die Positionsinterpolationsmethode und der Vergleich mit der Extrapolationsmethode ist wie folgt. Aufgrund der Glattheit der Basisfunktionen ϕ_j ist die Interpolation stabiler und führt nicht zu Ausreißern.
 Bild
Bild
Diese Studie ersetzte RoPE f durch f′ und erhielt die folgende Formel:
 Bild
Bild
Diese Studie nennt die Konvertierung der Positionskodierung Positionsinterpolation. Dieser Schritt reduziert den Positionsindex von [0, L′ ) auf [0, L), um mit dem ursprünglichen Indexbereich übereinzustimmen, bevor RoPE berechnet wird. Daher wurde als Eingabe für RoPE der maximale relative Abstand zwischen zwei beliebigen Token von L ′ auf L reduziert. Durch die Angleichung des Bereichs der Positionsindizes und relativen Abstände vor und nach der Erweiterung werden die Auswirkungen der Kontextfenstererweiterung auf die Aufmerksamkeitsbewertungsberechnungen abgemildert, was die Anpassung des Modells erleichtert.
Es ist erwähnenswert, dass die Methode zur Neuskalierung des Positionsindex weder zusätzliche Gewichte einführt noch die Modellarchitektur in irgendeiner Weise verändert.
Experimente
Diese Studie zeigt, dass die Positionsinterpolation das Kontextfenster effektiv auf das 32-fache der ursprünglichen Größe erweitern kann und dass diese Erweiterung in nur wenigen hundert Trainingsschritten abgeschlossen werden kann.
Tabelle 1 und Tabelle 2 zeigen die Verwirrung des PI-Modells und des Basismodells für die PG-19- und Arxiv Math Proof-Pile-Datensätze. Die Ergebnisse zeigen, dass das mit der PI-Methode erweiterte Modell die Ratlosigkeit bei längeren Kontextfenstergrößen deutlich verbessert.
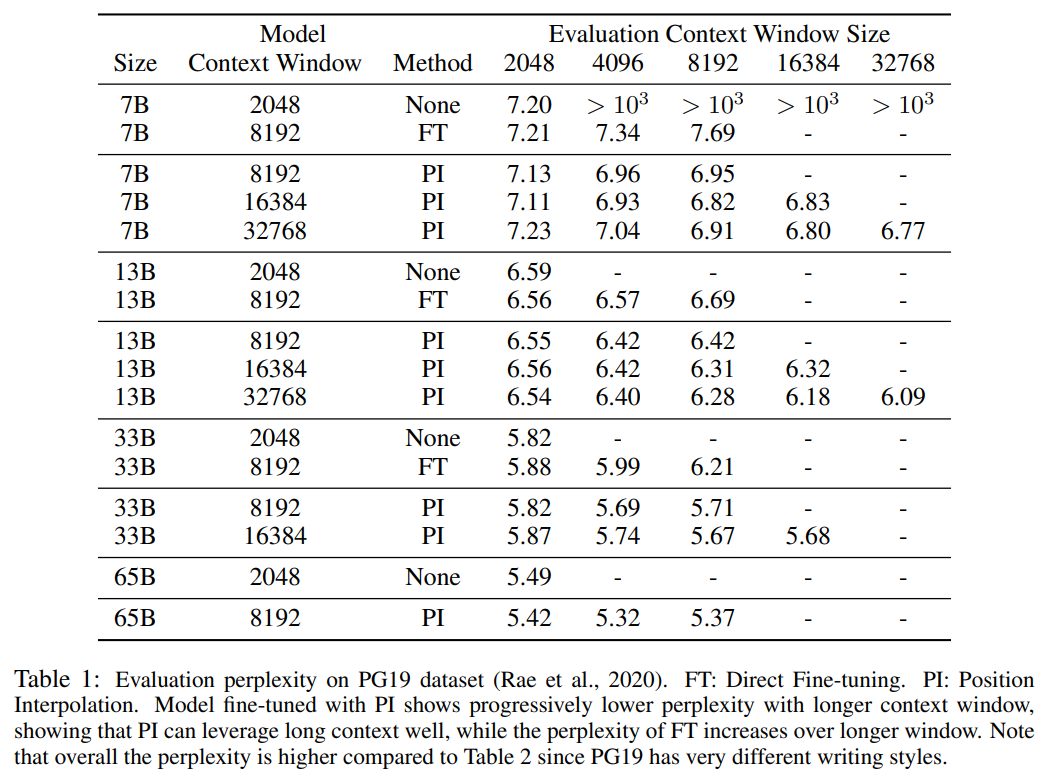
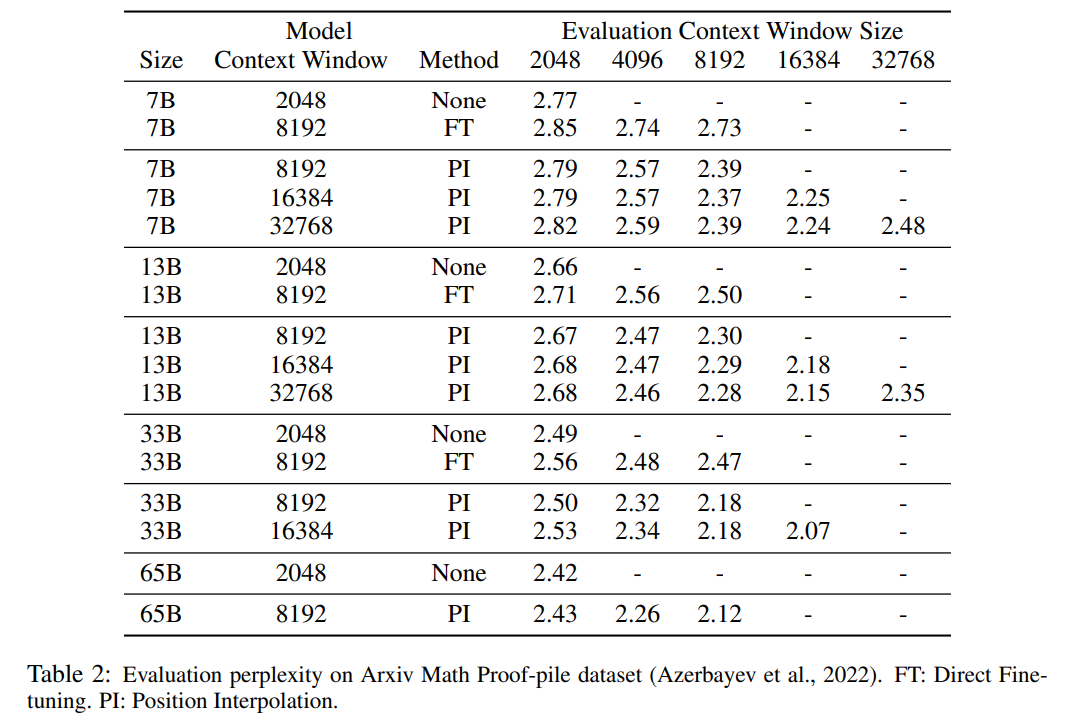
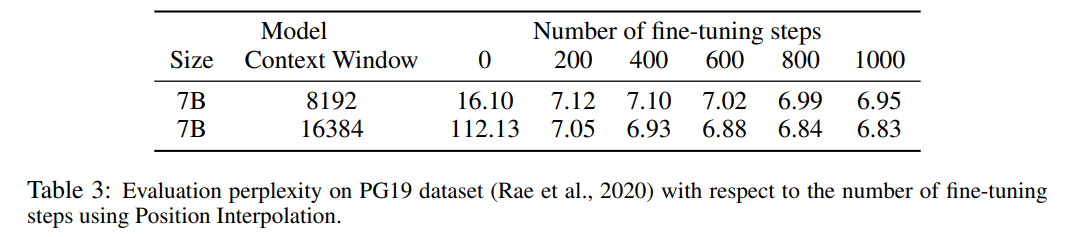
Tabelle 3 zeigt die Beziehung zwischen Ratlosigkeit und der Anzahl der Feinabstimmungsschritte bei der Erweiterung des LLaMA 7B-Modells auf 8192- und 16384-Kontextfenstergrößen unter Verwendung der PI-Methode für den PG19-Datensatz.
Aus den Ergebnissen geht hervor, dass das Modell ohne Feinabstimmung (die Anzahl der Schritte beträgt 0) bestimmte Sprachmodellierungsfunktionen demonstrieren kann. Wenn beispielsweise das Kontextfenster auf 8192 erweitert wird, ist die Verwirrung geringer als 20 (im Vergleich zu Unten ist die Verwirrung der direkten Extrapolationsmethode größer als 10^3). Bei 200 Schritten übersteigt die Ratlosigkeit des Modells die des Originalmodells bei einer Kontextfenstergröße von 2048, was darauf hindeutet, dass das Modell in der Lage ist, längere Sequenzen effektiv für die Sprachmodellierung zu nutzen als die vorab trainierte Einstellung. Bei 1000 Schritten ist eine stetige Verbesserung des Modells zu beobachten und es wird eine bessere Ratlosigkeit erreicht.
 Bilder
Bilder
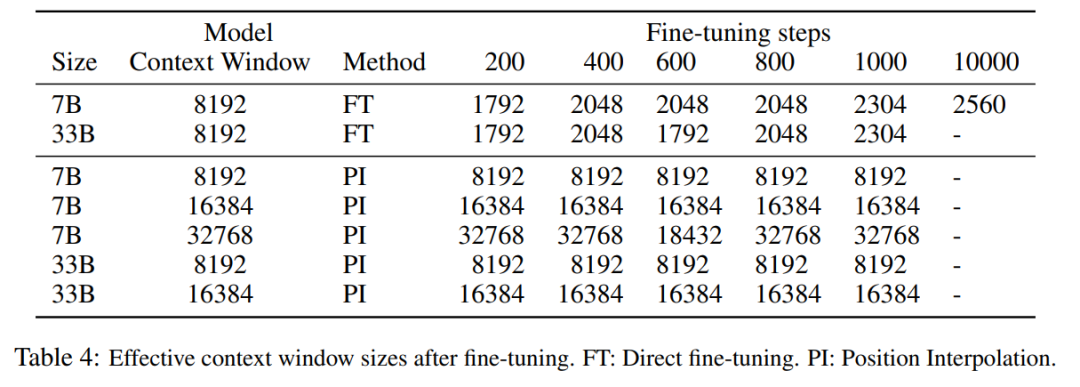
Die folgende Tabelle zeigt, dass das von PI erweiterte Modell das Skalierungsziel hinsichtlich der effektiven Kontextfenstergröße erfolgreich erreicht, d. h. nach nur 200 Schritten der Feinabstimmung die effektive Kontextfenstergröße erreicht den Maximalwert, konsistent über die Modellgrößen 7B und 33B und bis zu 32768 Kontextfenster. Im Gegensatz dazu stieg die effektive Kontextfenstergröße des LLaMA-Modells, das nur durch direkte Feinabstimmung erweitert wurde, nur von 2048 auf 2560, ohne Anzeichen einer signifikanten beschleunigten Fenstergrößenzunahme, selbst nach mehr als 10.000 Feinabstimmungsschritten.
 Bilder
Bilder
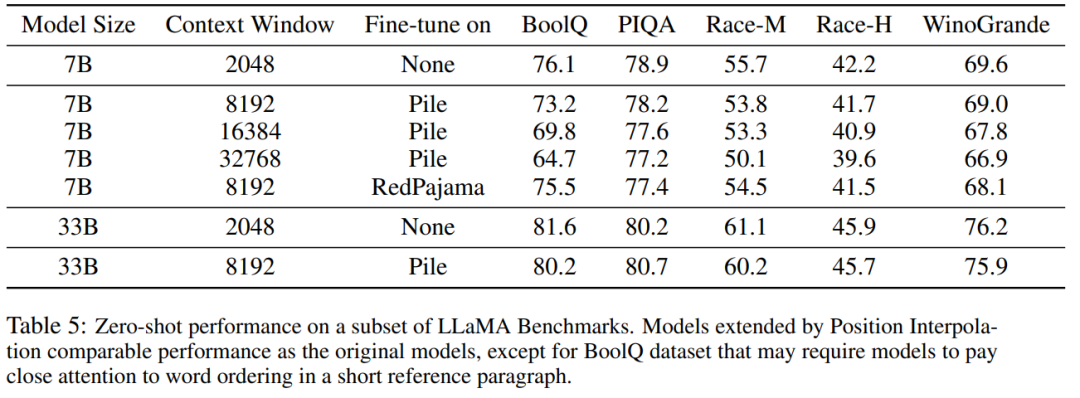
Tabelle 5 zeigt, dass das auf 8192 erweiterte Modell vergleichbare Ergebnisse bei der ursprünglichen Basisaufgabe liefert, die für kleinere Kontextfenster konzipiert wurde, und zwar für die Modellgrößen 7B und 33B, die Verschlechterung in der Benchmark-Aufgabe erreicht bis zu 2 %.
 Bilder
Bilder
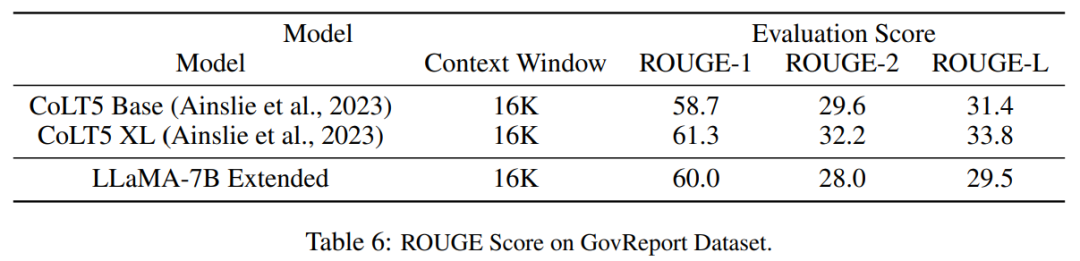
Tabelle 6 zeigt, dass das PI-Modell mit 16384 Kontextfenstern Langtextzusammenfassungsaufgaben effektiv bewältigen kann.
 Bilder
Bilder
Das obige ist der detaillierte Inhalt vonNeue Forschung des Teams von Tian Yuandong: Feinabstimmung von <1000 Schritten, Erweiterung des LLaMA-Kontexts auf 32K. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Technologietrends, die Sie im Jahr 2023 im Auge behalten sollten
- Wie künstliche Intelligenz Rechenzentrumsteams neue Alltagsaufgaben beschert
- Können künstliche Intelligenz oder Automatisierung das Problem der geringen Energieeffizienz in Gebäuden lösen?
- OpenAI-Mitbegründer im Interview mit Huang Renxun: Die Argumentationsfähigkeiten von GPT-4 haben noch nicht die Erwartungen erfüllt
- Dank der OpenAI-Technologie übertrifft Bing von Microsoft Google im Suchverkehr