
Heim >Technologie-Peripheriegeräte >KI >Analyse und Anwendung von Finanzereignissen basierend auf vorab trainierten Modellen
Analyse und Anwendung von Finanzereignissen basierend auf vorab trainierten Modellen

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBnach vorne
- 2023-06-12 11:15:561102Durchsuche

1. Die Hauptaufgaben der Finanzereignisanalyse

Die Hauptaufgaben der Finanzereignisanalyse lassen sich in drei Teile unterteilen:
① Der erste Teil ist die intelligente Analyse unstrukturierter Daten. Informationen im Finanzbereich weisen im Vergleich zu Internetinformationen ihre eigenen Alleinstellungsmerkmale auf. Informationen im Finanzbereich liegen häufig in unstrukturierter Form vor, und es gibt einige spezielle Dateiformate, wie z. B. PDF, die eine größere Herausforderung für die Extraktion sauberer und genauer Daten aus Dateien oder Daten darstellen. Das PDF-Format ist ein Satz- und Druckformat und verfügt nicht über so klare Absätze wie andere Dateitypen. PDF dient eher dem Schriftsatz, daher enthält die Datei nur einige Standortinformationen. Es ist schwieriger, aus unstrukturierten Daten genau formatierten und semantisch klaren Text zu analysieren. Wenn außerdem die Formatsemantik im Dokument unklar ist, führt die Ereignisanalyse zu Rauschen, und diese schmutzigen Daten verursachen erhebliche Störungen beim Modelltraining und bei der Inferenz. Um die Genauigkeit des Modells zu verbessern, sollten daher zunächst die unstrukturierten Daten analysiert werden.
② Der zweite Teil ist das Verständnis der Ereignissemantik, die ein technisch wichtiger Teil ist. Dies umfasst hauptsächlich die Ereigniserkennung, die Extraktion von Ereigniselementen und die Extraktion von Ereignisbeziehungen.
③ Basierend auf dem Verständnis von Ereignissen wird das dritte, für die Aufgabe wichtigere Modul eingeführt, die Ereignisdiagrammanalyse, die die Ereigniskettenanalyse und die Ereignisvorhersage umfasst.
Um die oben genannten Aufgaben zu erledigen, werden zwei weitere wichtige Systeme eingeführt. Das erste ist das Finanzereignissystem. Ein Finanzereignissystem umfasst relevante Entitäten im Finanzbereich, und diese Entitäten haben auch unterschiedliche Anwendungsszenarien. Um diese Themen und Szenarien besser unterstützen zu können, muss ein entsprechendes Ereignissystem aufgebaut werden, das viel Domänenwissen erfordert und erfordert, dass Domänenexperten entsprechendes Wissen als Input bereitstellen. Dies wird uns helfen, ein umfassenderes und wissenschaftlicheres System aufzubauen, das entsprechende Szenarien abdecken kann. Natürlich wird für das induktive Lernen neben Expertenwissen auch Technologie benötigt, die auch ein vollständiges szenariobasiertes und skalierbares Veranstaltungssystem bereitstellen kann.
Denn das Einbringen von Expertenwissen dient vor allem den wichtigeren Ereignissen in der Szene. Bei einigen mittel- und langwierigen Ereignissen wird das Problem hauptsächlich durch einige lernbasierte Technologien gelöst. Mit dem Finanzereignisdiagramm kombinieren wir die Ereignisextraktionstechnologie, die Ereignisbeziehungsklassifizierung und die Darstellung von Lernereignissen und können ein Diagramm zur Analyse und Vorhersage erstellen.
Mit klaren Aufgabenstellungen und der Unterstützung der Technik können wir Nachrichten oder Dokumente aufbereiten und viele Fragen zusammenfassend beantworten. Beispielsweise, welche Art von Ereignis in welchem Unternehmen stattgefunden hat und welche Elemente an dem Ereignis beteiligt waren, wie z. B. gemeinsame Elemente Zeit, Ort, Personen oder Elemente im Zusammenhang mit der Ereignisart. Beispielsweise umfasst das Ereignis „Aktienausgabe des Unternehmens“. die Elemente Ausgabepreis, Auflage etc. Darüber hinaus können wir auch auf diese Informationen achten, beispielsweise auf die Bewertung dieses Ereignisses durch Personen (Sentimentanalyse). und Vorhersagen darüber, was mit dem Unternehmen in Zukunft passieren wird, nachdem bestimmte Arten von Ereignissen eingetreten sind. Wenn Sie die oben genannten Fragen beantworten können, ist dies in vielen Szenarien hilfreich.
Sehen wir uns unten ein konkretes Beispiel an.
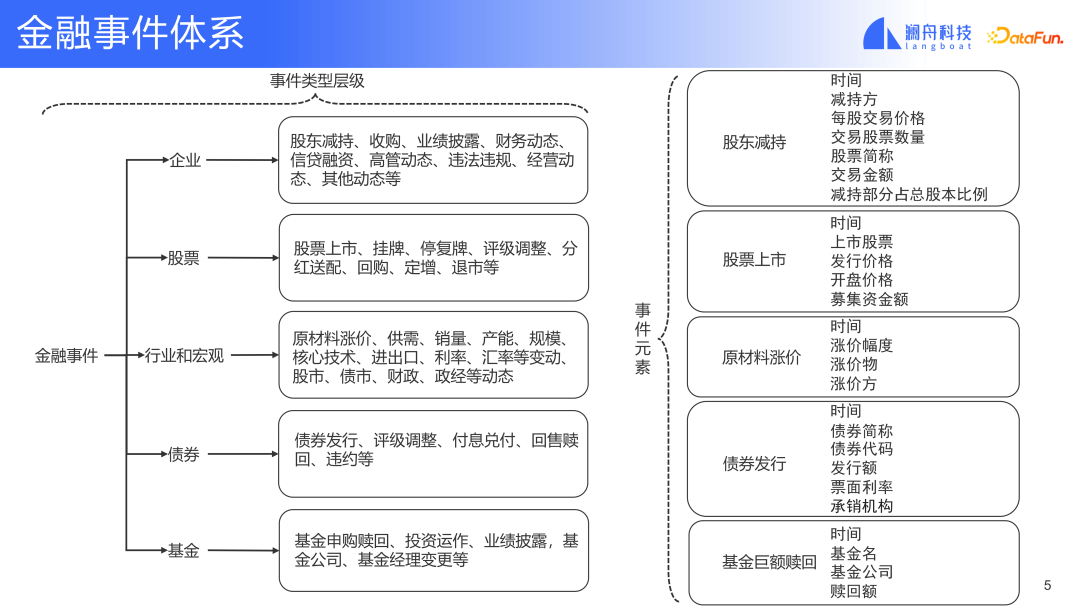
Die obige Abbildung unterteilt das Finanzereignissystem in zwei Ebenen. Die erste Ebene besteht aus fünf Kategorien, die hauptsächlich nach bestimmten Objekten unterschieden werden, z. B. Unternehmensereignisse, Aktienereignisse, Branchen- und Makroereignisse. Ereignisse vom Typ „Schaden“ und Ereignisse vom Typ „Fonds“. Für unterschiedliche Ereignisobjekte werden unterschiedliche Ereignistypen definiert. Dies sind die häufigsten Objekte im Finanzwesen. In der zweiten Ebene unterteilen wir jeden Objekttyp weiter. Zum Beispiel übliche Arten von Ereignissen in einem Unternehmen, wie z. B. eine Aktionärsreduzierung usw. (siehe Bild oben). Nehmen Sie als Beispiel Ereignisse wie die Reduzierung Ihrer Anteile durch Aktionäre. Zu den darin enthaltenen Ereigniselementen gehören der Zeitpunkt der Reduzierung, die Aktionäre, die ihre Anteile reduziert haben, der Transaktionspreis zum Zeitpunkt der Reduzierung und andere Informationen. Die Definition eines vollständigen Ereignissystems, das auf das Szenario zugeschnitten ist, ist eine wichtige Voraussetzung dafür, dass die Ereignisanalyse ihre Ziele erreichen kann. Der Detaillierungsgrad bei der Definition des Ereignissystems bestimmt den Grad an feinkörnigen Ereignisinformationen, die die endgültige Ereignisanalyse liefern kann erreichen.
Die Veranstaltungskarte wird unten vorgestellt.
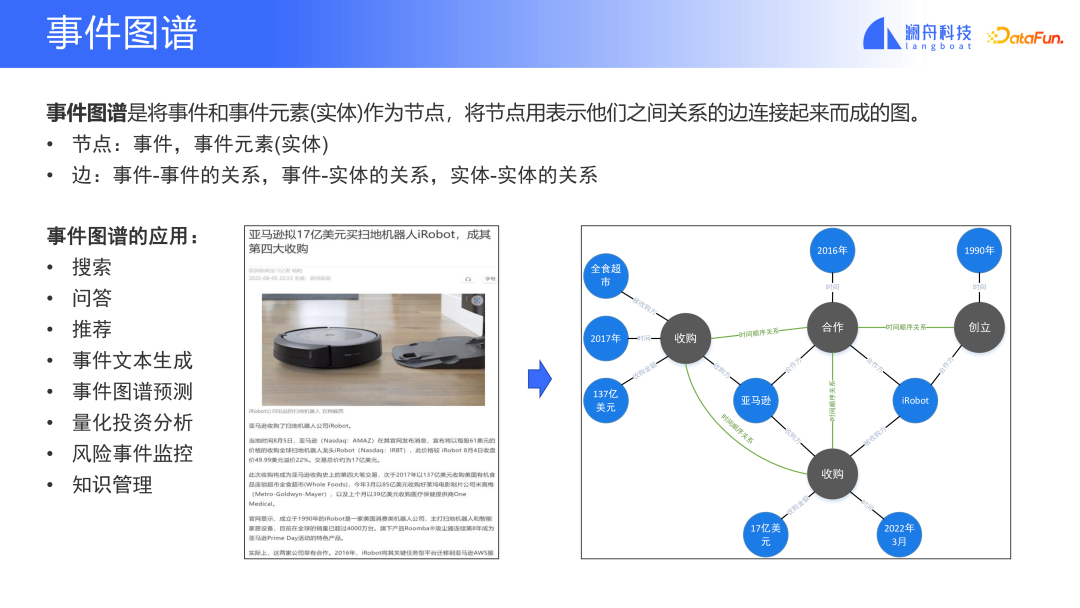
Der Ereignisgraph ist ein Graph und enthält Knoten und Kanten. Im Ereignisdiagramm können Ereignisknoten Ereignisse oder Entitäten in den Ereignissen sein, beispielsweise Unternehmen. Eine Kante ist die Beziehung zwischen Ereignissen oder zwischen Ereignissen und Entitäten oder zwischen Entitäten.
Schauen wir uns ein Beispiel an. Das Bild oben ist ein Nachrichtenartikel, der die Übernahme von iRobot durch Amazon vorstellt. In diesem Nachrichtenbericht wurden insgesamt vier Ereignisse beschrieben, darunter zwei Akquisitionen, die zu unterschiedlichen Zeitpunkten stattfanden. Die anderen beiden sind die Ereignisse der Unternehmensgründung und die Ereignisse der Zusammenarbeit. Diese Ereignisse sind durch die chronologische Abfolge ihres Auftretens verbunden. Diese Nachrichten enthalten neben Ereignissen auch andere Entitäten und Zeiten, und diese Entitäten und Zeiten sind auch durch entsprechende Beziehungen verbunden.
Wenn wir unstrukturierte Webseiteninformationen auf diese Weise betrachten, indem wir den Text und die Absätze im Dokument analysieren, eine semantische Analyse der Absätze durchführen und Ereignisentitäten und -beziehungen extrahieren, können wir ein Ereignisdiagramm erstellen. Das heißt, unstrukturierte Daten in strukturierte Informationen umzuwandeln. Mit strukturierten Informationen ist es einfacher, die Informationen zu verstehen und zu verarbeiten. Solche Informationen können in Informationsbeschaffungsszenarien wie Suche und Frage und Antwort oder in Geschäftsszenarien wie Risikoüberwachung und quantitativen Investitionen im Finanzbereich verwendet werden.
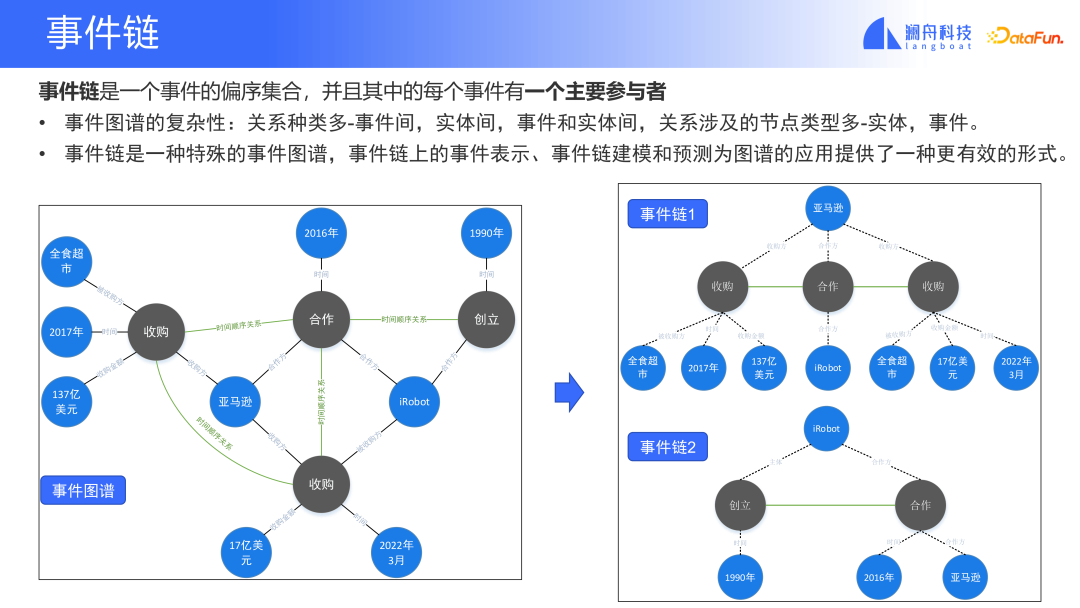
Die Ereigniskette ist ein spezielles Ereignisdiagramm und ein vereinfachter Modus des Ereignisdiagramms. Es konzentriert sich hauptsächlich auf eine Reihe von Ereignissen, die einem Teilnehmer widerfahren, und auf die Beziehung zwischen Ereignissen. Wie aus der obigen Abbildung ersichtlich ist, kann das Ereignisdiagramm auf der linken Seite in die beiden Ereignisketten auf der rechten Seite vereinfacht werden. Die Ereigniskette enthält nur vereinfachte Knoten, und andere Elemente können als Attributinformationen der Ereigniskette betrachtet werden. Diese Vereinfachung ist hilfreich für die praktische Anwendung von Ereignisgraphen. Nachdem die Beziehungen und Knoten des Ereignisdiagramms vereinfacht wurden, konzentriert sich das Lernen und Verarbeiten des Diagramms durch das Modell nur auf eine Art von Knoten und eine Art von Beziehung zwischen Ereignissen, wodurch die Komplexität dieses Problems verringert wird. Obwohl vereinfacht, bleiben die Hauptinformationen der Veranstaltung erhalten, wie z. B. Veranstaltungstyp, Veranstaltungsthema und andere Informationen.
Sehen wir uns an, wie eine Ereigniskette vorhergesagt wird.
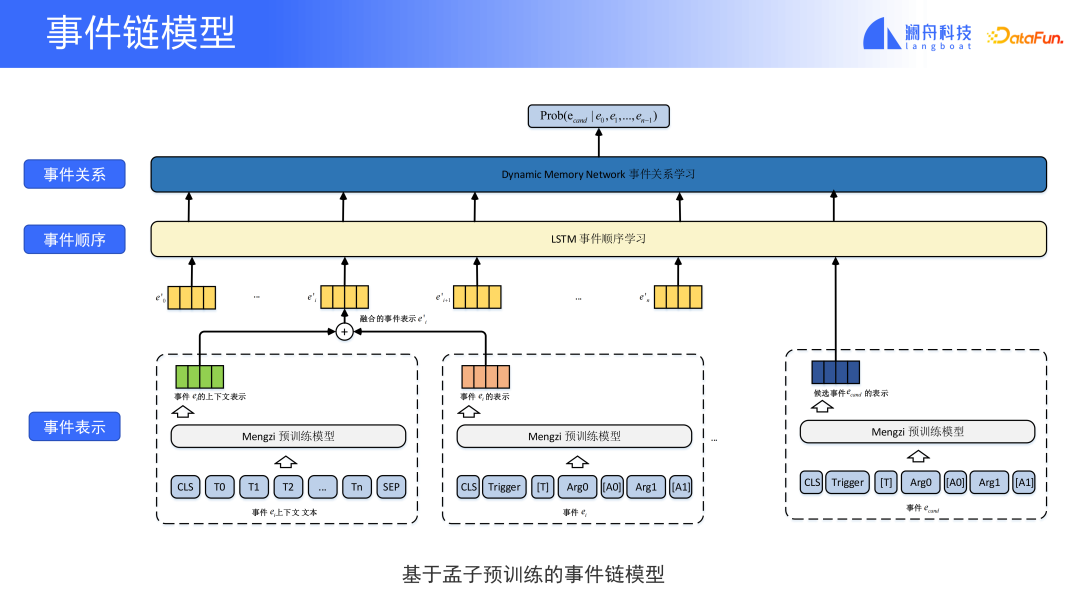
Das obige Bild ist ein Vorhersagemodell einer Ereigniskette. Es besteht im Wesentlichen aus drei Teilen. Der erste Teil ist die Ereignisdarstellung, wobei aktuelle Ereignisse, historische Ereignisse und letztendlich die Ereignisse im Text aufgeführt sind, die wir vorhersagen möchten. Historische Ereignisse und vorherzusagende Ereignisse, die Auslösewörter und die Ereigniselemente, die sie darstellen, können zusammengefügt werden, um historische Informationen besser zu erfassen. Durch die Kombination der Kontextdarstellung und der historischen Darstellung von Ereignissen betreten wir den zweiten Teil, die Sequenzdarstellung von Ereignissen. Hier kommt eine LSTM-Netzwerkstruktur zum Einsatz, die die zeitliche Beziehung zwischen Ereignissen erfassen und Ereignissequenzinformationen in die Ereignisdarstellung integrieren kann. Schließlich werden Ereignisdarstellungen mit chronologischen Beziehungen in ein dynamisches Netzwerk eingespeist, das zur Vorhersage von Kandidatenereignissen und Ereignissen in den gegebenen Nachrichten verwendet werden kann. Wenn es beispielsweise Dutzende mögliche Ereignistypen gibt, können wir anhand der Ereignistypen, die wir in den aktuellen Nachrichten gesehen haben, vorhersagen, welches Ereignis ein größerer Ereignistyp sein könnte, der diesem Thema in Zukunft passieren wird. Das Ergebnis ist eine Verteilung der Ereignistypen.
Hier muss betont werden, dass die Vorhersageergebnisse dieses Modells nicht darin bestehen, Ereignisse vorherzusagen, die definitiv in der Zukunft im Unternehmen eintreten werden, sondern solche Hilfsinformationen bereitzustellen, die eine Grundlage für Analysen, Vorhersagen usw. bieten Urteil.
Die oben erwähnte Ereigniskette und Ereignisvorhersage sind Vorhersagen und Urteile über Situationen, die noch nicht eingetreten sind. Die Ereignisvorhersage kann tatsächlich eine nützliche Hilfe für bereits eingetretene Ereignisse sein.
Schauen wir uns ein weiteres Beispiel an. Dieses Beispiel basiert auf bereits eingetretenen Ereignissen, um nützliche Hilfe zu bieten.
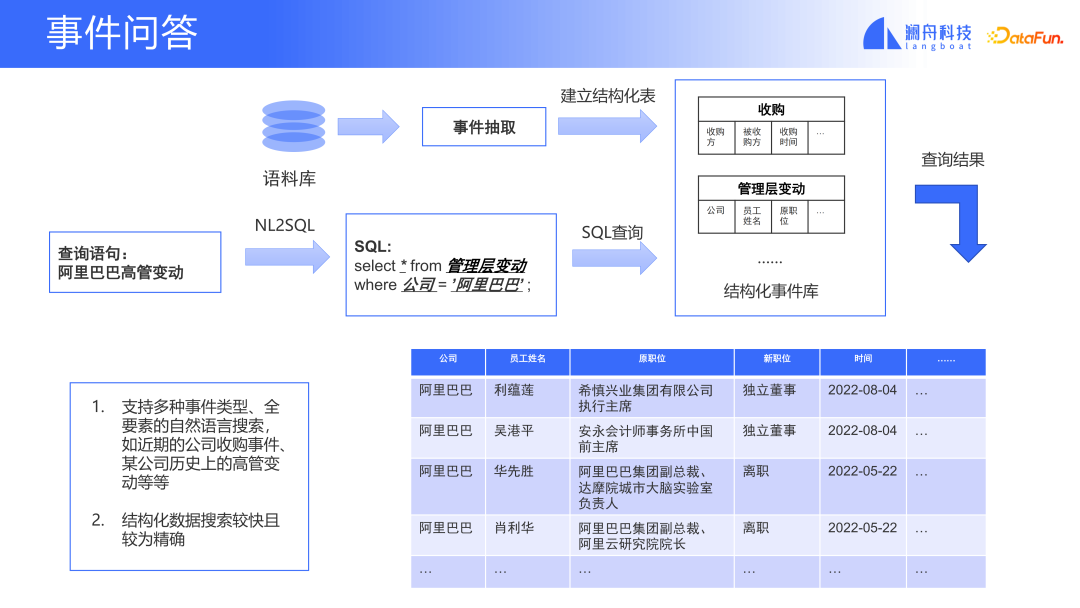
Diese Art von Event-Fragen und -Antworten basierend auf der Event-Bibliothek kann die Suche nach Events in natürlicher Sprache unterstützen. Wir extrahieren zunächst aus dem Korpus und erstellen eine strukturierte Ereignisbibliothek. Jedes Feld in der Tabelle stellt unterschiedliche Ereigniselemente dar. In Kombination mit der NL2SQL-Technologie kann die Abfrageanweisung in eine Datenbankabfrageanweisung umgewandelt werden. Auf diese Weise können wir den genauen Ereignistyp in der soeben erstellten Tabelle finden. Dies unterscheidet sich von der Erfahrung bei der Suche nach Veranstaltungen mit den derzeit auf dem Markt befindlichen allgemeinen Suchmaschinen. Die von der Suchmaschine zurückgegebenen Ergebnisse umfassen viele Arten von Nachrichten zu diesem Veranstaltungstyp. Auch wenn relevante Nachrichten gefunden werden, ist das Ergebnis, das Sie sehen, ein vollständiger Bericht und keine spezifischen Informationen zu einem bestimmten Ereignis. Durch Fragen und Antworten zu Veranstaltungen auf Basis der Veranstaltungsdatenbank können wir Fragen und Antworten für Veranstaltungen präziser durchführen.
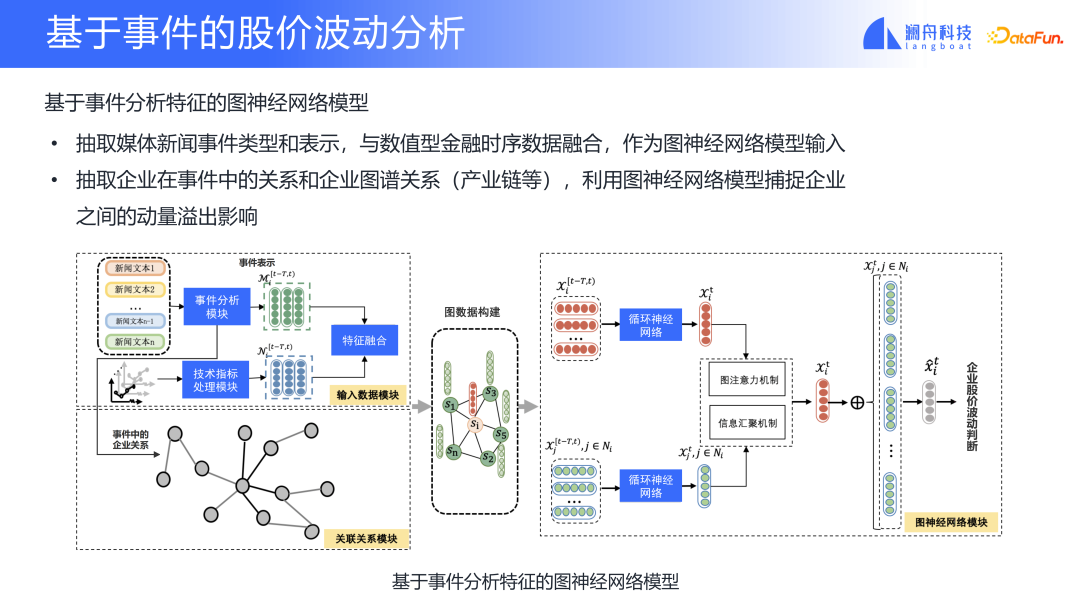
Anhand des obigen Beispiels können Sie sehen, wie eine Ereignisanalyse in bestimmten Szenarien durchgeführt werden kann. Die Schwankungen der Aktienkurse von Unternehmen stehen im Mittelpunkt des Marktes. Ereignisbasierte Aktienkursschwankungen sind auch ein Szenario, in dem NLP und der Finanzbereich in der Ereignisanalyse kombiniert werden, wodurch die Transformation von Marktinformationen und Aktienkursschwankungen realisiert werden kann. Die obige Abbildung zeigt zwei Merkmale im Modell. Ein Typ repräsentiert ein bestimmtes Unternehmen und der andere Typ repräsentiert die Beziehung zwischen Unternehmen. Wir führen eine Ereignisanalyse ein, um Ereignistypen und verschiedene an der Veranstaltung beteiligte Unternehmen zu extrahieren. Die extrahierten Ereignistypen und zwei Arten von Informationen, die das Unternehmen bereitstellen kann, ist die Darstellung des Ereignisses, die zu einem Feature werden und in die Funktionen des Unternehmens integriert werden kann. Die Beziehung zwischen Unternehmen und Ereignissen kann das Assoziationsbeziehungsmodul zwischen Unternehmen bilden. Fügen Sie dann vorhandene Funktionen hinzu, z. B. unternehmensspezifische technische Indikatoren oder Unternehmensbeziehungskarten. Durch die Kombination der beiden können wir ein Diagramm mit Unternehmensinformationen und Beziehungsinformationen erstellen. Basierend auf dieser Grafik verwenden wir das Graph Attention Network, um die Auswirkungen der Beziehung zwischen Unternehmen auf die Aktienkursschwankungsleistung von Unternehmen zu erfassen. Unter Verwendung von Aktienkursschwankungen als Ziel des Modelllernens zum Trainieren des Modells kann die von uns erhaltene Modellnetzwerkstruktur anhand von Funktionen wie der Nachrichtenbranchenkarte und der Unternehmensbeziehungskarte eine Beurteilung der zukünftigen Merkmale des Unternehmens vornehmen. Durch die Analyse des Aufmerksamkeitsmodells können wir auch wissen, von welchen Modulen die Schwankungen hauptsächlich stammen, ob es sich um ein Ereignistypmodul oder ein Ereignisbeziehungsmodul handelt. Und durch die Modellierung der Beziehungen zwischen Unternehmen kann auch analysiert werden, wie sich diese Auswirkungen auf verbundene Unternehmen verteilen. Dies kann auch als Nutzen des Momentum-Spillovers im Finanzbereich bezeichnet werden.
Umfassend die verschiedenen Ereignisanalysetechniken und -szenarien, die wir zuvor vorgestellt haben . Wir haben ein vollständiges Ereignisanalyse-Framework zusammengefasst. (Wie im Bild unten gezeigt)
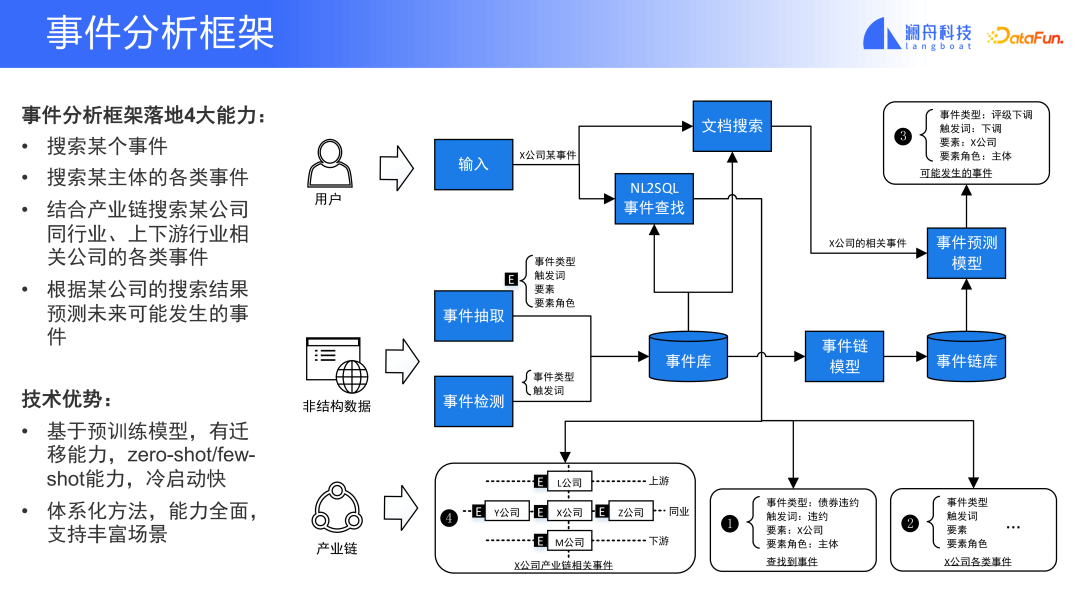
Es bietet mehrere Hauptfunktionen:
① Erstens kann es nach verschiedenen Ereignissen zu einem bestimmten Ereignis oder einem bestimmten Thema suchen.
② Zweitens kann es die Suche nach verschiedenen verwandten Ereignissen eines Unternehmens in derselben Branche über die Industriekette ermöglichen, bei der es sich um eine Industriekette oder eine Unternehmenskette handeln kann.
③ Dieses Framework kann auch mögliche zukünftige Ereignisse basierend auf den Suchergebnissen eines Unternehmens vorhersagen.
Der Vorteil dieses Frameworks besteht darin, dass es auf einem vorab trainierten Modell basiert, die Fähigkeit zur Lernübertragung besitzt, Zero-Shot-/Wenige-Shot-Training unterstützen kann und über einen schnellen Kaltstart verfügt. Darüber hinaus verfügt diese systematische Methode über relativ umfassende Fähigkeiten und kann eine Vielzahl von Szenarien unterstützen.
Nicht alle Szenarien erfordern alle Module im Framework, und die Module können je nach Bedarf getrennt und separat verwendet werden.
2. Technologie zur Analyse von Finanzereignissen
Die beiden wichtigeren Teile der Technologie zur Analyse von Finanzereignissen sind Ereigniserkennung und Ereignisextraktion.

Das Ziel der Ereigniserkennungsaufgabe besteht darin, Ereignisse aus Texten zu extrahieren und zu klassifizieren. Normalerweise werden Triggerwörter zur Ereigniserkennung extrahiert, es gibt jedoch auch einige Methoden zur Ereigniserkennung ohne Extraktion von Triggerwörtern. Die Herausforderung bei dieser Art von Problem besteht in der Kennzeichnung von Triggerwörtern. Wenn Probleme wie semantische Migration, Ereignisaufteilung und Änderungen der Ereignisdefinition auftreten, müssen wir die Daten neu kennzeichnen. Diese Art von Problem tritt häufig in tatsächlichen Szenarien auf. Obwohl wir über unsere eigene Ereigniserkennungslösung verfügen, sind ihre Ereignissysteme sehr unterschiedlich, wenn sie auf verschiedene Bereiche angewendet werden oder auf unterschiedliche Kundenbedürfnisse reagieren. Wie können wir vorhandene Modelle und Daten kombinieren, um das Ereignissystem besser zu unterstützen? . Der aktuelle Ansatz ist die Ereigniserkennung basierend auf Stichworten und vorab trainierten Modellen. Je nach Eingabeaufforderung des Ereignistyps können wir in Szenarien mit wenigen Schüssen eine bessere Datenmigration oder ein Modelltraining durchführen.

Die obige Abbildung zeigt das Modell und die Methode basierend auf Triggerwörtern. Entsprechend der Eingabeaufforderung des Ereignistyps kann die Eingabe des Modells auf Token-Ebene mit Anmerkungen versehen werden, sodass die Auslösewörter der entsprechenden Ereignisse extrahiert werden können. Wenn das Triggerwort basierend auf der aktuellen Eingabeaufforderung transformiert wird, können der entsprechende Ereignistyp und das Triggerwort entsprechend geändert werden. Durch den Datenvergleich öffentlicher Datensätze ist ersichtlich, dass die Leistung unseres Modells im Vergleich zu früheren Methoden bei voller Datenmenge erheblich verbessert wurde. Selbst bei wenigen Schüssen ist die Leistung unseres Modells besser als bei anderen Modellen.
 Die Ereignisextraktionsaufgabe ist eine Erweiterung der Ereigniserkennungsaufgabenfunktion. Es identifiziert nicht nur den Ereignistyp und die Auslösewörter, sondern extrahiert auch die entsprechenden Elemente im Ereignis. Dies wirkt sich stärker auf Szenarien aus, in denen die Ereignisanalyse relativ vollständige Informationen erfordert. Das Beispiel in der Abbildung oben kann detailliertere Informationen extrahieren. Zu den Herausforderungen bei der Ereignisextraktion gehört, dass es in einem vollständigen Ereignissystem viele Ereigniselemente gibt, dass für die Datenanmerkung Domänenexperten erforderlich sind, dass die Kosten relativ hoch sind und es schwierig ist, sie auf viele Ereignistypen zu erweitern. Unsere aktuelle Lösung besteht darin, vorab trainierte Modelle und Eingabeaufforderungen zu verwenden. Die auf
Die Ereignisextraktionsaufgabe ist eine Erweiterung der Ereigniserkennungsaufgabenfunktion. Es identifiziert nicht nur den Ereignistyp und die Auslösewörter, sondern extrahiert auch die entsprechenden Elemente im Ereignis. Dies wirkt sich stärker auf Szenarien aus, in denen die Ereignisanalyse relativ vollständige Informationen erfordert. Das Beispiel in der Abbildung oben kann detailliertere Informationen extrahieren. Zu den Herausforderungen bei der Ereignisextraktion gehört, dass es in einem vollständigen Ereignissystem viele Ereigniselemente gibt, dass für die Datenanmerkung Domänenexperten erforderlich sind, dass die Kosten relativ hoch sind und es schwierig ist, sie auf viele Ereignistypen zu erweitern. Unsere aktuelle Lösung besteht darin, vorab trainierte Modelle und Eingabeaufforderungen zu verwenden. Die auf
basierende generative Methode kann auch in Szenarien mit weniger annotierten Daten eine gute Modellleistung erzielen, bietet eine höhere Datenauslastung und Flexibilität und ist einfacher auf neue Ereignistypen zu erweitern .
 Die Ereignisextraktionsaufgabe ist eine Erweiterung der Ereigniserkennungsaufgabenfunktion. Es identifiziert nicht nur den Ereignistyp und die Auslösewörter, sondern extrahiert auch die entsprechenden Elemente im Ereignis. Dies wirkt sich stärker auf Szenarien aus, in denen die Ereignisanalyse relativ vollständige Informationen erfordert. Das Beispiel in der Abbildung oben kann detailliertere Informationen extrahieren. Zu den Herausforderungen bei der Ereignisextraktion gehört, dass es in einem vollständigen Ereignissystem viele Ereigniselemente gibt, dass für die Datenanmerkung Fachexperten erforderlich sind, dass die Kosten relativ hoch sind und es schwierig ist, sie auf viele Ereignistypen zu erweitern. Unsere aktuelle Lösung besteht darin, vorab trainierte Modelle und Eingabeaufforderungen zu verwenden. Die generative Methode kann auch in Szenarien mit weniger annotierten Daten eine gute Modellleistung erzielen, bietet eine höhere Datenauslastung und Flexibilität und lässt sich leichter auf neue Ereignistypen erweitern.
Die Ereignisextraktionsaufgabe ist eine Erweiterung der Ereigniserkennungsaufgabenfunktion. Es identifiziert nicht nur den Ereignistyp und die Auslösewörter, sondern extrahiert auch die entsprechenden Elemente im Ereignis. Dies wirkt sich stärker auf Szenarien aus, in denen die Ereignisanalyse relativ vollständige Informationen erfordert. Das Beispiel in der Abbildung oben kann detailliertere Informationen extrahieren. Zu den Herausforderungen bei der Ereignisextraktion gehört, dass es in einem vollständigen Ereignissystem viele Ereigniselemente gibt, dass für die Datenanmerkung Fachexperten erforderlich sind, dass die Kosten relativ hoch sind und es schwierig ist, sie auf viele Ereignistypen zu erweitern. Unsere aktuelle Lösung besteht darin, vorab trainierte Modelle und Eingabeaufforderungen zu verwenden. Die generative Methode kann auch in Szenarien mit weniger annotierten Daten eine gute Modellleistung erzielen, bietet eine höhere Datenauslastung und Flexibilität und lässt sich leichter auf neue Ereignistypen erweitern.
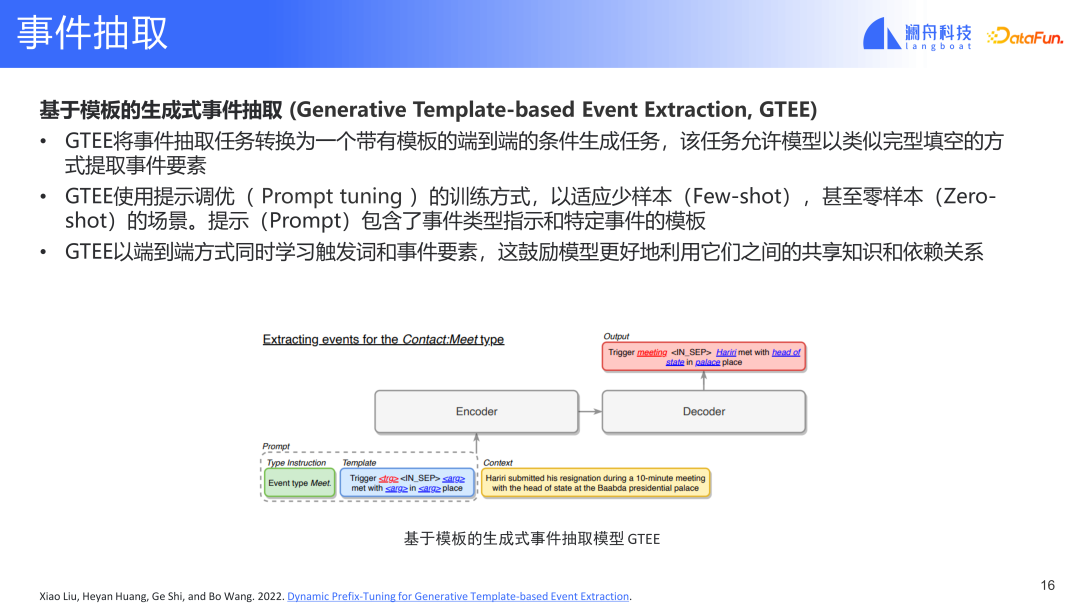
Das Bild oben ist eine vorlagenbasierte Methode zur generativen Ereignisextraktion. Diese Extraktionsmethode definiert mehrere wichtige Konzepte. Zuerst müssen wir die Vorlage vor der Extraktion vordefinieren. Mit der Vorlage können Sie sie beim Definieren eines neuen Ereignisses auch mit früheren Ereignissen in Verbindung bringen im voraus. Auf diese Weise kann das Modell mit einer kleinen Datenmenge neue Ereignistypen lernen.
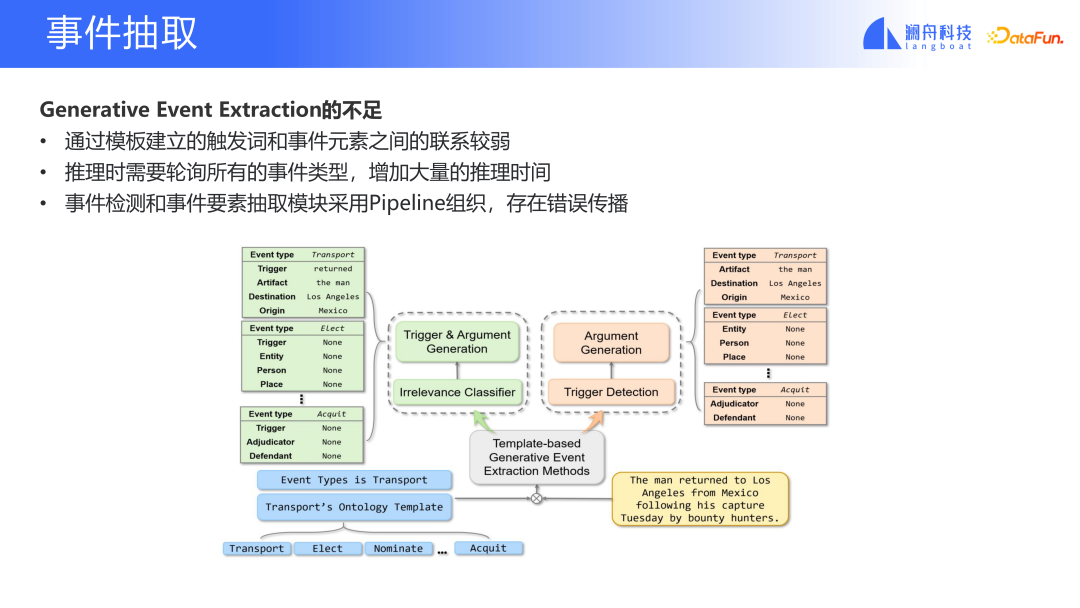
Obwohl die obige Methode das Problem der Ereignisextraktion bis zu einem gewissen Grad lösen kann, gibt es noch viel Raum für Verbesserungen. Beispielsweise ist die Verbindung zwischen Triggerwörtern und Ereigniselementen der aktuellen Methode schwach; alle Ereignistypen müssen während der Inferenz abgefragt werden, was einen großen Rechenaufwand und eine lange Inferenzzeit für die Organisation der Ereigniserkennungs- und Ereigniselementextraktionsmodule erfordert durch Pipeline, was zur Fehlerausbreitung führt.
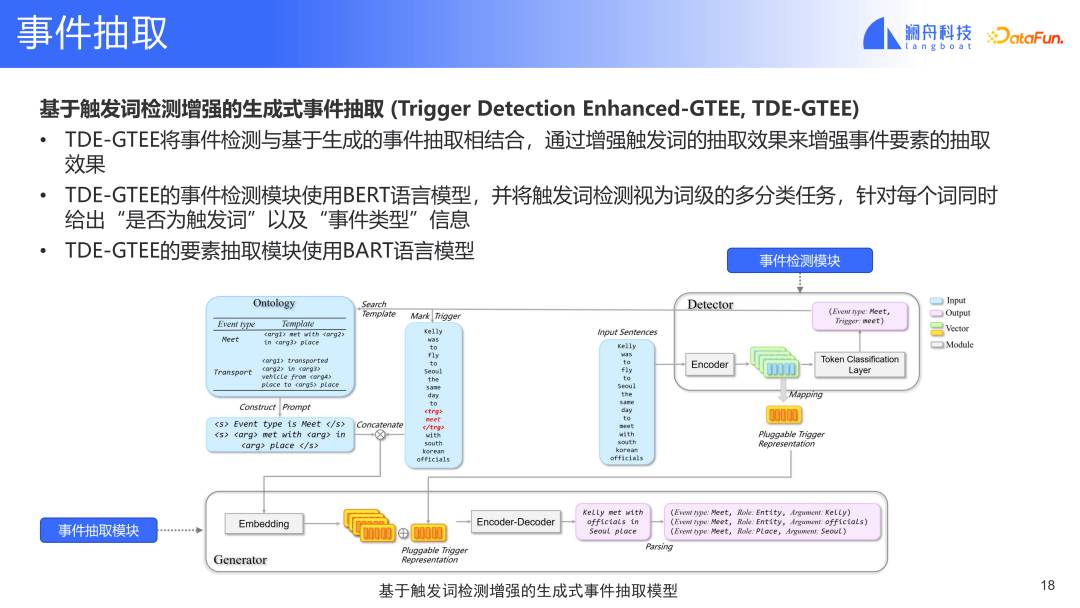
Wir haben das Modell basierend auf den oben gestellten Fragen verbessert und eine weitere Methode zur generativen Ereignisextraktion vorgeschlagen, die auf der Verbesserung der Triggerworterkennung basiert TDE-GTEE.
(Ge Shi, Yunyue Su, Yongliang Ma und Ming Zhou (2023). Ein hybrides Erkennungs- und Generierungs-Framework mit separaten Encodern für die Ereignisextraktion. In Tagungsband der 17. Konferenz des Europäischen Kapitels der Association for Computational Linguistik: Hauptband. Gesellschaft für Computerlinguistik.)
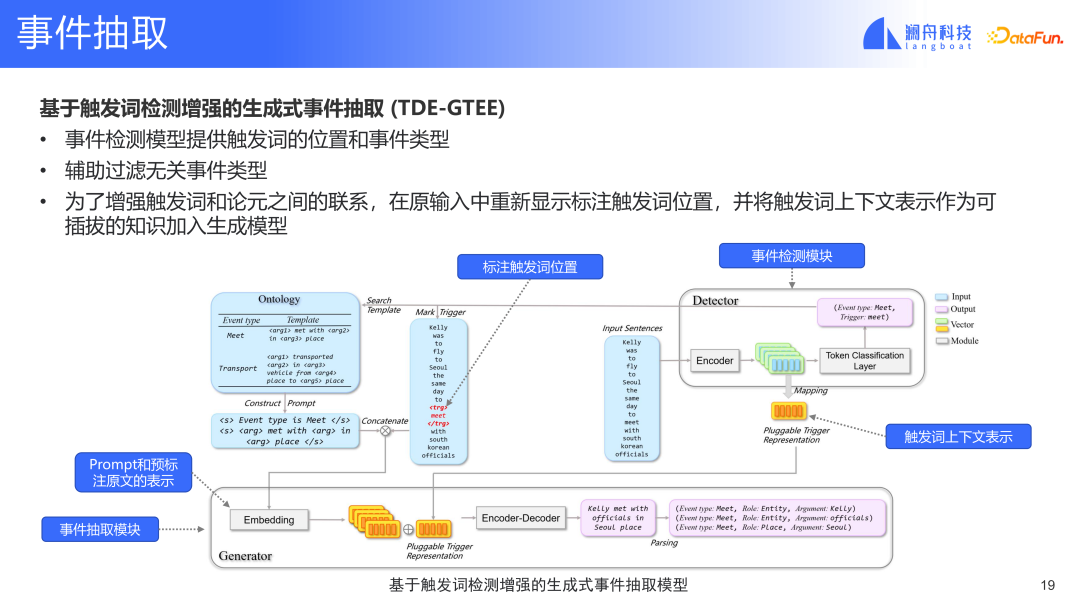
Bei dieser Methode stellt das Ereigniserkennungsmodul Informationen über Ereignisauslöserwörter bereit. Wir markieren die Auslösewörter in der Eingabe und wählen die entsprechende Vorlage basierend auf den Informationen zum Ereignistyp aus. Diese Eingabe und Ereignisvorlage werden später kombiniert, um die Darstellung des Ereigniserkennungsmoduls zu bilden. Diese Darstellung wird in das Themenmodell eingespeist und schließlich wird die gefüllte Vorlage erhalten. Der Unterschied zwischen diesem Modell und dem Vorgängermodell besteht darin, dass dieses Modell über eine zusätzliche Triggerwortdarstellung verfügt und auch Kontextinformationen kombiniert. Dies löst das erste gerade erwähnte Problem, nämlich das Problem, dass es nicht viele Verbindungen zwischen Triggerwörtern und Triggerwort-Extraktionselementen gibt. Dieses Modell kann die Anzeigebeziehung zwischen den beiden konstruieren. Gleichzeitig können wir durch die Eingabe des Triggerworts den Ereignistyp kennen, der sich auf das Triggerwort bezieht. Auf diese Weise können wir irrelevante Ereignistypen herausfiltern. Das Ereigniserkennungsmodul extrahiert nur Ereignisse für relevante Ereignistypen. Schließlich können das Ereigniserkennungsmodul und das Ereignisextraktionsmodul ein durchgängiges gemeinsames Training bilden. Dieses Modell kann die beiden anderen oben genannten Probleme lösen.
Das TDE-GTEE-Modell hat in den beiden öffentlichen Datensätzen ACE und ERE das SOTA-Niveau erreicht. In den Experimenten haben wir die gesamte Datenmenge genutzt. Um die Leistung dieses Modells anhand einer kleinen Anzahl von Stichproben zu überprüfen, haben wir auch einige Anpassungen am Ereigniserkennungsmodul vorgenommen, z. B. das Ersetzen der ursprünglichen Mehrfachklassifizierungsmethode durch eine auf Eingabeaufforderungen basierende Methode. Auch bei Zero-Shot/Few-Shot können Modelle gute Ergebnisse erzielen. Wir glauben, dass dieses Modell in praktischen Szenarien weit verbreitet sein kann.
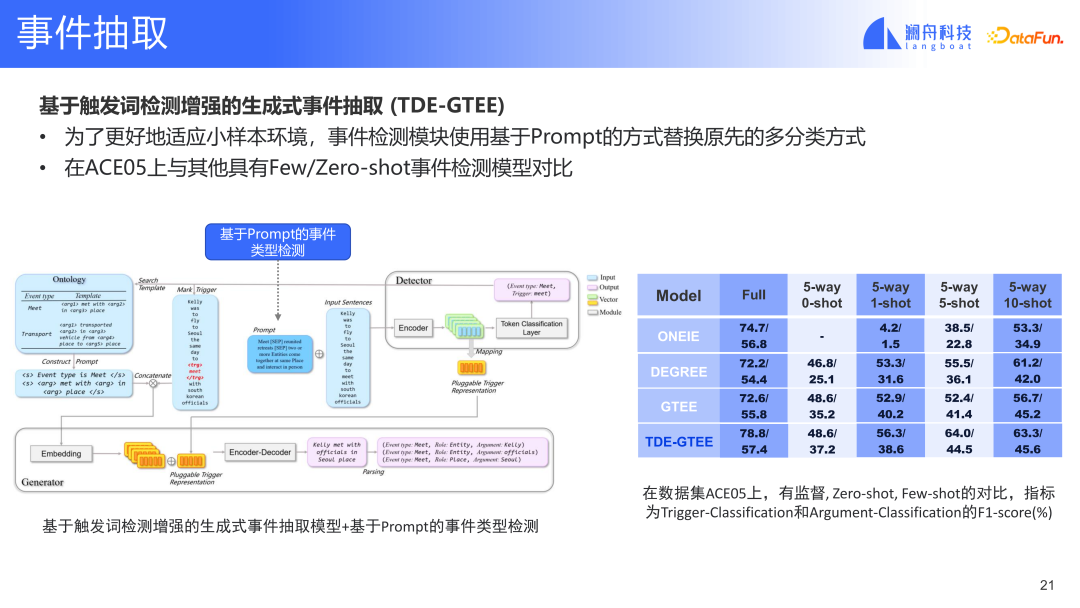
3. Zusammenfassung und Ausblick
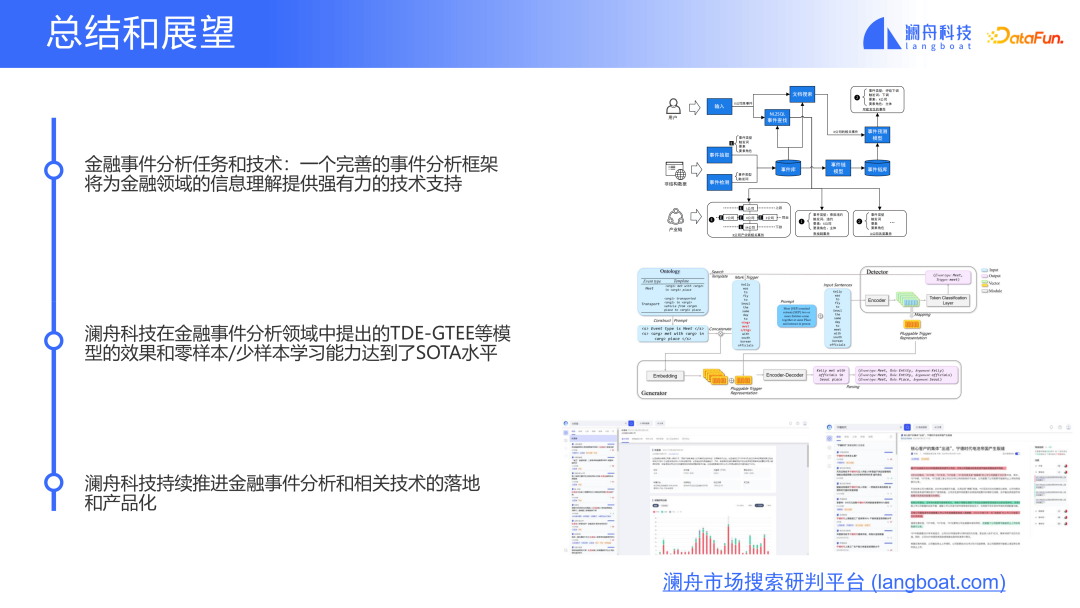
Ereignisanalysetechnologie ist im Finanzbereich weit verbreitet und es gibt viele Szenarien. Ein umfassendes System-Framework zur Ereignisanalyse wird eine starke technische Unterstützung für das Informationsverständnis im Finanzbereich bieten.
TDE-GTEE und andere von Lanzhou Technology im Bereich der Finanzereignisanalyse vorgeschlagene Methoden können das SOTA-Niveau erreichen und in Szenarien mit wenigen Stichproben und Nullstichproben eine gute Leistung erbringen. Wir werden den technologischen Fortschritt und die Produktisierung im Bereich der Finanzereignisanalyse weiterhin vorantreiben.
IV. Frage- und Antwortsitzung
F1: Gibt es eine Datenbank speziell für Ereignisdiagramme wie Neo4j, die zum Speichern und Verwalten von Ereignisdiagrammen geeignet ist?
A1: Es gibt eine Datenbank speziell für Ereignisdiagramme. Einige Datenanbieter stellen solche Datenbanken zur Verfügung. Beispielsweise werden Unternehmen wie Lanzhou Technology und Ant Group auch eigene Datenbanken innerhalb ihrer Unternehmen aufbauen. Mit Neo4j können Ereignisdiagramme gespeichert und verwaltet werden. Abhängig vom Nutzungsszenario eignet sich Neo4j besser für die Speicherung und Verwaltung in komplexen Szenarien. Bei einer Vereinfachung in eine Ereigniskette kann die Darstellung von Ereignissen flexibler sein. Wir extrahieren die Daten aus dem Text, um eine Ereigniskette als Trainingsdaten für das Modell zu generieren. Beim Training ist keine Diagrammoperation erforderlich.
F2: Wie lässt sich die Wirkung der Bestandsschwankungsanalyse bewerten?
A2: Es gibt zwei Hauptwege. Bei der Konstruktion und Bewertung spezifischer Modelle stützen wir uns stärker auf Informationen aus der Börse. Es kann als Backtesting im quantitativen Handel verstanden werden. Wir verwenden historische Daten für Training und Bewertung. Das andere ist, dass wir in realen Szenarien manuelle Beurteilungen vornehmen, wie etwa die Vorhersage von Aktienkursschwankungen im nächsten Monat auf der Grundlage von Unternehmensnachrichten und technischen Indikatoren für Aktienvolumen und Preishandel. Wir werden konkret prüfen, ob es in diesem Monat tatsächlich zu Kursschwankungen bei den Aktien kommt. Wenn Schwankungen auftreten, werden der entsprechende Ereignistyp, das entsprechende Aktienkursvolumen und Preisinformationen sowie andere Elemente analysiert, um festzustellen, ob ein starker Kausalzusammenhang besteht.
Das obige ist der detaillierte Inhalt vonAnalyse und Anwendung von Finanzereignissen basierend auf vorab trainierten Modellen. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Technologietrends, die Sie im Jahr 2023 im Auge behalten sollten
- Wie künstliche Intelligenz Rechenzentrumsteams neue Alltagsaufgaben beschert
- Können künstliche Intelligenz oder Automatisierung das Problem der geringen Energieeffizienz in Gebäuden lösen?
- OpenAI-Mitbegründer im Interview mit Huang Renxun: Die Argumentationsfähigkeiten von GPT-4 haben noch nicht die Erwartungen erfüllt
- Dank der OpenAI-Technologie übertrifft Bing von Microsoft Google im Suchverkehr