
Heim >Technologie-Peripheriegeräte >KI >Das iPhone produziert Bilder in zwei Sekunden. Das schnellste bekannte mobile Stable Diffusion-Modell ist da.
Das iPhone produziert Bilder in zwei Sekunden. Das schnellste bekannte mobile Stable Diffusion-Modell ist da.

- 王林nach vorne
- 2023-06-12 11:15:481434Durchsuche
Stable Diffusion (SD) ist derzeit das beliebteste Diffusionsmodell für die Text-zu-Bild-Generierung. Obwohl seine leistungsstarken Bilderzeugungsfunktionen schockierend sind, besteht ein offensichtliches Manko darin, dass es enorme Rechenressourcen erfordert und die Inferenzgeschwindigkeit sehr langsam ist: Am Beispiel von SD-v1.5 beträgt die Modellgröße selbst bei Verwendung von Speicher mit halber Genauigkeit 1,7 GB Bei 1 Milliarde Parametern beträgt die Inferenzzeit auf dem Gerät oft fast 2 Minuten.
Um das Problem der Inferenzgeschwindigkeit zu lösen, haben Wissenschaft und Industrie mit der Forschung zur SD-Beschleunigung begonnen und sich dabei hauptsächlich auf zwei Routen konzentriert: (1) Reduzieren Sie die Anzahl der Inferenzschritte. Diese Route kann in zwei Unterrouten unterteilt werden . Die eine besteht darin, die Anzahl der Schritte zu reduzieren, indem ein besserer Rauschplaner vorgeschlagen wird. Die repräsentativen Arbeiten sind DDIM [1], PNDM [2], DPM [3] usw.; Progressive Destillation), die repräsentative Arbeit ist Progressive Destillation [4] und W-Konditionierung [5] usw. (2) Die Optimierung der technischen Fähigkeiten besteht darin, dass Qualcomm int8-Quantisierung + Full-Stack-Optimierung verwendet, um SD-v1.5 auf Android-Telefonen in 15 Sekunden zu erreichen [6]. .4 auf Samsung-Handys. Beschleunigung auf 12 s [7].
Obwohl diese Bemühungen weit fortgeschritten sind, geht es immer noch nicht schnell genug.
Kürzlich hat das Snap Research Institute das neueste leistungsstarke Stable Diffusion-Modell auf den Markt gebracht. Durch umfassende Optimierung der Netzwerkstruktur, des Trainingsprozesses und der Verlustfunktion kann es eine Bildwiedergabe von 2 Sekunden (512 x 512) auf dem iPhone 14 Pro erreichen. und ist schneller als SD-v1.5 und erzielt einen besseren CLIP-Score. Dies ist das schnellste bekannte durchgängige stabile Diffusionsmodell!

- Papieradresse: https://arxiv.org/pdf/2306.00980.pdf
- Webseite: https://snap-research.github.io/SnapFusion
Kernmethode
Das stabile Diffusionsmodell ist in drei Teile unterteilt: VAE-Encoder/Decoder, Text-Encoder, UNet, wobei UNet in Bezug auf Parametermenge und Berechnungsmenge die absolute Mehrheit ausmacht, sodass SnapFusion hauptsächlich UNet optimiert. Es ist in zwei Teile gegliedert: (1) Optimierung der UNet-Struktur: Durch die Analyse des Geschwindigkeitsengpasses des ursprünglichen UNet schlägt dieser Artikel eine Reihe automatischer Bewertungs- und Evolutionsprozesse für die UNet-Struktur vor und erhält eine effizientere UNet-Struktur (genannt Effizientes UNet). (2) Optimierung der Anzahl der Inferenzschritte: Wie wir alle wissen, ist das Diffusionsmodell ein iterativer Entrauschungsprozess während der Inferenz. Je mehr Iterationsschritte, desto höher ist die Qualität der generierten Bilder, aber auch der Zeitaufwand steigt linear mit Anzahl der Iterationsschritte. Um die Anzahl der Schritte zu reduzieren und die Bildqualität aufrechtzuerhalten, schlagen wir eine CFG-bewusste Destillationsverlustfunktion vor, die die Rolle von CFG (Classifier-Free Guidance) während des Trainingsprozesses explizit berücksichtigt Verbesserung des CLIP-Scores!
Die folgende Tabelle ist ein Übersichtsvergleich zwischen SD-v1.5- und SnapFusion-Modellen. Es ist ersichtlich, dass die Geschwindigkeitsverbesserung von den beiden Teilen UNet- und VAE-Decoder herrührt, wobei der UNet-Teil der größte ist. Die Verbesserung des UNet-Teils umfasst zwei Aspekte: Der eine ist die Reduzierung der Einzellatenz (1700 ms -> 230 ms, 7,4-fache Beschleunigung), der andere ist die Reduzierung der Inferenzschritte ( 50 -> 8, 6,25 x Beschleunigung), die durch die vorgeschlagene CFG-bewusste Destillation erhalten wird. Der VAE-Decoder wird durch strukturiertes Bereinigen beschleunigt.

Das Folgende konzentriert sich auf das Design von Efficient UNet und das Design der CFG-bewussten Destillationsverlustfunktion.
(1) Effizientes UNet
Durch die Analyse der Cross-Attention- und ResNet-Module in UNet haben wir festgestellt, dass der Geschwindigkeitsengpass im Cross-Attention-Modul liegt (insbesondere im Cross-Attention im ersten Downsample). Stufe). Die Hauptursache für dieses Problem besteht darin, dass die Komplexität des Aufmerksamkeitsmoduls in einem quadratischen Zusammenhang mit der räumlichen Größe der Feature-Map steht. In der ersten Downsample-Stufe ist die räumliche Größe der Feature-Map immer noch groß, was zu einer hohen Rechenkomplexität führt.
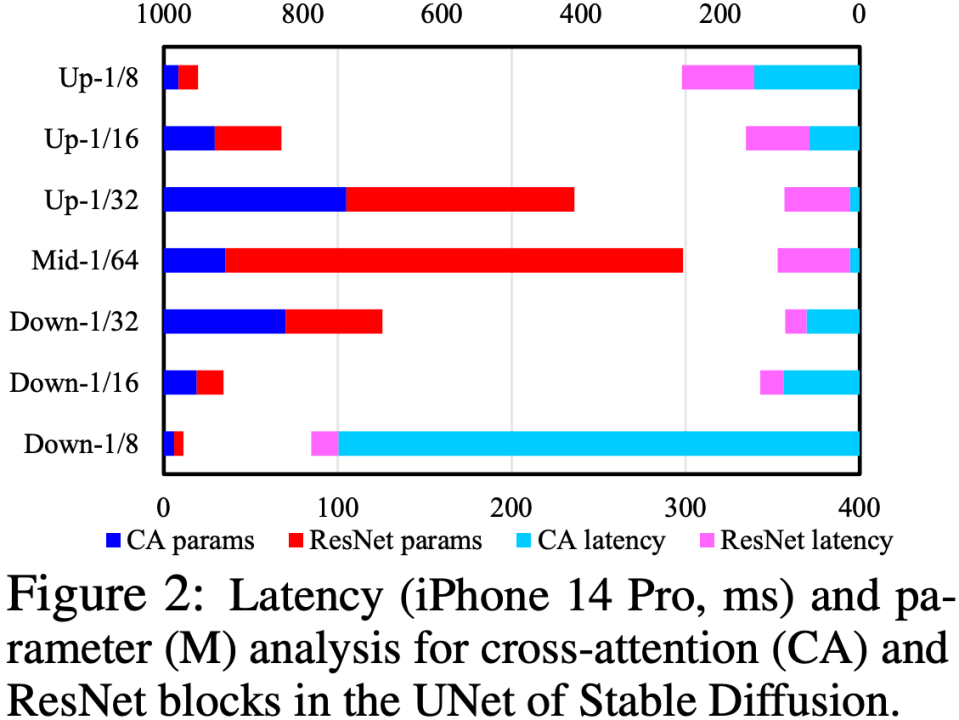
Um die UNet-Struktur zu optimieren, schlagen wir eine Reihe automatischer Bewertungs- und Weiterentwicklungsprozesse für die UNet-Struktur vor: Führen Sie zunächst ein robustes Training (Robust Training) auf UNet durch und lassen Sie während des Trainings zufällig einige Module fallen, um die Leistung jedes Moduls zu testen Die tatsächliche Auswirkung auf den CLIP-Score wird erstellt, um eine Nachschlagetabelle „Auswirkung auf den CLIP-Score vs. Latenz“ zu erstellen. Anschließend werden auf der Grundlage der Nachschlagetabelle zuerst Module entfernt, die nur geringe Auswirkungen auf den CLIP-Score haben und sehr zeitaufwändig sind. Diese Reihe von Prozessen wird automatisch online ausgeführt. Nach Abschluss erhalten wir eine brandneue UNet-Struktur namens Efficient UNet. Im Vergleich zum ursprünglichen UNet erreicht es eine 7,4-fache Beschleunigung ohne Leistungseinbußen.
(2) CFG-bewusste Stufendestillation
CFG (Classifier-Free Guidance) ist eine wesentliche Fähigkeit in der SD-Inferenzphase. Sie kann die Bildqualität erheblich verbessern, was sehr wichtig ist! Obwohl es Arbeiten zum Diffusionsmodell gab, bei denen die Stufendestillation zur Beschleunigung verwendet wurde [4], wurde CFG nicht als Optimierungsziel in das Destillationstraining einbezogen. Das heißt, die Destillationsverlustfunktion weiß nicht, dass CFG später verwendet wird. Nach unserer Beobachtung wird dies den CLIP-Score erheblich beeinträchtigen, wenn die Anzahl der Schritte gering ist.
Um dieses Problem zu lösen, schlagen wir vor, sowohl das Lehrer- als auch das Schülermodell CFG durchführen zu lassen, bevor die Destillationsverlustfunktion berechnet wird, sodass die Verlustfunktion anhand der Merkmale nach CFG berechnet wird und somit der Einfluss unterschiedlicher CFG-Skalen explizit berücksichtigt wird . Im Experiment haben wir herausgefunden, dass zwar der CLIP-Score durch die vollständige Verwendung der CFG-bewussten Destillation verbessert werden kann, der FID jedoch auch deutlich schlechter wird. Anschließend schlugen wir ein Zufallsstichprobenschema vor, um die ursprüngliche Stufendestillationsverlustfunktion und die CFG-bewusste Destillationsverlustfunktion zu mischen und so die Koexistenz der Vorteile beider zu erreichen, was nicht nur den CLIP-Score deutlich verbesserte, sondern auch den FID nicht verschlechterte . Durch diesen Schritt wird in der weiteren Inferenzstufe eine Beschleunigung um das 6,25-fache erreicht, wodurch eine Gesamtbeschleunigung von etwa dem 46-fachen erreicht wird.
Zusätzlich zu den beiden oben genannten Hauptbeiträgen enthält der Artikel auch die Bereinigungsbeschleunigung des VAE-Decoders und die sorgfältige Gestaltung des Destillationsprozesses. Einzelheiten zum spezifischen Inhalt finden Sie im Artikel.
Experimentelle Ergebnisse
SnapFusion testet die Text-zu-Bild-Funktion von SD-v1.5. Das Ziel besteht darin, die Inferenzzeit deutlich zu verkürzen und die Bildqualität beizubehalten:
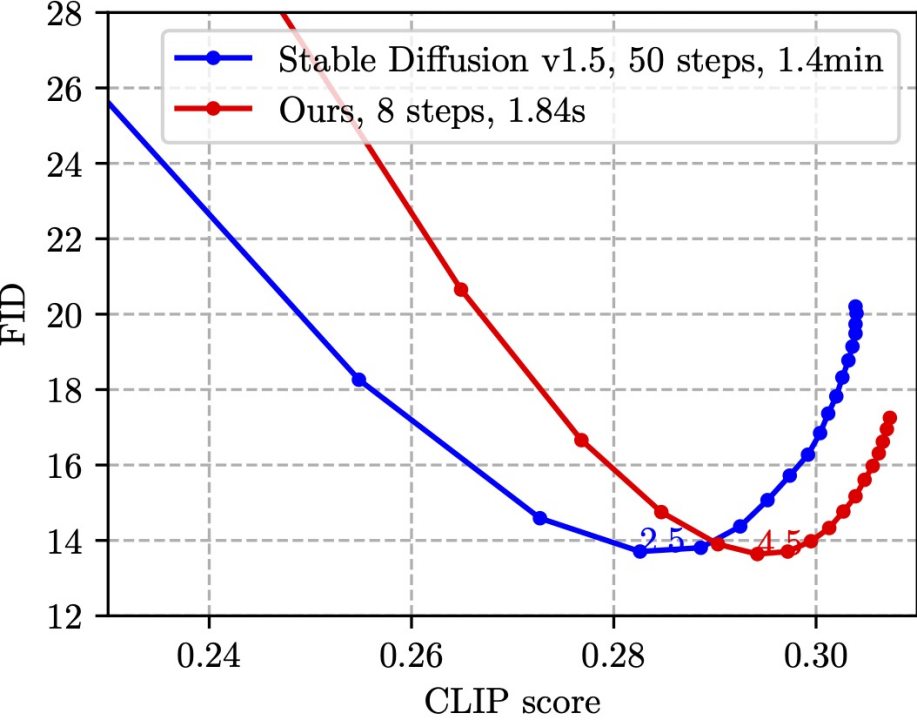
Diese Zahl basiert auf der zufälligen Auswahl von 30.000 Untertitel-Bild-Paaren im MS COCO'14-Verifizierungssatz zur Messung des CLIP-Scores und der FID. Der CLIP-Score misst die semantische Konsistenz zwischen Bildern und Text. Je größer, desto besser. FID misst den Verteilungsabstand zwischen generierten Bildern und realen Bildern (im Allgemeinen als Maß für die Vielfalt generierter Bilder betrachtet). Je kleiner, desto besser. Verschiedene Punkte im Diagramm werden mithilfe unterschiedlicher CFG-Skalen ermittelt, und jede CFG-Skala entspricht einem Datenpunkt. Wie aus der Abbildung ersichtlich ist, kann unsere Methode (rote Linie) den gleichen niedrigsten FID wie SD-v1.5 (blaue Linie) erreichen und gleichzeitig ist der CLIP-Score unserer Methode besser. Es ist erwähnenswert, dass SD-v1.5 1,4 Minuten benötigt, um ein Bild zu erzeugen, während SnapFusion nur 1,84 Sekunden benötigt. Dies ist auch das schnellste mobile Stable Diffusion-Modell, das wir kennen!
Hier sind einige von SnapFusion generierte Beispiele:

Weitere Beispiele finden Sie im Anhang des Artikels.
Zusätzlich zu diesen Hauptergebnissen zeigt der Artikel auch zahlreiche Experimente zur Ablationsanalyse (Ablationsstudie) und hofft, Referenzerfahrungen für die Entwicklung effizienter SD-Modelle zu liefern:
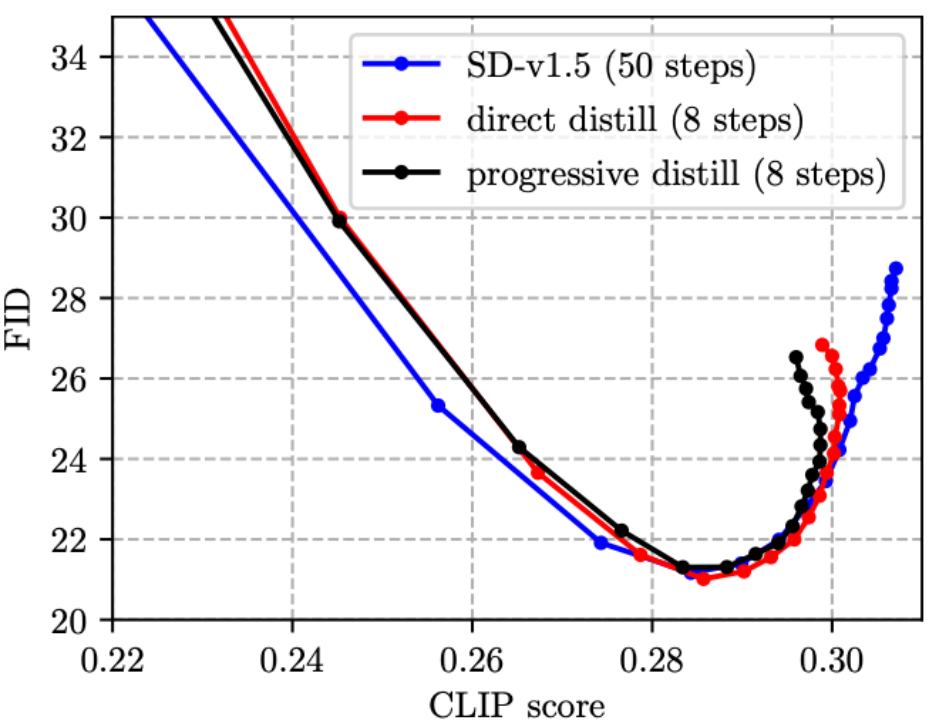
(1) Normalerweise frühere Arbeiten zur Stufendestillation verwendeten ein schrittweises Formelschema [4, 5], aber wir stellten fest, dass die progressive Destillation keine Vorteile gegenüber der direkten Destillation nach dem SD-Modell hat und der Prozess umständlich ist, weshalb wir in diesem Artikel das direkte Destillationsschema übernehmen.
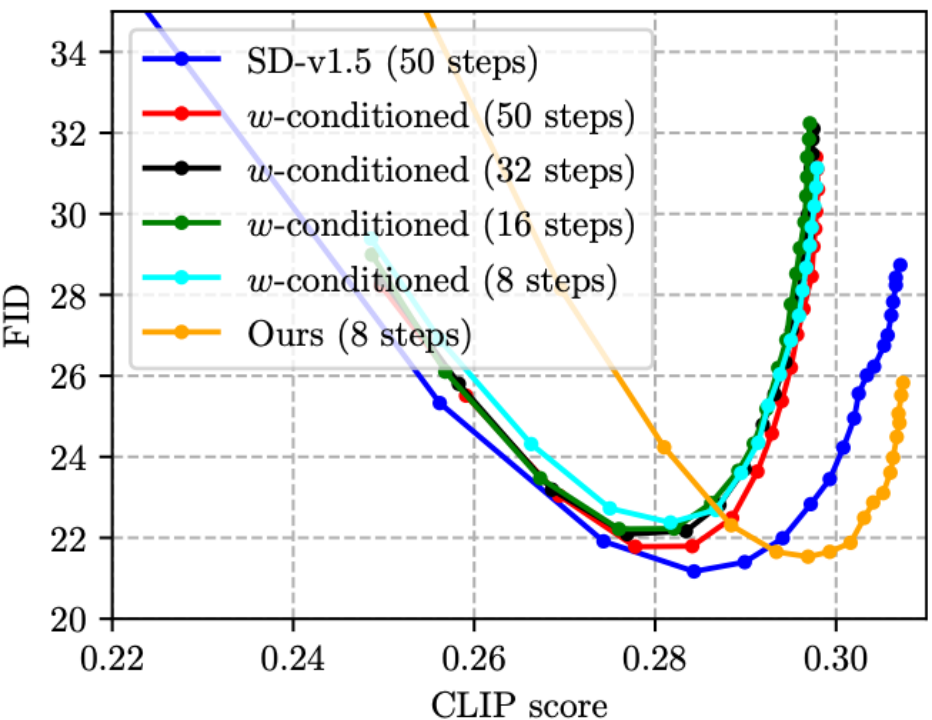
(2) Obwohl CFG die Bildqualität erheblich verbessern kann, verdoppelt der Preis die Inferenzkosten. Im diesjährigen CVPR'23 Award Candidate's On Distillation-Artikel [5] wurde eine W-Konditionierung vorgeschlagen, die CFG-Parameter als Eingabe für UNet für die Destillation verwendet (das resultierende Modell wird als w-konditioniertes UNet bezeichnet), wodurch der CFG-Schritt während des Denkens und Realisierens des Denkens eliminiert wird Kosten halbiert. Wir haben jedoch festgestellt, dass dies tatsächlich dazu führt, dass die Bildqualität abnimmt und der CLIP-Score abnimmt (wie in der folgenden Abbildung gezeigt, überschreitet der CLIP-Score der vier w-konditionierten Linien nicht 0,30, was schlechter ist als der SD- v1.5). Dank der vorgeschlagenen CFG-bewussten Destillationsverlustfunktion kann unsere Methode die Anzahl der Schritte reduzieren und gleichzeitig den CLIP-Score verbessern! Besonders hervorzuheben ist, dass die Inferenzkosten der grünen Linie (w-bedingt, 16 Schritte) und der orangen Linie (unsere, 8 Schritte) in der folgenden Abbildung gleich sind, die orange Linie jedoch offensichtlich besser ist, was darauf hinweist, dass unsere Die technische Route ist besser als die w-konditionierte Konditionierung [5] und ist beim destillierten CFG-geführten SD-Modell effektiver.
(3) Die bestehende Arbeit der Stufendestillation [4, 5] fügt die ursprüngliche Verlustfunktion und die Destillationsverlustfunktion nicht zusammen. Freunde, die mit der Bildklassifizierungswissensdestillation vertraut sind, sollten dies wissen Das Design ist intuitiv suboptimal. Daher haben wir vorgeschlagen, dem Training die ursprüngliche Verlustfunktion hinzuzufügen, wie in der folgenden Abbildung gezeigt, was tatsächlich effektiv ist (die FID leicht reduzieren).
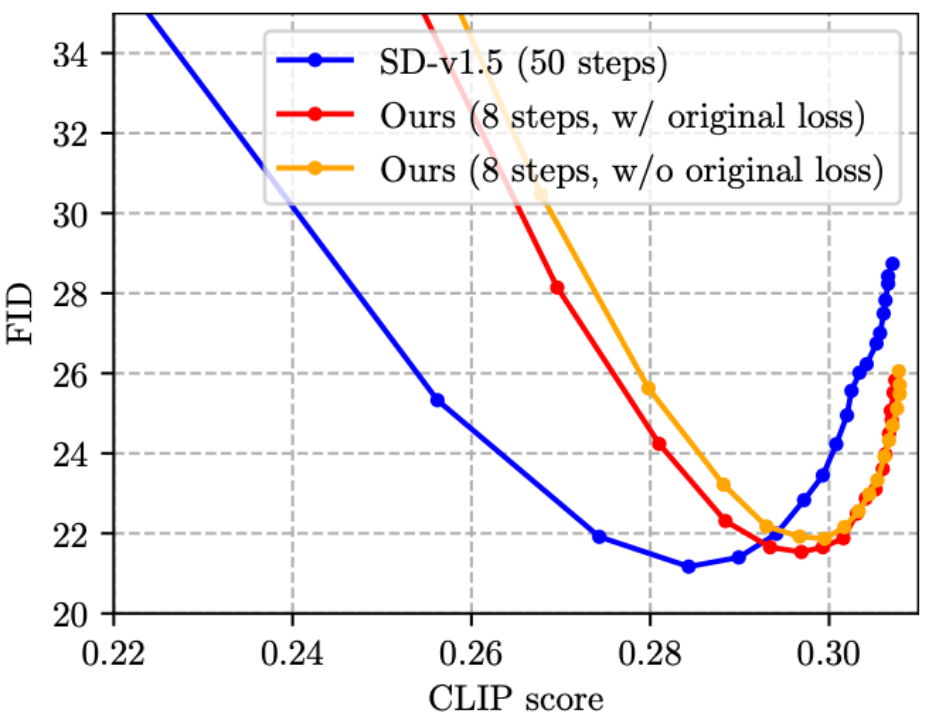
Zusammenfassung und zukünftige Arbeit
Dieses Papier schlägt SnapFusion vor, ein leistungsstarkes stabiles Diffusionsmodell für mobile Endgeräte. SnapFusion hat zwei Kernbeiträge: (1) Durch schichtweise Analyse des vorhandenen UNet wird der Geschwindigkeitsengpass lokalisiert und eine neue effiziente UNet-Struktur (Efficient UNet) vorgeschlagen, die das UNet in der ursprünglichen stabilen Diffusion gleichwertig ersetzen kann Erzielen Sie eine 7,4-fache Beschleunigung. (2) Optimieren Sie die Anzahl der Iterationsschritte in der Inferenzphase und schlagen Sie ein neues Stufendestillationsschema (CFG-bewusste Stufendestillation) vor, das den CLIP-Score erheblich verbessern und gleichzeitig die Anzahl der Schritte reduzieren kann, wodurch 6,25x erreicht werden Beschleunigung. Insgesamt erreicht SnapFusion eine Bildausgabe innerhalb von 2 Sekunden auf dem iPhone 14 Pro, dem derzeit schnellsten bekannten mobilen Stable Diffusion-Modell.
Zukünftige Arbeit:
1. Dieser Artikel ist zeitlich begrenzt und konzentriert sich derzeit nur auf die Kernaufgabe Text-zu-Bild wird später befolgt (z. B. Inpainting, ControlNet usw.).
2. Dieser Artikel konzentriert sich hauptsächlich auf die Geschwindigkeitsverbesserung und nicht auf die Optimierung der Modellspeicherung. Wir glauben, dass das vorgeschlagene Efficient UNet noch Raum für Komprimierung bietet. In Kombination mit anderen leistungsstarken Optimierungsmethoden (wie Beschneiden, Quantisierung) wird erwartet, dass es den Speicher verkleinert und die Zeit auf weniger als 1 Sekunde verkürzt, wodurch Echtzeit-SD ermöglicht wird am Off-End noch einen Schritt weiter.
Das obige ist der detaillierte Inhalt vonDas iPhone produziert Bilder in zwei Sekunden. Das schnellste bekannte mobile Stable Diffusion-Modell ist da.. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Technologietrends, die Sie im Jahr 2023 im Auge behalten sollten
- Wie künstliche Intelligenz Rechenzentrumsteams neue Alltagsaufgaben beschert
- Können künstliche Intelligenz oder Automatisierung das Problem der geringen Energieeffizienz in Gebäuden lösen?
- OpenAI-Mitbegründer im Interview mit Huang Renxun: Die Argumentationsfähigkeiten von GPT-4 haben noch nicht die Erwartungen erfüllt
- Dank der OpenAI-Technologie übertrifft Bing von Microsoft Google im Suchverkehr