
Heim >Technologie-Peripheriegeräte >KI >Entmystifizierung einiger der KI-basierten Techniken zur Sprachverbesserung, die bei Echtzeitanrufen verwendet werden
Entmystifizierung einiger der KI-basierten Techniken zur Sprachverbesserung, die bei Echtzeitanrufen verwendet werden

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBnach vorne
- 2023-06-10 08:58:231488Durchsuche

Hintergrundeinführung
Nachdem Echtzeit-Audio- und Videokommunikation RTC zu einer unverzichtbaren Infrastruktur im Leben und Arbeiten der Menschen geworden ist, entwickeln sich auch die verschiedenen beteiligten Technologien ständig weiter, um komplexe Probleme mit mehreren Szenen wie Audioszenen zu bewältigen um Benutzern in Szenarien mit mehreren Geräten, mehreren Personen und mehreren Geräuschen ein klares und echtes Hörerlebnis zu bieten.
Als führende internationale Konferenz im Bereich der Sprachsignalverarbeitungsforschung repräsentiert die ICASSP (International Conference on Acoustics, Speech and Signal Processing) seit jeher die modernste Forschungsrichtung im Bereich der Akustik. ICASSP 2023 hat eine Reihe von Artikeln zu Audiosignal-Sprachverbesserungsalgorithmen aufgenommen, darunter „Volcano Engine“ und „RTC“. sprecherspezifische Sprachverbesserung, Echounterdrückung, Mehrkanal-Sprachverbesserung, Thema zur Reparatur der Klangqualität . In diesem Artikel werden die wichtigsten Szenenprobleme und technischen Lösungen vorgestellt, die in diesen vier Artikeln gelöst werden, und die Denkweise und Praxis des RTC-Audioteams von Volcano Engine in den Bereichen Sprachrauschunterdrückung, Echounterdrückung und Beseitigung von Interferenzen mit menschlicher Stimme vorgestellt. „Lautsprecherspezifische Verbesserung basierend auf einem wiederkehrenden neuronalen Netzwerk mit Bandsegmentierung“Papieradresse:
https://www.php.cn/link/73740ea85c4ec25f00f9acbd859f861d
Sprecherspezifisch in Echtzeit Stimme Es gibt viele Probleme, die im Rahmen der Verbesserungsmission angegangen werden müssen. Erstens erhöht die Erfassung der gesamten Frequenzbandbreite des Schalls die Verarbeitungsschwierigkeit des Modells. Zweitens ist es für Modelle in Echtzeitszenarien im Vergleich zu Nicht-Echtzeitszenarien schwieriger, den Zielsprecher zu lokalisieren. Wie die Informationsinteraktion zwischen dem Sprechereinbettungsvektor und dem Sprachverbesserungsmodell verbessert werden kann, ist in Echtzeit eine Schwierigkeit. Zeitverarbeitung. Inspiriert von der menschlichen Höraufmerksamkeit schlägt Volcano Engine ein Speaker Attentive Module (SAM) vor, das Sprecherinformationen einführt und diese mit einer Fusion aus einem einkanaligen Sprachverbesserungsmodell und einem wiederkehrenden neuronalen Netzwerk mit Bandsegmentierung (Band-Split Recurrent Neural Network, BSRNN) kombiniert. Erstellen Sie ein spezifisches System zur Verbesserung der menschlichen Sprache als Nachbearbeitungsmodul des Echounterdrückungsmodells und optimieren Sie die Kaskade der beiden Modelle.
Modell-Framework-StrukturBand-Split Recurrent Neural Network (BSRNN)
Band-Split-RNN (BSRNN) ist ein SOTA-Modell zur Vollband-Sprachverbesserung und Musiktrennung. Seine Struktur ist wie in der Abbildung dargestellt oben anzeigen. BSRNN besteht aus drei Modulen, nämlich dem Band-Split-Modul, dem Band- und Sequenzmodellierungsmodul und dem Band-Merge-Modul. Das Frequenzbandsegmentierungsmodul unterteilt das Spektrum zunächst in K Frequenzbänder. Nachdem die Merkmale jedes Frequenzbands stapelweise normalisiert (BN) sind, werden sie durch K vollständig verbundene Schichten (FC) auf die gleiche Merkmalsdimension C komprimiert. Anschließend werden die Merkmale aller Frequenzbänder zu einem dreidimensionalen Tensor verkettet und vom Modul zur Modellierung der Frequenzbandsequenz weiterverarbeitet, das mithilfe von GRU abwechselnd die Zeit- und Frequenzbanddimensionen des Merkmalstensors modelliert. Die verarbeiteten Merkmale werden schließlich durch das Frequenzband-Zusammenführungsmodul geleitet, um die endgültige Spektrumsmaskierungsfunktion als Ausgabe zu erhalten. Die verbesserte Sprache kann durch Multiplikation der Spektrumsmaske und des Eingabespektrums erhalten werden. Um ein sprecherspezifisches Sprachverbesserungsmodell zu erstellen, fügen wir nach dem Modellierungsmodul jeder Frequenzbandsequenz ein Sprecheraufmerksamkeitsmodul hinzu.
Speaker Attentive Module (SAM)
 Die Struktur des Speaker Attentive Module ist in der Abbildung oben dargestellt. Die Kernidee besteht darin, den Sprechereinbettungsvektor
Die Struktur des Speaker Attentive Module ist in der Abbildung oben dargestellt. Die Kernidee besteht darin, den Sprechereinbettungsvektor
als Attraktor des Zwischenmerkmals des Sprachverbesserungsmodells zu verwenden und die Korrelation
szwischen ihm und dem Zwischenmerkmal zu allen Zeiten und Frequenzbändern zu berechnen, die als „ Aufmerksamkeitswert. Dieser Aufmerksamkeitswert wird verwendet, um die Zwischenmerkmale
h zu skalieren und zu regulieren. Die spezifische Formel lautet wie folgt: 
k und q werden multipliziert, um den Aufmerksamkeitswert zu erhalten:
Schließlich den Aufmerksamkeitswert ist bestanden Maßstab Originalmerkmale: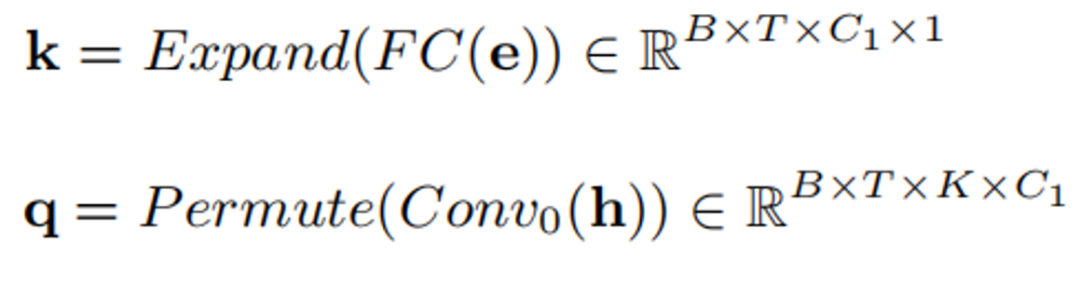
Modelltrainingsdaten
In Bezug auf die Modelltrainingsdaten haben wir die Daten des 5. DNS-Sprecherspezifischen Sprachverbesserungs-Tracks und die hochwertigen Sprachdaten von DiDispeech verwendet. Durch Datenbereinigung haben wir klare Sprachdaten von etwa 3500 Sprechern erhalten. Im Hinblick auf die Datenbereinigung haben wir das vorab trainierte Modell verwendet, das auf der Sprechererkennung von ECAPA-TDNN [1] basiert, um die verbleibende störende Sprechersprache in den Sprachdaten zu entfernen, und wir haben auch das vorab trainierte Modell verwendet, das den ersten Platz gewonnen hat 4. DNS-Herausforderung zur Entfernung von Restrauschen aus Sprachdaten. In der Trainingsphase haben wir mehr als 100.000 4s-Sprachdaten generiert, diesen Audios Nachhall hinzugefügt, um verschiedene Kanäle zu simulieren, und sie nach dem Zufallsprinzip mit Rauschen und Interferenzgesang gemischt, um sie in eine Art von Rauschen, zwei Arten von Rauschen, Rauschen und Interferenzen, zu versetzen Sprache Es gibt 4 Interferenzszenarien: menschliche und nur störende Sprecher. Gleichzeitig werden die Pegel der verrauschten Sprache und der Zielsprache zufällig skaliert, um Eingaben unterschiedlicher Größe zu simulieren.
„Technische Lösung zur Fusion spezifischer Lautsprecherextraktion und Echounterdrückung“
Papieradresse:
https://www.php.cn/link/7c7077ca5231fd6ad758b9d49a2a1eeb
Antworten Tonabbruch ist immer möglich extern durchgeführt Ein äußerst komplexes und entscheidendes Thema im Szenario. Um qualitativ hochwertige, saubere Sprachsignale im Nahbereich zu extrahieren, schlägt Volcano Engine ein leichtes Echounterdrückungssystem vor, das Signalverarbeitung und Deep-Learning-Technologie kombiniert. Basierend auf der personalisierten Tiefengeräuschunterdrückung (pDNS) haben wir außerdem ein personalisiertes akustisches Echounterdrückungssystem (pAEC) aufgebaut, das ein Vorverarbeitungsmodul basierend auf digitaler Signalverarbeitung und ein Vorverarbeitungsmodul basierend auf einem zweistufigen Tiefenmodell umfasst neuronales Netzwerk und ein sprecherspezifisches Sprachextraktionsmodul basierend auf BSRNN und SAM.

Gesamtrahmen der sprecherspezifischen Echounterdrückung
Vorverarbeitungsmodul basierend auf digitaler Signalverarbeitung, linearer Echounterdrückung
Das Vorverarbeitungsmodul besteht hauptsächlich aus zwei Teilen: Zeitverzögerungskompensation (TDC) und lineare Echounterdrückung (LAEC), dieses Modul wird für Subband-Features durchgeführt. 🔜 und verwendet dann die Abstimmungsmethode, um die endgültige Zeitverzögerung zu bestimmen.
Lineare Echounterdrückung
LAEC-Verarbeitungsflussdiagramm
Zweistufiges Modell basierend auf mehrstufigem Convolutional-Cyclic Convolutional Neural Network (CRN)
Wir empfehlen, die pAEC-Aufgabe zu entkoppeln und in „Echounterdrückung“ aufzuteilen. und „spezifische Sprecherextraktions“-Aufgaben, um den Modellierungsdruck zu reduzieren. Daher besteht das Nachverarbeitungsnetzwerk hauptsächlich aus zwei neuronalen Netzwerkmodulen: einem leichten CRN-basierten Modul zur vorläufigen Echokompensation und Rauschunterdrückung und einem pDNS-basierten Nachverarbeitungsmodul zur besseren Rekonstruktion von Sprachsignalen im Nahbereich.
Phase 1: CRN-basiertes Lightweight-Modul
Zweite Stufe: Nachbearbeitungsmodul basierend auf pDNSDas pDNS-Modul umfasst in dieser Stufe das Bandsegmentierungs-Rekurrenten-Neuronale-Netzwerk BSRNN und das oben eingeführte Sprecher-Aufmerksamkeitsmechanismus-Modul SAM. Das Kaskadenmodul ist in Reihe mit dem CRN auf leichter Ebene verbunden Modul. Da unser pDNS-System bei der Aufgabe der Sprachverbesserung charakteristischer Sprecher eine relativ hervorragende Leistung erzielt hat, verwenden wir einen vorab trainierten pDNS-Modellparameter als Initialisierungsparameter der zweiten Stufe des Modells, um die Ausgabe der vorherigen Stufe weiter zu verarbeiten.
Kaskadensystem-Trainingsoptimierungs-Verlustfunktion
Wir verbessern das zweistufige Modell durch Kaskadenoptimierung, sodass es in der ersten Stufe die Nahsprache und in der zweiten Stufe die Nahsprache eines bestimmten Sprechers vorhersagen kann. Wir integrieren außerdem eine Sprachaktivitätserkennungsstrafe für die Nähe zum Sprecher, um die Fähigkeit des Modells zu verbessern, Sprache aus nächster Nähe zu erkennen. Die spezifische Verlustfunktion ist wie folgt definiert:

wobei
jeweils den STFT-Merkmalen entspricht, die in der ersten und zweiten Stufe des Modells vorhergesagt wurden, bzw. die STFT-Merkmale der Nahsprache und die STFT-Merkmale der Nahsprache darstellt Sprechersprache,
repräsentiert jeweils Modellvorhersagen und Ziel-VAD-Zustände.
Modelltrainingsdaten
Um das Echounterdrückungssystem in die Lage zu versetzen, das Echo von Multi-Geräte-, Multi-Reverberation- und Multi-Noise-Collection-Szenen zu verarbeiten, haben wir über 2000 Stunden Trainingsdaten durch die Mischung von Echo und klarer Sprache erhalten. wobei die Echodaten AEC Challenge 2023-Remote-Single-Speech-Daten verwenden, Clean Speech von DNS Challenge 2023 und LibriSpeech stammt und der RIR-Satz, der zur Simulation des Nachhalls am nahen Ende verwendet wird, von DNS Challenge stammt. Da das Echo in den Single-Talk-Daten der AEC Challenge 2023 eine kleine Menge an Rauschdaten enthält, kann die direkte Verwendung dieser Daten als Echo leicht zu Sprachverzerrungen am nahen Ende führen Aber eine effektive Datenbereinigungsstrategie mit Vorverarbeitung. Ein trainiertes AEC-Modell verarbeitet Remote-Einzelkanaldaten, identifiziert Daten mit höherer Restenergie als Rauschdaten und wiederholt den unten gezeigten Bereinigungsprozess.
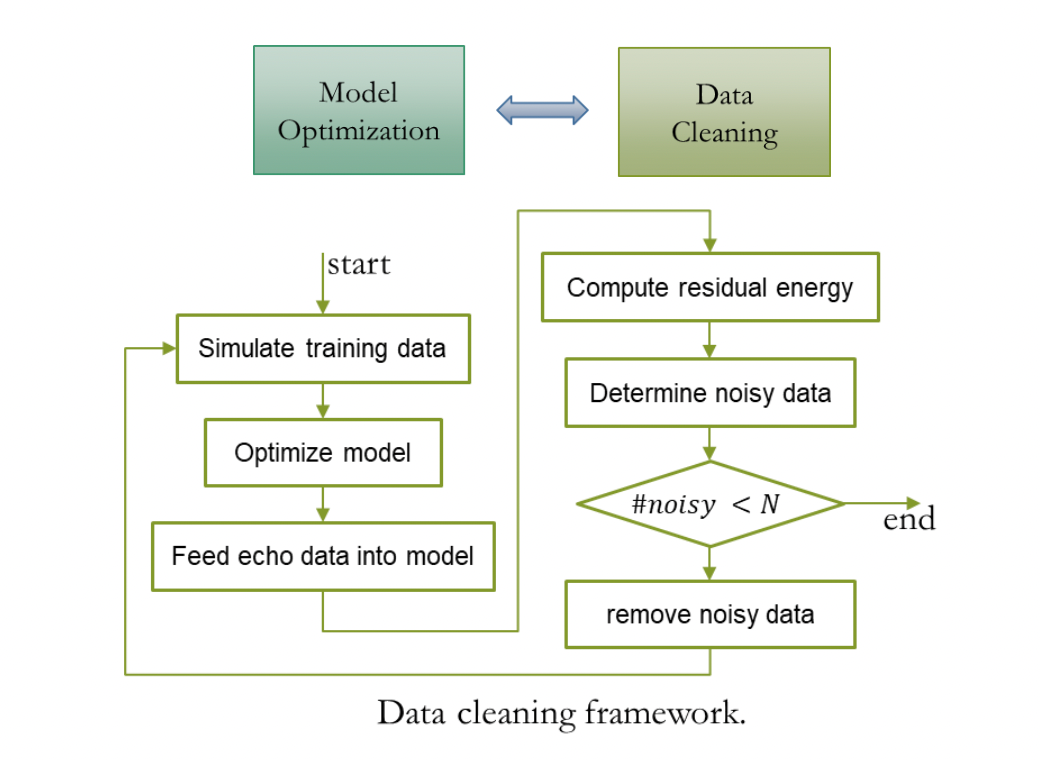
Cascading Optimization Scheme System Effect
Ein solches Sprachverbesserungssystem, das auf verschmolzener Echounterdrückung und spezifischer Sprecherextraktion basiert, wurde im ICASSP 2023 AEC Challenge-Blindtestsatz [2] anhand subjektiver und objektiver Indikatoren verifiziert. Vorteile – erzielte einen subjektiven Meinungswert von 4,44 (Subjektiv-MOS) und eine Spracherkennungsgenauigkeitsrate von 82,2 % (WAcc).

„Mehrkanalige Sprachverbesserung basierend auf dem Fourier-Faltungsaufmerksamkeitsmechanismus“
Papieradresse:
https://www.php.cn/link/373cb8cd58 5f1309b31c56e2d5a83
Die auf Deep Learning basierende Strahlgewichtsschätzung ist derzeit eine der gängigsten Methoden zur Lösung von Mehrkanal-Sprachverbesserungsaufgaben, d. h. das Filtern von Mehrkanalsignalen durch Lösen von Strahlgewichten über das Netzwerk, um reine Sprache zu erhalten. Bei der Schätzung von Strahlgewichten spielen Spektrumsinformationen und räumliche Informationen eine ähnliche Rolle wie das Prinzip der Lösung der räumlichen Kovarianzmatrix im herkömmlichen Strahlformungsalgorithmus. Allerdings sind viele vorhandene neuronale Strahlformer nicht in der Lage, die Strahlgewichte optimal abzuschätzen. Um dieser Herausforderung zu begegnen, schlägt Volcano Engine einen Fourier Convolutional Attention Encoder (FCAE) vor, der ein globales Empfangsfeld auf der Frequenzmerkmalsachse bereitstellen und die Kontextmerkmale der Frequenzachse der Extraktion verbessern kann. Gleichzeitig haben wir auch eine FCAE-basierte CRED-Struktur (Convolutional Recurrent Encoder-Decoder) vorgeschlagen, um spektrale Kontextmerkmale und räumliche Informationen aus Eingabemerkmalen zu erfassen.
Modellrahmenstruktur
Netzwerk zur Strahlgewichtsschätzung

Dieses Netzwerk verwendet das Strukturparadigma des Embedding and Beamforming Network (EaBNet), um das Netzwerk in zwei Teile zu unterteilen: das Einbettungsmodul und das Strahlmodul wird verwendet, um den Einbettungsvektor zu extrahieren, der spektrale und räumliche Informationen aggregiert, und sendet den Einbettungsvektor an den Strahlteil, um das Strahlgewicht abzuleiten. Hier wird eine CRED-Struktur verwendet, um den Einbettungstensor zu lernen. Nachdem das Mehrkanal-Eingangssignal durch STFT transformiert wurde, wird es an eine CRED-Struktur gesendet, um den Einbettungstensor zu extrahieren und enthält unterscheidbare Sprache und Merkmale von Geräuschen. Der Einbettungstensor wird durch die LayerNorm2d-Struktur geleitet, dann durch zwei gestapelte LSTM-Netzwerke und schließlich werden die Strahlgewichte durch eine lineare Schicht abgeleitet. Wir wenden das Strahlgewicht auf die Eigenschaften des Mehrkanal-Eingangsspektrums an, führen Filter- und Summationsoperationen durch und erhalten schließlich das reine Sprachspektrum. Nach der ISTFT-Transformation kann die Zielwellenform im Zeitbereich erhalten werden.
CRED-Struktur
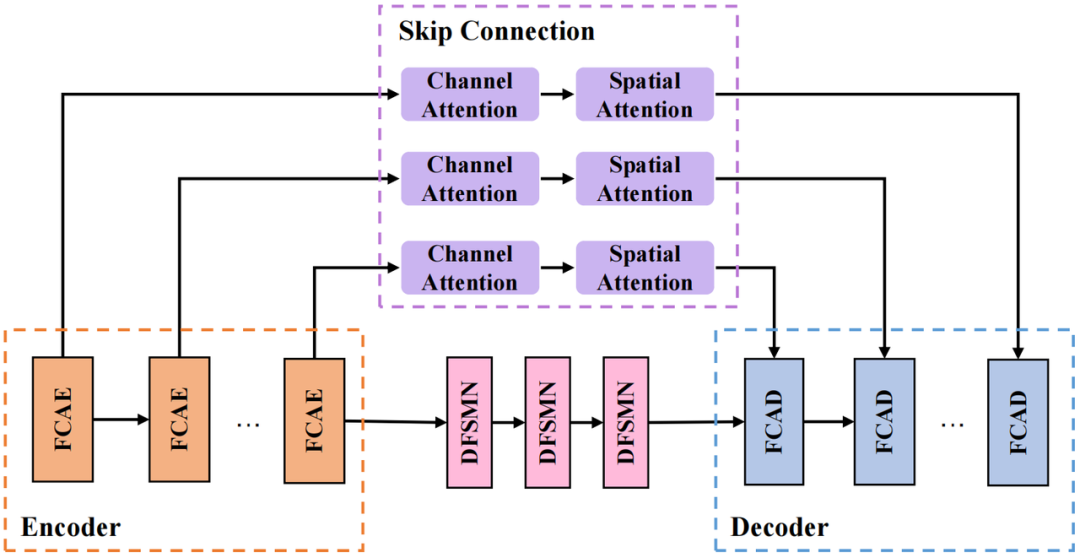
Die von uns verwendete CRED-Struktur ist im Bild oben dargestellt. Unter ihnen ist FCAE der Fourier-Faltungsaufmerksamkeitsencoder und FCAD ist der zu FCAE symmetrische Decoder. Das Schleifenmodul verwendet das Deep Feedward Sequential Memory Network (DFSMN), um die zeitliche Abhängigkeit der Sequenz zu modellieren, ohne das Modell zu beeinflussen Leistung; Der Sprungverbindungsteil verwendet serielle Kanalaufmerksamkeitsmodule (Channel Attention) und räumliche Aufmerksamkeitsmodule (Spatial Attention), um kanalübergreifende räumliche Informationen weiter zu extrahieren und tiefe Schichten zu verbinden. Merkmale und flache Merkmale erleichtern die Übertragung von Informationen im Netzwerk.
FCAE-Struktur
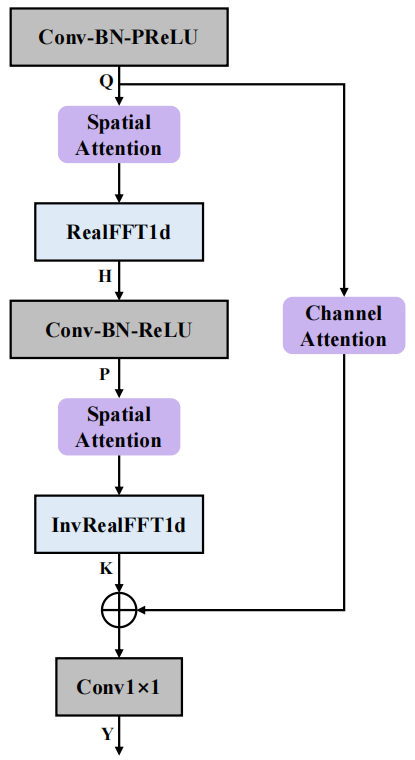
Die Struktur des Fourier Convolutional Attention Encoder (FCAE) ist in der Abbildung oben dargestellt. Inspiriert durch den Fourier-Faltungsoperator [3] macht sich dieses Modul die Tatsache zunutze, dass die Aktualisierung der diskreten Fourier-Transformation an jedem Punkt in der Transformationsdomäne einen globalen Einfluss auf das Signal in der ursprünglichen Domäne hat, und führt eine Anpassung durch. Frequenzanalyse der Frequenzachsenmerkmale Durch dimensionale FFT-Transformation kann das globale Empfangsfeld auf der Frequenzachse ermittelt werden, wodurch die Extraktion von Kontextmerkmalen auf der Frequenzachse verbessert wird. Darüber hinaus haben wir ein räumliches Aufmerksamkeitsmodul und ein Kanalaufmerksamkeitsmodul eingeführt, um die Faltungsausdrucksfähigkeit weiter zu verbessern, nützliche spektral-räumliche gemeinsame Informationen zu extrahieren und das Erlernen unterscheidbarer Merkmale von reiner Sprache und Rauschen durch das Netzwerk zu verbessern. Im Hinblick auf die Endleistung erzielte das Netzwerk eine hervorragende Mehrkanal-Sprachverbesserung mit nur 0,74 Millionen Parametern.
Modelltrainingsdaten
In Bezug auf den Datensatz haben wir den Open-Source-Datensatz des Wettbewerbs ConferencingSpeech 2021 verwendet. Die reinen Sprachdaten umfassen AISHELL-1, AISHELL-3, VCTK und LibriSpeech (train-clean-360). , und wählte die Signal-Rausch-Daten unter ihnen aus. Daten mit einem Verhältnis von mehr als 15 dB werden verwendet, um mehrkanalige gemischte Sprache zu erzeugen, und der Rauschdatensatz verwendet MUSAN und AudioSet. Um gleichzeitig reale Nachhallszenarien in mehreren Räumen zu simulieren, wurden die Open-Source-Daten mit mehr als 5.000 Raumimpulsantworten gefaltet, indem Änderungen der Raumgröße, Nachhallzeit, Schallquellen, Geräuschquellenstandorte usw. simuliert wurden Schließlich wurden mehr als 60.000 Antworten auf Multi-Channel-Trainingsbeispiele generiert.
„System zur Wiederherstellung der Klangqualität basierend auf einem zweistufigen neuronalen Netzwerkmodell“
Papieradresse:
https://www.php.cn/link/e614f646836aaed9f89ce58e837e2310
Vulkan Der Motor ist Es werden immer noch Reparaturen an der Klangqualität durchgeführt. Es wurden mehrere Versuche unternommen, die Sprache bestimmter Sprecher zu verbessern, Echos zu eliminieren und Mehrkanal-Audio zu verbessern. Im Prozess der Echtzeitkommunikation beeinträchtigen verschiedene Formen der Verzerrung die Qualität des Sprachsignals, was zu einer Verschlechterung der Klarheit und Verständlichkeit des Sprachsignals führt. Volcano Engine schlägt ein zweistufiges Modell vor, das eine abgestufte Divide-and-Conquer-Strategie verwendet, um verschiedene Verzerrungen zu reparieren, die sich auf die Sprachqualität auswirken.
Modellrahmenstruktur
Das Bild unten zeigt die Gesamtrahmenzusammensetzung des zweistufigen Modells. Das Modell der ersten Stufe repariert hauptsächlich die fehlenden Teile des Spektrums und das Modell der zweiten Stufe unterdrückt hauptsächlich Rauschen und Nachhall und Artefakte, die durch den Film der ersten Stufe erzeugt werden können.

Modell der ersten Stufe: Reparierendes Netz
Das Gesamtmodell übernimmt die Architektur des Deep Complex Convolution Recurrent Network (DCCRN) [4], die drei Teile umfasst: Encoder, Timing-Modellierungsmodul und Decoder. Inspiriert von der Bildreparatur führen wir die komplexwertige Gate-Faltung und die komplexwertige transponierte Gate-Faltung ein, um die komplexwertige Faltung und die komplexwertige transponierte Faltung in Encoder und Decoder zu ersetzen. Um die Natürlichkeit des Audio-Reparaturteils weiter zu verbessern, haben wir den Multi-Period-Diskriminator und den Multi-Scale-Diskriminator für das Hilfstraining eingeführt.
Modell der zweiten Stufe: Denoising Net
Die gesamte S-DCCRN-Architektur wird verwendet, einschließlich des Encoders, zweier leichter DCCRN-Submodule und des Decoders. Die beiden leichten DCCRN-Submodule führen jeweils eine Subband- und eine Full-Scale-Verarbeitung durch . Mit Modellierung. Um die Fähigkeit des Modells zur Zeitbereichsmodellierung zu verbessern, haben wir das LSTM im DCCRN-Untermodul durch das Squeezed Temporal Convolutional Module (STCM) ersetzt.
Modell-Trainingsdaten
Das saubere Audio, das Rauschen und der Nachhall, die für das Training zur Wiederherstellung der Klangqualität verwendet werden, stammen alle aus dem DNS-Wettbewerbsdatensatz 2023, in dem die Gesamtdauer des sauberen Audios 750 Stunden und die Gesamtdauer des Rauschens 750 Stunden beträgt 170 Stunden. Während der Datenerweiterung des ersten Stufenmodells verwendeten wir Vollband-Audio zur Faltung mit zufällig generierten Filtern, mit einer Fensterlänge von 20 ms, um die Audio-Abtastpunkte zufällig auf Null zu setzen und das Audio nach dem Zufallsprinzip herunterzuskalieren, um einen Spektrumsverlust zu simulieren Andererseits werden die Audioamplitudenfrequenz und die Audiosammelpunkte mit zufälligen Skalen multipliziert. In der zweiten Stufe der Datenerweiterung verwenden wir die bereits in der ersten Stufe generierten Daten, um verschiedene Arten von Raumimpulsen zu falten mit unterschiedlichem Nachhall.
Audioverarbeitungseffekt
Bei der ICASSP 2023 AEC Challenge gewann das Volcano Engine RTC-Audioteam die Meisterschaftin zwei Tracks: Universal Echo Cancellation (Nicht personalisierte AEC) und Specific Speaker Echo Cancellation (Personalisierte AEC) und gewann den Dual-Talk-Echounterdrückung, Dual-Talk-Near-End-Sprachschutz, Near-End-Single-Talk-Hintergrundgeräuschunterdrückung, umfassende subjektive Audioqualitätsbewertung und endgültige Spracherkennungsgenauigkeit
sind deutlich besser als andere teilnehmende Teams und haben die internationale Ebene erreicht führende Ebene. Werfen wir einen Blick auf die Verarbeitungseffekte der Sprachverbesserung von Volcano Engine RTC in verschiedenen Szenarien nach den oben genannten technischen Lösungen. Echounterdrückung in verschiedenen Signal-Rausch-Echo-Verhältnis-SzenarienDie folgenden zwei Beispiele zeigen die vergleichenden Auswirkungen des Echounterdrückungsalgorithmus vor und nach der Verarbeitung in verschiedenen Signal-zu-Echo-Energieverhältnis-Szenarien.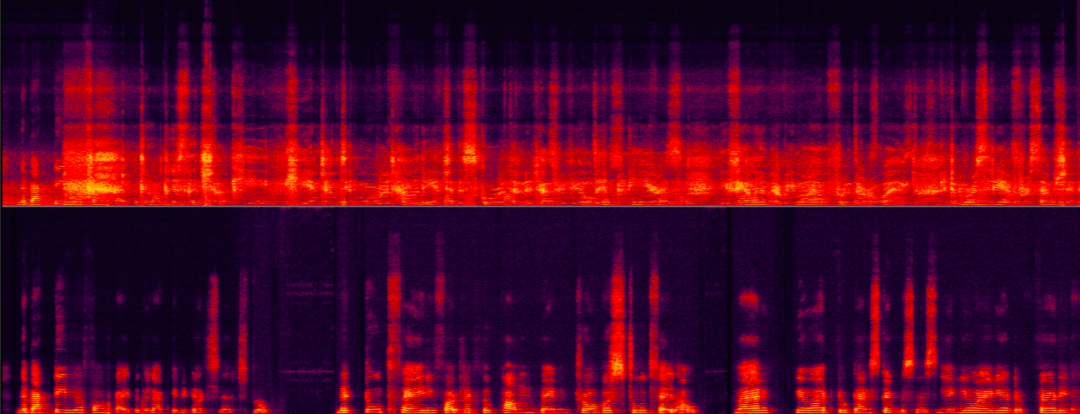
Szenen mit mittlerem Signal-Echo-Verhältnis
Szenen mit extrem niedrigem Signal-Echo-Verhältnis sind derzeit die größte Herausforderung für die Echounterdrückung Entfernen Sie effektiv hochenergetische Echos, maximieren Sie aber gleichzeitig den Erhalt schwacher Zielsprache. Die Stimme (Echo) des Nicht-Zielsprechers überschattet fast vollständig die Stimme des Zielsprechers (weiblich), was die Identifizierung erschwert.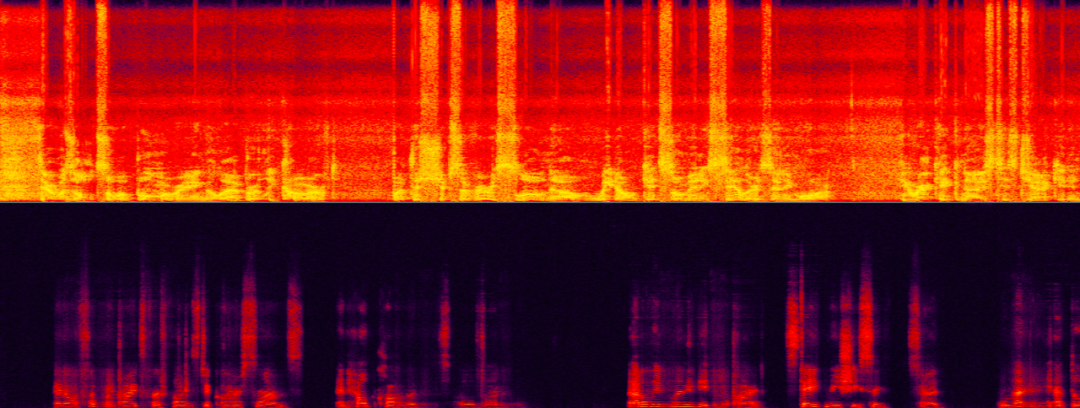
Szene mit extrem niedrigem Signal-Echo-Verhältnis
Lautsprecherextraktion in Szenarien, in denen unterschiedliche Hintergründe den Sprecher störenDie folgenden beiden Beispiele demonstrieren jeweils die Leistung einer bestimmten Lautsprecherextraktion Algorithmen in Rauschen und Hintergrund. Vergleichende Effekte vor und nach der Behandlung in menschlichen Interferenzszenen. Im folgenden Beispiel weist der bestimmte Lautsprecher sowohl türklingelartige Geräuschstörungen als auch Hintergrundgeräuschstörungen auf. Durch die alleinige Verwendung der KI-Rauschunterdrückung kann nur das Türklingelgeräusch entfernt werden, sodass die Stimme des bestimmten Lautsprechers eliminiert werden muss.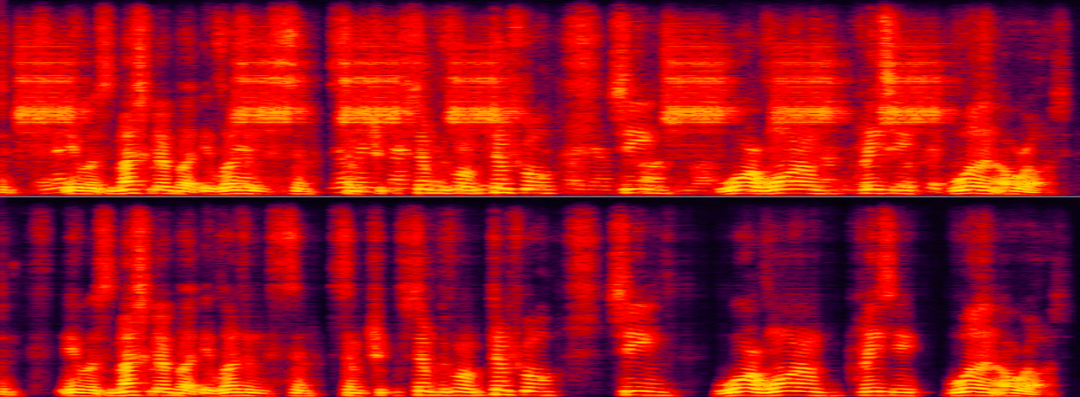
Der Zielsprecher und die im Hintergrund störenden Stimmen und Geräusche
Wenn die Stimmabdruckmerkmale des Zielsprechers und die im Hintergrund störende Stimme sehr nahe beieinander liegen, wird zu diesem Zeitpunkt der spezifische Sprecher extrahiert Die Herausforderung des Algorithmus ist größer und er kann die Robustheit des spezifischen Sprecherextraktionsalgorithmus testen. Im folgenden Beispiel sind der Zielsprecher und die störende Hintergrundstimme zwei ähnliche Frauenstimmen.
Mischung von weiblicher Zielstimme und weiblicher Interferenzstimme
Zusammenfassung und AusblickDas Obige stellt das Volcano Engine RTC-Audioteam vor, das auf Deep Learning in der lautsprecherspezifischen Geräuschreduzierung und dem Echo basiert Unterdrückung und Mehrkanalsprache Obwohl einige Lösungen und Effekte in Richtung Verbesserung erzielt wurden, stehen zukünftige Szenarien immer noch in vielerlei Hinsicht vor Herausforderungen, z. B. wie die Reduzierung von Sprachgeräuschen an Geräuschszenen angepasst werden kann und wie Reparaturen mehrerer Arten durchgeführt werden können Audiosignale in einem breiteren Bereich der Klangqualitätsreparatur und die Durchführung verschiedener Arten von Reparaturen an Audiosignalen in einem breiteren Bereich. Diese Herausforderungen werden auch im Mittelpunkt unserer weiteren Forschungsrichtungen stehen. 🎜Das obige ist der detaillierte Inhalt vonEntmystifizierung einiger der KI-basierten Techniken zur Sprachverbesserung, die bei Echtzeitanrufen verwendet werden. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Technologietrends, die Sie im Jahr 2023 im Auge behalten sollten
- Wie künstliche Intelligenz Rechenzentrumsteams neue Alltagsaufgaben beschert
- Können künstliche Intelligenz oder Automatisierung das Problem der geringen Energieeffizienz in Gebäuden lösen?
- OpenAI-Mitbegründer im Interview mit Huang Renxun: Die Argumentationsfähigkeiten von GPT-4 haben noch nicht die Erwartungen erfüllt
- Dank der OpenAI-Technologie übertrifft Bing von Microsoft Google im Suchverkehr