
Heim >Technologie-Peripheriegeräte >KI >Die DAMO Academy erweitert große Sprachmodelle um umfassende audiovisuelle Funktionen und ist Open-Source-Video-LLaMA
Die DAMO Academy erweitert große Sprachmodelle um umfassende audiovisuelle Funktionen und ist Open-Source-Video-LLaMA

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBnach vorne
- 2023-06-09 21:28:041676Durchsuche
Videos spielen in der heutigen sozialen Medien- und Internetkultur eine immer wichtigere Rolle. Douyin, Kuaishou, Bilibili usw. sind zu beliebten Plattformen für Hunderte Millionen Benutzer geworden. Benutzer teilen ihre Lebensmomente, kreativen Arbeiten, interessanten Momente und andere Inhalte rund um Videos, um mit anderen zu interagieren und zu kommunizieren.
In letzter Zeit haben große Sprachmodelle beeindruckende Fähigkeiten unter Beweis gestellt. Können wir große Models mit „Augen“ und „Ohren“ ausstatten, damit sie Videos verstehen und mit Nutzern interagieren können?
Ausgehend von diesem Problem schlugen Forscher der DAMO Academy Video-LLaMA vor, ein großes Modell mit umfassenden audiovisuellen Funktionen. Video-LLaMA kann Video- und Audiosignale in Videos wahrnehmen und verstehen und kann Benutzereingabeanweisungen verstehen, um eine Reihe komplexer Aufgaben basierend auf Audio und Video zu erledigen, wie z. B. Audio-/Videobeschreibung, Schreiben, Fragen und Antworten usw. Derzeit sind alle Artikel, Codes und interaktive Demos geöffnet. Darüber hinaus stellt das Forschungsteam auf der Homepage des Video-LLaMA-Projekts auch eine chinesische Version des Modells bereit, um die Erfahrung chinesischer Benutzer reibungsloser zu gestalten.

- Papierlink: https://arxiv.org/abs/2306.02858
- Codeadresse: https://github.com/DAMO-NLP-SG/Video- LLaMA
- Demo-Adresse:
- Modelscope: https://modelscope.cn/studios/damo/video-llama/summary
- . Huggingface: https: //huggingface.co/spaces/DAMO-NLP-SG/Video-LLaMA
- Adresse der Beispieleingabedatei:
- https://www.php.cn/link/0fbce6c74ff376d18cb352e7fdc627 3b
Modelldesign
Video-LLaMA verwendet modulare Designprinzipien, um die visuellen und akustischen modalen Informationen im Video dem Eingaberaum des großen Sprachmodells zuzuordnen und so die Fähigkeit zu erreichen, modalübergreifenden Anweisungen zu folgen. Im Gegensatz zu früheren großen Modellforschungen (MiNIGPT4, LLaVA), die sich auf das Verständnis statischer Bilder konzentrierten, steht Video-LLaMA beim Videoverständnis vor zwei Herausforderungen: der Erfassung dynamischer Szenenänderungen im Sehvermögen und der Integration audiovisueller Signale.
Um dynamische Szenenwechsel in Videos zu erfassen, führt Video-LLaMA einen steckbaren visuellen Sprachzweig ein. Dieser Zweig verwendet zunächst den vorab trainierten Bildencoder in BLIP-2, um die einzelnen Merkmale jedes Bildes zu erhalten, und kombiniert sie dann mit der Einbettung der entsprechenden Bildposition. Alle Bildmerkmale werden an Video Q-Former und Video Q gesendet -Former aggregiert Bilddarstellungen auf Frame-Ebene und generiert synthetische Videodarstellungen fester Länge. Schließlich wird eine lineare Ebene verwendet, um die Videodarstellung an den Einbettungsraum des großen Sprachmodells anzupassen.
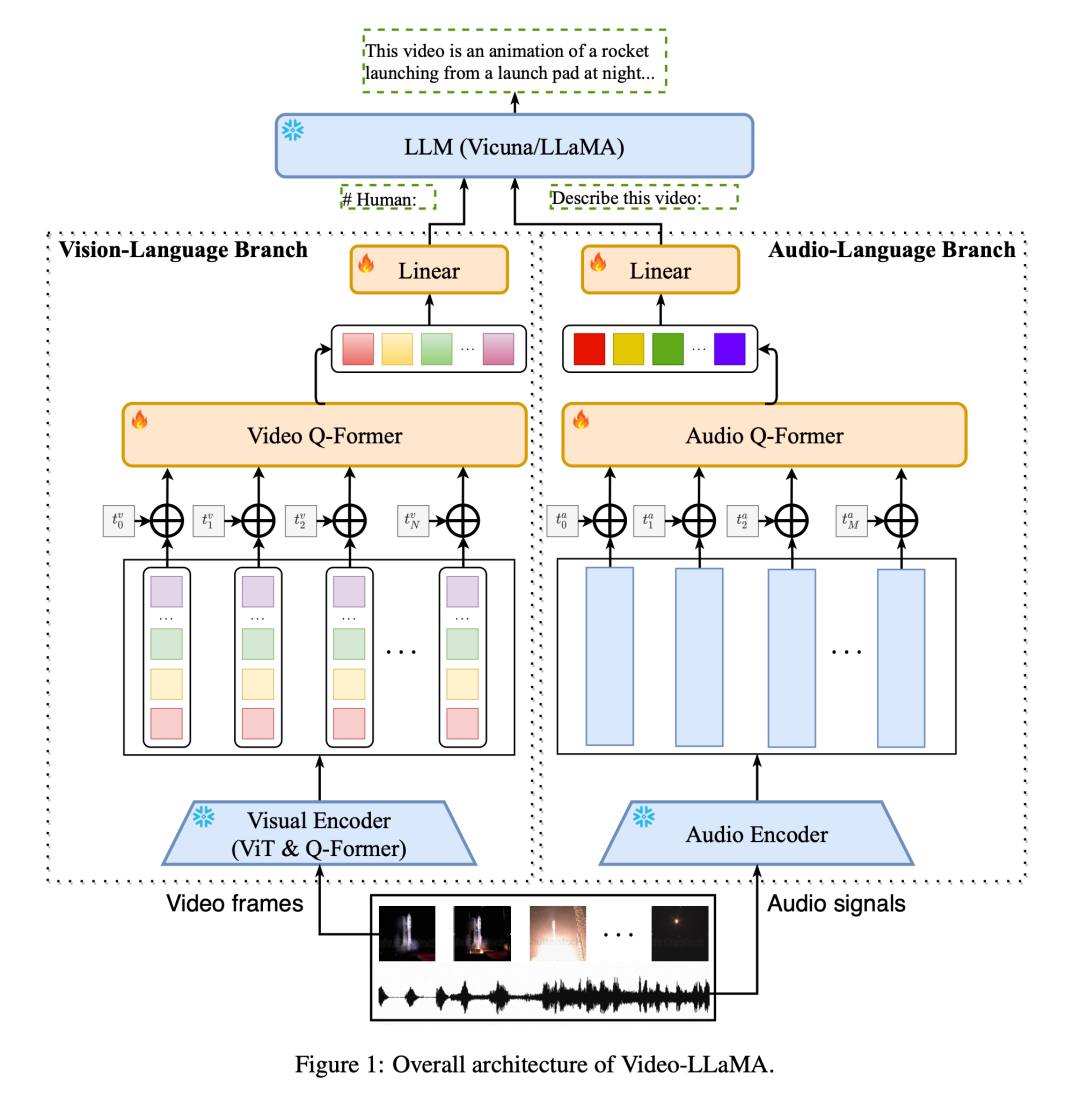
Was die Tonsignale im Video betrifft, nutzt Video-LLaMA den Audio-Sprachzweig zur Verarbeitung. Zunächst werden mehrere zwei Sekunden lange Audioclips gleichmäßig aus dem Originalvideo abgetastet und jeder Clip wird in ein 128-dimensionales Mel-Spektrogramm umgewandelt. Anschließend wird das leistungsstarke ImageBind als Audio-Encoder verwendet, um die Funktionen jedes Soundclips einzeln zu extrahieren. Nach dem Hinzufügen lernbarer Positionseinbettungen aggregiert Audio Q-Former Segmentfunktionen als Ganzes und generiert Audiofunktionen fester Länge. Ähnlich wie beim Zweig der visuellen Sprache wird schließlich eine lineare Ebene verwendet, um die Audiodarstellung an den Einbettungsraum des großen Sprachmodells anzupassen.
Um die Trainingskosten zu senken, friert Video-LLaMA den vorab trainierten Bild-/Audio-Encoder ein und aktualisiert nur die folgenden Parameter in den visuellen und Audio-Zweigen: Video/Audio Q-Former, Positionskodierungsschicht und lineare Schicht ( Wie in Abbildung 1 dargestellt).
Um die Ausrichtungsbeziehung zwischen Vision und Text zu lernen, trainierten die Autoren zunächst den Vision-Zweig mithilfe eines großen Video-Text-Datensatzes (WebVid-2M) und eines Bild-Text-Datensatzes (CC-595K). Anschließend nutzten die Autoren Bildbefehlsdatensätze von MiniGPT-4, LLaVA und Videobefehlsdatensätze von Video-Chat zur Feinabstimmung, um bessere modalübergreifende Befehlsfolgefunktionen zu erreichen.
Was das Erlernen von Audio-Text-Ausrichtungsbeziehungen betrifft, haben die Autoren aufgrund des Mangels an umfangreichen, hochwertigen Audio-Text-Daten eine Umgehungsstrategie angenommen, um dieses Ziel zu erreichen. Erstens kann das Ziel der lernbaren Parameter im audiolinguistischen Zweig darin verstanden werden, die Ausgabe des Audio-Encoders an den Einbettungsraum des LLM anzupassen. Der Audio-Encoder ImageBind verfügt über eine sehr starke multimodale Ausrichtungsfähigkeit, die die Einbettungen verschiedener Modalitäten in einem gemeinsamen Raum ausrichten kann. Daher verwenden die Autoren visuelle Textdaten, um den Audio-Sprachzweig zu trainieren, indem sie den gemeinsamen Einbettungsraum von ImageBind an den Texteinbettungsraum von LLM anpassen und so eine Audiomodalität für die Ausrichtung des LLM-Texteinbettungsraums erreichen. Auf diese clevere Weise ist Video-LLaMA in der Lage, die Fähigkeit zu demonstrieren, Audio während der Inferenz zu verstehen, obwohl es noch nie auf Audiodaten trainiert wurde.
Beispieldemonstration
Der Autor zeigt einige Beispiele für Video-LLaMA-Dialoge auf Video-/Audio-/Bildbasis.
(1) Die folgenden beiden Beispiele demonstrieren die audiovisuell umfassenden Wahrnehmungsfähigkeiten von Video-LLaMA. Das Gespräch im Beispiel dreht sich um Audio-Video. In Beispiel 2 wird nur der Darsteller auf dem Bildschirm gezeigt, aber der Ton ist der Jubel und Applaus des Publikums. Wenn das Modell nur visuelle Signale empfangen kann, kann es nicht auf die positive Reaktion des Publikums schließen Kein Ton von Musikinstrumenten im Bild. Wenn das Modell nur akustische Signale empfangen kann, weiß es nicht, dass der Spieler das Saxophon gespielt hat.

(2) Video-LLaMA verfügt auch über starke Wahrnehmungsverständnisfähigkeiten für statische Bilder und kann Aufgaben wie Bildbeschreibung, Fragen und Antworten usw. erledigen.

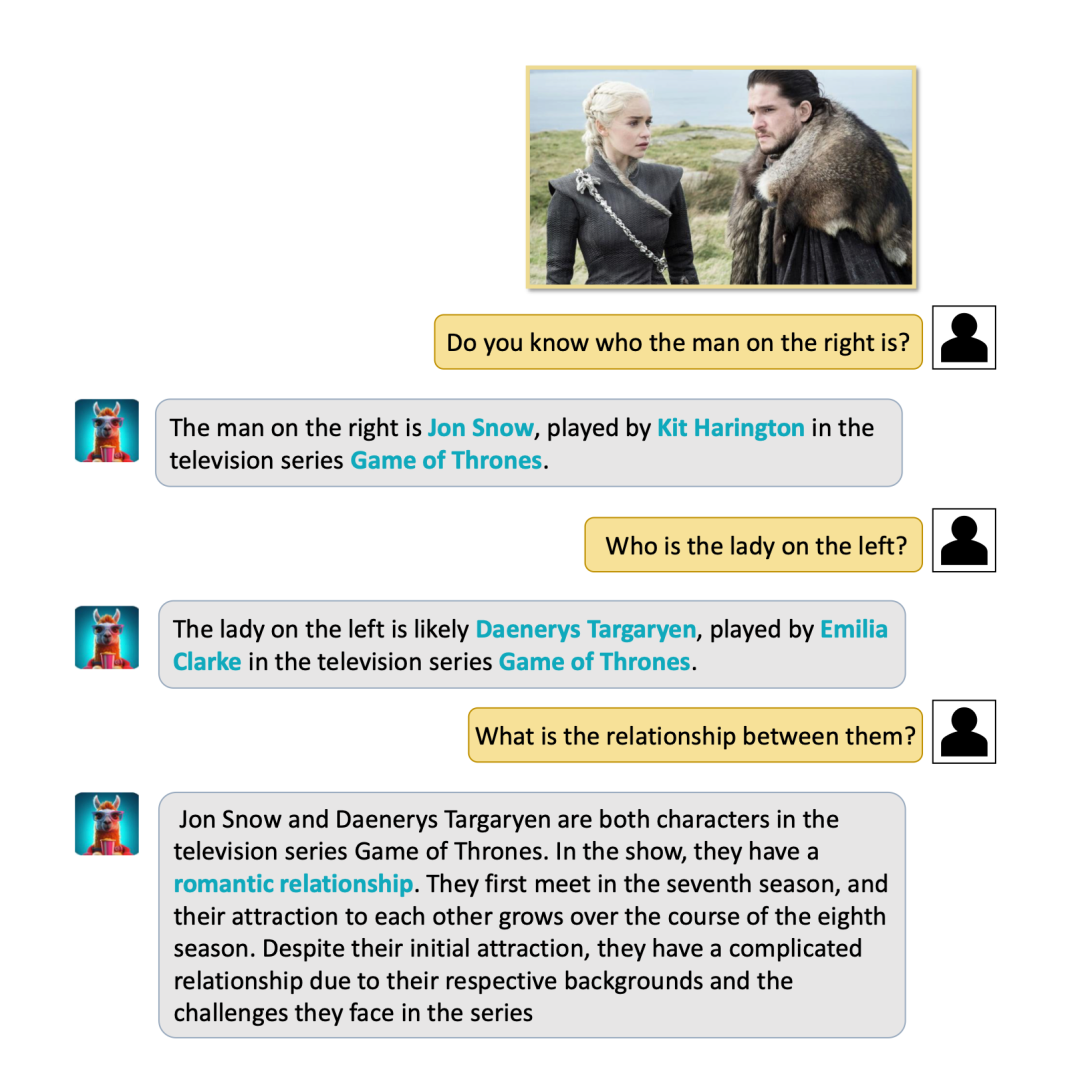
(3) Überraschenderweise kann Video-LLaMA berühmte Sehenswürdigkeiten und Personen erfolgreich identifizieren und Fragen und Antworten mit gesundem Menschenverstand durchführen. Beispielsweise hat VIdeo-LLaMA unten das Weiße Haus erfolgreich identifiziert und die Situation des Weißen Hauses vorgestellt. Ein weiteres Beispiel ist die Eingabe eines Standbildes von Long Ma und Jon Snow (Charaktere in der klassischen Film- und Fernsehserie „Game of Thrones“). VIdeo-LLaMA kann sie nicht nur erfolgreich identifizieren, sondern ihnen auch von ihrer ständigen Beziehung erzählen bearbeitet und durcheinander gebracht.

(4) Video-Lama kann auch dynamische Ereignisse im Video erfassen, wie zum Beispiel die Bewegung von Pfiffen und die Richtung des Bootes.

Zusammenfassung
Derzeit ist das Audio- und Videoverständnis immer noch ein sehr komplexes Forschungsproblem ohne ausgereifte Lösung. Obwohl Video-LLaMA beeindruckende Fähigkeiten gezeigt hat, weist der Autor auch darauf hin, dass es einige Einschränkungen gibt.
(1) Eingeschränkte Wahrnehmungsfähigkeit: Die visuellen und auditiven Fähigkeiten von Video-LLaMA sind noch relativ rudimentär und es ist immer noch schwierig, komplexe visuelle und akustische Informationen zu identifizieren. Ein Grund dafür ist, dass die Qualität und Größe der Datensätze nicht gut genug sind. Diese Forschungsgruppe arbeitet hart daran, einen hochwertigen Audio-Video-Text-Ausrichtungsdatensatz zu erstellen, um die Wahrnehmungsfähigkeiten des Modells zu verbessern.
(2) Schwierigkeiten bei der Verarbeitung langer Videos: Lange Videos (wie Filme und Fernsehsendungen) enthalten eine große Menge an Informationen, was hohe Denkfähigkeiten und Rechenressourcen für das Modell erfordert.
(3) Das inhärente Halluzinationsproblem von Sprachmodellen besteht in Video-LLaMA immer noch.
Im Allgemeinen hat Video-LLaMA als großes Modell mit umfassenden audiovisuellen Fähigkeiten beeindruckende Ergebnisse im Bereich des Audio- und Videoverständnisses erzielt. Während die Forscher weiterhin hart arbeiten, werden die oben genannten Herausforderungen nach und nach bewältigt, sodass das Audio- und Video-Verständnismodell einen breiten praktischen Wert erhält.
Das obige ist der detaillierte Inhalt vonDie DAMO Academy erweitert große Sprachmodelle um umfassende audiovisuelle Funktionen und ist Open-Source-Video-LLaMA. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Technologietrends, die Sie im Jahr 2023 im Auge behalten sollten
- Wie künstliche Intelligenz Rechenzentrumsteams neue Alltagsaufgaben beschert
- Können künstliche Intelligenz oder Automatisierung das Problem der geringen Energieeffizienz in Gebäuden lösen?
- OpenAI-Mitbegründer im Interview mit Huang Renxun: Die Argumentationsfähigkeiten von GPT-4 haben noch nicht die Erwartungen erfüllt
- Dank der OpenAI-Technologie übertrifft Bing von Microsoft Google im Suchverkehr