
Heim >Technologie-Peripheriegeräte >KI >Cambridge, Tencent AI Lab und andere haben das große Sprachmodell PandaGPT vorgeschlagen: Ein Modell vereint sechs Modalitäten
Cambridge, Tencent AI Lab und andere haben das große Sprachmodell PandaGPT vorgeschlagen: Ein Modell vereint sechs Modalitäten

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBnach vorne
- 2023-06-05 12:19:51910Durchsuche
Forscher aus Cambridge, NAIST und Tencent AI Lab haben kürzlich ein Forschungsergebnis namens PandaGPT veröffentlicht, bei dem es sich um eine Methode zum Ausrichten und Binden großer Sprachmodelle mit unterschiedlichen Modalitäten handelt, um eine modalübergreifende Technologie zur Befehlsfolgefähigkeit zu erreichen. PandaGPT kann komplexe Aufgaben erledigen, z. B. detaillierte Bildbeschreibungen erstellen, Geschichten aus Videos schreiben und Fragen zu Audio beantworten. Es kann multimodale Eingaben gleichzeitig empfangen und deren Semantik auf natürliche Weise kombinieren.

- Projekthomepage: https:/ /panda-gpt.github.io/
- Code: https://github.com/yxuansu/PandaGPT
- Papier: http://arxiv.org/abs/2305.16355
- # 🎜🎜#Online-Demo-Anzeige: https://huggingface.co/spaces/GMFTBY/PandaGPT
# 🎜 🎜#
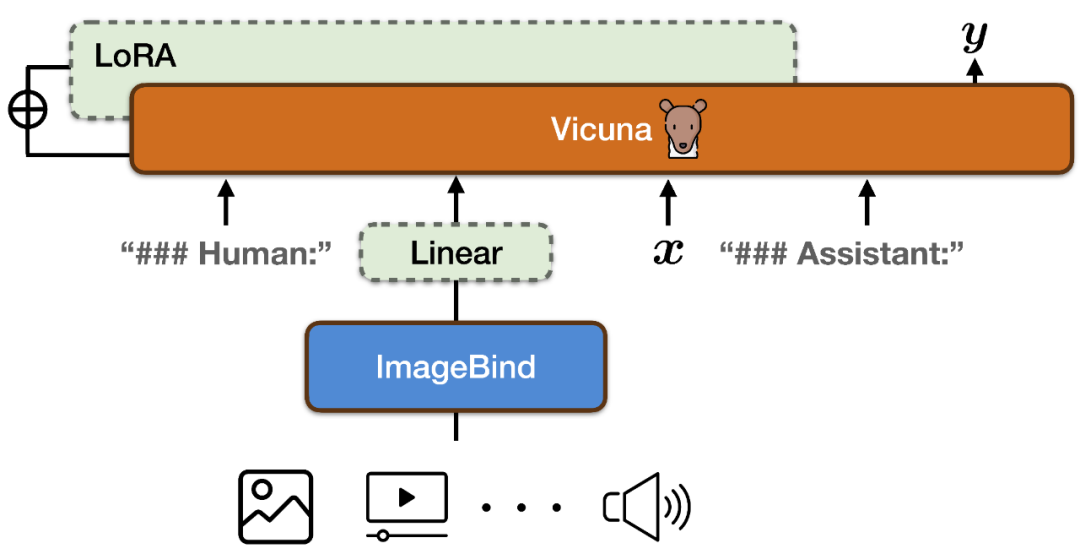
Um die Funktionsräume des multimodalen Encoders von ImageBind und des großen Sprachmodells von Vicuna auszurichten, verwendete PandaGPT eine Kombination aus LLaVa und Mini-GPT4 und veröffentlichte insgesamt 160.000 Basierend auf den verbalen Anweisungen der Bilder folgen die Daten als Trainingsdaten. Jede Trainingsinstanz besteht aus einem Bild und einem entsprechenden Satz von Dialogrunden.
Um die multimodale Ausrichtung von ImageBind selbst nicht zu zerstören und die Schulungskosten zu senken, hat PandaGPT nur die folgenden Module aktualisiert:
#🎜🎜 #
Fügen Sie dem Codierungsergebnis von ImageBind eine lineare Projektionsmatrix hinzu, konvertieren Sie die von ImageBind generierte Darstellung und fügen Sie sie in die Eingabesequenz von Vicuna ein 🎜## 🎜🎜#Zusätzliche LoRA-Gewichte zum Aufmerksamkeitsmodul von Vicuna hinzugefügt. Die Gesamtzahl der Parameter der beiden macht etwa 0,4 % der Vicuna-Parameter aus. Die Trainingsfunktion ist ein traditionelles Ziel der Sprachmodellierung. Es ist zu beachten, dass während des Trainingsprozesses nur das Gewicht des entsprechenden Teils der Modellausgabe aktualisiert wird und der Benutzereingabeteil nicht berechnet wird. Der gesamte Trainingsprozess dauert auf 8×A100 (40G) GPUs etwa 7 Stunden.- Es ist hervorzuheben, dass die aktuelle Version von PandaGPT nur ausgerichtete Bild-Text-Daten für das Training verwendet, aber die sechs Arten des modalen Verständnisses des ImageBind-Encoders erbt Funktionen (Bild/Video, Text, Audio, Tiefe, Wärmekarte und IMU) und Ausrichtungseigenschaften zwischen ihnen, wodurch modalübergreifende Funktionen über alle Modalitäten hinweg ermöglicht werden.
- In dem Experiment demonstrierte der Autor die Fähigkeit von PandaGPT, verschiedene Modalitäten zu verstehen, darunter bild-/videobasierte Fragen und Antworten, bild-/videobasiertes kreatives Schreiben, visuelle basierend auf akustischen Informationen usw. Hier sind einige Beispiele:
Bild:
#🎜 🎜 ## 🎜🎜 ## 🎜🎜 ## 🎜🎜 ## 🎜🎜 ## 🎜🎜 ## 🎜🎜 ## 🎜🎜#Audio:#🎜🎜 ## 🎜🎜 ## 🎜🎜 ## 🎜🎜 ## 🎜 🎜 ## 🎜🎜 ## 🎜🎜 ## 🎜🎜 ## 🎜🎜 ## 🎜🎜 ## 🎜🎜#Video:#🎜🎜 ## 🎜🎜 ## 🎜🎜 ## 🎜🎜 ## 🎜🎜 ## 🎜 🎜 #
Im Vergleich zu anderen multimodalen Sprachmodellen ist das herausragendste Merkmal von PandaGPT seine Fähigkeit, Informationen aus verschiedenen Modalitäten zu verstehen und auf natürliche Weise zu kombinieren.
Video + Audio:
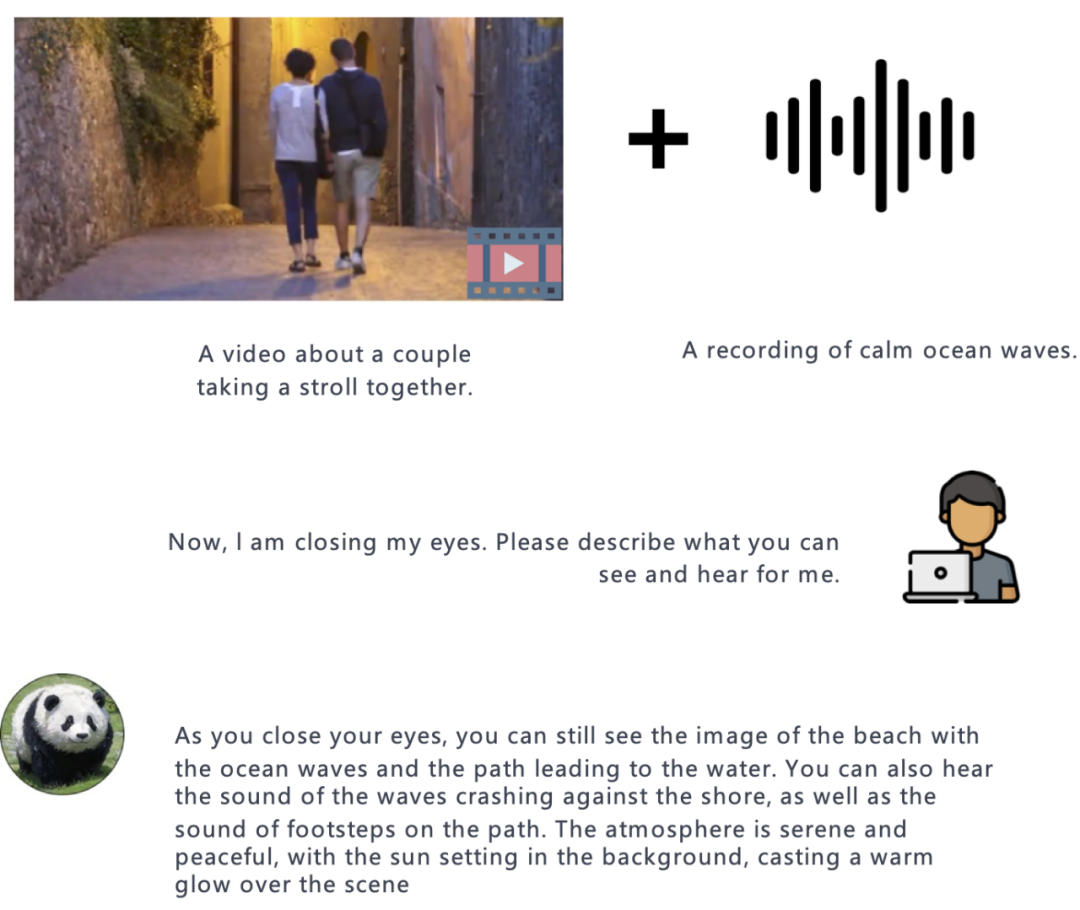
Bild + Audio:

Zusammenfassung
Die Autoren haben auch viele Probleme des aktuellen PandaGPT zusammengefasst und zukünftige Entwicklungsrichtungen. Obwohl PandaGPT über eine erstaunliche Fähigkeit verfügt, mehrere Modalitäten und deren Kombinationen zu verarbeiten, gibt es immer noch viele Möglichkeiten, die Leistung von PandaGPT erheblich zu verbessern.
- PandaGPT kann das Verständnis von anderen Modalitäten als Bildern weiter verbessern, indem es andere modale Ausrichtungsdaten verwendet, wie z. B. die Verwendung von ASR- und TTS-Daten für das modale Verständnis und die Befehlsfolgefunktionen von Audio-Text-Modalitäten.
- Andere Modi als Text werden nur durch einen Einbettungsvektor dargestellt, was dazu führt, dass das Sprachmodell die feinkörnigen Informationen des Modells außer Text nicht verstehen kann. Weitere Forschung zur feinkörnigen Merkmalsextraktion, beispielsweise zu modalübergreifenden Aufmerksamkeitsmechanismen, kann zur Verbesserung der Leistung beitragen.
- PandaGPT erlaubt derzeit nur die Verwendung anderer modaler Informationen als Text als Eingabe. In Zukunft hat dieses Modell das Potenzial, die gesamte AIGC in demselben Modell zu vereinen, d. h. ein Modell kann gleichzeitig Aufgaben wie Bild- und Videogenerierung, Sprachsynthese und Textgenerierung ausführen.
- Neue Benchmarks sind erforderlich, um die Fähigkeit zur Kombination multimodaler Eingaben zu bewerten.
- PandaGPT kann auch einige häufige Mängel bestehender Sprachmodelle aufweisen, darunter Halluzinationen, Toxizität und Stereotypisierung.
Abschließend betonen die Autoren, dass PandaGPT nur ein Forschungsprototyp ist und noch nicht für den direkten Einsatz in einer Produktionsumgebung bereit ist.
Das obige ist der detaillierte Inhalt vonCambridge, Tencent AI Lab und andere haben das große Sprachmodell PandaGPT vorgeschlagen: Ein Modell vereint sechs Modalitäten. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Technologietrends, die Sie im Jahr 2023 im Auge behalten sollten
- Wie künstliche Intelligenz Rechenzentrumsteams neue Alltagsaufgaben beschert
- Können künstliche Intelligenz oder Automatisierung das Problem der geringen Energieeffizienz in Gebäuden lösen?
- OpenAI-Mitbegründer im Interview mit Huang Renxun: Die Argumentationsfähigkeiten von GPT-4 haben noch nicht die Erwartungen erfüllt
- Dank der OpenAI-Technologie übertrifft Bing von Microsoft Google im Suchverkehr