
Heim >Technologie-Peripheriegeräte >KI >Duxiaoman-Quotenmodell basierend auf kontrafaktischer Kausalfolgerung
Duxiaoman-Quotenmodell basierend auf kontrafaktischer Kausalfolgerung

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBnach vorne
- 2023-06-03 22:16:021810Durchsuche

1. Forschungsparadigma der kausalen Schlussfolgerung
Das Forschungsparadigma hat derzeit zwei Hauptforschungsrichtungen:
- Judäa-Perlenstrukturmodell
- Potenzielles Output-Framework
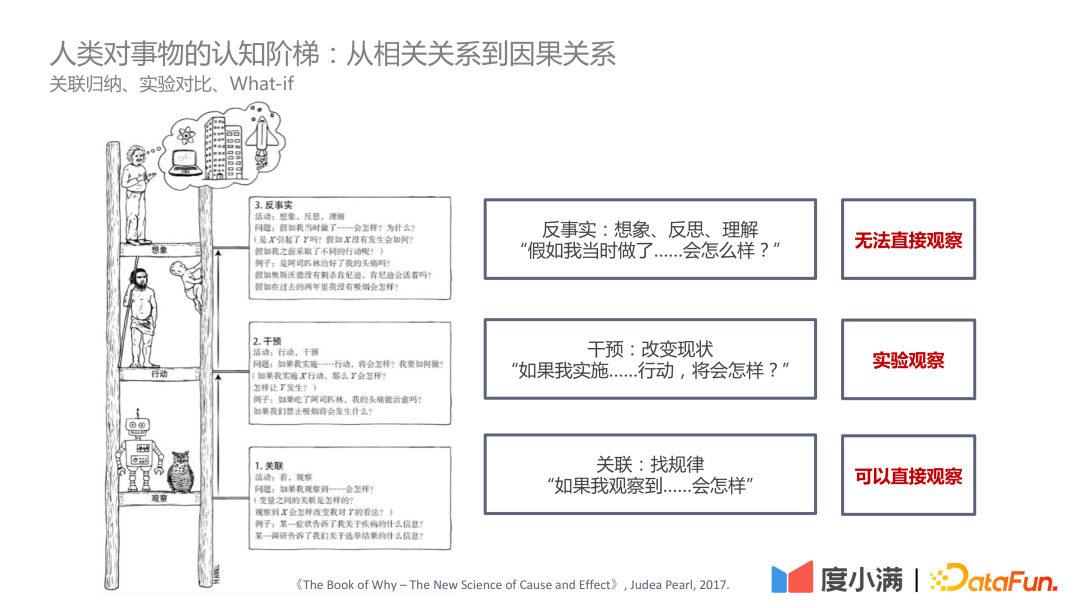
In dem Buch „The Book of Why – The New Science of Cause and Effect“ von Judea Pearl ist die kognitive Leiter in drei Ebenen unterteilt:
- Die erste Ebene – Korrelation: Finden Sie durch Korrelation die Regeln heraus, die direkt beobachtet werden können.
- Die zweite Ebene – Intervention: Wenn sich der Status Quo ändert, welche Maßnahmen umgesetzt werden sollten und welche Schlussfolgerungen daraus gezogen werden können, können Sie experimentell beobachten ;
- Die dritte Ebene – Kontrafaktisch: Aufgrund von Problemen wie Gesetzen und Vorschriften ist eine direkte experimentelle Beobachtung nicht möglich. Durch kontrafaktische Annahmen ist es schwieriger zu bestimmen, was passieren wird, wenn die Maßnahme umgesetzt wird Bewerten Sie ATE und CATE.
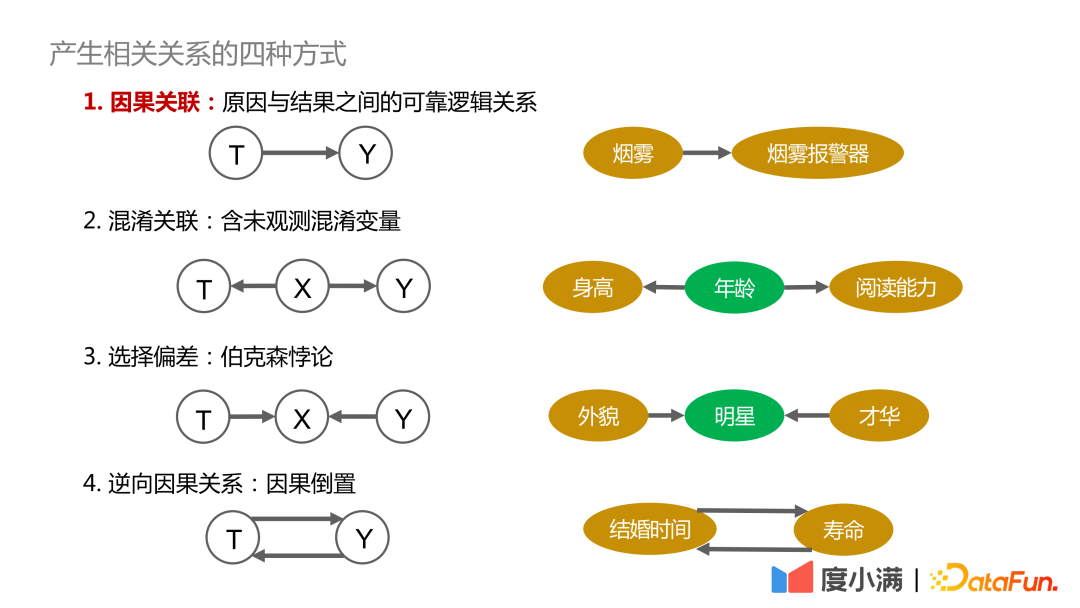
Erklären wir zunächst die vier Möglichkeiten, Korrelationen zu erzeugen:
1. Kausaler Zusammenhang: Es besteht ein verlässlicher, nachvollziehbarer und positiver Zusammenhang zwischen Ursache und Ergebnis . Zusammenhänge wie Rauch und Rauchmelder stehen in einem kausalen Zusammenhang
2: Enthält verwirrende Variablen, die nicht direkt beobachtet werden können, z muss kontrolliert werden. Die Variablen sind ähnlich und ziehen daher gültige Schlussfolgerungen. : Es handelt sich im Wesentlichen um Berksons Paradoxon, z Gruppen, Man könnte zu dem Schluss kommen, dass Aussehen und Talent nicht zusammenpassen. Bei allen Menschen beobachtet, gibt es keinen kausalen Zusammenhang zwischen Aussehen und Talent.
4. Umgekehrte Kausalität: Das heißt, die Umkehrung von Ursache und Wirkung. Statistiken zeigen beispielsweise, dass ihre Lebensspanne umso länger ist, je länger sie verheiratet sind. Aber umgekehrt können wir nicht sagen: Wer länger leben will, muss früh heiraten. Wie Störfaktoren die Beobachtungsergebnisse beeinflussen, hier zwei Fälle zur Veranschaulichung:
Das obige Bild beschreibt den Zusammenhang zwischen Trainingsvolumen und Cholesterinspiegel. Aus dem Bild links können wir schließen, dass der Cholesterinspiegel umso höher ist, je mehr Sport getrieben wird. Wenn jedoch die Altersstratifizierung hinzugefügt wird, gilt bei gleicher Altersstratifizierung, dass der Cholesterinspiegel umso niedriger ist, je mehr Sport betrieben wird. Darüber hinaus steigt der Cholesterinspiegel mit zunehmendem Alter allmählich an, sodass diese Schlussfolgerung mit unserem Wissen übereinstimmt.
Das zweite Beispiel ist das Kreditszenario. Aus historischen Statistiken geht hervor, dass die Überfälligkeitsrate umso niedriger ist, je höher die gegebene Grenze (der Geldbetrag, der geliehen werden kann) ist. Im Finanzbereich wird die Kreditwürdigkeit des Kreditnehmers jedoch zunächst anhand seiner A-Karte beurteilt. Wenn die Kreditwürdigkeit besser ist, gewährt die Plattform ein höheres Limit und die Gesamtüberfälligkeitsrate wird sehr niedrig sein. Lokale Zufallsexperimente zeigen jedoch, dass es bei Personen mit den gleichen Kreditqualifikationen einige Personen geben wird, deren Kreditlimit-Migrationskurve sich langsam ändert, und dass es auch einige Personen geben wird, deren Kreditlimit-Migrationsrisiko höher ist erhöht wird, wird der Risikoanstieg größer sein.
Die beiden oben genannten Fälle verdeutlichen, dass es zu falschen oder sogar gegenteiligen Schlussfolgerungen kommen kann, wenn Störfaktoren bei der Modellierung ignoriert werden.
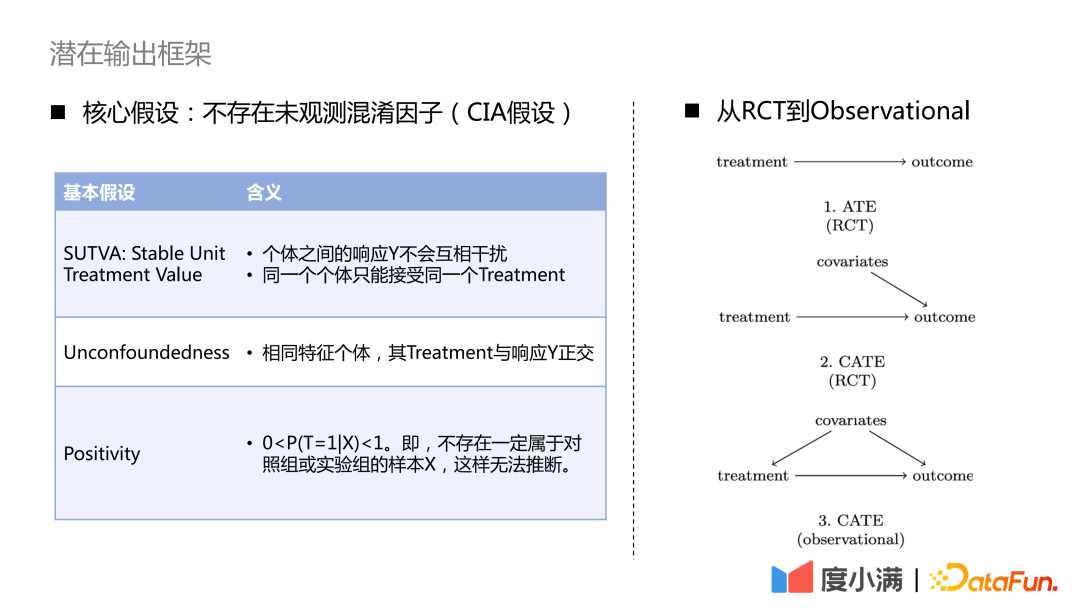
Wie gelingt der Übergang von RCT-Zufallsstichproben zur kausalen Modellierung von Beobachtungsstichproben?
Wenn Sie bei RCT-Stichproben den ATE-Indikator auswerten möchten, können Sie die Gruppensubtraktion oder DID (Differenz in Differenz) verwenden. Wenn Sie den CATE-Indikator auswerten möchten, können Sie die Uplift-Modellierung verwenden. Zu den gängigen Methoden gehören Meta-Learner, doppeltes maschinelles Lernen, Kausalwald usw. Hier sind drei notwendige Annahmen zu beachten: SUTVA, Unbegründetheit und Positivität. Die Kernannahme ist, dass es keine unbeobachteten Störfaktoren gibt.
Für den Fall, dass nur Beobachtungsstichproben vorhanden sind, kann der kausale Zusammenhang zwischen Behandlung und Ergebnis nicht direkt ermittelt werden. Wir müssen die erforderlichen Mittel einsetzen, um den Hintertürweg von den Kovariaten zur Behandlung abzuschneiden. Gängige Methoden sind instrumentelle Variablenmethoden und kontrafaktisches Repräsentationslernen. Bei der instrumentellen Variablenmethode müssen die Details des spezifischen Geschäfts herausgearbeitet und ein Ursache-Wirkungs-Diagramm der Geschäftsvariablen erstellt werden. Das kontrafaktische Repräsentationslernen basiert auf ausgereiftem maschinellem Lernen, um Stichproben mit ähnlichen Kovariaten für die kausale Bewertung abzugleichen. ?? Um Schritt für Schritt zur kausalen Repräsentation überzugehen.
Zu den gängigen Uplift-Modellen gehören: Slearner, Tlearner, Xlearner.
wobei Slearner die dazwischenliegenden Variablen als eindimensionale Merkmale behandelt. Es ist zu beachten, dass in gängigen Baummodellen die Behandlung leicht überfordert ist, was zu geringeren Schätzungen des Behandlungseffekts führt.
Tlearner diskretisiert die Behandlung, modelliert die dazwischenliegenden Variablen in Gruppen, erstellt ein Vorhersagemodell für jede Behandlung und macht dann einen Unterschied. Es ist wichtig zu beachten, dass kleinere Stichprobengrößen zu höheren geschätzten Varianzen führen.
Xlearner-Gruppen-Kreuzmodellierung, die Versuchsgruppe und die Kontrollgruppe werden kreuzberechnet und separat trainiert. Diese Methode vereint die Vorteile von S/T-Learner, ihr Nachteil besteht jedoch darin, dass sie höhere Modellstrukturfehler einführt und die Schwierigkeit der Parameteranpassung erhöht.
Vergleich von drei Modellen:
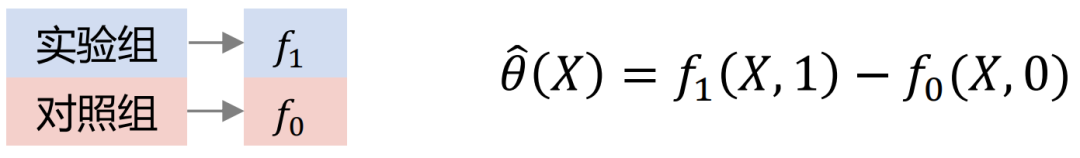
In der obigen Abbildung ist die horizontale Achse der komplexe kausale Effekt, der Schätzfehler von MSE, und die vertikale Achse ist einfacher Kausalitätseffekt, die horizontale Achse und die vertikale Achse repräsentieren jeweils zwei Datenelemente. Grün repräsentiert die Fehlerverteilung von Slearner, Braun repräsentiert die Fehlerverteilung von Tlearner und Blau repräsentiert die Fehlerverteilung von Xlearner. 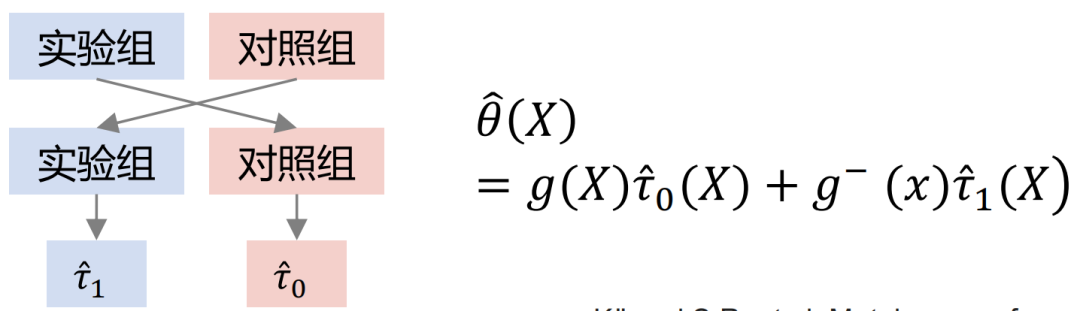
Unter Zufallsstichprobenbedingungen eignet sich Xlearner besser für die Schätzung komplexer Kausaleffekte und für die Schätzung einfacher Kausaleffekte;
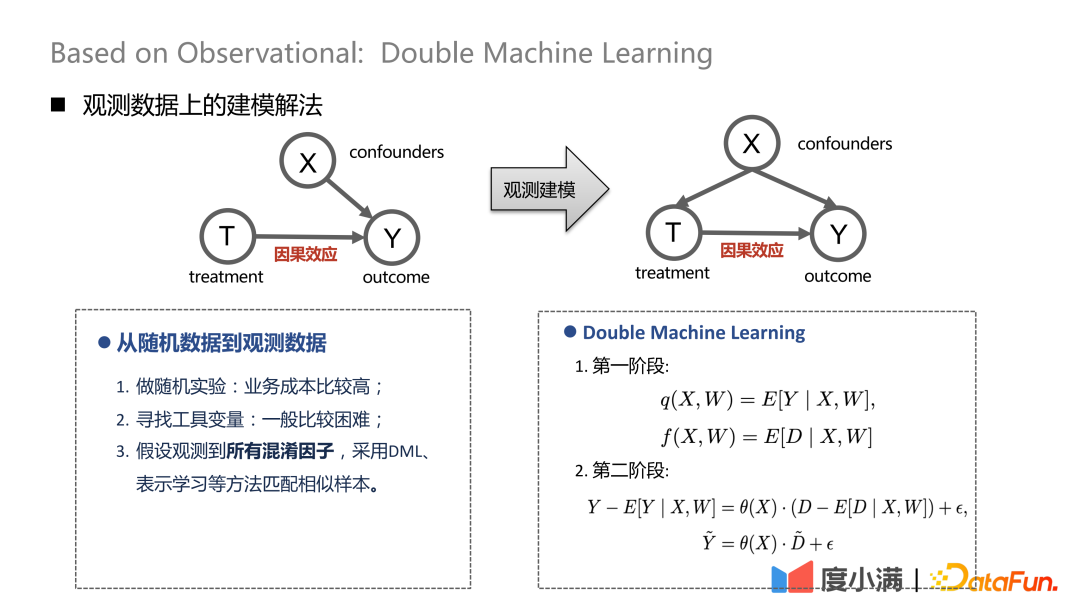
Bei Zufallsstichproben können die Pfeile von X bis T entfernt werden. Nach dem Übergang zur Beobachtungsmodellierung können die Pfeile von X nach T nicht gleichzeitig durch Störfaktoren beeinflusst werden. Zu diesem Zeitpunkt kann eine gewisse Depolarisierungsverarbeitung durchgeführt werden. Beispielsweise führt die DML-Methode (Double Machine Learning) eine zweistufige Modellierung durch. In der ersten Stufe handelt es sich bei X hier um die eigenen Darstellungsmerkmale des Nutzers, wie Alter, Geschlecht etc. Zu den verwirrenden Variablen könnten beispielsweise historische Bemühungen gehören, bestimmte Personengruppen auszusortieren. In der zweiten Stufe wird der Fehler im Berechnungsergebnis der vorherigen Stufe modelliert, hier erfolgt die Schätzung von CATE.
Es gibt drei Verarbeitungsmethoden von Zufallsdaten zu Beobachtungsdaten:
(1) Führen Sie Zufallsexperimente durch, aber die Geschäftskosten sind höher;
(2) Finden Sie instrumentelle Variablen , im Allgemeinen Relativ schwierig;
(3) Gehen Sie davon aus, dass alle Störfaktoren beobachtet werden, und verwenden Sie DML, Repräsentationslernen und andere Methoden, um ähnliche Stichproben abzugleichen.
2. Kausales Repräsentationslernen
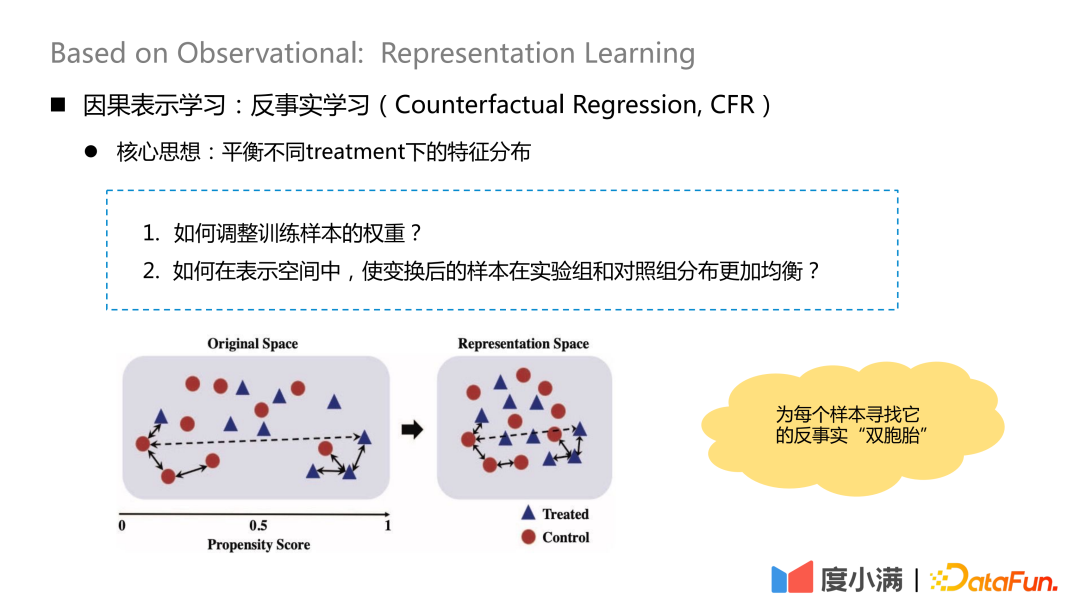
Die Kernidee des kontrafaktischen Lernens besteht darin, die Merkmalsverteilung unter verschiedenen Behandlungen auszugleichen.
Es gibt zwei Kernfragen:
1. Wie passt man das Gewicht von Trainingsproben an?
2. Wie können die transformierten Proben gleichmäßiger in der Versuchsgruppe und der Kontrollgruppe im Darstellungsraum verteilt werden?
Die wesentliche Idee besteht darin, für jede Stichprobe nach der Transformationszuordnung ihren kontrafaktischen „Zwilling“ zu finden. Nach der Kartierung ist die Verteilung von X in der Behandlungsgruppe und der Kontrollgruppe relativ ähnlich.
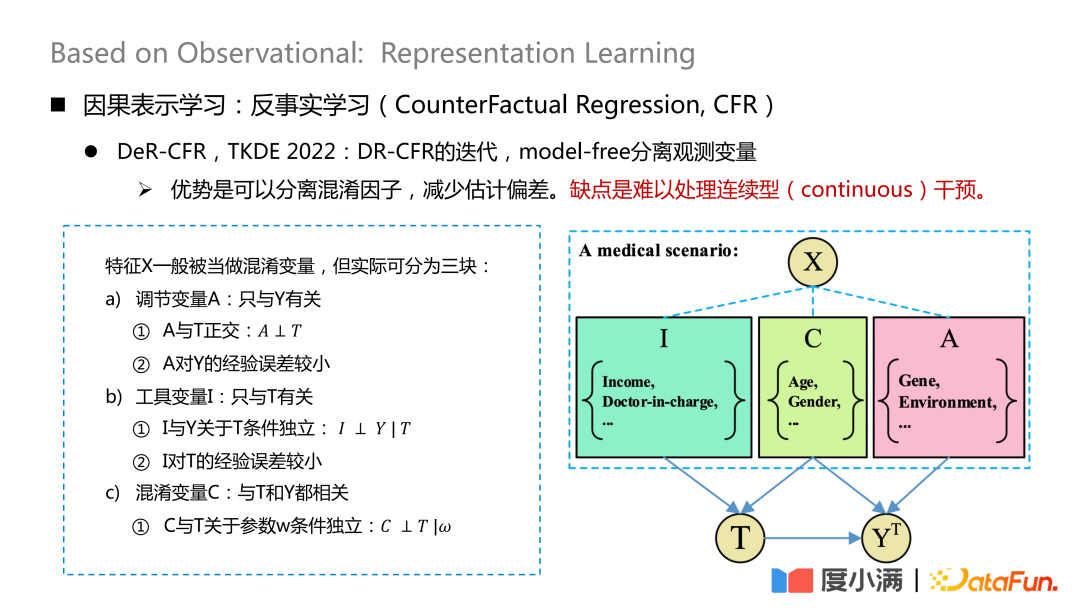
Die repräsentativere Arbeit ist ein auf TKDE 2022 veröffentlichtes Papier, das einige Arbeiten von DeR-CFR vorstellt. Dieser Teil ist eigentlich eine Iteration des DR-CRF-Modells, bei der eine modellfreie Trennung verwendet wird beobachtete Variablen.
Teilen Sie die X-Variable in drei Teile: Anpassungsvariable A, Instrumentalvariable I und Störvariable C. Dann werden I, C und A verwendet, um das Gewicht von X unter verschiedenen Behandlungen anzupassen, um den Zweck der kausalen Modellierung der beobachteten Daten zu erreichen.
Der Vorteil dieser Methode besteht darin, dass sie Störfaktoren trennen und Schätzfehler reduzieren kann. Der Nachteil besteht darin, dass es schwierig ist, kontinuierliche Eingriffe zu bewältigen.
Der Kern dieses Netzwerks besteht darin, die drei Arten von Variablen A/I/C zu trennen. Die Anpassungsvariable A bezieht sich nur auf Y und es muss sichergestellt werden, dass A und T orthogonal sind und der empirische Fehler von A zu Y gering ist. Die Instrumentvariable I bezieht sich nur auf T und muss Folgendes erfüllen Die bedingte Unabhängigkeit von I und Y in Bezug auf T und die Erfahrung von I in Bezug auf T sind gering. Die Verwirrungsvariable C hängt sowohl mit T als auch mit Y zusammen, und w ist das Gewicht des Netzwerks Gewicht muss sichergestellt werden, dass C und T in Bezug auf w bedingt unabhängig sind. Die Orthogonalität kann hier durch allgemeine Abstandsformeln wie Logloss oder mse Euklidische Distanz und andere Einschränkungen erreicht werden.
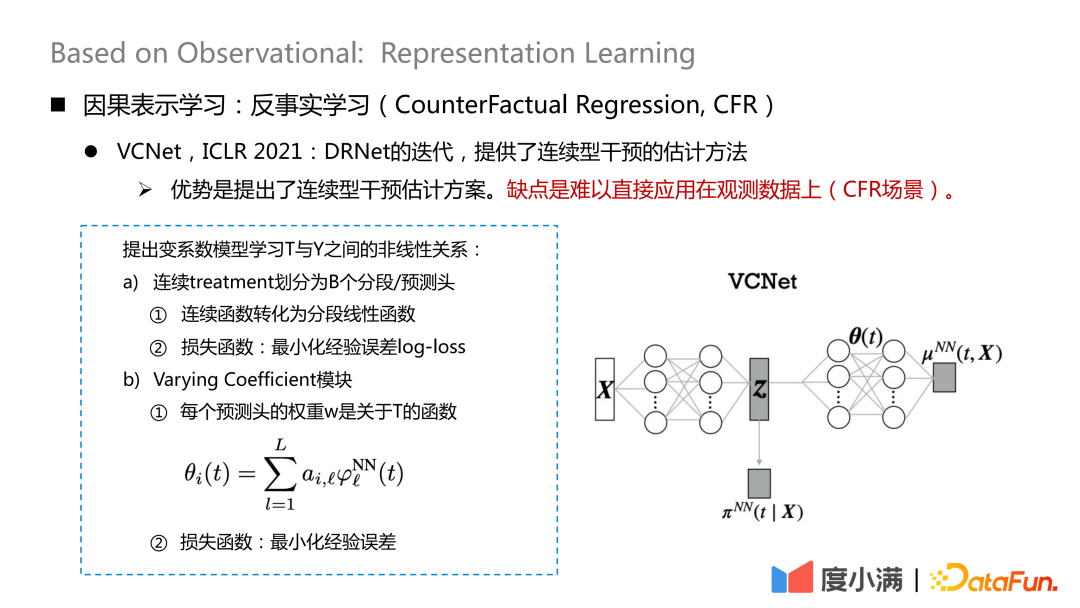
Es gibt auch einige neue Papierstudien zum Umgang mit kontinuierlicher Intervention, die auf ICLR2021 veröffentlicht wurden und eine Schätzmethode für kontinuierliche Intervention bieten. Der Nachteil besteht darin, dass es schwierig ist, es direkt auf Beobachtungsdaten anzuwenden (CFR-Szenario).
Ordnen Sie Das heißt, Variablen, die zur Behandlung beitragen, werden aus X extrahiert. Hier wird die kontinuierliche Behandlung in B-Segmentierungs-/Vorhersageköpfe unterteilt, jede kontinuierliche Funktion wird in eine segmentierte lineare Funktion umgewandelt und der empirische Fehlerprotokollverlust wird minimiert, der zum Lernen verwendet wird #🎜 🎜## 🎜🎜#
Dann verwenden Sie das Z und θ(t), das Sie gelernt haben, zu lernen. Das ist das Ergebnis. θ(t) ist hier der Schlüssel zur Verarbeitung der kontinuierlichen Behandlung. Es handelt sich um ein Modell mit variablen Koeffizienten, aber dieses Modell verarbeitet nur die kontinuierliche Behandlung. Wenn es sich um Beobachtungsdaten handelt, kann nicht garantiert werden, dass alle B-Segmentdaten homogen sind. 
# 🎜 🎜#Lassen Sie uns abschließend das kontrafaktische Quotenmodell von Du Xiaoman vorstellen. Die Hauptlösung hier ist das kontrafaktische Schätzproblem der kontinuierlichen Behandlung von Beobachtungsdaten.
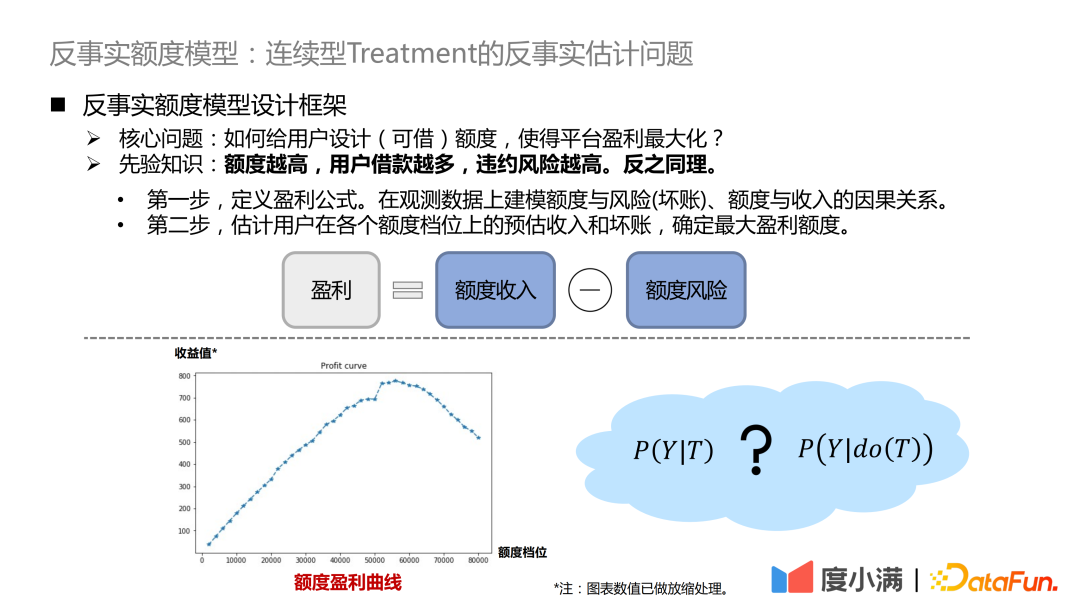
- Der erste Schritt besteht darin, die Gewinnformel zu definieren. Gewinn = Quoteneinkommen – Quotenrisiko. Die Formel sieht einfach aus, tatsächlich gibt es aber viele Details anzupassen. Auf diese Weise wird das Problem dahingehend transformiert, den Kausalzusammenhang zwischen Quote und Risiko (uneinbringliche Schulden), Quote und Einkommen anhand von Beobachtungsdaten zu modellieren.
- Der zweite Schritt besteht darin, das geschätzte Einkommen und die Forderungsausfälle des Benutzers auf jeder Quotenebene zu schätzen und den maximalen Gewinnbetrag zu bestimmen.
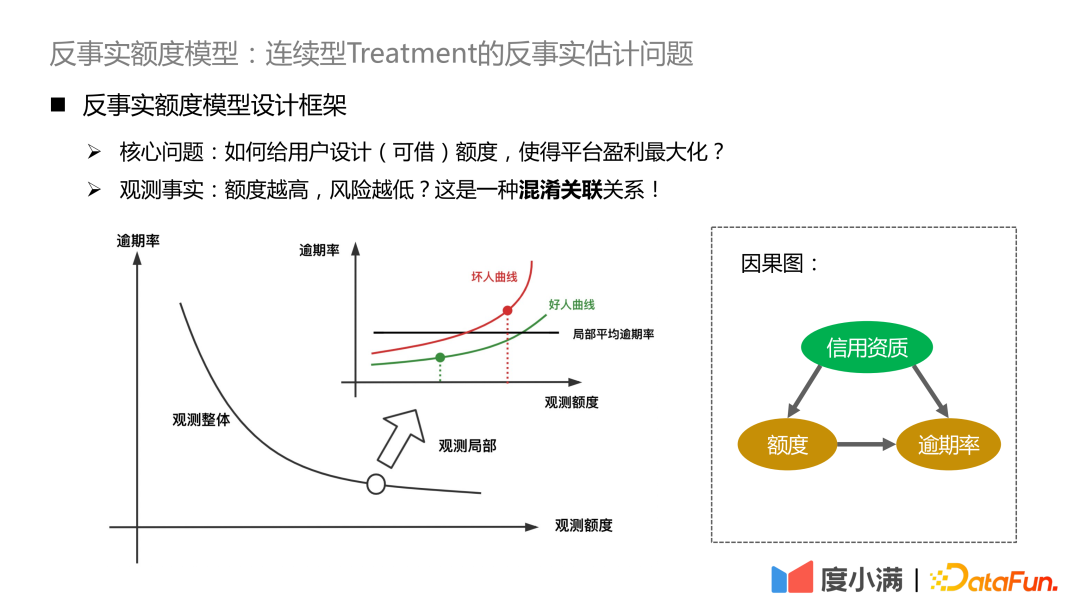
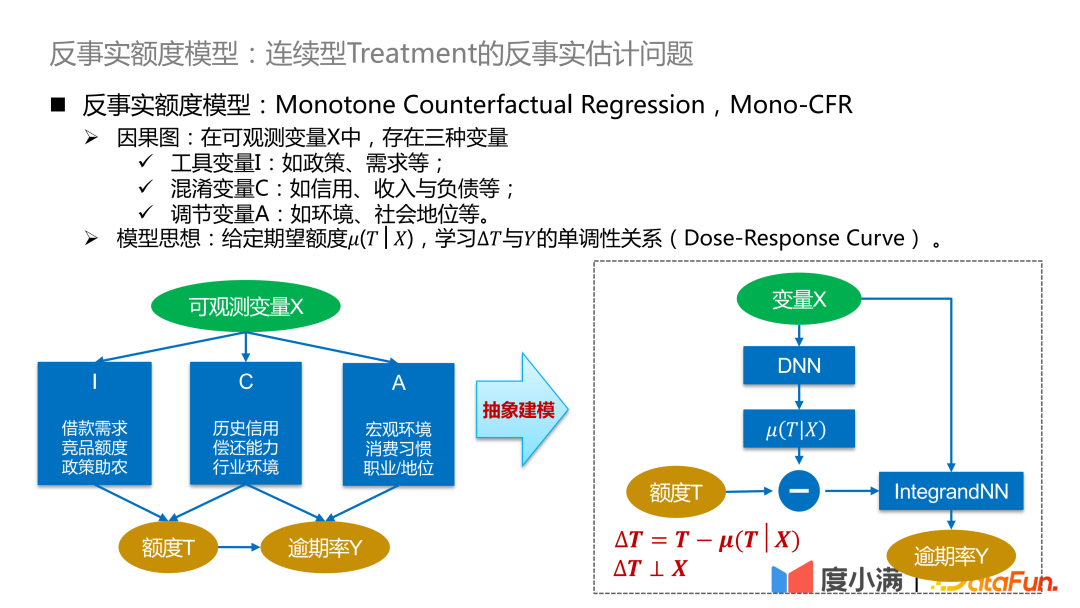
Modellidee: Lernen Sie bei gegebener erwarteter Menge μ(T|X) die monotone Beziehung zwischen ΔT und Y (Dosis-Wirkungs-Kurve). Der erwartete Betrag kann als der vom Modell gelernte kontinuierliche Tendenzbetrag verstanden werden, sodass die Beziehung zwischen der Störvariablen C und dem Betrag T getrennt und in das kausale Beziehungslernen zwischen ΔT und Y umgewandelt werden kann, um die Verteilung zu vergleichen von Y unter ΔT Gute Charakterisierung.
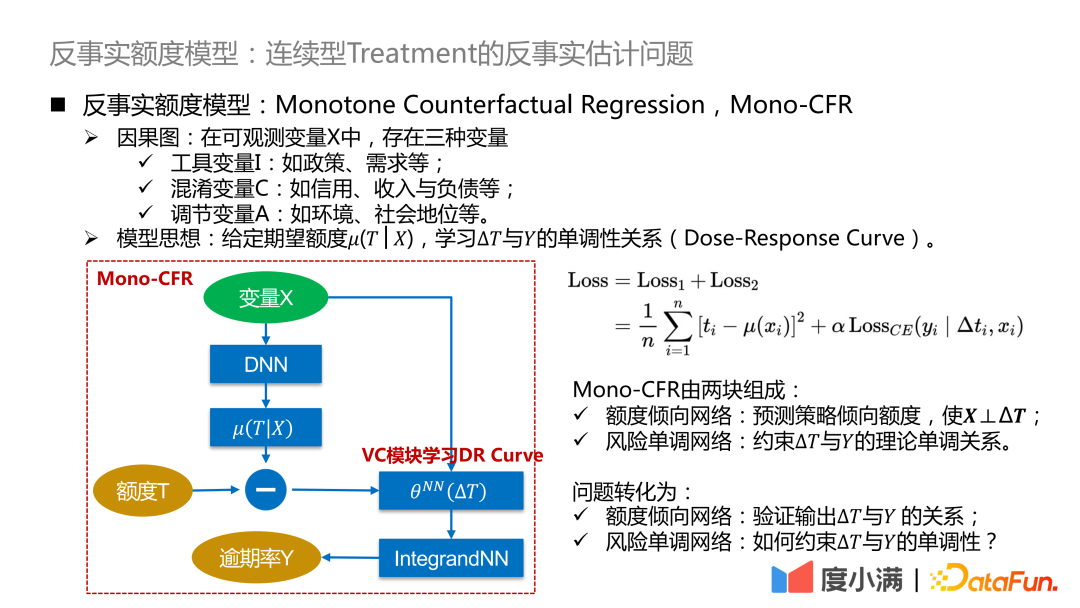
Der obige abstrakte Rahmen wird hier weiter verfeinert: ΔT wird in ein Modell mit variablen Koeffizienten umgewandelt und dann mit dem IntegrandNN-Netzwerk verbunden. Der Trainingsfehler wird in zwei Teile unterteilt:
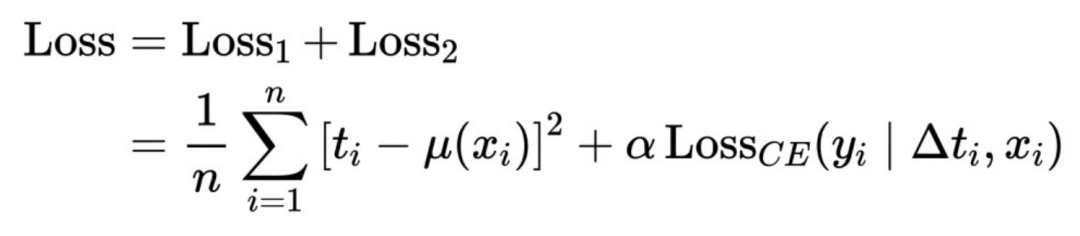
Das α ist hier ein Hyperparameter, der die Bedeutung des Risikos misst.
Mono-CFR besteht aus zwei Teilen:
- Betragsneigungsnetzwerk: Vorhersage des Strategiepräferenzbetrags, sodass X⊥ΔT.
Funktion 1: Destillieren Sie die Variablen in X heraus, die für T am relevantesten sind, und minimieren Sie den empirischen Fehler.
Funktion 2: Näherungsbeispiele auf historischen Strategien verankern.
- Risikomonotones Netzwerk: Die theoretische monotone Beziehung zwischen der Einschränkung ΔT und Y.
Funktion 1: Anwenden unabhängiger monotoner Einschränkungen auf schwache Koeffizientenvariablen.
Funktion 2: Schätzungsverzerrung reduzieren.
Das Problem wird wie folgt umgewandelt:
- Betragsneigungsnetzwerk: Überprüfen Sie die Beziehung zwischen der Ausgabe ΔT und Y.
- Risikomonotonisches Netzwerk: Wie kann die Monotonie von ΔT und Y eingeschränkt werden?
Die tatsächliche Quotenneigungsnetzwerkeingabe ist wie folgt:
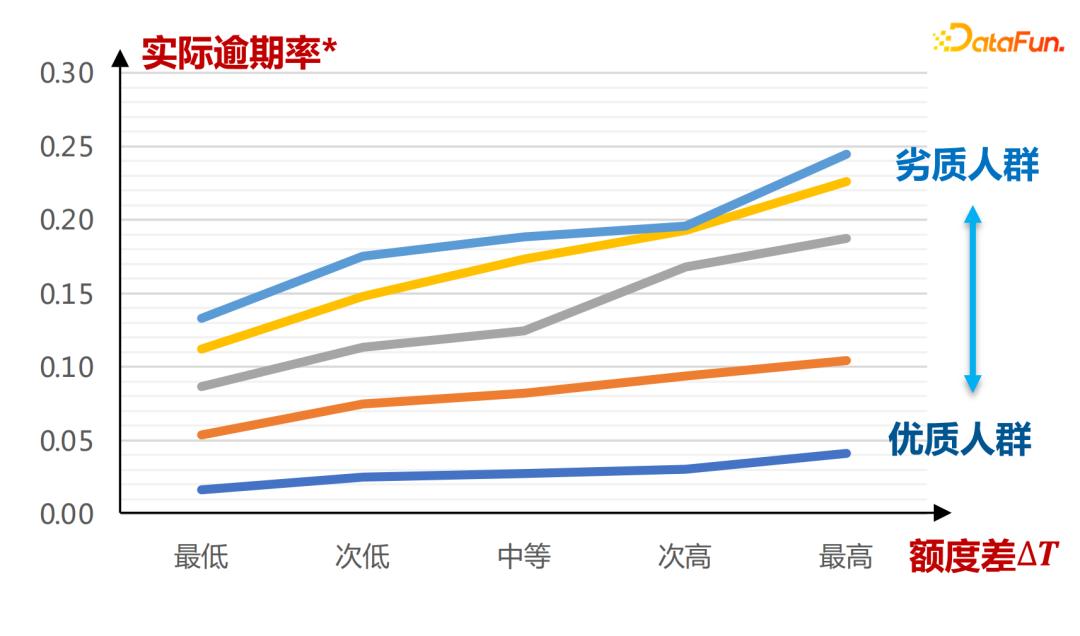
Die horizontale Achse ist die durch den A-Karten-Score definierte Gruppe. Dies ist unter verschiedenen Neigungsquoten zu sehen μ(T | die gesamte Kurve ist größer. Die Schlussfolgerungen hier werden vollständig durch das Lernen historischer Daten gezogen.
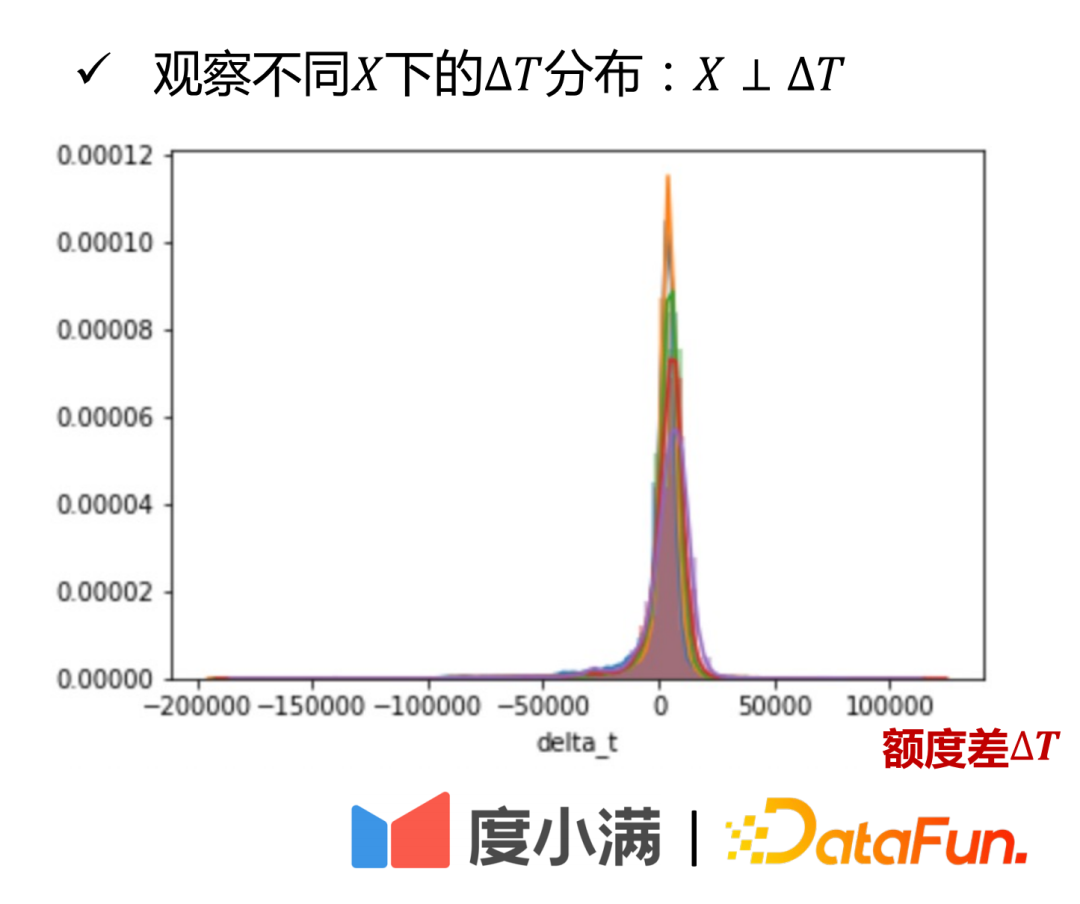
Es ist aus dem Verteilungsdiagramm von ersichtlich. Dies wird aus praktischer Sicht erklärt.
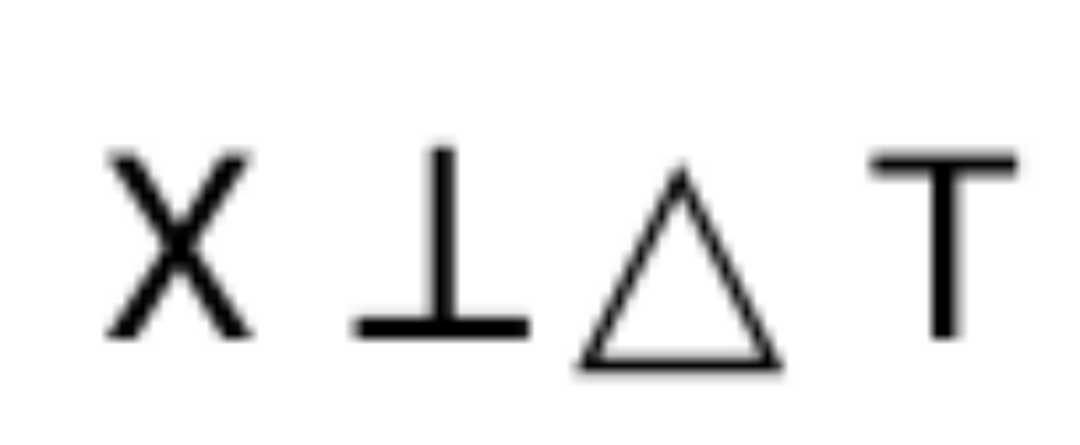
Aus theoretischer Sicht lässt es sich auch rigoros beweisen.
Der zweite Teil ist die Implementierung des risikomonotonen Netzwerks:

Der mathematische Ausdruck der ELU+1-Funktion hier ist:
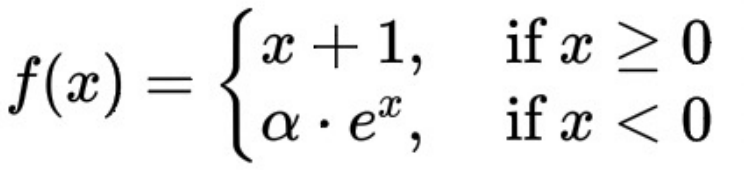
ΔT und die Überfälligkeitsrate zeigen einen monoton steigenden Trend, der dadurch garantiert wird, dass die Ableitung der ELU+1-Funktion immer größer oder gleich 0 ist.
Erklären Sie als Nächstes, wie das risikomonotone Netzwerk für schwache Koeffizientenvariablen genauer lernen kann:
Angenommen, es gibt eine solche Formel:
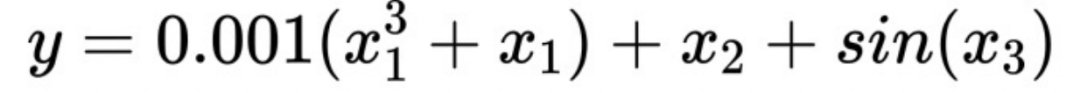
x1 eine schwache Koeffizientenvariable. Wenn x1 Monotoniebeschränkungen auferlegt werden, ist die Schätzung der Antwort Y genauer. Ohne eine solche separate Einschränkung wird die Bedeutung von x1 durch x2 überwältigt, was zu einer erhöhten Modellverzerrung führt.
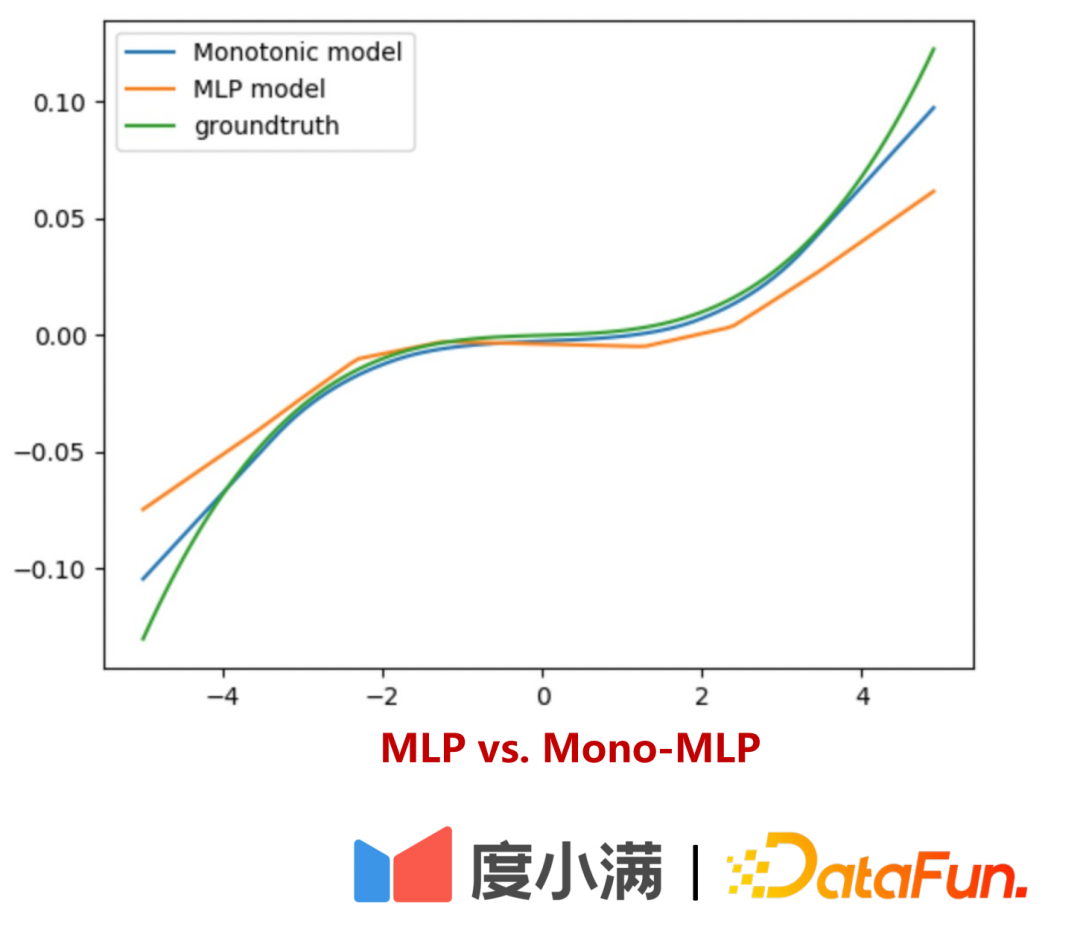
ist in zwei Teile unterteilt:
- Teil Eins: Interpretierbare Überprüfung
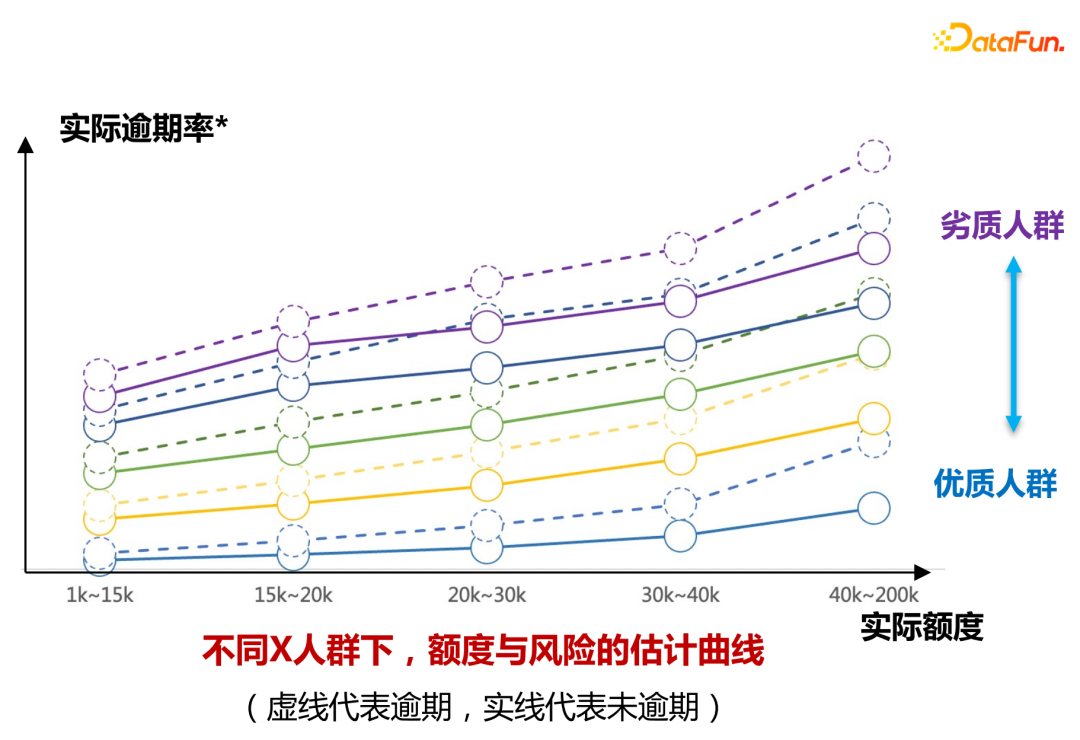
- Teil 2: Verwenden Sie kleine Verkehrsexperimente, um zu überprüfen, ob die Risikoabweichung unter verschiedenen Anstiegsbereichen durch Uplift-Binning ermittelt werden kann.
Unter der Bedingung, dass die Quote um 30 % steigt, sinkt die überfällige Anzahl der Nutzer um mehr als 20 %, die Kreditaufnahme steigt um 30 % und die Rentabilität steigt um mehr als 30 %.
Zukünftige Modellerwartungen:
Trennen Sie instrumentelle Variablen und moderierende Variablen klarer in modellfreier Form, damit das Modell beim Risikotransfer bei Gruppen schlechter Qualität eine bessere Leistung erbringen kann.
In tatsächlichen Geschäftsszenarien sieht der Iterationsprozess der Modellentwicklung von Du Xiaoman wie folgt aus:
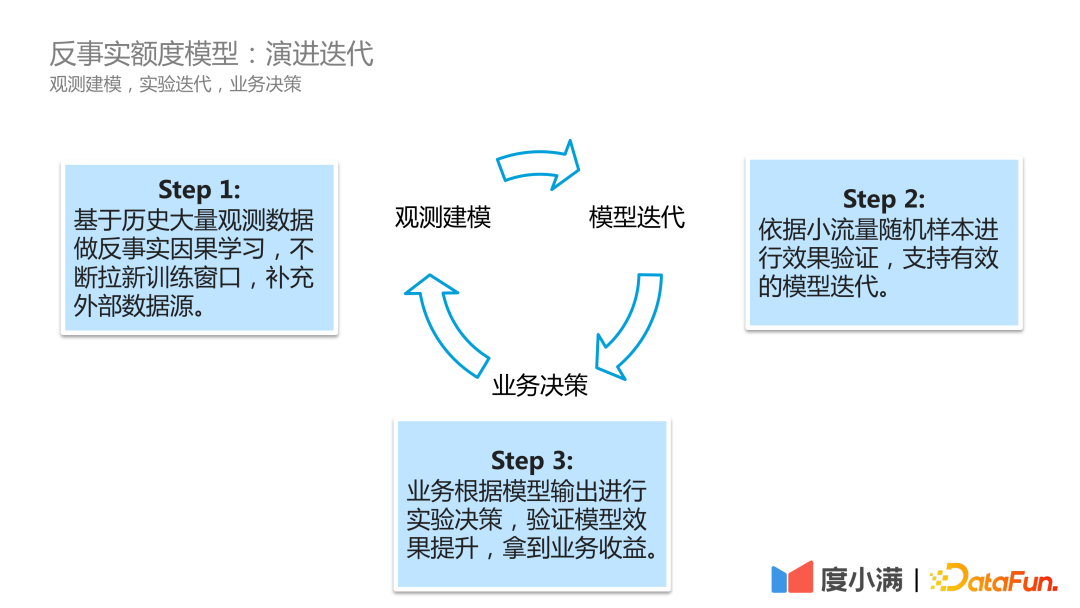
Der erste Schritt ist die Beobachtungsmodellierung, das kontinuierliche Scrollen historischer Beobachtungsdaten und das Durchführen von kontrafaktischen Kausallernen öffnet kontinuierlich neue Trainingsfenster und ergänzt externe Datenquellen.
Der zweite Schritt ist die Modelliteration. Der Effekt wird anhand kleiner Verkehrsstichproben überprüft, um eine effektive Modelliteration zu unterstützen.
Der dritte Schritt ist die geschäftliche Entscheidungsfindung auf der Grundlage der Modellausgabe, um die Verbesserung des Modelleffekts zu überprüfen geschäftliche Vorteile erzielen.
Das obige ist der detaillierte Inhalt vonDuxiaoman-Quotenmodell basierend auf kontrafaktischer Kausalfolgerung. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Technologietrends, die Sie im Jahr 2023 im Auge behalten sollten
- Wie künstliche Intelligenz Rechenzentrumsteams neue Alltagsaufgaben beschert
- Können künstliche Intelligenz oder Automatisierung das Problem der geringen Energieeffizienz in Gebäuden lösen?
- OpenAI-Mitbegründer im Interview mit Huang Renxun: Die Argumentationsfähigkeiten von GPT-4 haben noch nicht die Erwartungen erfüllt
- Dank der OpenAI-Technologie übertrifft Bing von Microsoft Google im Suchverkehr